本文主要是介绍统计是一门艺术(点估计),希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
1 点估计
1.1 点估计理解(point estimate)
总体,样本
属于参数空间
一般未知,要由样本对
作一个估计,或对
作一个估计,这种估计称为点估计
通常用记为
的一个点估计。
1.2 点估计的方法
(1)矩估计:
就是用样本矩来代替总体矩,当然有好有坏
设为总体的一个简单随机样本,
,
分别称,
为k阶样本原点矩和k阶样本中心矩.
记
为什么能用矩估计?原理?
根据大数定理,当(
)时,
,
,所以当样本数据量到达一定数目时,就可以用样本的矩来估计总体的矩,从而估计一系列矩的函数。
定义:在应用中用样本矩来代替总体矩,得到的估计称为矩估计,
前提:未知参数可以使用总体矩来表示
核心:样本矩来代替总体矩
区别:不同的样本矩表达的效果不同
设,则
,称为
的一个矩估计
例1. 总体均值a,总体方差为,则
,
,
故未知参数的矩估计不唯一,那么那种估计是最好的?
低阶矩比高阶矩好
例2.总体,
则,故未知参数的矩估计不唯一
例3.总体,求
因为,
用代替EX,
代替
可以反解出结果。
例4.总体,EX不存在,所以未知参数的矩估计不存在
统计量与统计值(由样本表示具有样本的性质)

偏度系数/峰度系数/变异系数,对于一个总体是否服从正态分布,可以先计算其系数,若与正态分布的值相差不大,则可认为是正态分布
例5.(X,Y)协方差及相关系数的矩估计

用样本数据取估计总体的协方差和相关系数
广义矩估计
总而言之:矩估计即使用样本矩代替总体矩,至于准不准,需要后面的判断




(2)极大似然估计(MLE)
概率密度函数的两种形态:
a.当未知参数固定,就是概率函数
b.当随机变量取值固定,此时就是似然函数

原理:既然随机变量取值固定,那么这些变量取这些值的概率就应该为1,那么变化未知参数,使得概率密度取值最大,这个未知参数就是我们想要的。似然函数表达了在给定样本下,概率结构的变化
例1.标志重捕法


定义:

那么接下来就是求极值的问题了,此时的变量只有未知参数,所以一般而言是对未知参数求导
对于简单随机样本,若总体
,则
,
记,
定理:有指数族的自然形式,
的驻点在参数空间内部,则该驻点唯一,且为极大似然估计(这里需要继续看)

例1:


例2:

如果矩估计和极大似然都不可以做,那么用什么估计?
例3:



对于定数截尾,可以使用次序统计量的概率密度函数来进行判断,次序统计量是实际观察到的量
对于定时结尾如何判断?什么是实际观察到的量?
设为第i个产品的寿命,所以服从指数分布
则,故
为观测到的量
即为
则
设有r个T之前失效,n-r个T之后失效,则似然函数为
求解即可,同时这也是既非离散也非连续的情况
例4:



总而言之,MLE就是在样本取值固定的情况下,使得取这些值的概率最大,因为此时只有未知参数是不确定的,所以就成了对未知参数求导,求得未知参数的极值。







1.3 点估计的评价标准
(1)无偏性
对未知参数的估计是由统计量来表示的,统计量是随机变量,故存在均值和方差

含义:没有系统偏差

尽管某一次可能会吃亏,但长远来看是相当的
总体的均值为a,总体方差为,
——>修正为
,
样本n阶原点矩是总体n阶原点矩的无偏估计,如果未知参数等于总体n阶原点矩,那么就是未知参数的无偏估计
样本n阶中点矩通常不是总体n阶中点矩的无偏估计
在独立同分布的条件下,k阶原点矩是易求的,如何求k阶中心矩?
以三阶中心距为例:
,
,标准化:
令
则化简为:
PS:
最终:
可以展开,单阶项可以通过刚才的标准化归为0
可以修正为:
X i.i.d ,EX=0,(需要看看)
例1:总体
两个都是无偏估计,那么谁最好?这时比方差,一般低阶矩的方差小
例2:gamma分布的可加性

例3 总体,求
和
对于两点分布:
,
,由于
,所以无偏
,由于
,系统偏小
和的期望是无条件的

注意n3服从二项分布
(2)有效性
如果的波动程度小,那么一次取样就越接近均值

一般低阶矩更加有效
(3)大样本性质
小样本性质:n固定
大样本性质:n在变化,()
a.渐进无偏估计

b.相合性


正态分布正交变换的性质

弱大数定律的连续函数形式

![]()

柯尔莫哥洛夫强大数定律:
均方相合估计:


c.相合渐进正态估计

如何证明?
若n个独立同分布变量的和,则使用弱大数定律,如辛钦大数定律
若不是n个独立同分布变量的和,则使用切比雪夫不等式,概率计算公式
1.4 一致最小方差无偏估计(UMVUE)
是无偏估计就是可估的,不是无偏估计就是不可估的
无偏估计不是总是存在的


均方误差:,兼顾方差和均值的一种衡量标准
TIPS:为一个常数,故
使这两部分都小的情况很难找到,那么退而求其次,使得后一项达到0,即为在无偏估计的情况下



![]()
一致最小均方误差估计通常很难找到,那么退而求其次,使得后一项达到0,即为在无偏估计的情况下,此时比较的标准只有方差:

因为后一项为0,所以只需要比较前一项即D
引理:

从引理中可以得到:
对于任意的的无偏估计
,若T为充分统计量,则
1)仍为
的无偏估计
2)若不是T的函数,则可以找到T的函数h(T),使h(T)为
的无偏估计,且方差不超过
综上UMVUE只需要在T的函数中寻找。
如何寻找一致最小方差无偏估计:
可估:
可估:
(1)Lehmann-Scheffe定理


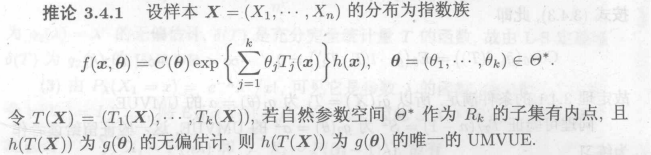
指数族的自然形式——>完全充分统计量
步骤:
先找充分完全统计量T
再找的无偏估计,设为
:
可以表达为T的函数,则直接使用
不是T的函数,则将其修正为T的函数,修正后函数直接使用,
那么怎么去找是
的无偏估计?
a.先求充分完全统计量的期望,方差,二阶原点矩,然后凑出待求变量
b.生成函数
c.直接用定义
例如:


如果充分完全统计量包括两个以上,那么只需是其中一个,那么就是T的函数




例1 :是T的函数

例2 :是T的函数


另一种解法:
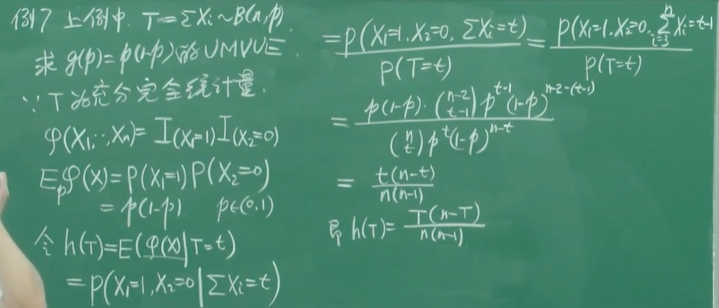
例3:找完全充分统计量的无偏估计


对于r.v. X,生成函数为:
对于泊松分布:
为完全充分统计量
因为
所以是
的无偏估计


例4:

另加:求的UMVUE
例5:
![]()

另外:求的UMVUE
T1与T2是独立的
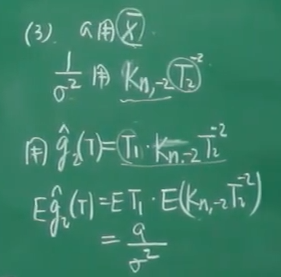

(2)零无偏估计法


为什么要选用充分统计量?因为包含了全部信息


1.5 Cramer-Rao不等式

达到C-R下界的一定是最小方差无偏估计,但满足C-R不等式的通常很少 ,一般来说C-R下界会偏小。

从总体中计算

(1)单参数C-R不等式

有了上面的正则条件才能证明,统计学的函数空间的投影理论?

指数族:未知参数*exp{未知参数与样本组合}*不含未知参数




Fisher信息函数:

(2)多参数的C-R不等式



效率和有效估计:








拉格朗日乘数法:(条件极值)



怎么求UMVUE:
a.L-S定理
b.零无偏估计
c.拉格朗日乘数法(约束条件是期望无偏)
2.多元函数求极值
极值:

最值:

无条件极值:

注:极值点存在于驻点和不可导的点
条件极值:

几种题目:有界区域:分为无条件极值和条件极值,所有极值比较大小即为最值
无条件极值求区域内部不包含边界,条件极值求边界,综合起来就是最值

矩阵的正定性:(二阶连续可导就是为了保证对称)




hassen矩阵求解极值:

3.期望和方差的性质
和的期望可以无条件拆开,乘积的期望需要独立才能拆开
4.线性空间
5.数理统计的线性空间描述
投影?
6.Be分布与Γ分布
指数分布和卡方分布是特殊形式的Γ分布
0-1区间的均匀分布是特殊的Be分布
https://zhuanlan.zhihu.com/p/69606875![]() https://zhuanlan.zhihu.com/p/69606875
https://zhuanlan.zhihu.com/p/69606875



这篇关于统计是一门艺术(点估计)的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!







