本文主要是介绍Ascend C Add算子样例代码详解,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
核函数定义
核函数(Kernel Function)是Ascend C算子设备侧实现的入口。在核函数中,需要为在一个核上执行的代码规定要进行的数据访问和计算操作,当核函数被调用时,多个核都执行相同的核函数代码,具有相同的参数,并行执行。
// 实现核函数
extern "C" __global__ __aicore__ void add_custom(GM_ADDR x, GM_ADDR y, GM_ADDR z)
{// 初始化算子类,算子类提供算子初始化和核心处理等方法KernelAdd op;// 初始化函数,获取该核函数需要处理的输入输出地址,同时完成必要的内存初始化工作op.Init(x, y, z);// 核心处理函数,完成算子的数据搬运与计算等核心逻辑op.Process();
}// 调用核函数
void add_custom_do(uint32_t blockDim, void* l2ctrl, void* stream, uint8_t* x, uint8_t* y, uint8_t* z)
{add_custom<<<blockDim, l2ctrl, stream>>>(x, y, z);
}
使用__global__函数类型限定符来标识它是一个核函数,可以被<<<…>>>调用;使用__aicore__函数类型限定符来标识该核函数在设备端AI Core上执行:
__global__ __aicore__ void kernel_name(argument list);
编程中使用到的函数可以分为三类:核函数(device侧执行)、host侧执行函数、device侧执行函数(除核函数之外的)。三者的调用关系如下图所示:
● host侧执行函数可以调用同类的host执行函数,也就是通用C/C++编程中的函数调用;也可以通过<<<>>>调用核函数。
● device侧执行函数(除核函数之外的)可以调用同类的device侧执行函数。
● 核函数可以调用device侧执行函数(除核函数之外的)。

Add算子代码分析
Add算子设计规格
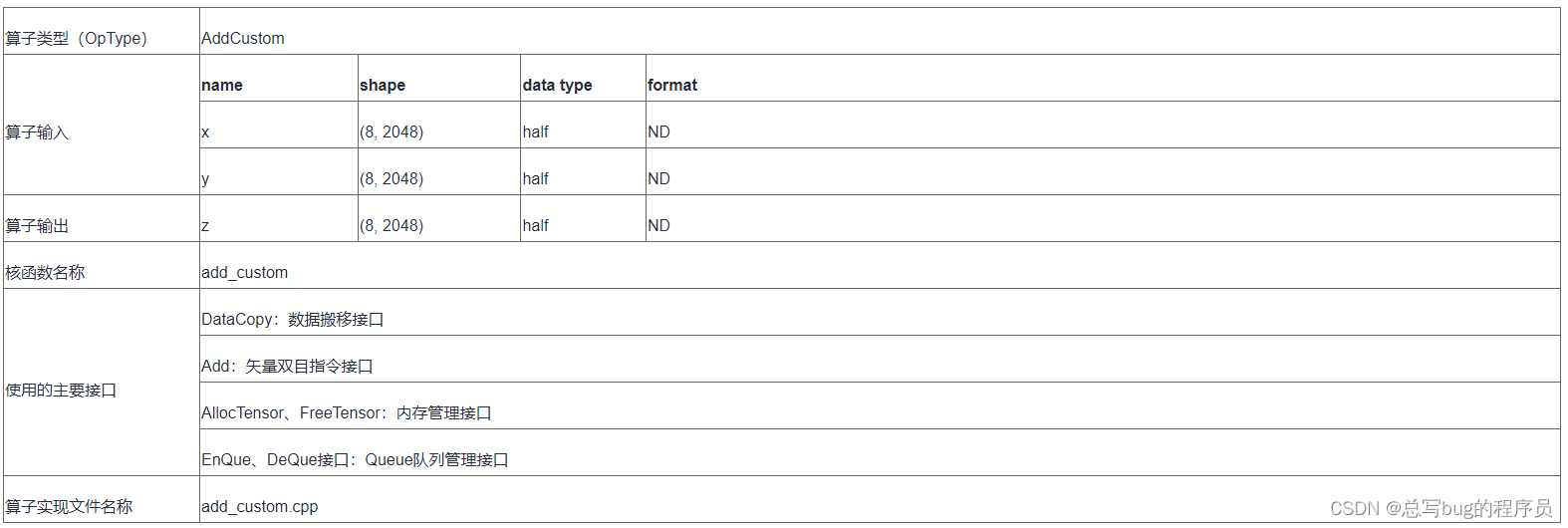
核函数开发
调用算子类的Init和Process函数
extern "C" __global__ __aicore__ void add_custom(GM_ADDR x, GM_ADDR y, GM_ADDR z)
{KernelAdd op;op.Init(x, y, z);op.Process();
}
矢量编程范式实现算子类
class KernelAdd {
public:
__aicore__ inline KernelAdd(){}
// 初始化函数,完成内存初始化相关操作
__aicore__ inline void Init(GM_ADDR x, GM_ADDR y, GM_ADDR z){}
// 核心处理函数,实现算子逻辑,调用私有成员函数CopyIn、Compute、CopyOut完成矢量算子的三级流水操作
__aicore__ inline void Process(){}private:
// 搬入函数,完成CopyIn阶段的处理,被核心Process函数调用
__aicore__ inline void CopyIn(int32_t progress){}
// 计算函数,完成Compute阶段的处理,被核心Process函数调用
__aicore__ inline void Compute(int32_t progress){}
// 搬出函数,完成CopyOut阶段的处理,被核心Process函数调用
__aicore__ inline void CopyOut(int32_t progress){}private:
TPipe pipe; //Pipe内存管理对象
TQue<QuePosition::VECIN, BUFFER_NUM> inQueueX, inQueueY; //输入数据Queue队列管理对象,QuePosition为VECIN
TQue<QuePosition::VECOUT, BUFFER_NUM> outQueueZ; //输出数据Queue队列管理对象,QuePosition为VECOUT
GlobalTensor<half> xGm, yGm, zGm; //管理输入输出Global Memory内存地址的对象,其中xGm, yGm为输入,zGm为输出
};
内部函数调用关系

由此可见除了Init函数完成初始化外,Process中完成了对流水任务:“搬入、计算、搬出”的调用,开发者可以重点关注三个流水任务的实现。
核函数运行验证
异构计算架构中,NPU(kernel侧)与CPU(host侧)是协同工作的,完成了kernel侧核函数开发后,即可编写host侧的核函数调用程序,实现从host侧的APP程序调用算子,执行计算过程。
代码整体结构
● 调用算子的应用程序:main.cpp。
● 输入数据和真值数据生成脚本文件:gen_data.py。
● 验证输出数据和真值数据是否一致的验证脚本:verify_result.py。
● 编译cpu侧或npu侧运行的算子的编译工程文件:CMakeLists.txt。
● 编译运行算子的脚本:run.sh。
以调用算子的应用程序的编写为例
NPU侧运行算子的调用程序

完整代码
// AscendCL初始化
CHECK_ACL(aclInit(nullptr));
// 运行管理资源申请
aclrtContext context;
int32_t deviceId = 0;
CHECK_ACL(aclrtSetDevice(deviceId));
CHECK_ACL(aclrtCreateContext(&context, deviceId));
aclrtStream stream = nullptr;
CHECK_ACL(aclrtCreateStream(&stream));
// 分配Host内存
uint8_t *xHost, *yHost, *zHost;
uint8_t *xDevice, *yDevice, *zDevice;
CHECK_ACL(aclrtMallocHost((void**)(&xHost), inputByteSize));
CHECK_ACL(aclrtMallocHost((void**)(&yHost), inputByteSize));
CHECK_ACL(aclrtMallocHost((void**)(&zHost), outputByteSize));
// 分配Device内存
CHECK_ACL(aclrtMalloc((void**)&xDevice, inputByteSize, ACL_MEM_MALLOC_HUGE_FIRST));
CHECK_ACL(aclrtMalloc((void**)&yDevice, inputByteSize, ACL_MEM_MALLOC_HUGE_FIRST));
CHECK_ACL(aclrtMalloc((void**)&zDevice, outputByteSize, ACL_MEM_MALLOC_HUGE_FIRST));
// Host内存初始化
ReadFile("./input/input_x.bin", inputByteSize, xHost, inputByteSize);
ReadFile("./input/input_y.bin", inputByteSize, yHost, inputByteSize);
CHECK_ACL(aclrtMemcpy(xDevice, inputByteSize, xHost, inputByteSize, ACL_MEMCPY_HOST_TO_DEVICE));
CHECK_ACL(aclrtMemcpy(yDevice, inputByteSize, yHost, inputByteSize, ACL_MEMCPY_HOST_TO_DEVICE));
// 用内核调用符<<<>>>调用核函数完成指定的运算,add_custom_do中封装了<<<>>>调用
add_custom_do(blockDim, nullptr, stream, xDevice, yDevice, zDevice);
CHECK_ACL(aclrtSynchronizeStream(stream));
// 将Device上的运算结果拷贝回Host
CHECK_ACL(aclrtMemcpy(zHost, outputByteSize, zDevice, outputByteSize, ACL_MEMCPY_DEVICE_TO_HOST));
WriteFile("./output/output_z.bin", zHost, outputByteSize);
// 释放申请的资源
CHECK_ACL(aclrtFree(xDevice));
CHECK_ACL(aclrtFree(yDevice));
CHECK_ACL(aclrtFree(zDevice));
CHECK_ACL(aclrtFreeHost(xHost));
CHECK_ACL(aclrtFreeHost(yHost));
CHECK_ACL(aclrtFreeHost(zHost));
// AscendCL去初始化
CHECK_ACL(aclrtDestroyStream(stream));
CHECK_ACL(aclrtDestroyContext(context));
CHECK_ACL(aclrtResetDevice(deviceId));
CHECK_ACL(aclFinalize());
编译运行
bash run.sh -r npu -v Ascend910A
输出结果
Scanning dependencies of target add_npu
[ 33%] Building CCE object cmake/npu/CMakeFiles/add_npu.dir/__/__/add_custom.cpp.o
[ 66%] Building CCE object cmake/npu/CMakeFiles/add_npu.dir/__/__/main.cpp.o
[100%] Linking CCE executable ../../../add_npu
[100%] Built target add_npu
INFO: compile op on npu succeed!
INFO: execute op on npu succeed!
test pass
这篇关于Ascend C Add算子样例代码详解的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






