本文主要是介绍mysql索引一(普通索引),希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
mysql的索引分为两大类,聚簇索引、非聚簇索引。聚簇索引是按照数据存放的物理位置为顺序的,而非聚簇索引则不同。聚簇索引能够提高多行检索的速度、非聚簇索引则对单行检索的速度很快。
在这两大类的索引类型下,还可以降索引分为4个小类型:
1,普通索引:最基本的索引,没有任何限制,是我们经常使用到的索引。
2,唯一索引:与普通索引类似,不同的是,唯一索引的列值必须唯一,但允许为空值。
主键索引是特殊的唯一索引,不允许有空值。
3,全文索引:全文索引(FULLTEXT)仅可以适用于MyISAM引擎的数据表,作用于CHAR,VARCHAR、TEXT数据类型的列。
4、组合索引:将几个列作为一条索引进行检索,使用最左匹配原则。
下面对以上的几种索引类型进行实践:
1,首先建立一个student表,向其中加入了20000条数据。SQL如下:
DROP TABLE IF EXISTS `student`;
CREATE TABLE `student` (`s_id` int(11) NOT NULL AUTO_INCREMENT,`s_name` varchar(100) DEFAULT NULL,`s_age` int(11) DEFAULT NULL,`s_phone` varchar(30) DEFAULT NULL,PRIMARY KEY (`s_id`)
) ENGINE=InnoDB, CHARSET=utf8;向里面加入数据的简单代码如下:其中id,name,phone是不重复的,年龄分为10,20,30岁。
package com.crscic.mysql;import java.sql.Connection;
import java.sql.DriverManager;
import java.sql.SQLException;
import java.util.Date;import com.mysql.jdbc.PreparedStatement;public class InsertTest {public static void main(String[] args) throws ClassNotFoundException, SQLException {final String url = "jdbc:mysql://127.0.0.1/test"; final String name = "com.mysql.jdbc.Driver"; final String user = "root"; final String password = "crscic"; Connection conn = null; Class.forName(name);//指定连接类型 conn = DriverManager.getConnection(url, user, password);//获取连接 if (conn!=null) {System.out.println("获取连接成功");insert(conn);}else {System.out.println("获取连接失败");}}public static void insert(Connection conn) {// 开始时间Long begin = new Date().getTime();PreparedStatement pst = null;// sql前缀String prefix = "INSERT INTO student (s_id,s_name,s_age,s_phone) VALUES ";try {// 保存sql后缀StringBuffer suffix = new StringBuffer();// 设置事务为非自动提交conn.setAutoCommit(false);// 比起st,pst会更好些pst = (PreparedStatement) conn.prepareStatement("");//准备执行语句// 外层循环,总提交事务次数suffix = new StringBuffer();// 第j次提交步长for (int j = 1; j <= 20000; j++) {// 构建SQL后缀if(j<=1000){suffix.append("(" + j+","+"'name"+ j +"',10,'"+j+"'),");}else if(10000<j || j<20000){suffix.append("(" + j+","+"'name"+ j +"',20,'"+j+"'),");}else{suffix.append("(" + j+","+"'name"+ j +"',30,'"+j+"'),");}}// 构建完整SQLString sql = prefix + suffix.substring(0, suffix.length() - 1);// 添加执行SQLpst.addBatch(sql);// 执行操作pst.executeBatch();// 提交事务conn.commit();// 清空上一次添加的数据suffix = new StringBuffer();} catch (SQLException e) {e.printStackTrace();}finally{try {pst.close();conn.close();} catch (SQLException e) {e.printStackTrace();}}// 结束时间Long end = new Date().getTime();// 耗时System.out.println("20000条数据插入花费时间 : " + (end - begin) / 1000 + " s");System.out.println("插入完成");}
}先看看不使用普通索引的情况下的查询情况。
select * from student where s_name='name10000'
可以看到查询时间是0.013s。
使用explain看一下具体的查询情况:

分析其中的关键信息:
1,select_type:SIMPLE,表示这是一次简单的查询,没有join,union,没有中间表
2,type:ALL,表示这次查询进行了全表查询
3,key,mysql使用的索引名,null表示此次SQL查询mysql并没有使用索引
4,rows,这个最关键,表示这个SQL查询了20179条记录
接下来,给s_name这一列加上普通索引
alter table student add index s_name(s_name)
可以看到,加了索引之后,查询时间几乎为0,速度非常快。
再使用explain查看一下,如图:

从分析结果上来看,由于此次SQL对列s_name使用了索引,因此rows只查了1条记录,大大提升了查询效率。
什么情况下建立索引合适?
把索引建立在有大量重复数据的字段上,并不能有效地提升SQL效率,比如我的s_age的取值为10,20,30,此时对s_age做查询,未加索引的时候:
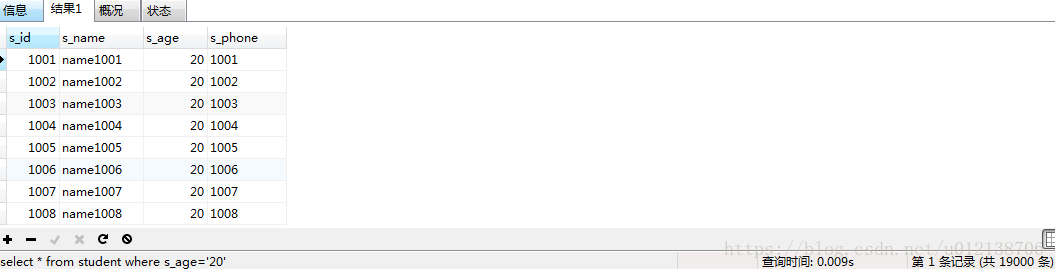
查询时间是0.009s。下面通过explain看看:

可以看到是查询了20635条记录。
下面给s_age加上索引,再次进行查询:
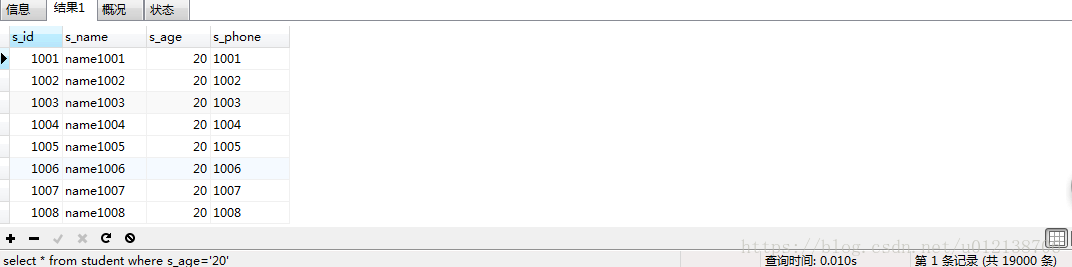
时间反而变为了0.010s,没有提升查询效率,反而降低了。通过explain看看具体情况:

发现这次查询,查询了9672条记录。
可能数据比较少,结果对比不是很明显。在测试期间,在删除和增加几次s_age索引的几次测试中,rows数值不一样。而且每次删除之后,第一次查询,时间都比较长,然后再次直行查询语句,时间降了很多。留待以后再观察吧。

这是删除了s_age索引之后又用explain观察的的查询。
下面再增加s_age索引,然后进行观察:

这里的rows变成了9719。
需要注意的是:在索引列上使用函数,会使索引失效。
索引和like。
就下面这两种情况下,没有用到索引。
explain select * from student where s_name like "%name1001%";
explain select * from student where s_name like "%name1001";结果如图:

但是通配符在结尾的时候,是可以用到索引的。
explain select * from student where s_name like "name1001%";就不上图了。也就是说,要对索引列使用like,通配符只能在结尾,开头不可以有任何的通配符。
本文介绍了普通索引,写起来才发现问题有那么多,而且看起来,这还不是全部,其余的索引类型必须要重新开一篇了。
这篇关于mysql索引一(普通索引)的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





