本文主要是介绍秋招突击——第八弹——Redis是怎么运作的,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
文章目录
- 引言
- 正文
- Redis在内存中是怎么存储的
- 面试重点
- Redis是单线程还是多线程
- 面试重点
- 内存满了怎么办?
- 面试重点
- 持久化介绍
- 面试重点
- RDB持久化
- 面试重点
- AOF日志
- 面试重点
- 总结
引言
- 差不多花了两天把redis给过了,早上也只背了一半,完成回去的时候,在背一会,还有健身的时候在听一会。加油,完成不要睡太晚了,早上起不了,还容易做噩梦。
正文
Redis在内存中是怎么存储的

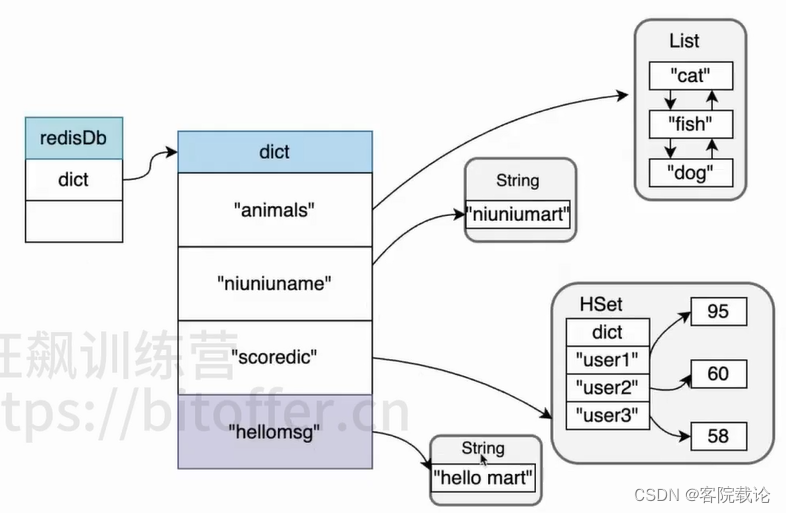
dict字典的存储结构


添加元素
- 这个字典对应一下存储结构
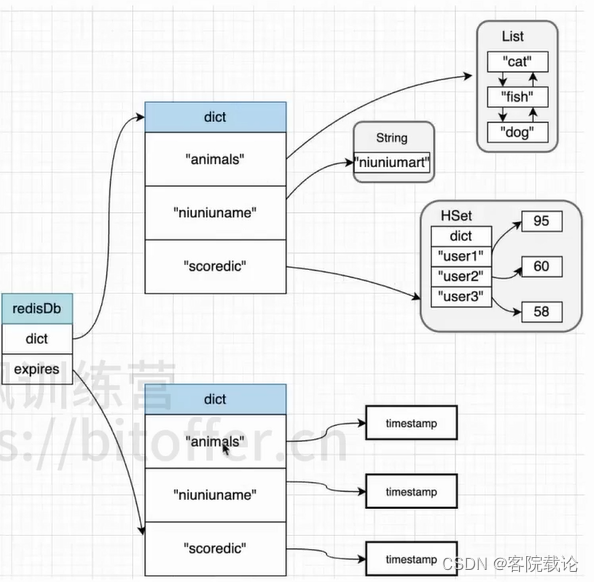
过期字典
- 这里所有的key都是指向内存的某一个对象
面试重点
set a b 这个数据的存储结构是怎么样的?
- redis存储是字典结构,set a b之后,a会放在字典对应的偏移位置,b作为对应的value进行存储。
过期的信息会存储在哪里?
- 如果添加了某一个元素的过期时间,则会立马将key添加到过期字典中,并存储对应的时间戳。
有个key过期事件后,那么既在字典还是过期字典,会有两份吗
- 这里保存的都是指针,对象的指针,不会重复占用内存。
Redis是单线程还是多线程
- 执行始终是单线程
为什么用单线程
- redis的瓶颈是IO操作,并不是CPU操作,基于这个投入产出比,还是使用的单线程。

为什么单线程还这么快?

- 高效的数据结构,保证了访问速度
- I/O多路复用
Reactor模型
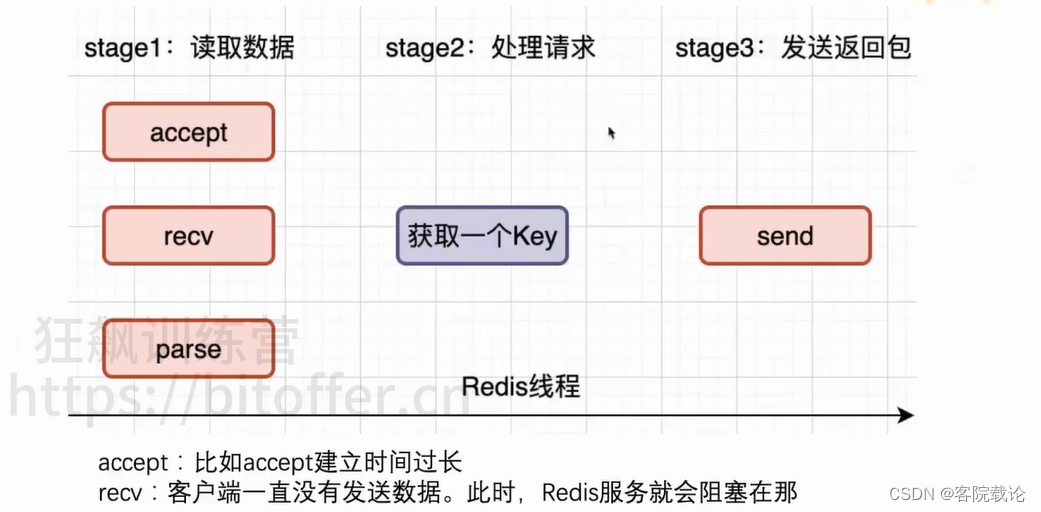
- 针对命令可以执行之后,就阻塞,不再管他,这里使用事件通知epoll模式解决不同步的问题。

- 每一个请求都会触发,触发之后就会发送到对应的句柄,进行处理。
面试重点
redis是单线程还是多线程
- 核心处理逻辑,Redis一直是单线程的;某些异步流程从4.0开始用多线程,如UNLINK、FLUSHALL ASYNC等非阻塞操作网络I0解包从6.0开始用的都是多线程
为什么使用单线程
- 瓶颈在I/0不是CPU,这种情况下,选择多线程成本和复杂性高,综合投入产出比,所以选择了单线程
为什么单线程还那么快?
- Redis是内存数据库,内存操作本身就很快
- 同时Redis选了高效的数据结构,很多对象底层有多种实现以应对不同的场景,追求性能的极致。
- 最后Redis采用了多路复用的机制,使其在网络10操作中能并发处理大量的客户端请求,实现高吞吐量
内存满了怎么办?
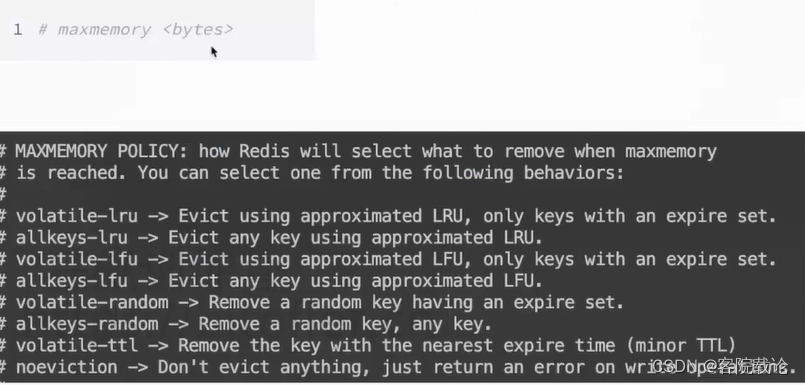
- 超过了操作系统最大的存储范围时,再继续添加数据
- 总共有8种淘汰策略
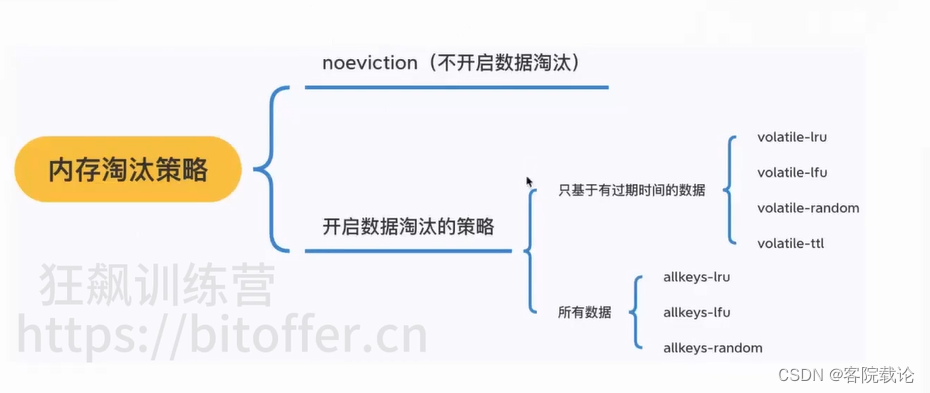
LRU算法
- 最近最久未使用的数据优先被淘汰
- 成本:双链表,巨大内存消耗
- redis选择近似LRU算法,方式消耗更多内存
- 每次随机选择特定数量的数据,在选中的数据中最不常用的淘汰
- 为了提高效率,这里选择维护随机池,大小是16个
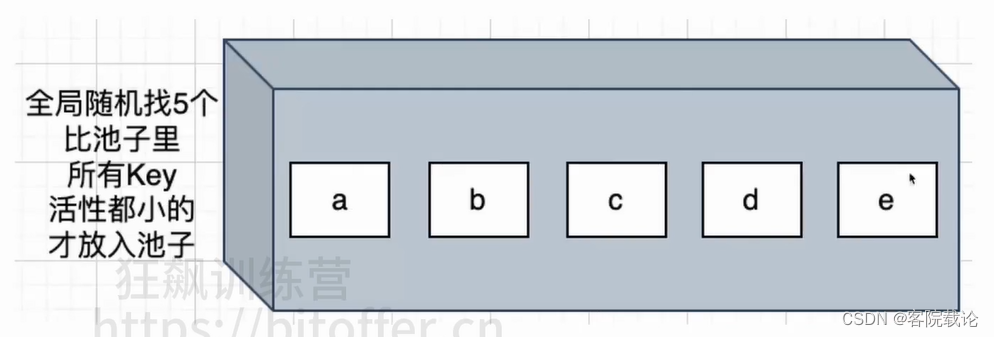
- 经过验证,是有效的!
- 缺陷
- 只管最近访问时间,不会考虑频率

- 只管最近访问时间,不会考虑频率
LFU算法
- 针对LRU的仅考虑访问时间的缺点,做的改良
- LFU同时记录访问的频率还有上一次访问的时间戳


- 决定效果是访问计数:
- 根据当前时间和上一次访问时间戳,计算衰减系数
- 如果被访问到,访问计数有概率增加,100之前每一次访问都会加1,如果超过一百,每次有一定的概率增加1
难度调节

面试重点
Redis有几种内存回收策略
内存回收,什么时候发起
- 每次读写的时候,都会检查是否需要释放内存,如果需要,就会触发。
介绍一下LRU回收算法
- 近似LRU算法,是否需要我继续往下讲讲?
- 没有淘汰池的情况
- 增加淘汰池的情况
什么是LFU算法
- 将访问频率也加入到影响因素中,同时记录访问计数和上一次访问的时间戳。
持久化介绍
是什么?
- 遇到崩溃重启时,原来已有的数据在重启之后,能够重新恢复。
- 具有一下几种方式
- RDB快照
- AOF日志
RDB和AOF的区别
- AOF是先写进缓冲区,最后再刷盘,在这段时间会有问题

加载策略
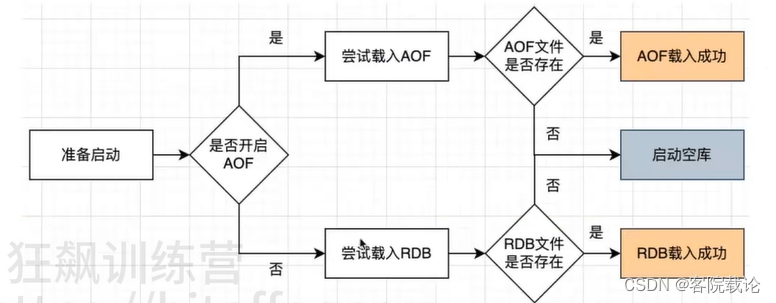
- 不要把潜在的问题埋起来,要暴露出来
面试重点
Redis为什么要持久化
- 定义 + 场景
RDB和AOF的区别
- 本质:快照和日志
- 安全性:在于丢失的文件多少
- 恢复速度:RDB二进制文件,恢复速度更快
- 操作的开销
RDB和AOF应该如何选择
- 混合持久化,尽量保证数据安全
- 接受分钟级别的丢失,那就RDB
- 不能只选择的AOF,这样不安全
同时加载AOF和RDB,启动时,会用哪个
- 只会用AOF,既然开启了AOF,想要保证数据丢失少。即使没有AOF文件,也会创建一个空库,暴露出对应的问题。
RDB持久化
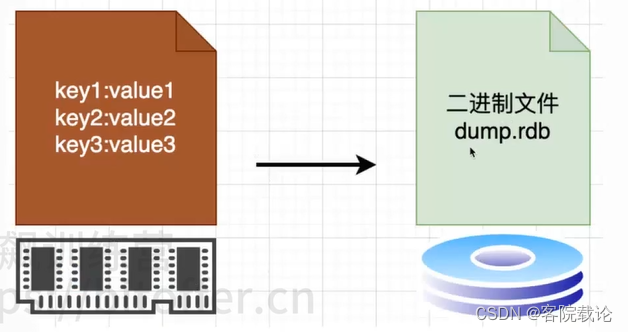
- RDB保存到磁盘的文件后缀是RDB
开启RDB
- 900秒内,有一次操作,会进行RDB的备份
- 一分钟内,有一万次操作,也会执行RDB

- 使用命令,进行持久化
- 顶时持久化的模式,是采用后台持久化

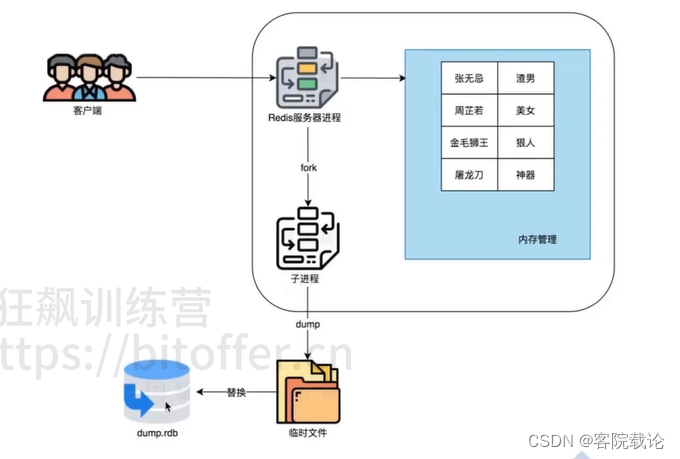
RDB写入流程到底是怎么样的?
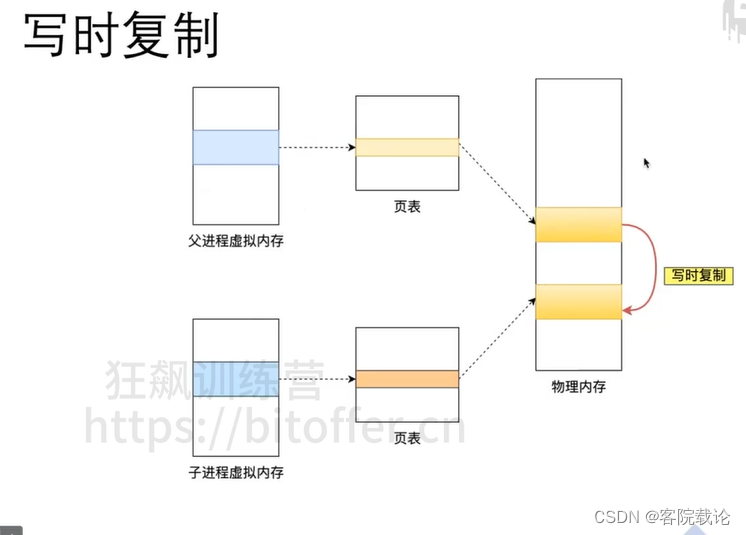
- 先调用fork创建子进程,子进程将数据写入临时文件,然后替代原来的文件,实现写时复制。

- 父进程fork创建子进程实现RDB新的创建
写时复制
- 如果fork一条数据后,这个数据是两份吗?并不是,谁写谁复制下,写的时候复制。
- 谁来更改,谁来复制一份。
- 子进程不会接受命令的,触发写时复制的,一定是父进程。
面试重点
RDB是什么?解决了什么问题?
- 二进制形式的快照
RDB怎么开启
- 定时(后台持久化)和主动命令
RDB对主流程有什么影响

RDB写入流程是什么?写时复制的机制。

AOF日志
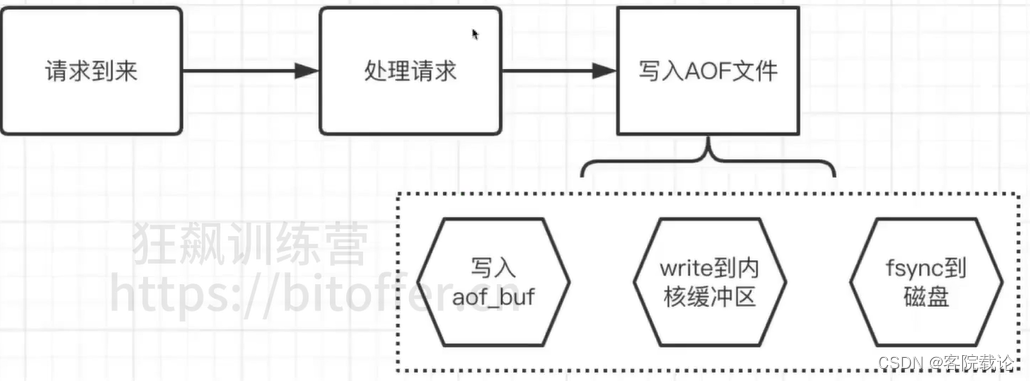
开启AOF

怎么写入AOF
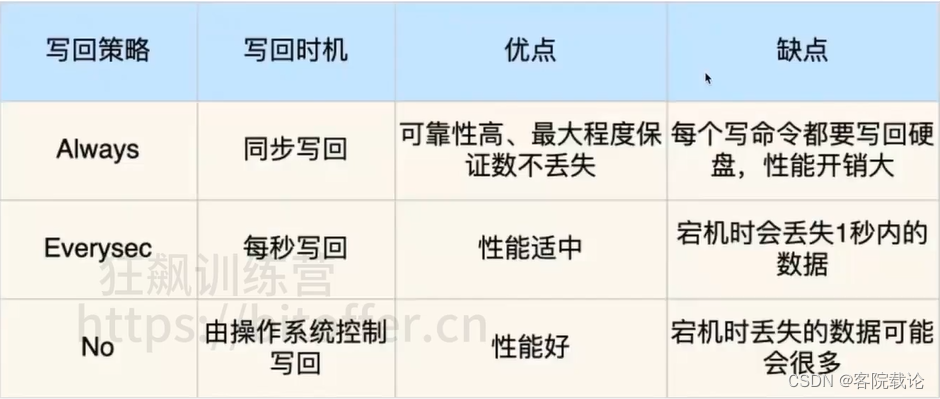
AOF刷盘策略

- 不同写回策略的问题
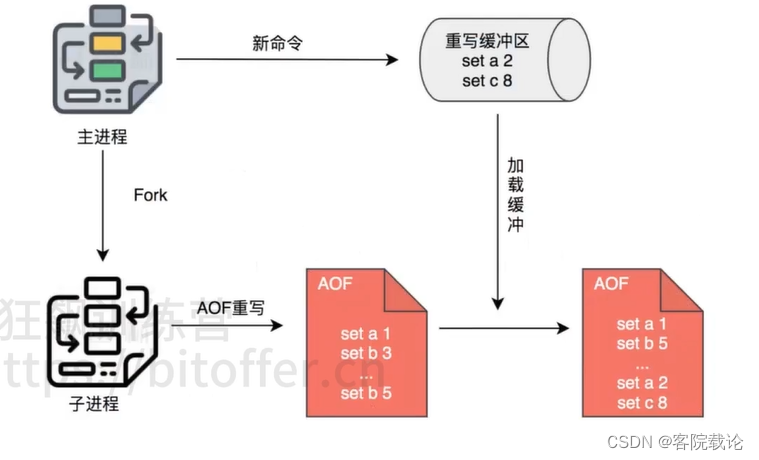
AOF重写
面试重点
AOF是默认开启的吗
- RDB是默认开启,AOF是不是
AOF重写是解决什么问题的
- 重写是用于解决AOF不断膨胀问题,随着命令越来越多,AOF文件越来越大但是很多数据其实不一定都是还有意义的,比如原来seta3,后面又有个seta100,那么前者就不需要再继续了。重写就是通过当前状态,重新生成最新的AOF操作命令记录的过程。
AOF重写流程

总结
- 这里的RDB持久化看的有点懵,这个写时复制在背操作系统的时候看过,但是没理解,现在看还是没有理解。
- 先背着,后续有时间再往下继续看,时间不多了,得继续加快进度。
这篇关于秋招突击——第八弹——Redis是怎么运作的的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!








