本文主要是介绍一步步学习SPD2010--第九章节--使用可重用工作流和工作流表单(1)--创建和使用可重用工作流,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
一步步学习SPD2010--第九章节--使用可重用工作流和工作流表单(1)--创建和使用可重用工作流
之前版本的SPD最大的问题是,你只能创建工作流,依附在特定列表或库。SPD2010允许你创建可重用工作流。你可以将可重用工作流依附到特定内容类型,这可以是工作流对于任何与那个内容类型关联的列表或库都可用。在工作流设置页面,你可以指定可重用工作流是否使用工作流可视化,在启动选项部分,可以指定当可重用工作流与列表或库关联时那个启动选项不启用。
本练习中,将创建可重用工作流,并使用浏览器关联到列表。
准备:使用SPD打开站点。
1. 导航窗格点击工作流,新建可重用工作流。
2. 命名SPD SBS Job Application,描述Use this SPD reusable workflow to create a workflow that will log job application information to the History Log。
3. 内容类型列表选择Document。
警告:一旦保存可重用工作流,不能再改变内容类型。
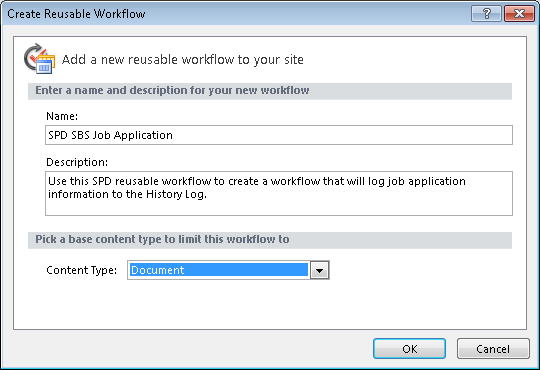
4. 点击确定。
5. 在工作流选项卡,点击操作,在核心操作下选择记录到历史记录列表。
6. 点击此消息,点击显示此参数的生成器(省略号按钮)。
7. 名称输入Job Applicant resume:,然后点击添加或更改查找。在源中的域列表,选择Name (for use in forms),点击确定两次。
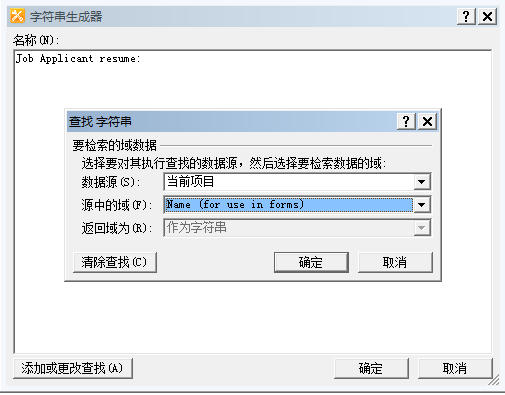
8. 保存。发布。
9. 在导航窗格,点击列表和库。选择共享文档,在列表设置选项卡,点击工作流关联。这样会打开浏览器。
10. 在“这些工作流配置为在此类型的项目上运行”列表选择文档,点击添加工作流。

11. 在选择工作流模板列表,选择SPD SBS Job Application。然后在输入工作流唯一名称输入JobHistory。
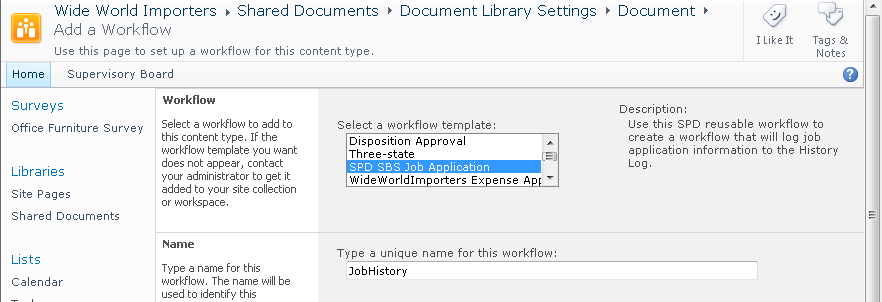
小贴士:当工作流经常使用时,应该有自己的任务列表。
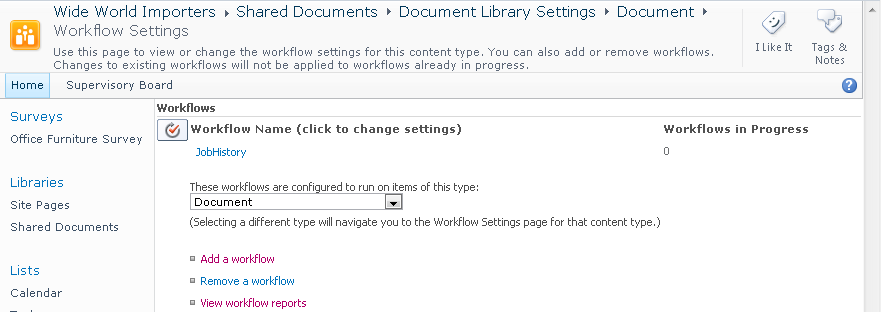
12. 在页面底部点击确定。
这篇关于一步步学习SPD2010--第九章节--使用可重用工作流和工作流表单(1)--创建和使用可重用工作流的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!







