本文主要是介绍LeetCode题练习与总结:克隆图--133,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
一、题目描述
给你无向 连通 图中一个节点的引用,请你返回该图的 深拷贝(克隆)。
图中的每个节点都包含它的值 val(int) 和其邻居的列表(list[Node])。
class Node {public int val;public List<Node> neighbors;
}
测试用例格式:
简单起见,每个节点的值都和它的索引相同。例如,第一个节点值为 1(val = 1),第二个节点值为 2(val = 2),以此类推。该图在测试用例中使用邻接列表表示。
邻接列表 是用于表示有限图的无序列表的集合。每个列表都描述了图中节点的邻居集。
给定节点将始终是图中的第一个节点(值为 1)。你必须将 给定节点的拷贝 作为对克隆图的引用返回。
示例 1:
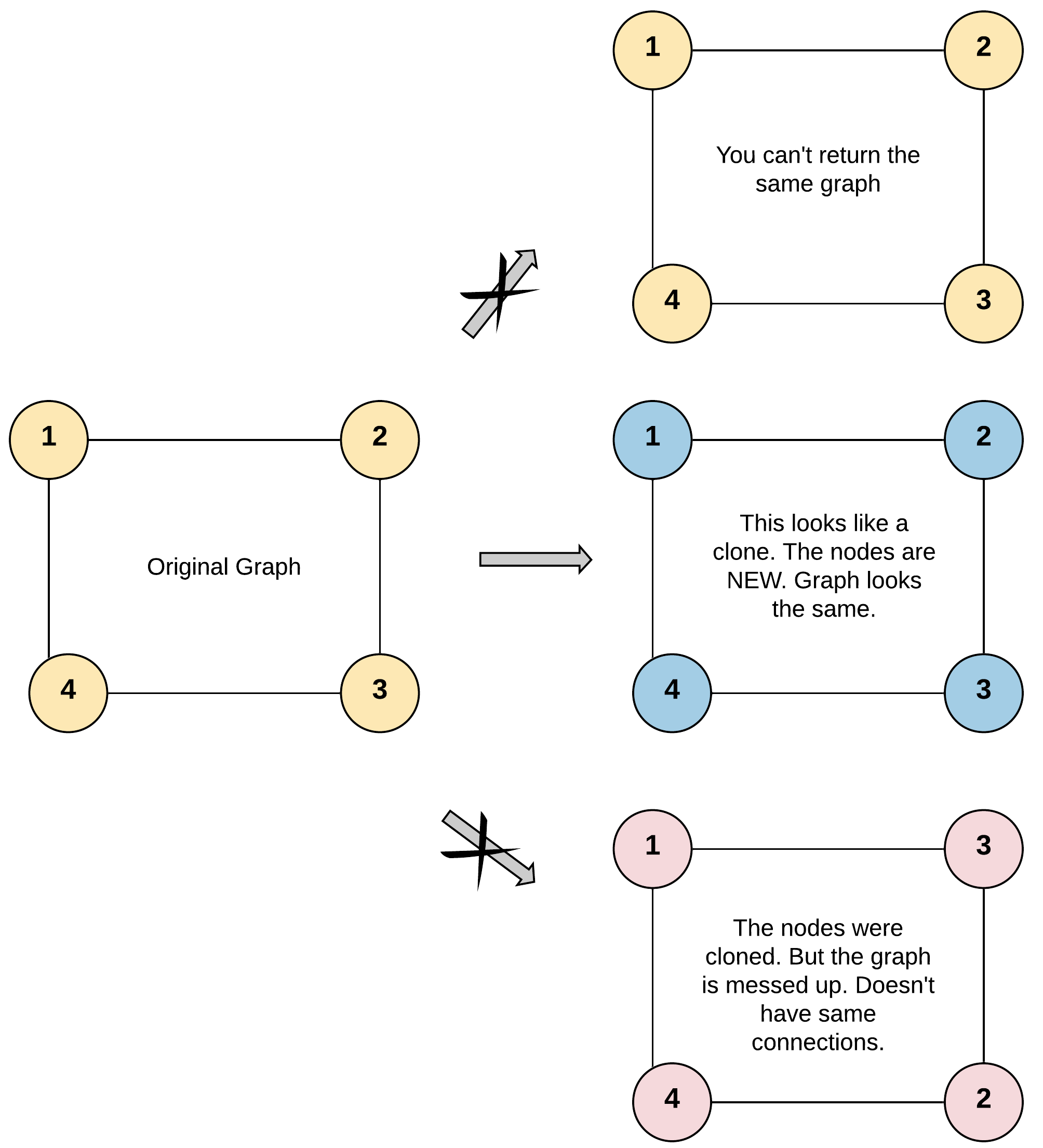
输入:adjList = [[2,4],[1,3],[2,4],[1,3]] 输出:[[2,4],[1,3],[2,4],[1,3]] 解释: 图中有 4 个节点。 节点 1 的值是 1,它有两个邻居:节点 2 和 4 。 节点 2 的值是 2,它有两个邻居:节点 1 和 3 。 节点 3 的值是 3,它有两个邻居:节点 2 和 4 。 节点 4 的值是 4,它有两个邻居:节点 1 和 3 。
示例 2:
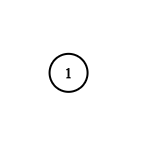
输入:adjList = [[]] 输出:[[]] 解释:输入包含一个空列表。该图仅仅只有一个值为 1 的节点,它没有任何邻居。
示例 3:
输入:adjList = [] 输出:[] 解释:这个图是空的,它不含任何节点。
提示:
- 这张图中的节点数在
[0, 100]之间。 1 <= Node.val <= 100- 每个节点值
Node.val都是唯一的, - 图中没有重复的边,也没有自环。
- 图是连通图,你可以从给定节点访问到所有节点。
二、解题思路
这个问题是图遍历和复制的问题。可以使用深度优先搜索(DFS)或广度优先搜索(BFS)来遍历图。遍历过程中,需要记录已经访问过的节点,以避免重复访问。同时,在复制每个节点时,需要复制它的邻居列表。
具体步骤如下:
1. 检查输入节点是否为空。如果为空,返回null。
2. 创建一个HashMap来存储原始节点和对应的克隆节点,用于避免重复克隆。
3. 使用DFS或BFS遍历图,对于每个访问的节点:
- 如果该节点已经在HashMap中,说明已经克隆过,直接从HashMap中获取克隆节点。
- 如果该节点不在HashMap中,创建一个新的克隆节点,并将原始节点和克隆节点的映射关系存入HashMap。
- 遍历原始节点的邻居列表,对于每个邻居节点,递归地进行克隆操作,并将克隆后的邻居节点添加到克隆节点的邻居列表中。
4. 返回HashMap中存储的输入节点的克隆节点。
三、具体代码
import java.util.ArrayList;
import java.util.HashMap;
import java.util.List;class Solution {public Node cloneGraph(Node node) {if (node == null) {return null;}HashMap<Node, Node> visited = new HashMap<>();return dfs(node, visited);}private Node dfs(Node node, HashMap<Node, Node> visited) {if (visited.containsKey(node)) {return visited.get(node);}Node cloned = new Node(node.val, new ArrayList<>());visited.put(node, cloned);for (Node neighbor : node.neighbors) {cloned.neighbors.add(dfs(neighbor, visited));}return cloned;}
}
四、时间复杂度和空间复杂度
1. 时间复杂度
- 对于每个节点,我们只访问一次,因为一旦一个节点被克隆并放入
visited哈希表中,我们就不会再次克隆它。 - 对于每个节点,我们需要遍历其所有的邻居节点,并进行克隆。
- 假设图中一共有
N个节点和E条边,那么每个节点都会被访问一次,每条边也会被访问一次(因为每条边都会使我们在邻居节点之间进行一次转移)。 - 因此,时间复杂度为
O(N + E),其中N是节点数,E是边数。
2. 空间复杂度
- 我们需要一个
visited哈希表来存储已经访问过的节点和它们的克隆节点,这个哈希表的大小与节点数N成正比。 - 递归调用栈的最大深度取决于图的最大深度,也就是图中的最长路径。在最坏的情况下,图可能是一个链状结构,递归调用栈的深度为
N。 - 因此,空间复杂度也是
O(N),主要取决于visited哈希表和递归调用栈的空间消耗。
综上所述,该算法的时间复杂度为O(N + E),空间复杂度为O(N)。
五、总结知识点
-
图的深度优先搜索(DFS):这是一种用于遍历或搜索树或图的算法。在这个算法中,我们从一个节点开始,探索尽可能深的分支,直到目标节点,然后回溯到之前的分支点,探索新的分支。
-
递归:
dfs函数是递归的,它调用自身来处理图的每个节点和它们的邻居。 -
哈希表(HashMap):
visited是一个哈希表,用于存储已经访问过的节点和它们的克隆。它提供了快速的查找和插入操作,这对于避免重复克隆节点至关重要。 -
引用类型和值类型:在Java中,
Node是一个引用类型,这意味着visited哈希表中存储的是节点的引用,而不是节点的副本。 -
链表(ArrayList):
ArrayList用于存储节点的邻居列表。它是一个可调整大小的数组实现,提供了对列表的快速随机访问。 -
对象的创建和初始化:
new Node(node.val, new ArrayList<>())创建了一个新的Node对象,并使用节点值和空的邻居列表进行了初始化。 -
迭代:
for循环用于迭代节点的邻居列表,对每个邻居节点调用dfs函数。 -
函数返回值:
dfs函数返回克隆后的节点,这允许递归调用将克隆的邻居节点添加到当前节点的邻居列表中。 -
基础数据结构操作:代码中涉及了哈希表和列表的基本操作,如添加元素(
put和add)和检查元素是否存在(containsKey)。 -
边界条件处理:代码首先检查输入节点是否为空,这是处理图问题时常见的边界条件。
以上就是解决这个问题的详细步骤,希望能够为各位提供启发和帮助。
这篇关于LeetCode题练习与总结:克隆图--133的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






