本文主要是介绍mysql中存储过过程和游标的联合使用,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
1.SQL如下:
DELIMITER //
DROP PROCEDURE IF EXISTS PrintAllEmployeeNames5;
CREATE PROCEDURE PrintAllEmployeeNames5()
BEGINDECLARE error_count INT DEFAULT 0;DECLARE num INT ;DECLARE done INT DEFAULT 0;DECLARE id1 BIGINT DEFAULT 0;DECLARE address VARCHAR(255) DEFAULT null;DECLARE username1 VARCHAR(255) DEFAULT null;DECLARE phone1 VARCHAR(255) DEFAULT '';DECLARE visittime1 DATETIME DEFAULT NULL;-- 定义游标hualian_userDECLARE cur CURSOR FOR SELECTid,phone,last_login_time,ip_address FROM tb_user; -- 声明NOT FOUND处理程序,当游标中没有更多行时,将done设置为1DECLARE CONTINUE HANDLER FOR NOT FOUND SET done = 1;-- 下边语句会自动跳过失败语句-- DECLARE CONTINUE HANDLER FOR SQLEXCEPTION SET error_count =1;--事务未生效-- START TRANSACTION;OPEN cur;read_loop: LOOPFETCH cur INTO id1,phone1,visittime1,address;SELECT address;-- 检查是否还有更多的行IF done THENLEAVE read_loop;END IF;-- 业务逻辑UPDATE tb_user SET statuss=2 WHERE id=id1;-- mysql中,除数为0,不会抛出异常,会返回特定的结果或警告 visittime1SET num=1/0;INSERT INTO tb_user_copy(id,phone,last_login_time,ip_address) VALUES(id1,phone1,address,address); END LOOP;CLOSE cur;-- COMMIT;END //
DELIMITER ;-- 执行存储过程CALL PrintAllEmployeeNames5();2.遇到的bug
1.SQL ERROR 1064 : You have an error in your SQL syntax; check the manual that corresponds to
原因:把自定义变量定义在定义游标之后
改正方式:把自定义变量放到定义游标之前
2.Mysql中关于 错误 1366 - Incorrect string value: ‘\xE5\xBC\xA0\xE4\xB8\x89‘ for column ‘name‘ at row 1
判断步骤:
1.使用出现问题的字段的字符集编码
方法一:使用HeidiSQL操作

方法二:SQL查询:SHOW FULL COLUMNS from tb_user;
 查询的报错字段字符集如上图所示
查询的报错字段字符集如上图所示
2.修改数据库的字符集编码HeidiSQL()
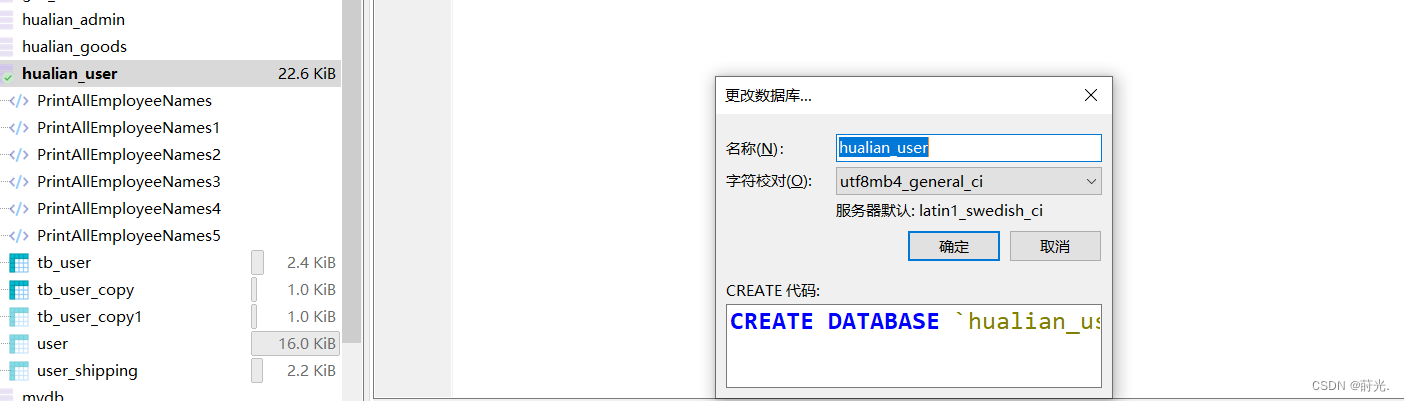
修改字符集编码与报错字段的字符集编码相同
终于成功!!!!
这篇关于mysql中存储过过程和游标的联合使用的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





