本文主要是介绍Pytho字符串的定义与操作,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
一、字符串的定义
Python 字符串是字符的序列,用于存储文本数据。字符串可以包括字母、数字、符号和空格。在 Python 中,字符串是不可变的,这意味着一旦创建了一个字符串,就不能更改其中的字符。但是,你可以创建新的字符串来模拟更改。
1、将文字、数字、符号用一对引号包起来,就形成了一个字符
串。

2、只要是成对出现,单引号、双引号、三引号都正确

3、不同引号的区别
外面使用了双引号,那么外面就使用单引号,如果在字符串的两侧使用了单引号,那么在字符串的内部使用双引号"避免计算机误读指令。使用三引号,保留字符串内部的格式。

二、字符串的操作
1. 连接字符串:
str1 = "Hello"
str2 = "World"
result = str1 + " " + str2 # 结果为 "Hello World"

2.重复字符串:
repeated = "重复" * 3 # 结果为 "重复重复重复"

3.字符串索引:
通过索引访问字符串中的单个字符。
索引从 0 开始,负数索引表示从字符串末尾开始计数。
char = "字符串索引"[0] # 结果为 '字'
last_char = "字符串索引"[-1] # 结果为 '引'

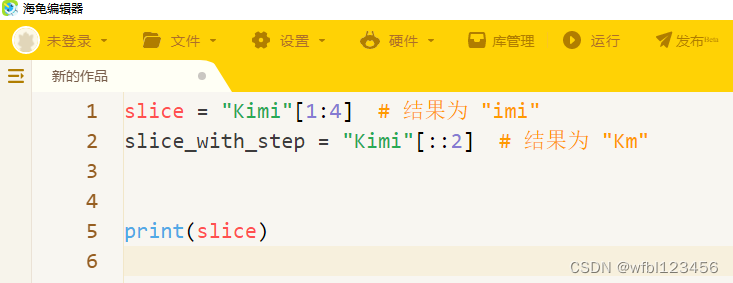
4.字符串切片:
切片用于获取字符串的一部分。
语法:string[start:end:step]
slice = "Kimi"[1:4] # 结果为 "imi"
slice_with_step = "Kimi"[::2] # 结果为 "Km"
5.字符串长度:
使用len()函数获取字符串的长度。
length = len("Kimi") # 结果为 4

6.大小写转换:
upper()将字符串转换为大写。
.lower()将字符串转换为小写。
upper = "kimi".upper() # 结果为 "KIMI"
lower = "KIMI".lower() # 结果为 "kimi"

7.字符串查找:
find(sub)查找子字符串 sub 在字符串中的位置,如果不存在则返回 -1。
index(sub) 与.find()类似,但若子字符串不存在则抛出异常。
index = "Kimi".find("m") # 结果为 2

8.字符串替换:
使用 replace(old, new)方法替换字符串中的部分内容。
replaced = "Kimi".replace("K", "Moonshot") # 结果为 "Moonshotimi"

9.字符串分割:
使用split(separator)方法根据指定分隔符将字符串分割成列表。
split_string = "Kimi,Moonshot,AI".split(",") # 结果为 ["Kimi", "Moonshot", "AI"]

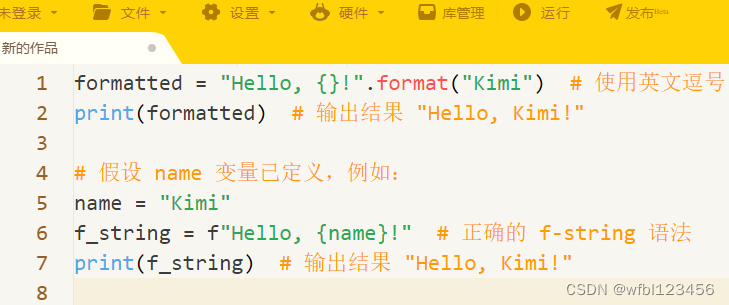
10.字符串格式化:
使用 format()`方法或 f-string(Python 3.6+)进行字符串格式化。
formatted = "Hello, {}!".format("Kimi") # 结果为 "Hello, Kimi!"
f_string = f"Hello, {name}!" # 假设 name 变量已定义
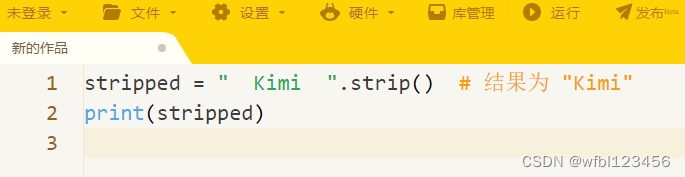
11.去除空白:
.strip()去除字符串两端的空白字符。
rstrip()去除字符串右侧的空白字符。
strip()` 去除字符串左侧的空白字符。
stripped = " Kimi ".strip() # 结果为 "Kimi"
12.检查字符串:
isalpha()` 检查字符串是否只包含字母。
isdigit()` 检查字符串是否只包含数字。
isalnum()` 检查字符串是否只包含字母和数字。
is_alpha = "Kimi".isalpha() # 结果为 True
这些只是 Python 字符串操作的一小部分。Python 的字符串类型非常强大,提供了许多内置方法来处理文本数据。
这篇关于Pytho字符串的定义与操作的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





