本文主要是介绍FEC 向前纠错编码,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
随写,看的有点杂,简单记一下。
应该叫ReedSolomon FEC
RS算法简单来讲就是,根据已有数据,构造模型,然后根据模型判纠错?
简单来讲,两点确定一条直线,直线直线上的点都会满足 y = kx + b 这个模型。
在传输场景/数据保存场景,给了两条数据 可以确定是否是正确的,而仅仅发送一条数据是无法判断的。然后发送三条数据可有判断第三条是否在这个模型上。但是一般传输数据,还会携带冗余数据,用于实现纠错。
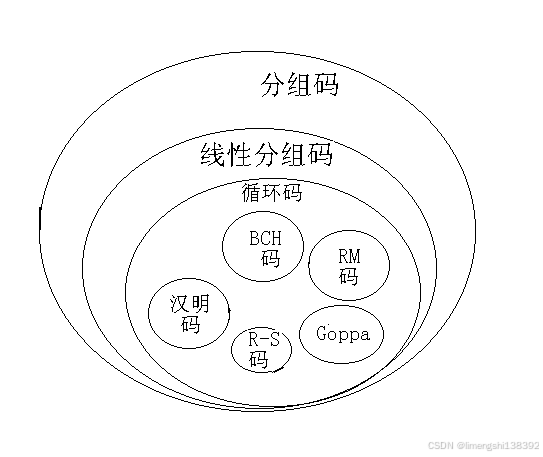
比如说,在学习计算机网络这门课程,大家肯定都熟悉 crc循环冗余算法吧,本质携带更多的冗余数据去验证哪些数据是错误的。
crc 计算参考
参考01
turbo
Low-density_parity-check
这篇关于FEC 向前纠错编码的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!