本文主要是介绍读书· 深入理解Java虚拟机,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
- 前言
- Java内存区域
- 运行时数据区
- 1.程序计数器
- 2.Java虚拟机栈
- 3.本地方法栈
- 4.Java堆
- 5.方法区
- 内存溢出和垃圾回收
- 1.内存溢出
- 2.垃圾回收
- 3.内存分配与回收策略
- 虚拟机类加载机制
- 1.加载
- 2.验证
- 3.准备
- 4.解析
- 5.初始化
前言
欢迎关注微信公众号“江湖喵的修炼秘籍”
撰文之前看到一段话,颇为喜欢,任性的写在这里:“入楼十七日,日日苦修,却修不到字词入心,只能眼睁睁看着它们溜走。我曾清醒过,也曾无来由的堕入黑甜梦乡,但它们总是不在,如果纸面上的它们是虚妄的,为何我能看见它们,如果它们是真实的,为何我不能记住它们。修行,到底是真实,还是虚妄,再上层楼,再上层楼,先前诸般愁,此时俱休。”–摘自《将夜》
我们所身处的,就是江湖。行走江湖,就离不开内功修炼,光靠三脚猫的功夫是不行的,需要内外兼修才有可能成为扫地僧一样的绝世高人。最近花了一些时间断断续续的读了周志明先生的《深入理解Java 虚拟机·JVM高级特性与最佳实践》第2版(该版本基于JDK1.7),结合官方的《JAVA虚拟机规范(Java SE 8版)》,总结一下自己的学习笔记和心得。
Java内存区域
越过虚拟机建起的高墙,窥探虚拟机内存管理的玄机。
运行时数据区
Java 虚拟机定义了几种程序运行时会使用到的数据区,从线程隔离性上分为两类:一类是于所有线程共享的数据区,包括方法区和堆,这两个区域会随着虚拟机的启动而创建,随着虚拟机的退出而销毁;另一类是线程隔离的,包括程序计数器(JAVA虚拟机规范中又叫PC寄存器),虚拟机栈和本地方法栈,这三个区域随着线程的启动而创建,随着线程的结束而销毁。
1.程序计数器
[1]Java 虚拟机的多线程是通过线程轮流切换并分配处理器执行时间的方式实现的,一个确定的时刻,一个处理器(对于多核处理器来说是一个内核)都只会执行一条线程的指令,因此,为了线程切换后能够恢复到正确的执行位置,每条线程都需要一个独立的计数器,各线程之间的计数器互不影响,独立存储[2]如果线程执行的是一个Java 方法,这个计数器记录的是正在执行的虚拟机字节码指令的地址,如果正在执行的是Native 方法,这个计数器的值则为空。[3]此内存区域是Java虚拟机规范中唯一一个没有规定任何OutOfMemoryError情况的区域。 --摘自《深入理解Java虚拟机》
思考一个问题,Java是如何实现多线程的?
面对这个问题,我们首先想到的答案是“继承Thread类,实现Runnable接口,实现Callable接口”,但原理是什么呢?
我们知道,一个处理器或一个内核同一时刻只会处理一个线程的指令,那么对于一个单核CPU要如何实现多线程呢?这就需要上述的[1]解释了,Java 虚拟机是通过快速切换线程并分配处理器执行时间实现的。比如A线程先向处理器发起一条指令,执行到一半时,B线程过来执行,且优先级高,此时处理器会将A挂起,执行B,当B执行完成后唤醒A继续执行。
由此我们引申出一个新的问题:
唤醒A 时如何确保A可以从上次中断的位置继续执行?
先看下面的代码[代码1]:
public class Test {public void add() {int a = 100;int b = 200;int c = a + b;}
}我们把它变编译成class文件,然后使用javap命令获取其字节码文件:
admindeMBP:auto-code-plugin nagsh$ javap -c Test.class
Compiled from "Test.java"
public class Test {public Test();Code:0: aload_01: invokespecial #1 // Method java/lang/Object."<init>":()V4: returnpublic void add();Code:0: bipush 1002: istore_13: sipush 2006: istore_27: iload_18: iload_29: iadd10: istore_311: return
}
这个字节码文反映了add方法的执行过程,类似于bipush的JVM指令在这里先不做阐述,将在后边的内容中具体解释,现在我们仅仅关注Code下的数字0-11,这些数字就是所谓的偏移地址,也就是[2]中的虚拟机字节码指令的地址。程序计数器就是用来存放这些数字的,当线程A被唤醒后,只要通过程序计数器就可以获取到中断的位置,继续执行。由于仅仅只是存放的值会发生变化,而不会随着程序的运行需要更大的空间,所以不会发生内存溢出的情况,因此程序计数器有[3]所说的特点。
什么是native方法呢?
native方法就是非Java的方法,比如可能是C 实现的,在字节码文件中并不会体现,所以native方法的计数器值是空的。比如System.currentTimeMillis();方法就是一个native方法,声明如下:
public static native long currentTimeMillis();
我们改造前边的代码,加入该方法的调用[代码2]:
public class Test {public void add() {int a = 100;int b = 200;int c = a + b;System.currentTimeMillis();}
}
再查看对应的字节码文件:
admindeMBP:auto-code-plugin nagsh$ javap -c Test.class
Compiled from "Test.java"
public class Test {public Test();Code:0: aload_01: invokespecial #1 // Method java/lang/Object."<init>":()V4: returnpublic void add();Code:0: bipush 1002: istore_13: sipush 2006: istore_27: iload_18: iload_29: iadd10: istore_311: invokestatic #2 // Method java/lang/System.currentTimeMillis:()J14: pop215: return
}
可以看到整个字节码文件中仅仅是多了方法调用的过程,对于currentTimeMillis方法的实现并未体现,程序计数器当然在执行的时候也不会记录偏移地址。
而native方法的多线程是如何实现的?答案是原生语言是怎么实现就是怎么实现,如果方法实现是C,那C是如何实现线程切换的,java的native方法就是如何实现线程切换的。
2.Java虚拟机栈
Java虚拟机栈也是线程私有的,每个方法在执行是都会创建一个栈帧用于存储局部变量表,操作数栈,动态链接,方法接口等信息。每一个方法调用的过程就对应这一个栈帧在虚拟机中入栈出栈的过程。 --摘自《深入理解Java虚拟机》
局部变量表
用于存储基本数据类型及对象的引用,基于下面的代码3,我们通过javap命令查看其局部变量表:
import java.util.HashMap;
import java.util.Map;public class Test {public void add() {byte a = 1;short b = 1;int c = 1;long d = 1L;float f = 1.0f;double g = 1.0d;boolean h = true;char i = '1';Map map = new HashMap();}
}
局部变量表:
admindeMBP:auto-code-plugin nagsh$ javap -l Test.class
Compiled from "Test.java"
public class Test {public Test();LineNumberTable:line 4: 0LocalVariableTable:Start Length Slot Name Signature0 5 0 this LTest;public void add();LineNumberTable:line 6: 0line 7: 2line 8: 4line 9: 6line 10: 9line 11: 12line 12: 15line 13: 18line 14: 22line 15: 31LocalVariableTable:Start Length Slot Name Signature0 32 0 this LTest;2 30 1 a B4 28 2 b S6 26 3 c I9 23 4 d J12 20 6 f F15 17 7 g D18 14 9 h Z22 10 10 i C31 1 11 map Ljava/util/Map;
}
Signature表示变量的类型,Name表示变量的名称,Slot表示占有的卡槽位。add方法LocalVariableTable第一行表示的是方法自身的引用,第二行表示变量a类型是byte,占有的卡槽位是1。需要注意的是long和double占用两个卡槽位,分别是4-5和7-8。关于其他列的含义,我们通过查看前边代码1的局部变量表来解释:
admindeMBP:auto-code-plugin nagsh$ javap -c -l Test.class
Compiled from "Test.java"
public class Test {public Test();Code:0: aload_01: invokespecial #1 // Method java/lang/Object."<init>":()V4: returnLineNumberTable:line 1: 0LocalVariableTable:Start Length Slot Name Signature0 5 0 this LTest;public void add();Code:0: bipush 1002: istore_13: sipush 2006: istore_27: iload_18: iload_29: iadd10: istore_311: return//左侧的数字对应着代码的行号,右侧的数字对应的在字节码中的偏移位置LineNumberTable:line 3: 0line 4: 3line 5: 7line 6: 11LocalVariableTable://Start和Start+Length表示变量在字节码中的生命周期,如this 对象从偏移位置0开始直到方法结束,变量从偏移位置3开始直到3+9方法结束Start Length Slot Name Signature0 12 0 this LTest;3 9 1 a I7 5 2 b I11 1 3 c I
}综上我们可以看出局部变量表中存储的是变量的偏移地址起始位置,生命周期,卡槽位,变量名称,变量类型。
行号表中存储了代码行对应字节码文件偏移地址的映射关系。
操作数栈
我们仍然使用代码1的字节码文件和局部变量表来了解操作数栈,前面提到方法的执行就是栈帧入栈出栈的过程,下面我们重点关注add方法的字节码文件,每一步的解释我会写在后面
admindeMBP:auto-code-plugin nagsh$ javap -c -l Test.class
Compiled from "Test.java"
public class Test {public Test();Code:0: aload_01: invokespecial #1 // Method java/lang/Object."<init>":()V4: returnLineNumberTable:line 1: 0LocalVariableTable:Start Length Slot Name Signature0 5 0 this LTest;public void add();Code:0: bipush 100 //将数字100压入操作数栈栈顶2: istore_1 //将操作数栈栈顶元素出栈并存储到局部变量表solt为1卡槽3: sipush 200 //将数字200压入操作数栈栈顶6: istore_2 //将操作数栈栈顶元素出栈并存储到局部变量表solt为2的卡槽7: iload_1 //将局部变量表卡槽1的变量的值压入操作数栈8: iload_2 //将局部变量表卡槽2的变量的值压入操作数栈9: iadd //对栈内数据执行加法操作10: istore_3 //将结果出栈,写入局部变量表solt为3的卡槽11: returnLineNumberTable:line 3: 0line 4: 3line 5: 7line 6: 11LocalVariableTable:Start Length Slot Name Signature0 12 0 this LTest;3 9 1 a I7 5 2 b I11 1 3 c I
}Java虚拟机栈可能发生两种类型的内存溢出,一种是StackOverfolwError,比如代码中有死循环,导致栈的深度过大,会出现栈内存溢出;另外一种是OutOfMemoryError,如果虚拟机栈在动态扩展时无法申请到足够的内存,就会出现内存溢出。
3.本地方法栈
本地方法栈主要是为native 方法服务的,这里暂时不做过多的阐述
前面三种都是线程私有的内存区,后面讲的两种是所有线程共享的区域:堆和方法区
4.Java堆
Java堆会在虚拟机启动是创建,Java堆用来存放对象的实例。Java堆可以处于物理上不连续的空间中,只要逻辑上连续即可。关于Java堆我们主要需要了解的就是GC机制,这一点我们将在后边重点讨论。
同虚拟机栈无法扩展时OutOfMemoryError一样,如果java堆在扩展时申请不到足够的内存,也会OutOfMemoryError。
5.方法区
方法区用于存放已被虚拟机加载的类信息,常量,静态变量,即时编译器编译后的代码等数据。 --摘自《深入理解Java虚拟机》
这句话写的很笼统,需要我们更深入的了解一下。
思考一个问题:字符串常量池,class文件常量池和运行时常量池有什么区别?
字符串常量池
String字符串类型是java中最常用的引用数据类型,为了提供性能和减少内存开销,开辟了一个字符串常量池,创建字符串常量时,首先校验字符串常量池中是否已存在该字符串,若存在,直接返回该实例,若不存在,实例化该字符串放入池中。该方式的实现基础是:字符串是不可变的,因此不必担心数据冲突。
关于字符串常量池我们可以通过一些代码进一步强化理解:
代码4
public class Test {public static void main(String args[]) {String a = "Hello";String b = "Hello";System.out.println(a == b); //true}
}
我们知道String类的==比较的是值在内存中的地址是否相同,通过上面的代码可以知道a和b 指向了同一个字符串。
代码5
public class Test {public static void main(String args[]) {String a = "Hello";String b = "Hello";String c = new String("Hello");String d = new String("Hello");System.out.println(a == b); //trueSystem.out.println(a == c); //falseSystem.out.println(d == c); //falseSystem.out.println(d.intern() == c.intern()); //true}
}
为什么呢?
因为通过等号直接赋值的方式字符串将会被创建在常量池中,通过new的方式创建的对象存储在堆中,intern() 方法获取到的是c和d在常量池中的引用值,上述代码在内存中存储的方式大致如下图:
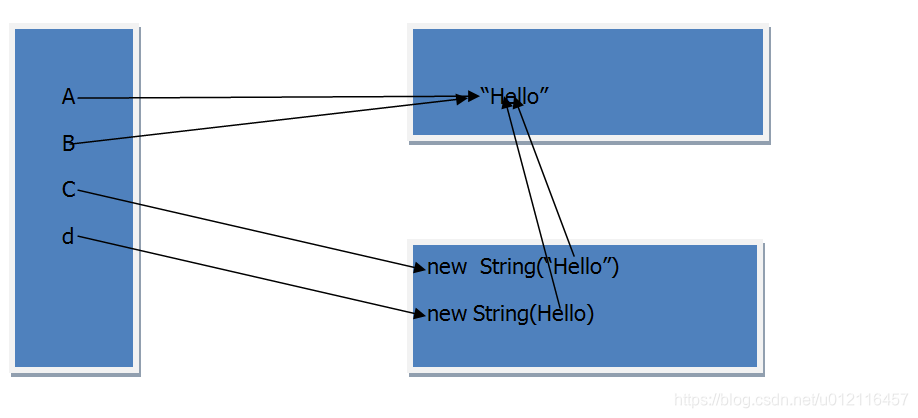
再看一行代码:
String a = new String("Hello");
分析这行代码会创建几个对象?
1.判断常量池中是否有“Hello”字面量
若有,则返回对应的引用实例
若没有,创建该引用对象
2.在堆中创建一个new String(“Hello”)对象
3.将对象的引用返回给a
所以,如果字符串常量池中已有该字面量,则创建一个对象,若没有,则创建两个个对象。以及一个对象的引用。
class文件常量池
我们先来了解一下class文件中都包含哪些信息?
虚拟机规范第四章给出class文件的格式如下图:

以下面的代码为例代码6:
public class Test {private String a = "Hello";public String getA(){return a + " World";}
}
编译后的class文件如下:
cafe babe 0000 0034 0024 0a00 0a00 1808
0019 0900 0900 1a07 001b 0a00 0400 180a
0004 001c 0800 1d0a 0004 001e 0700 1f07
0020 0100 0161 0100 124c 6a61 7661 2f6c
616e 672f 5374 7269 6e67 3b01 0006 3c69
6e69 743e 0100 0328 2956 0100 0443 6f64
6501 000f 4c69 6e65 4e75 6d62 6572 5461
626c 6501 0012 4c6f 6361 6c56 6172 6961
626c 6554 6162 6c65 0100 0474 6869 7301
0006 4c54 6573 743b 0100 0467 6574 4101
0014 2829 4c6a 6176 612f 6c61 6e67 2f53
7472 696e 673b 0100 0a53 6f75 7263 6546
696c 6501 0009 5465 7374 2e6a 6176 610c
000d 000e 0100 0548 656c 6c6f 0c00 0b00
0c01 0017 6a61 7661 2f6c 616e 672f 5374
7269 6e67 4275 696c 6465 720c 0021 0022
0100 0620 576f 726c 640c 0023 0015 0100
0454 6573 7401 0010 6a61 7661 2f6c 616e
672f 4f62 6a65 6374 0100 0661 7070 656e
6401 002d 284c 6a61 7661 2f6c 616e 672f
5374 7269 6e67 3b29 4c6a 6176 612f 6c61
6e67 2f53 7472 696e 6742 7569 6c64 6572
3b01 0008 746f 5374 7269 6e67 0021 0009
000a 0000 0001 0002 000b 000c 0000 0002
0001 000d 000e 0001 000f 0000 0039 0002
0001 0000 000b 2ab7 0001 2a12 02b5 0003
b100 0000 0200 1000 0000 0a00 0200 0000
0100 0400 0200 1100 0000 0c00 0100 0000
0b00 1200 1300 0000 0100 1400 1500 0100
0f00 0000 4100 0200 0100 0000 17bb 0004
59b7 0005 2ab4 0003 b600 0612 07b6 0006
b600 08b0 0000 0002 0010 0000 0006 0001
0000 0004 0011 0000 000c 0001 0000 0017
0012 0013 0000 0001 0016 0000 0002 0017
class文件以16进制存储,其中前四个字节0xcafe babe为魔数,用于确定这个文件是否是一个能被虚拟机接收的class文件。
紧接这两个字节0x0000表示次版本号,0x0034表示主版本号,转化成十进制为52。
版本号后跟着的就是常量池计数器,constant_pool_count的值等于常量池成员表中的成员数+1(摘自–java虚拟机规范),0x0024对应十进制为36,所以常量池中有35项常量。
常量池计数器后紧跟着的就是常量池。常量池数据的分析比较繁琐,我们直接借助javap命令进行分析,结果如下:
admindeMBP:auto-code-plugin nagsh$ javap -verbose Test.class
Classfile /Users/nagsh/Documents/codes/code0920/code2/auto-code-plugin/out/production/auto-code-plugin/Test.classLast modified 2018-11-4; size 544 bytesMD5 checksum 35d70281f7a07d3f423f049f7c5757aeCompiled from "Test.java"
public class Testminor version: 0major version: 52flags: ACC_PUBLIC, ACC_SUPER
Constant pool:#1 = Methodref #10.#24 // java/lang/Object."<init>":()V#2 = String #25 // Hello#3 = Fieldref #9.#26 // Test.a:Ljava/lang/String;#4 = Class #27 // java/lang/StringBuilder#5 = Methodref #4.#24 // java/lang/StringBuilder."<init>":()V#6 = Methodref #4.#28 // java/lang/StringBuilder.append:(Ljava/lang/String;)Ljava/lang/StringBuilder;#7 = String #29 // World#8 = Methodref #4.#30 // java/lang/StringBuilder.toString:()Ljava/lang/String;#9 = Class #31 // Test#10 = Class #32 // java/lang/Object#11 = Utf8 a#12 = Utf8 Ljava/lang/String;#13 = Utf8 <init>#14 = Utf8 ()V#15 = Utf8 Code#16 = Utf8 LineNumberTable#17 = Utf8 LocalVariableTable#18 = Utf8 this#19 = Utf8 LTest;#20 = Utf8 getA#21 = Utf8 ()Ljava/lang/String;#22 = Utf8 SourceFile#23 = Utf8 Test.java#24 = NameAndType #13:#14 // "<init>":()V#25 = Utf8 Hello#26 = NameAndType #11:#12 // a:Ljava/lang/String;#27 = Utf8 java/lang/StringBuilder#28 = NameAndType #33:#34 // append:(Ljava/lang/String;)Ljava/lang/StringBuilder;#29 = Utf8 World#30 = NameAndType #35:#21 // toString:()Ljava/lang/String;#31 = Utf8 Test#32 = Utf8 java/lang/Object#33 = Utf8 append#34 = Utf8 (Ljava/lang/String;)Ljava/lang/StringBuilder;#35 = Utf8 toString
{public Test();descriptor: ()Vflags: ACC_PUBLICCode:stack=2, locals=1, args_size=10: aload_01: invokespecial #1 // Method java/lang/Object."<init>":()V4: aload_05: ldc #2 // String Hello7: putfield #3 // Field a:Ljava/lang/String;10: returnLineNumberTable:line 1: 0line 2: 4LocalVariableTable:Start Length Slot Name Signature0 11 0 this LTest;public java.lang.String getA();descriptor: ()Ljava/lang/String;flags: ACC_PUBLICCode:stack=2, locals=1, args_size=10: new #4 // class java/lang/StringBuilder3: dup4: invokespecial #5 // Method java/lang/StringBuilder."<init>":()V7: aload_08: getfield #3 // Field a:Ljava/lang/String;11: invokevirtual #6 // Method java/lang/StringBuilder.append:(Ljava/lang/String;)Ljava/lang/StringBuilder;14: ldc #7 // String World16: invokevirtual #6 // Method java/lang/StringBuilder.append:(Ljava/lang/String;)Ljava/lang/StringBuilder;19: invokevirtual #8 // Method java/lang/StringBuilder.toString:()Ljava/lang/String;22: areturnLineNumberTable:line 4: 0LocalVariableTable:Start Length Slot Name Signature0 23 0 this LTest;
}
SourceFile: "Test.java"Constant pool中1-35的内容及class文件常量池的内容,我们可以得出下面的结论:
class文件常量池主要存放两大类常量:字面量和符号引用,字面量如文本字符串,声明为final的常量值;符号引用包括:
类和接口的全限定名
字段的名称和描述符
方法的名称和描述符 --摘自《深入理解Java虚拟机》第六章
运行时常量池
Java虚拟机为每个类型都维护着一个常量池,当类或接口创建时,它的二进制表示中的常量池表被用来构造运行是常量池。运行时常量池中的引用最初都是符号引用。…字符串常量指向String类实例的引用,它来自接口或类二进制表示中的CONSTATT_STRING_INFO结构…java语言规定相同的字符串常量必须指向同一个String类实例,如果某String实例包含的unicode码点序列与CONSTATT_STRING_INFO序列相同,而之前又曾在该实例上调用过String.intern方法,那么此次字符串实例获取的结果将是一个指向相同实例的引用。否则会创建一个新的实例,字符串常量的获取指向新实例的引用,最后新String实例的intern方法被虚拟机自动调用。–摘自《JAVA虚拟机规范 8版》
简单的说,就是JVM在加载时会将class常量池中的存放到运行时常量池中,如果是字符串也会和字符串常量池中的值比较,如果已经存在,直接指向该引用,保证字符串常量池引用的字符串与全局字符串常量池的引用是一致的。
到这里,有两个疑问:
1.字符串常量池到底在哪?
jdk1.7之前,Hotspot虚拟机将字符串常量池置于永久代中,1.7中已经将其从永久代移除,转移到了堆中,1.8取消了永久代,方法区改用native memory实现。
2.字符串常量池是否包含在运行时常量池中?
小编认为是没有的,毕竟字符串常量池已经移到了堆中,但至少根据官方文档,运行是常量池是位于方法区。(如我理解有误请指正)
现在来总结一下方法区中有什么?

内存溢出和垃圾回收
1.内存溢出
Java堆溢出
java堆是用来存储对象实例的,只要不断创建对象,并且保证对象一直被引用就可以避免垃圾回收机制清除这些对象,从而内存溢出。
写个简单的例子模拟一下:
import java.util.ArrayList;
import java.util.HashMap;
import java.util.List;
import java.util.Map;// 虚拟机参数:-Xms20m -Xmx20m -XX:+HeapDumpOnOutOfMemoryError
public class Test {public static void main(String args[]){List<Map> list = new ArrayList<>();while(true){list.add(new HashMap());}}
}
这个方法会不断创建对象添加到list中,运行前将堆大小设置为20m。点击运行后生成了dump文件,使用java visualVM进行分析(文件–装入),首先从摘要界面的线程信息中可以定位到导致异常的类和方法:

从类界面可以看到HashMap实例数可能异常:

当然这只是一个很简单的模拟的例子,因为创建的这些map一直被list引用,所以很明显是一个内存溢出的问题。
下面尝试写了一个模拟内存泄漏的代码:
import java.util.*;// -Xms20m -Xmx20m -XX:+HeapDumpOnOutOfMemoryError
public class Test {List<Map> list = new ArrayList<>();public void run1(){for (int i=0;i<300000;i++) {list.add(new HashMap());}System.out.println(list.size());}public void run2(){List<Map> list2 = new ArrayList<>();for (int i=0;i<300000;i++) {list2.add(new HashMap());}System.out.println(list2.size());}public static void main(String args[]){Test t = new Test();t.run1();t.run2();}
}在这个内存设置下,run1方法可以正常执行,run2方法执行是内存溢出。可以看到,list对象其实在run1方法中使用完以后就没有用了,但是因为list是一个全局变量,和对象t的生命周期一样长,所以在执行run2方法是,list的内存依旧没有释放。
将list改为run1方法的局部变量或者在run1中使用完后释放内存。
public void run1(){List<Map> list = new ArrayList<>();for (int i=0;i<300000;i++) {list.add(new HashMap());}System.out.println(list.size());}
或者:
public void run1(){for (int i=0;i<300000;i++) {list.add(new HashMap());}System.out.println(list.size());list = new ArrayList<>();}
栈内存溢出
大家都知道栈的结构是一个筒型的,栈内存溢出往往是栈深过大,我们可以通递归调用来模拟栈内存溢出。
// -Xss256K
// -Xss256K
public class Test {private int width = 0;public int getWidth () {if (width == Integer.MAX_VALUE) {return width;}++width;return getWidth();}public static void main(String args[]){Test t = new Test();try {t.getWidth();} catch (Error e) {System.out.println("栈深度为:"+t.width);e.printStackTrace();}}
}
虚拟机参数设置为-Xss256K,指定线程的栈大小为256K
执行结果:
java.lang.StackOverflowErrorat Test.getWidth(Test.java:9)
栈深度为:1899at Test.getWidth(Test.java:9)
需要注意的是,代码中catch的是Error 而不是Exception,因为这不属于程序可以处理的异常,而是虚拟机错误,所以需要用Error或者其父类Throwable类。
怀着好奇心,继续想一个问题:为什么递归方法会栈溢出呢?
看一下字节码文件,由于篇幅问题,只贴出getWidth方法:
public int getWidth();Code:0: aload_01: getfield #2 // Field width:I4: ldc #4 // int 21474836476: if_icmpne 149: aload_010: getfield #2 // Field width:I13: ireturn14: aload_015: dup16: getfield #2 // Field width:I19: iconst_120: iadd21: putfield #2 // Field width:I24: aload_025: invokevirtual #5 // Method getWidth:()I28: ireturn重点关注24和25两行就可以了,24行将slot0的值入栈,25行调用方法getWidth,在被调用的方法里同样是做入栈和方法调用,而且在最后return之前一直没有出栈,一直往操作数栈中压入数据,最终当然会栈内存溢出。
方法区溢出
在1.8之前,方法区是使用永久代实现的,而在1.8中已经将永久代溢出,用元空间去实现方法区,至于原因主要是两点
1.为融合HotSpot JVM与 JRockit VM而做出的努力,因为JRockit没有永久代,不需要配置永久代。
2.由于永久代内存经常不够用或发生内存泄露,爆出异常java.lang.OutOfMemoryError: PermGen
而元空间的大小与本机内存相关
2.垃圾回收
虚拟机进行GC的时候,必须先搞清楚一件事情,就是识别哪些对象是可以回收的,哪些对象是不能回收的,也就是需要算法来判断对象是否存活。
对象是否存活算法
一般来说,主要是两种算法 引用计数法和可达性分析算法
引用计数法:就是给每个对象添加一个引用计数器,每当被引用一次,计数器就+1,引用失效后,计数器减-1,当计数器值为0时,表示该对象已“死”,可以被回收。
可达性分析算法:这种算法类似一棵树,根节点叫GC Root,从这个节点向下搜索某一个对象的路径叫做引用链,当一个对象与GC root之前没有引用链时,就可标记这个对象可以被回收
而像主流的虚拟机比如Hotspot使用的都是可达性分析算法
垃圾收集算法
1.标记-清除算法
标记清除算法如下图,执行过程是首先标记这个对象可以被回收,然后在标记完成后统一回收。缺点就是会产生大量的内存碎片,当需要分配比较大的对象时找不到足够的空间而提前触发下一次GC.

2.标记-整理算法
标记-整理算法是在标记清除算法的基础上发展起来的,如下图,标记过程与标记-清除算法一致,但后续步骤不是直接回收,而是进行整理,将存活对象移动到一端,然后清除掉边界意外的内存

3.复制算法
复制算法的原理是将内存分成大小相等的两块,每次只使用其中的一块,当内存用完了,将存活的对象统一转移到另一块,并清除这部分的内存,但缺点是造成一般的内存浪费。

算法选择
新生代98%的对象都是朝生夕死的,所以现在的商业虚拟机都是使用复制算法进行新生代的垃圾回收,不过并不是1:1的分配,而是分成了一个Eden区和两个Survivor区,比例是8:1:1,每次只使用Eden区和其中一块Survivor区,所以只有10%的空间浪费。具体的回收策略会在后边列出。
老年代相对与新生代来说对象存活率要高,并不适合再使用复制算法,而是使用标记整理算法。
不同的收集器使用的算法不同,具体各种虚拟机的对比在本文暂不列举,有兴趣的童鞋可以去看看书上的这块内容。
3.内存分配与回收策略
1.对象优先在Eden区分配
大多数情况下,对象将在新生代分配:
/*** 虚拟机参数-Xms20m -Xmx20m -Xmn10m -XX:+PrintGCDetails* 堆内存:20M 不可扩展* 新生代:10M 默认比例8:1:1* 老年代:10M*/
public class Test {static int _1MB = 1024*1024;public static void main(String args[]) {byte[] t1 = new byte[_1MB*2];byte[] t2 = new byte[_1MB*3];}
}
查看GC日志:
HeapPSYoungGen total 9216K, used 7138K [0x00000007bf600000, 0x00000007c0000000, 0x00000007c0000000)eden space 8192K, 87% used [0x00000007bf600000,0x00000007bfcf8858,0x00000007bfe00000)from space 1024K, 0% used [0x00000007bff00000,0x00000007bff00000,0x00000007c0000000)to space 1024K, 0% used [0x00000007bfe00000,0x00000007bfe00000,0x00000007bff00000)ParOldGen total 10240K, used 0K [0x00000007bec00000, 0x00000007bf600000, 0x00000007bf600000)object space 10240K, 0% used [0x00000007bec00000,0x00000007bec00000,0x00000007bf600000)Metaspace used 3192K, capacity 4496K, committed 4864K, reserved 1056768Kclass space used 354K, capacity 388K, committed 512K, reserved 1048576K
PSYoungGen新生代分为eden from 和to 三部分,比例是8:1:1,新生代可使用空间为9216K(eden+from) ,在代码中我们创建了一个2M内存的对象,一个3M内存的对象,直接分配在了eden区,而老年代使用率为0.
2.大对象直接在老年代分配
虚拟机提供了一个-XX:PretenureSizeThresold参数,大于这个参数的对象将直接在老年代分配,这样做的目的是避免新生代发生大量的内存复制
-XX:PretenureSizeThresold参数只对serial和ParNew两款收集器有效,Paraller Scavange收集器不认识这个参数 --摘自《深入理解Java虚拟机》
笔者针对这两段话做了几个实验。
首先打印一下虚拟机的参数,查看虚拟机使用的收集器。
admindeMBP:auto-code-plugin nagsh$ java -XX:+PrintCommandLineFlags -version
-XX:InitialHeapSize=268435456 -XX:MaxHeapSize=4294967296 -XX:+PrintCommandLineFlags -XX:+UseCompressedClassPointers -XX:+UseCompressedOops -XX:+UseParallelGC
java version "1.8.0_181"
Java(TM) SE Runtime Environment (build 1.8.0_181-b13)
Java HotSpot(TM) 64-Bit Server VM (build 25.181-b13, mixed mode)
参数-XX:+UseParallelGC表明使用的收集器为并行收集器,这是一个新生代收集器,即上文中的不认识-XX:PretenureSizeThresold参数的Paraller Scavange收集器。
先看实验一:
/*** 虚拟机参数Xms20m -Xmx20m -Xmn10m -XX:+PrintGCDetails -XX:PretenureSizeThreshold=4* 堆内存:20M 不可扩展* 新生代:10M 默认比例8:1:1* 老年代:10M* -XX:PretenureSizeThresold=4*/
public class Test {static int _1MB = 1024*1024;public static void main(String args[]) {byte[] t1 = new byte[_1MB*5];}
}
结果为:
HeapPSYoungGen total 9216K, used 7130K [0x00000007bf600000, 0x00000007c0000000, 0x00000007c0000000)eden space 8192K, 87% used [0x00000007bf600000,0x00000007bfcf6838,0x00000007bfe00000)from space 1024K, 0% used [0x00000007bff00000,0x00000007bff00000,0x00000007c0000000)to space 1024K, 0% used [0x00000007bfe00000,0x00000007bfe00000,0x00000007bff00000)ParOldGen total 10240K, used 0K [0x00000007bec00000, 0x00000007bf600000, 0x00000007bf600000)object space 10240K, 0% used [0x00000007bec00000,0x00000007bec00000,0x00000007bf600000)Metaspace used 3190K, capacity 4496K, committed 4864K, reserved 1056768Kclass space used 354K, capacity 388K, committed 512K, reserved 1048576K
虚拟机参数我们设置为了-XX:PretenureSizeThresold=4 ,但是在代码中我们创建了一个大小为5M的对象,其并没有分配在来年代中,而是在eden区中,所以该参数对Paraller收集器确实无效。
下面是第二个实验:
/*** 虚拟机参数-Xms20m -Xmx20m -Xmn10m -XX:+PrintGCDetails* 堆内存:20M 不可扩展* 新生代:10M 默认比例8:1:1* 老年代:10M*/
public class Test {static int _1MB = 1024*1024;public static void main(String args[]) {byte[] t1 = new byte[_1MB*2];byte[] t2 = new byte[_1MB*3];byte[] t3 = new byte[_1MB*2];byte[] t4 = new byte[_1MB*2];}
}
运行结果如下:
[GC (Allocation Failure) [PSYoungGen: 6965K->592K(9216K)] 6965K->5720K(19456K), 0.0040655 secs] [Times: user=0.03 sys=0.01, real=0.01 secs]
[Full GC (Ergonomics) [PSYoungGen: 592K->0K(9216K)] [ParOldGen: 5128K->5514K(10240K)] 5720K->5514K(19456K), [Metaspace: 3174K->3174K(1056768K)], 0.0046981 secs] [Times: user=0.02 sys=0.00, real=0.00 secs]
HeapPSYoungGen total 9216K, used 4418K [0x00000007bf600000, 0x00000007c0000000, 0x00000007c0000000)eden space 8192K, 53% used [0x00000007bf600000,0x00000007bfa50930,0x00000007bfe00000)from space 1024K, 0% used [0x00000007bfe00000,0x00000007bfe00000,0x00000007bff00000)to space 1024K, 0% used [0x00000007bff00000,0x00000007bff00000,0x00000007c0000000)ParOldGen total 10240K, used 5514K [0x00000007bec00000, 0x00000007bf600000, 0x00000007bf600000)object space 10240K, 53% used [0x00000007bec00000,0x00000007bf162be8,0x00000007bf600000)Metaspace used 3192K, capacity 4496K, committed 4864K, reserved 1056768Kclass space used 354K, capacity 388K, committed 512K, reserved 1048576K
其实在添加t3对象的时候新生代就已经内存不足了,然后进行了一次新生代GC(Minor GC),但t1和t2对象都不可以被回收,且to space的大小只有1M ,不足以存放,提前转移到了老年代。
分析日志我们可以知道,minor GC的原因是Allocation Failure,是创建对象时向新生代申请空间,空间不足导致的GC,full GC的原因是Ergonomics,是因为开启了UseAdaptiveSizePolicy,jvm自己进行自适应调整引发的full gc.
接下来看最神奇的第三个实验:
/*** 虚拟机参数-Xms20m -Xmx20m -Xmn10m -XX:+PrintGCDetails* 堆内存:20M 不可扩展* 新生代:10M 默认比例8:1:1* 老年代:10M*/
public class Test {static int _1MB = 1024*1024;public static void main(String args[]) {byte[] t1 = new byte[_1MB*2];byte[] t2 = new byte[_1MB*3];byte[] t3 = new byte[_1MB*4];}
}
运行结果:
HeapPSYoungGen total 9216K, used 7334K [0x00000007bf600000, 0x00000007c0000000, 0x00000007c0000000)eden space 8192K, 89% used [0x00000007bf600000,0x00000007bfd29848,0x00000007bfe00000)from space 1024K, 0% used [0x00000007bff00000,0x00000007bff00000,0x00000007c0000000)to space 1024K, 0% used [0x00000007bfe00000,0x00000007bfe00000,0x00000007bff00000)ParOldGen total 10240K, used 4096K [0x00000007bec00000, 0x00000007bf600000, 0x00000007bf600000)object space 10240K, 40% used [0x00000007bec00000,0x00000007bf000010,0x00000007bf600000)Metaspace used 3268K, capacity 4496K, committed 4864K, reserved 1056768Kclass space used 359K, capacity 388K, committed 512K, reserved 1048576K
与实验2不同的是实验2是在最后创建两个大小均为2M的对象,实验三是创建一个4M的对象,实验2引发了GC,而实验3直接将第三个对象创建在了老年代。
3.长期存活的对象进入老年代
虚拟机给每个对象定义了一个年龄,每当熬过一次minor GC,年龄就增加一岁,增加到一定程度(默认是15)就会晋升到老年代,这个年龄阈值可以通过-XX:MaxTenuringThreshold设置,该参数只在串行GC时才管用。
4.动态对象年龄判断
如果在survivor空间中相同年龄的所有对象大小的总和大于survivor空间的一半,年龄大于或等于该年龄的对象就可以直接进入老年代,无需等到MaxTenuringThreshold所要求的年龄。
5.空间分配担保
在发生Minor GC之前,虚拟机会下检查老年代的最大可用的连续空间是否大于新生代所有对象的总空间,如果这个条件成立,那么Minor GC可以确保是安全的。如果不成立,则虚拟机会查看HandlePromotionFailure设置只是否允许担保失败,如果允许,会继续检查老年代最大可用的连续空间是否大于历次晋升到老年队对象的平均大小,如果大于,将尝试进行一次MinorGC。如果设置为不允许冒险,则改为进行一次full GC. --摘自《深入理解Java虚拟机》
从这段话我们可以总结出一个结论,什么时候进行Full GC?
1.老年代最大可用的连续空间小于MinorGC时所有晋升新生代对象的总空间且HandlePromotionFailure设置为不允许担保失败
2.老年代最大可以连续空间小于minor GC时,所有新生代对象的总空间且小于历次晋升到老年代对象的平均大小
3.老年代最大可用连续空间小于minor GC时所有新生代对象的总空间,但大于历次晋升到老年代对象的平均大小,且允许冒险,会尝试进行minor GC, 若失败,会进行Full GC.
虚拟机类加载机制
虚拟机动态的 加载 链接和初始化类和接口。加载是根据特定名称查找类或接口的二进制表示,并由该二进制表示创建类或接口的过程。链接是为了让类或接口可以被Java虚拟机执行,将其并入虚拟机运行时状态的过程。类或接口的初始化是执行类或接口的初始化方法。 --摘自《Java虚拟机规范 8版》
1.加载
类加载分为两种,一种是预加载,一种是运行时加载。
预加载是指在虚拟机启动时把一些常用的类预先加载进来,可通过将虚拟机参数设置为-XX:+TraceClassLoading,然后创建一个只有空的main方法的类运行,会打出如下内容,截取部分如下:
[Opened /Library/Java/JavaVirtualMachines/jdk1.8.0_181.jdk/Contents/Home/jre/lib/rt.jar]
[Loaded java.lang.Object from /Library/Java/JavaVirtualMachines/jdk1.8.0_181.jdk/Contents/Home/jre/lib/rt.jar]
[Loaded java.io.Serializable from /Library/Java/JavaVirtualMachines/jdk1.8.0_181.jdk/Contents/Home/jre/lib/rt.jar]
[Loaded java.lang.Comparable from /Library/Java/JavaVirtualMachines/jdk1.8.0_181.jdk/Contents/Home/jre/lib/rt.jar]
[Loaded java.lang.CharSequence from /Library/Java/JavaVirtualMachines/jdk1.8.0_181.jdk/Contents/Home/jre/lib/rt.jar]
[Loaded java.lang.String from /Library/Java/JavaVirtualMachines/jdk1.8.0_181.jdk/Contents/Home/jre/lib/rt.jar]
[Loaded java.lang.reflect.AnnotatedElement from /Library/Java/JavaVirtualMachines/jdk1.8.0_181.jdk/Contents/Home/jre/lib/rt.jar]
[Loaded java.lang.reflect.GenericDeclaration from /Library/Java/JavaVirtualMachines/jdk1.8.0_181.jdk/Contents/Home/jre/lib/rt.jar]
[Loaded java.lang.reflect.Type from /Library/Java/JavaVirtualMachines/jdk1.8.0_181.jdk/Contents/Home/jre/lib/rt.jar]`在这里插入代码片`
...
如下面的代码:
public class Test {static class MyObj {}static class MyObj2 {}public static void main(String args[]) {MyObj o = new MyObj();}
}
运行时只会加载MyObj类,而不会加载MyObj2类。
[Loaded Test$MyObj from file:/Users/Documents/codes/auto-code-plugin/out/production/auto-code-plugin/]
在加载阶段,虚拟机主要做三件事:
1.通过一个类的全限定名获取定义此类的二进制字节流
2.将这个字节流所代表的静态存储结构转换为方法区的运行时数据结构
3.在内存中生成一个代表这个类的java.lang.Class对象,作为方法区这个类的各种数据的访问入口
第1点中的获取二进制字节流,可以是从jar包,war包中获取,也可以从网络上获取,Jsp文件中获取等等,并没有严格的限制
2.验证
连接阶段的第一步,这一阶段的目的是为了确保.class文件的字节流中包含的信息符合当前虚拟机的要求,并且不会危害虚拟机自身的安全。
验证阶段将做以下几个工作,:
1、文件格式验证
在前边我们以前涉及到了class的文件结构,包括魔数,主次版本号等,将在验证阶段进行校验
2、元数据验证
3、字节码验证
4、符号引用验证
3.准备
准备阶段是正式为类变量分配内存并设置其初始值的阶段,这些变量所使用的内存都将在方法区中分配。关于这点,有两个地方注意一下:
1、这时候进行内存分配的仅仅是类变量(被static修饰的变量),而不是实例变量,实例变量将会在对象实例化的时候随着对象一起分配在Java堆中
2、这个阶段赋初始值的变量指的是那些不被final修饰的static变量,比如”public static int value = 123;”,value在准备阶段过后是0而不是123,给value赋值为123的动作将在初始化阶段才进行;比如”public static final int value = 123;”就不一样了,在准备阶段,虚拟机就会给value赋值为123。
4.解析
解析阶段是虚拟机将常量池内的符号引用替换为直接引用的过程。
在上面我们已经讲到:
class文件常量池主要存放两大类常量:字面量和符号引用,字面量如文本字符串,声明为final的常量值;符号引用包括:
类和接口的全限定名
字段的名称和描述符
方法的名称和描述符
我们截取上边的一部分字节码文件:
...
public class Testminor version: 0major version: 52flags: ACC_PUBLIC, ACC_SUPER
Constant pool:#1 = Methodref #10.#24 // java/lang/Object."<init>":()V#2 = String #25 // Hello#3 = Fieldref #9.#26 // Test.a:Ljava/lang/String;#4 = Class #27 // java/lang/StringBuilder#5 = Methodref #4.#24 // java/lang/StringBuilder."<init>":()V#6 = Methodref #4.#28 // java/lang/StringBuilder.append:(Ljava/lang/String;)Ljava/lang/StringBuilder;#7 = String #29 // World#8 = Methodref #4.#30 // java/lang/StringBuilder.toString:()Ljava/lang/String;#9 = Class #31 // Test#10 = Class #32 // java/lang/Object#11 = Utf8 a#12 = Utf8 Ljava/lang/String;#13 = Utf8 <init>#14 = Utf8 ()V#15 = Utf8 Code#16 = Utf8 LineNumberTable#17 = Utf8 LocalVariableTable#18 = Utf8 this#19 = Utf8 LTest;#20 = Utf8 getA#21 = Utf8 ()Ljava/lang/String;#22 = Utf8 SourceFile#23 = Utf8 Test.java#24 = NameAndType #13:#14 // "<init>":()V#25 = Utf8 Hello#26 = NameAndType #11:#12 // a:Ljava/lang/String;#27 = Utf8 java/lang/StringBuilder#28 = NameAndType #33:#34 // append:(Ljava/lang/String;)Ljava/lang/StringBuilder;#29 = Utf8 World#30 = NameAndType #35:#21 // toString:()Ljava/lang/String;#31 = Utf8 Test#32 = Utf8 java/lang/Object#33 = Utf8 append#34 = Utf8 (Ljava/lang/String;)Ljava/lang/StringBuilder;#35 = Utf8 toString...
上面的常量池中共有35项内容,显示为Utf8的就是符号引用。
5.初始化
初始化阶段是类加载过程的最后一步,初始化阶段是真正执行类中定义的Java程序代码(或者说是字节码)的过程。初始化过程是一个执行类构造器()方法的过程,根据程序员通过程序制定的主观计划去初始化类变量和其它资源。把这句话说白一点,其实初始化阶段做的事就是给static变量赋予用户指定的值以及执行静态代码块。
回过头来想一个问题,什么时候类会初始化?,Java虚拟机规范有严格的限制:
1、使用new关键字实例化对象、读取或者设置一个类的静态字段(被final修饰的静态字段除外)、调用一个类的静态方法的时候
2、使用java.lang.reflect包中的方法对类进行反射调用的时候
3、初始化一个类,发现其父类还没有初始化过的时候
4、虚拟机启动的时候,虚拟机会先初始化用户指定的包含main()方法的那个类
除了上面4种场景外,所有引用类的方式都不会触发类的初始化,称为被动引用。
这篇关于读书· 深入理解Java虚拟机的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





