本文主要是介绍伸缩立方,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
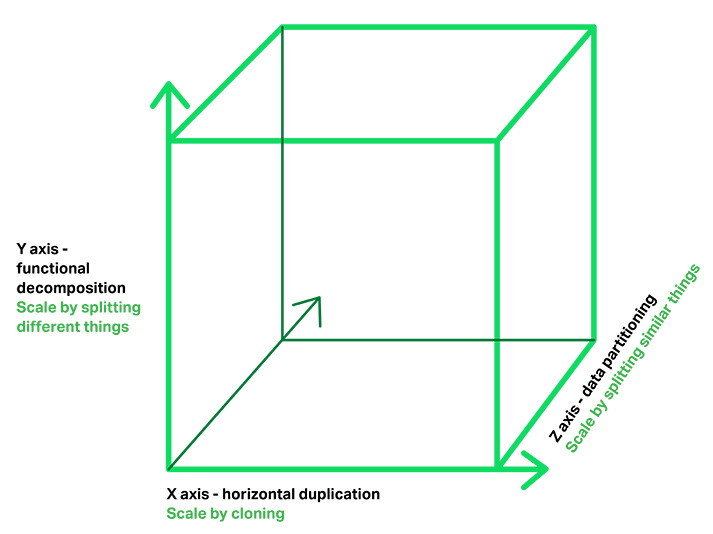
在这个模型中,通过在负载均衡器之后运行多份拷贝来伸缩应用的方式叫做X轴伸缩。另外两种伸缩方式叫Y轴伸缩和Z轴伸缩。微服务架构是Y轴伸缩的,让我们也同时认识下X轴和Z轴伸缩。
X轴伸缩
X轴的伸缩,由负载均衡器后运行的多个拷贝构成。如果有N份拷贝,每份拷贝处理1/N的负载。这是个简单常用的伸缩应用的方式。
这个方法的缺点是,由于每份拷贝潜在地访问所有数据,缓存需要更多内存才能更加有效。另一个问题是,这个方法并没有解决不断增加的开发和应用复杂度的问题。
Y轴伸缩
不同于X轴和Z轴那种运行多份完全相同应用的伸缩方式,Y轴伸缩将应用分成多份不同的服务。每份服务负责一个或多个紧密相关的功能。将应用分解为多个服务的方法有很多。一种方法是使用动词分解,服务实现单个用例,如检出。另外的选择是通过名词来分解,服务负责与特定实体相关的所有操作,如客户管理。某个应用可以采用动词分解和名词分解的组合。
Z轴伸缩
使用Z轴伸缩的话,每个服务器运行一份完全相同的代码。在这个角度上,它与X轴伸缩类似。最大的区别在于每个服务器只负责数据的一个子集。系统的某些组件负责将请求路由到合适的服务器上。一个常用的路由标准是请求的属性,如被访问的实体主键。另一个常用路由标准是客户类型。例如,应用可以将SLA(服务水平协议, Service Level Agressment)更高的付费客户的请求路由到处理能力更强的服务器上去。
Z轴分割常用于数据库的伸缩。数据依据每个记录的属性被跨服务器地分区(也叫分片)。这这个例子中,RESTAURANT表的主键用于在两个不同数据库服务器间对数据行进行分区。注意通过部署一个或多个服务器作为备份/从服务器(replicas/slaves),X轴克隆也可以用于每个分区。Z轴伸缩也可用于应用。在这个例子中,搜索服务包含很多分区。路由将每个内容条目发送到合适的分区(会在分区中被索引和储存)。聚合器(aggregator)将每个查询发送到所有分区,并将所有响应结果组合在一起。
Z轴伸缩的好处:
- 每台服务器只处理数据的一个子集。
- 提升了缓存的利用率,减少了内存占用和I/O流量。
- 提升了事务的可伸缩性,因为请求一般分布在多台服务器上。
- 另外,Z轴伸缩提升了故障隔离(fault isolation),因为故障只造成一部分数据不能访问。
Z轴伸缩的缺点:
- 提高了应用复杂度。
- 需要实现一个分区方案,可能很棘手,尤其当我们需要重新对数据进行分区时。
- 它没有解决不断增加的开发和应用复杂度。为了解决这些问题,我们需要采用Y轴伸缩。
这篇关于伸缩立方的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!







![[大屏适配]根据屏幕尺寸获取伸缩比例](/front/images/it_default.gif)