本文主要是介绍Omnivore:全能开源稍后阅读神器,让文字爱好者畅享阅读乐趣!,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
热门开源项目推荐
项目地址🔗🔗🔗🔗
https://gitcode.com/omnivore-app/omnivore/overview
Omnivore:全能开源稍后阅读神器
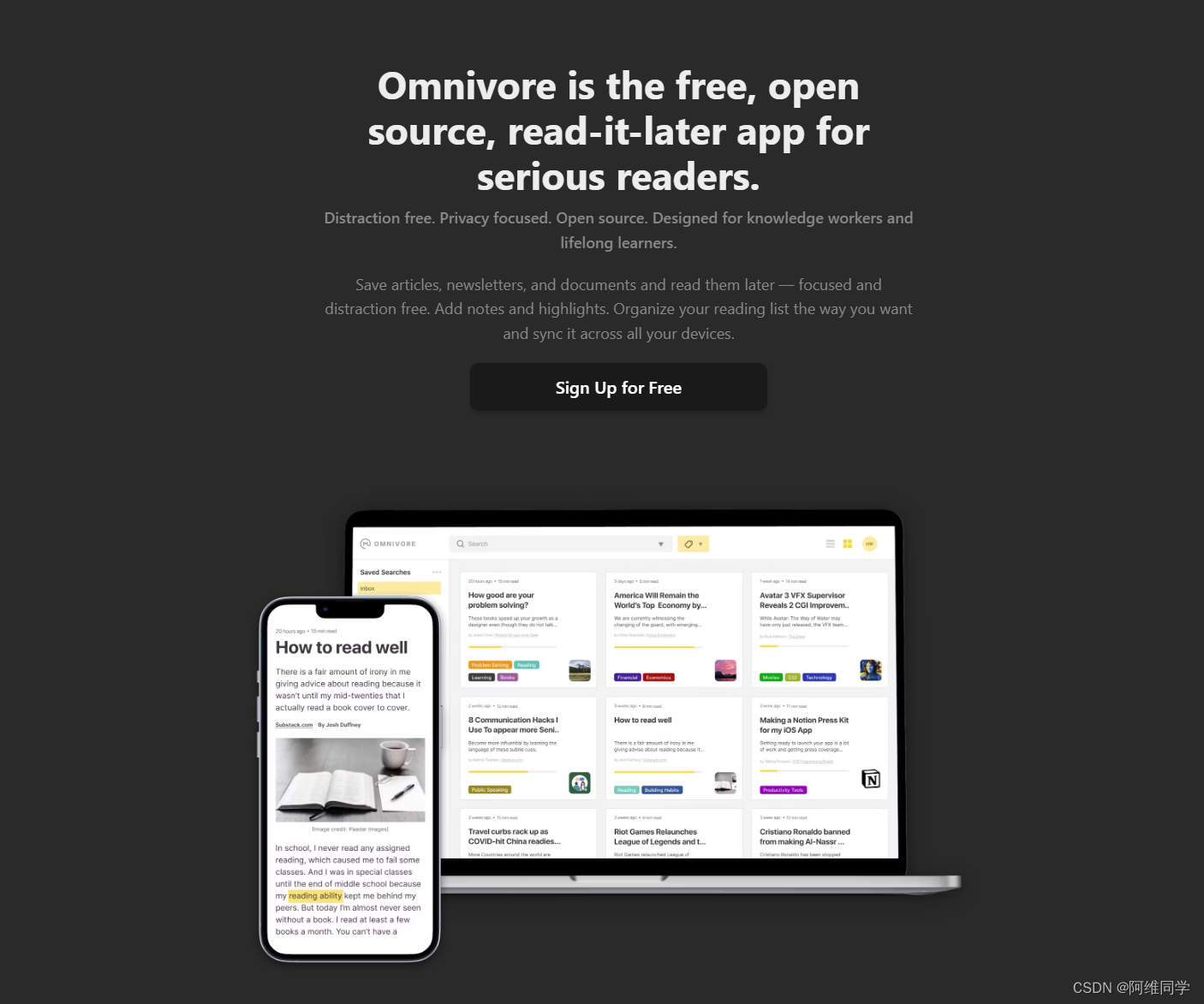
Omnivore App 介绍
Omnivore是一个完整的开源稍后阅读解决方案,专为喜欢文字的人设计。它的核心功能包括高亮、笔记、搜索和分享,完全键盘导航,自动保存长篇文章的进度,通过电子邮件添加新闻通讯文章(支持Substack),PDF支持,以及离线支持。此外,Omnivore还提供了浏览器扩展,包括Chrome、Safari、Firefox和Edge,并通过Logseq和Obsidian插件支持Logseq和Obsidian。
**
开源特性
**
Omnivore的主要功能包括:
-
高亮和笔记:方便用户在文章中做标记,便于回顾和记忆。
-
搜索:强大的搜索功能可以快速定位到用户保存的内容,提高查找效率。
-
分享:允许用户将自己的阅读内容或笔记分享给其他人,促进知识传播。
-
完全键盘导航:对于习惯使用键盘操作的用户,这是一个提高效率的重要功能。
-
自动保存阅读进度:在阅读长篇文章时,自动保存功能确保用户可以随时回到上次阅读的位置。
-
通过电子邮件添加文章:支持通过邮件导入文章,尤其是Substack平台的文章,增加了内容的获取途径。
-
PDF支持:允许用户导入和阅读PDF文档,拓宽了Omnivore的应用范围。
-
浏览器扩展:通过浏览器扩展,用户可以轻松地将网页内容保存到Omnivore中,方便管理。
-
标签(标记):用户可以通过标签对内容进行分类,便于查找和管理。
-
离线支持:支持离线阅读,用户无需担心在没有网络连接的情况下无法访问已保存的内容。
-
文字转语音(仅限iOS):为iOS用户提供了文字转语音的功能,增加了阅读的灵活性。
-
集成到Logseq和Obsidian:Omnivore通过插件与这两款流行的知识管理工具集成,为用户提供了更多的扩展和整合可能性。
这些功能共同构成了Omnivore作为一个全面的内容管理和阅读工具的核心竞争力,为用户提供了从内容获取、保存到分享、管理的全方位服务。
一、项目介绍
Omnivore是一个功能丰富的现代阅读应用,旨在为用户提供一种全新的阅读体验。该项目采用全栈TypeScript编写,结合了一系列前沿的技术栈,包括Next.js、Apollo GraphQL、Swift GraphQL、Stitches、SWR、Radix、PostgreSQL等,构建了一个既强大又易于扩展的Web和移动应用。
二、技术栈分析
-
全栈TypeScript
- TypeScript为Omnivore提供了静态类型检查的能力,这不仅增强了代码的可读性和可维护性,也极大地提高了代码的健壮性和可靠性。
-
Next.js 和 Vercel
- Next.js是一个基于React的框架,提供了静态站点生成、服务器端渲染等功能,为Omnivore的前端提供了快速且高效的开发体验。而Vercel作为Next.js的官方托管平台,提供了自动部署和优化的能力,确保了应用的快速响应和稳定性。
-
Apollo GraphQL
- Apollo GraphQL为Omnivore提供了强大的API请求处理能力。无论是在Web端还是Android端,Apollo GraphQL都提供了高效的GraphQL查询和变更处理,使得数据交互变得简单而高效。
-
Swift GraphQL
- 对于iOS应用,Omnivore采用了Swift GraphQL库来生成GraphQL查询。这不仅简化了与GraphQL服务器的交互,也确保了数据的安全性和一致性。
-
Stitches
- Stitches库为Omnivore提供了模块化和响应式的CSS-in-JS解决方案。开发人员可以轻松地编写可重用、可组合的样式代码,大大提高了组件的可定制性和可维护性。
-
SWR
- 在Web应用中,SWR库用于进行数据获取和缓存。通过缓存请求的结果,SWR可以显著减少网络请求的次数,提高了应用的性能和用户体验。
-
Radix
- Radix是一个现代化的、可组合的JavaScript UI组件库。它为Omnivore提供了丰富的UI组件和灵活的布局选项,使得开发人员可以快速地构建出美观且易于使用的界面。
-
PostgreSQL
- PostgreSQL作为后端数据库,为Omnivore提供了强大的数据存储和管理功能。其丰富的数据类型、事务处理能力和扩展性,确保了应用数据的安全性和可靠性。
-
Docker Compose
- Docker Compose简化了Omnivore开发环境的设置和管理。通过定义服务、网络和卷的配置文件,开发人员可以快速地启动和管理不同的服务,提高了开发效率。
-
Observability
- Omnivore对observability的关注体现在使用Prometheus和Grafana进行服务的性能监控。这使得开发人员可以实时地了解应用的运行状况,及时地发现并解决问题。
代码解释:Omnivore 项目中的关键部分
1. GraphQL 模型
在Omnivore项目中,GraphQL模型定义了数据结构和它们之间的关系。这通常使用GraphQL Schema语言编写,并可能使用TypeScript的接口或类型来增强类型安全。
// 例如:用户模型的GraphQL Schema定义
type User {id: ID!username: String!email: String!articles: [Article!]!tags: [Tag!]!
}// TypeScript接口,可能与上面的GraphQL Schema相对应
interface IUser {id: string;username: string;email: string;articles: IArticle[];tags: ITag[];
}
2. GraphQL 操作
GraphQL操作定义了API的查询、修改和订阅。它们使用GraphQL查询语言编写,并在服务器端实现相应的解析器(resolver)来处理请求。
# 查询所有用户
query GetUsers {users {idusernameemail}
}# 服务器端解析器示例(伪代码)
getUsers: async () => {// 假设有一个userService来处理用户相关的逻辑return await userService.findAll();
}
3. 业务逻辑
业务逻辑包含数据的增删改查操作,通常封装在服务层中。它们可能涉及数据库查询、验证、授权和外部服务的调用。
// 示例:用户服务中的创建用户方法
async function createUser(userData: IUserInput): Promise<IUser> {// 验证用户数据validateUserData(userData);// 将数据保存到数据库const newUser = await database.insert('users', userData);// 发送通知或其他外部操作await sendWelcomeEmail(newUser.email);return newUser;
}
4. 数据库迁移
使用TypeORM或Knex.js等数据库迁移工具来管理数据库模式的变更。这些工具提供了迁移文件来定义数据库模式的更新。
// 使用TypeORM的迁移示例
export class CreateUserTable1585458433123 implements MigrationInterface {name = 'CreateUserTable1585458433123'public async up(queryRunner: QueryRunner): Promise<void> {await queryRunner.query(`CREATE TABLE "user" (...)`, undefined);// ...其他表或索引的创建}public async down(queryRunner: QueryRunner): Promise<void> {// ...撤销操作,如删除表或索引}
}
5. 前端组件
前端组件通常包括功能组件和样式。它们可能使用React、Vue或其他前端框架编写。
// 使用React和Stitches的组件示例
import { styled } from 'stitches.config';const StyledArticleList = styled('div', {// CSS样式定义display: 'flex',flexWrap: 'wrap',// ...其他样式
});function ArticleList({ articles }: { articles: IArticle[] }) {return (<StyledArticleList>{articles.map((article) => (<ArticleCard key={article.id} article={article} />))}</StyledArticleList>);
}// ArticleCard组件的实现会在这里或另一个文件中
6. 内容抓取服务
使用Puppeteer或类似工具来自动化浏览器并抓取网页内容。服务逻辑涉及接收请求、处理参数、执行抓取操作并返回结果。
// 示例:使用Puppeteer抓取网页内容的伪代码
async function fetchWebpageContent(url: string): Promise<string> {const browser = await puppeteer.launch();const page = await browser.newPage();await page.goto(url);const content = await page.content();await browser.close();return content;
}
7. 部署脚本
部署脚本自动化了应用的构建、测试和部署过程。它们可能使用Docker Compose、CI/CD工具(如GitLab CI/CD、Jenkins等)和自动化脚本(如Bash、Makefile等)编写。
8. 测试
测试是确保代码质量和稳定性的关键部分。单元测试针对函数和方法进行测试,集成测试确保不同组件之间的交互正常。测试可能使用Jest、Mocha等测试框架编写。
推荐理由
Omnivore作为一个全栈TypeScript构建的现代阅读应用,不仅功能丰富、性能优越,而且采用了众多前沿的技术栈,为开发人员提供了强大的技术支持和丰富的开发体验。同时,Omnivore也充分考虑了observability的重要性,确保了应用的稳定性和可维护性。因此,我强烈推荐Omnivore作为一个值得学习和研究的项目。
技术栈
TypeScript:用于前后端开发。
Next.js:用于前端开发,托管在Vercel上。
SWR:用于Web上的数据获取。
Stitches:用于前端样式化组件。
Mozilla Readability:用于提高页面可读性。
Swift GraphQL和Apollo GraphQL:分别用于iOS和Android上的GraphQL查询生成。
Radix:用于前端UI组件。
Omnivore 是一个开源项目,这意味着我们都可以审查其代码,为其发展做出贡献,或者将其作为自己项目的基础。鼓励有兴趣的读者尝试使用 Omnivore,加入其社区,一起打造更好的阅读体验。

项目地址🔗🔗🔗🔗
https://gitcode.com/omnivore-app/omnivore/overview
这篇关于Omnivore:全能开源稍后阅读神器,让文字爱好者畅享阅读乐趣!的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!









