本文主要是介绍Race Condition竞争条件,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
Race Condition

- Question – why was there no race condition in the first solution (where at most N – 1) buffers can be filled?
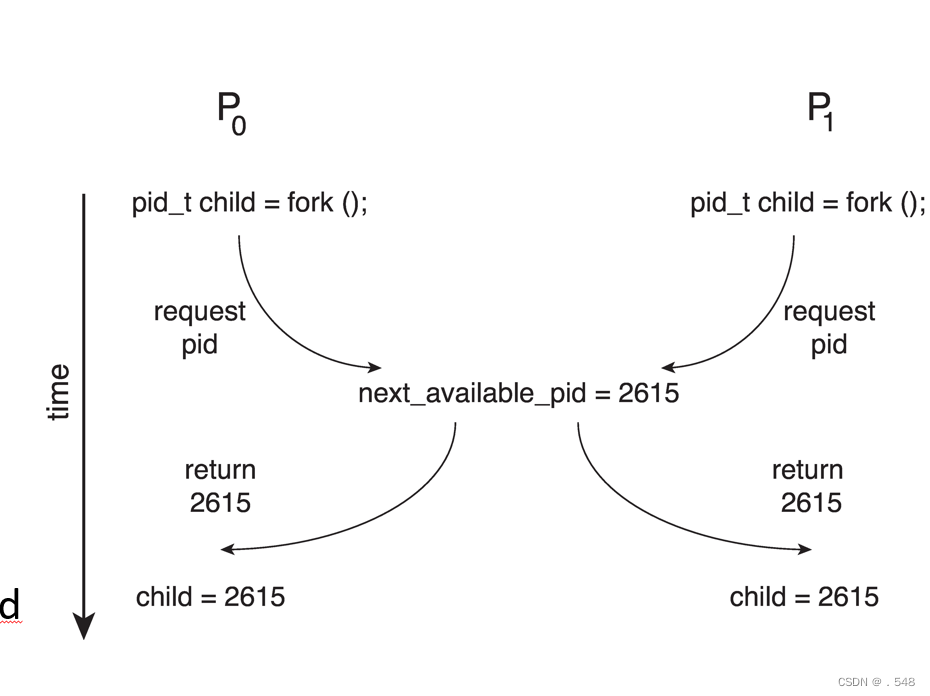
- Processes P0 and P1 are creating child processes using the fork() system call
- Race condition on kernel variable next_available_pid which represents the next available process identifier (pid)
- Unless there is a mechanism to prevent P0 and P1 from accessing the variable next_available_pid the same pid could be assigned to two different processes!
进程 P0 和 P1 正在使用 fork() 系统调用创建子进程
内核变量 next_available_pid 代表下一个可用进程标识符 (pid) 的竞赛条件
除非有机制阻止 P0 和 P1 访问变量 next_available_pid,否则相同的 pid 可能被分配给两个不同的进程!
solution
Memory Barrier
• Memory model are the memory guarantees a computer architecture makes to application programs. • Memory models may be either:
• Strongly ordered – where a memory modification of one processor is immediately visible to all other processors. • Weakly ordered – where a memory modification of one processor may not be immediately visible to all other processors.
• A memory barrier is an instruction that forces any change in memory to be propagated (made visible) to all other processors.
内存模型是计算机体系结构为应用程序提供的内存保证。- 内存模型可以是
- 强有序 - 一个处理器的内存修改会立即被所有其他处理器看到。- 弱有序--一个处理器的内存修改可能不会立即被所有其他处理器看到。
- 内存障碍是一种指令,它强制将内存中的任何变化传播(使其可见)到所有其他处理器。
Memory Barrier Instructions
• When a memory barrier instruction is performed, the system ensures that all loads and stores are completed before any subsequent load or store operations are performed.
• Therefore, even if instructions were reordered, the memory barrier ensures that the store operations are completed in memory and visible to other processors before future load or store operations are performed.
执行内存障碍指令时,系统会确保在执行任何后续加载或存储操作之前,完成所有加载和存储操作。
- 因此,即使指令被重新排序,内存屏障也能确保存储操作在内存中完成,并在今后执行加载或存储操作前对其他处理器可见。
Memory Barrier Example
• Returning to the example of slides 6.17 - 6.18 • We could add a memory barrier to the following instructions to ensure Thread 1 outputs 100:
• Thread 1 now performs while (!flag) memory_barrier(); print x
• Thread 2 now performs x = 100; memory_barrier(); flag = true • For Thread 1 we are guaranteed that the value of flag is loaded before the value of x. • For Thread 2 we ensure that the assignment to x occurs before the assignment flag.
Synchronization Hardware
• Many systems provide hardware support for implementing the critical section code.
• Uniprocessors – could disable interrupts
• Currently running code would execute without preemption
• Generally too inefficient on multiprocessor systems
• Operating systems using this not broadly scalable
• We will look at three forms of hardware support:
1. Hardware instructions 2. Atomic variables Hardware Instructions
• Special hardware instructions that allow us to either test-and-modify the content of a word, or to swap the contents of two words atomically (uninterruptedly.) • Test-and-Set instruction • Compare-and-Swap instruction
Atomic Variables
• Typically, instructions such as compare-and-swap are used as building blocks for other synchronization tools. • One tool is an atomic variable that provides atomic (uninterruptible) updates on basic data types such as integers and booleans.
• For example: • Let sequence be an atomic variable • Let increment() be operation on the atomic variable sequence • The Command: increment(&sequence); ensures sequence is incremented without interruption:
Mutex Locks
• Previous solutions are complicated and generally inaccessible to application programmers • OS designers build software tools to solve critical section problem • Simplest is mutex lock
• Boolean variable indicating if lock is available or not • Protect a critical section by
• First acquire() a lock • Then release() the lock • Calls to acquire() and release() must be atomic • Usually implemented via hardware atomic instructions such as compare-and-swap. • But this solution requires busy waiting • This lock therefore called a spinlock
Semaphore
• Synchronization tool that provides more sophisticated ways (than Mutex locks) for processes to synchronize their activities.
• Semaphore S – integer variable • Can only be accessed via two indivisible (atomic) operations • wait() and signal()
• Originally called P() and V() Semaphore (Cont.)
• Definition of the wait() operation wait(S) { while (S value--; if (S->value < 0) { add this process to S->list; block(); } } signal(semaphore *S) { S->value++; if (S->value list; wakeup(P); } }
Problems with Semaphores • Incorrect use of semaphore operations:
• signal(mutex) …. wait(mutex) • wait(mutex) … wait(mutex) • Omitting of wait (mutex) and/or signal (mutex) • These – and others – are examples of what can occur when semaphores and other synchronization tools are used incorrectly.
这篇关于Race Condition竞争条件的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!



