本文主要是介绍视频云沉浸式音视频技术能力探索与建设,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
概述
随着传输技术、显示技术与算力的持续提升,用户对于音视频体验的需求在提高,各家设备厂商也在探索和推出对应的技术与产品。打造空间感的空间视频与空间音频是其中最为关键的2项技术,bilibili视频云在这两项技术领域也进行了相关代探索与建设。
空间视频
背景
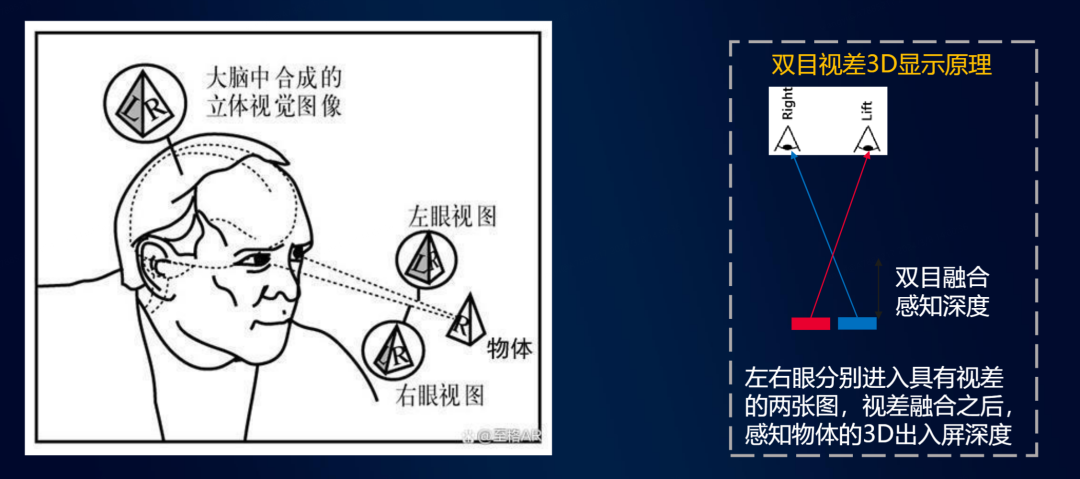
双目视差3D显示原理
人类视觉的空间感,来自于人类双眼的视角差,传统的2D视频为双眼提供的相同视角的画面,在此基础上,为双眼分别提供一幅互相具有视角差的画面,在设备端,通过各类光学和显示组件,降对应的画面投射到对应的眼镜,即可显著提升观影的沉浸感。对于视频云团队,我们最为关心的数据编码层面相关的技术。该领域目前存在2类方案,传统的2D编码与苹果在最新产品上使用的MultiView编码。
相比使用传统2D HEVC编码3D内容,MV-HEVC有大约20%~30%的压缩率提升,且在解码侧不支持MV-HEVC解码时,仍然可以以单目的形式得到单眼的画面,行为与2D视频一致。
目前该技术的生态还较为薄弱,生产侧目前只有iPhone15pro系列与VisionPro眼镜支持拍摄,只能在VisionPro眼睛上实现3D观看。
2D编码

2D编码空间视频
如上图所示,该编码方式是将空间视频的左右眼画面在空域内合并在一个2D画面上,使用传统的2D视频编解码技术即可实现内容传输,再播放端分割画面后得到左右眼画面,进行3D渲染。根据不同的空间布局与尺寸关系,可进一步区分为如下几种格式:
| 格式 | 内容分辨率 | 单眼分辨率 | 传输分辨率 |
| HSBS 半宽左右 | 1920x1080 | 960x1080 | 1920x1080 |
| FSBS 全宽左右 | 1920x1080 | 1920x1080 | 3840x1080 |
| HOU 半高上下 | 1920x1080 | 1920x540 | 1920x1080 |
| FOU 全高上下 | 1920x1080 | 1920x1080 | 1920x2160 |
该方案开发和执行成本较低,只需在采集与渲染做一些适配开发工作,中间传输都可以复用现有系统。而相对的,由于无法告知视频编码器左右眼画面,继而无法有效挖掘左右眼画面之间的数据冗余度,造成编码压缩率较低,需要较大的传输带宽,一般来说同内容的3D视频会比其2D版本需要额外的50%~100%的传输带宽。
当前线上也已经有采用该方案的视频投稿,如BV1Nh411a7Q1。
MultiView编码
MV编码是视频编码领域,针对类似场景而生的技术方案,可以有效利用左右眼画面之间的数据冗余,显著提升压缩率。而此次苹果在iPhone15pro和VisionPro上采用的,就是在HEVC基础之上的MV-HEVC技术。
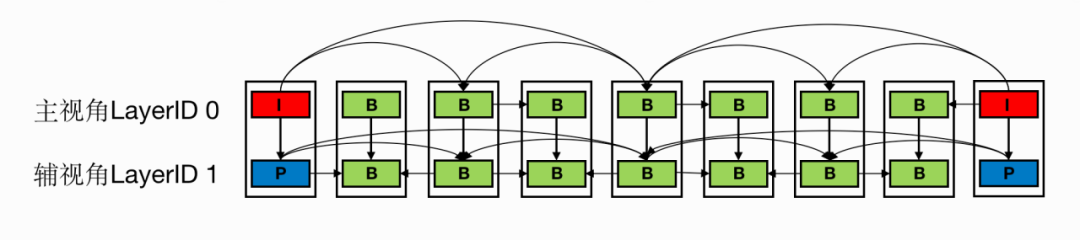
MultiView编码原理
相比使用传统2D HEVC编码3D内容,MV-HEVC有大约20%~30%的压缩率提升,且在解码侧不支持MV-HEVC解码时,仍然可以以单目的形式得到单眼的画面,行为与2D视频一致。
目前该技术的生态还较为薄弱,生产侧目前只有iPhone15pro系列与VisionPro眼镜支持拍摄,只能在VisionPro眼睛上实现3D观看。
视频云空间视频探索与建设
规划方案
综合考虑两种方案各自的优缺点,我们认为较为适合当前点播类业务形态的方式可以简单归纳为:
-
支持以MV-HEVC的投稿输入,以支撑iPhone用户的UGC投稿
-
云端侧实现苹果设备拍摄的MV-HEVC空间视频到SBS空间视频的转码,使用SBS进行分发与播放,来实现尽可能多的VV覆盖
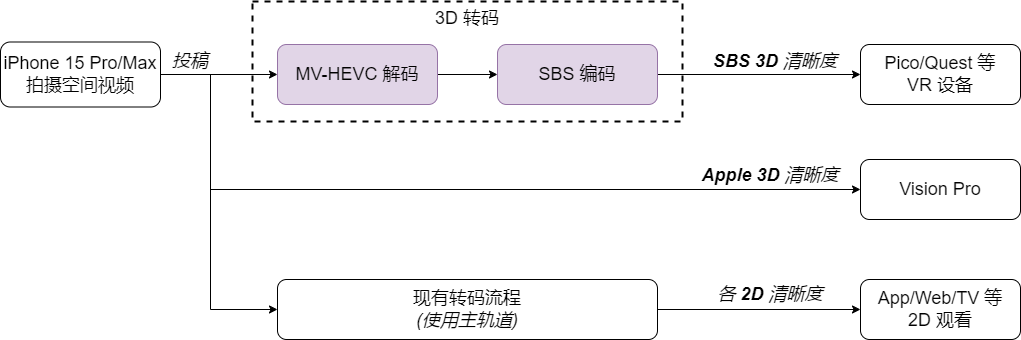
空间视频转码方案
基于该方案的需求,我们需要建设的是从苹果MV-HEVC到SBS的转码能力,该项工作目前还未得到开源社区的支持,我们根据自身业务需求,基于现有的转码框架进行了相关能力的开发,主要覆盖以下3个部分的工作。
空间视频识别
根据苹果提供的封装侧技术文档,通过在转码框架中识别相应的MP4 BOX,从而实现了使用命令行识别出苹果空间视频的能力。结果示例如下:
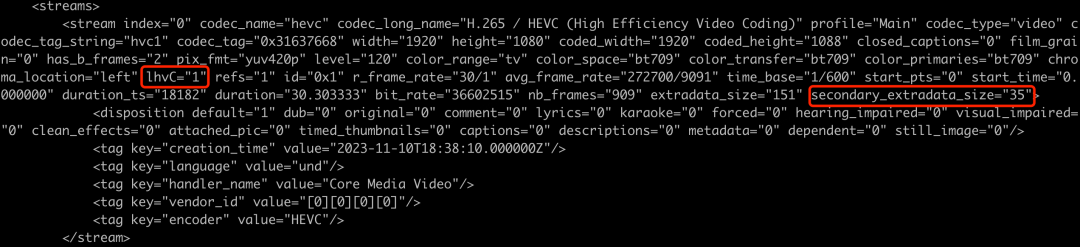
空间视频识别结果示例
HTM解码器封装&集成
目前的多媒体开源框架都未提供MV-HEVC解码器,使用常规解码器解码码流只能得到layer-0的主视角画面。所幸,我们在JCT-3V组织的HTM编解码库找到了相关能力的支持,但是项目本身是为了验证H265协议而实现的,只针对二进制流数据进行操作,需要将其封装成转码框架接口的解码器。
同时为了让解码器能正常工作,需要在mov的解封装器中获取lhvC信息。我们添加新的mvhevc_mp4toannexb二进制滤镜,将封装信息嵌入到数据流中,得到二进制数据。然后送入HTM解码器得到layer0,layer1单独的raw数据。
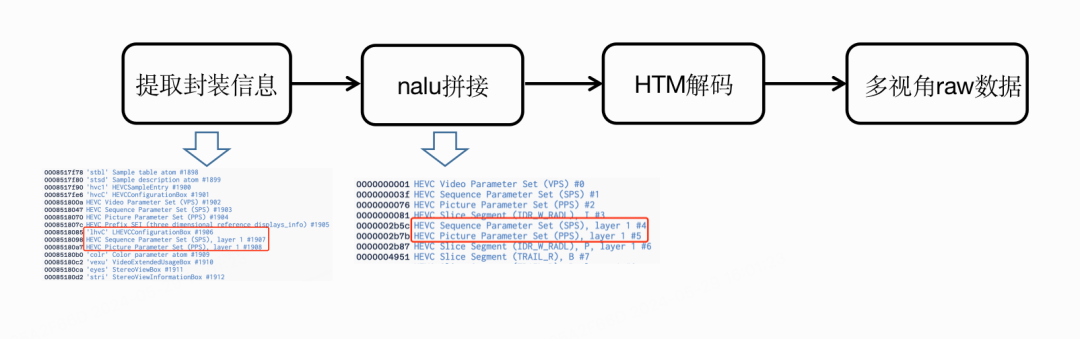
HTM使用流程
SBS转帧输出
要得到正确的SBS画面,需要确定MV-HEVC的layer与视角的映射关系,这部分由码流中的vps和sei信息来确定。我们使用转码框架的现有能力提取到vps信息。通过修改HTM接口,对外暴露解码得到的sei信息。

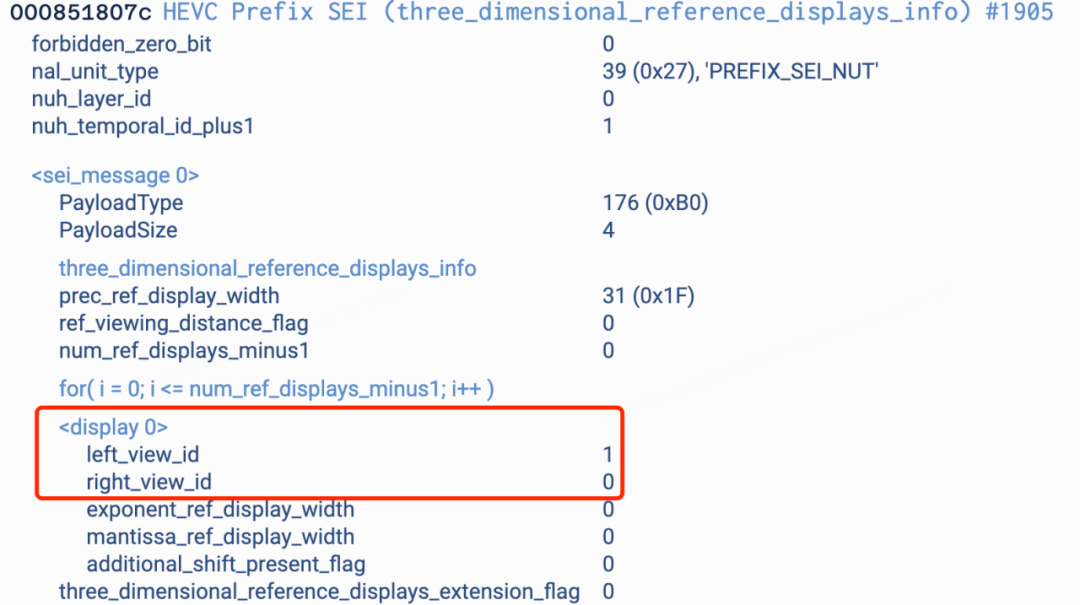
vps信息(上)sei信息(下)
如果要得到SBS格式视频,还需要对raw数据进行左右眼帧对齐、图像拼接,二次编码等操作。我们对HTM封装新的接口,并将其集成在转码框架中,得到了新的解码器mv_hevc。在新解码器中实现SBS格式数据生成逻辑,再根据所需要的SBS格式输出结果,搭建了如下的处理流程
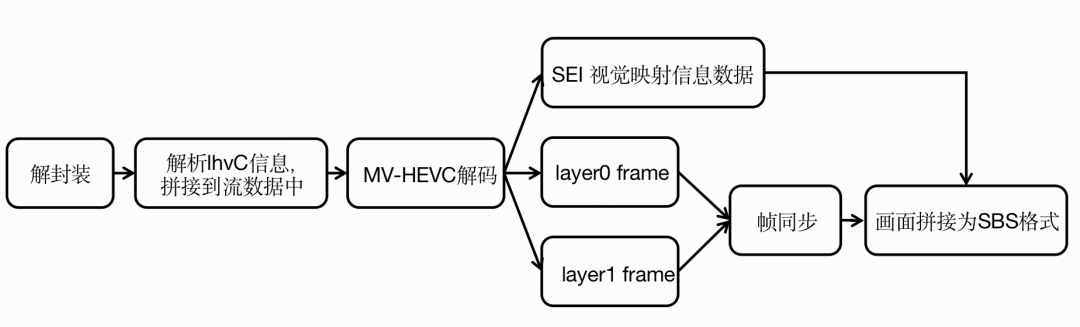
空间视频转码流程示意图
空间视频转码结果示例如下图:


半宽拼接HSBS(上) 全宽拼接FSBS(下)
空间音频
背景
在空间音频领域,视频云曾在2020年接入了杜比全景声的相关能力,从业务侧的反馈也印证了用户对于沉浸式音频的需求,体现了这项技术的价值。
菁彩声(Audio Vivid)是全球首个基于AI技术的三维声标准,由世界超高清产业联盟(简称UWA联盟)率先提出。2023年7月,其成为了国家4K超高清电视技术应用实施指南 (2023 版:http://www.nrta.gov.cn/attach/0/e0e2b226e24c4a74a910bbcc02ccc147.pdf)中的空间音频标准,这也间接指引了我们在该技术领域的投入方向。
Audio Vivid三维声技术
三维声音相对于传统声音增添了空间和方位感,使听众能够沉浸在仿佛置身真实世界中的声音体验中。
Audio Vivid的实现方式主要有以下几种方式:基于声道的实现、基于声床的实现、基于声场的实现、基于对象的实现,其中对象信号可以和另外三种信号互相组合,如下图。

Audio Vivid的三种实现方式
传统的5.1或者7.1声道制作的音频,在超过声道数目的扬声器下无法发挥出扬声器的最大价值——更多的扬声器也只能渲染出音频文件所指示的声道数目。
Audio Vivid中基于声床+对象的实现很好地解决了上述的问题,声床信号承载了基本环境声,对象信号承载的是一系列单声道的音频及其元数据。它在生产端不需要考虑声道的布局,只需要考虑对象的位置,强度,大小,然后将其编码为元数据即可。
在渲染端播放器会根据扬声器的数目和元数据来进行渲染,这样不仅能发挥更多扬声器的作用,还能将声音在三维空间中的运动准确重现出来,极具沉浸感。除此,在渲染端,用户可以根据自身的喜好对每个对象的位置和属性进行实时调整,从而满足用户多样化的需求。
Audio Vivid也包含基于声场的实现方式。基于声场的实现方式主要依托于HOA(Higher Order Ambisonics)技术,它是一种定义在球体表面上的3D声场建模格式,可以在任何设备(如耳机、扬声器、音箱)上对声场实现准确处理和重构。
工程化实践
目前B站已经在云端建设了完整的Audio Vivid处理能力。对于投稿的Audio Vivid音频,我们能透传一路Audio Vivid音频作为一路音轨。同时,为了兼容那些没有Audio Vivid渲染能力的终端设备,我们还会转出一路经过双耳渲染的立体声音轨。
若终端设备有能力进行Audio Vivid的渲染,它可以通过多组扬声器来呈现Audio Vivid的三维声效,或者进行双耳渲染。否则,终端设备将以兼容模式播放由服务端渲染好的立体声音轨。下图详细展示了Audio Vivid在服务端和终端的处理流程。
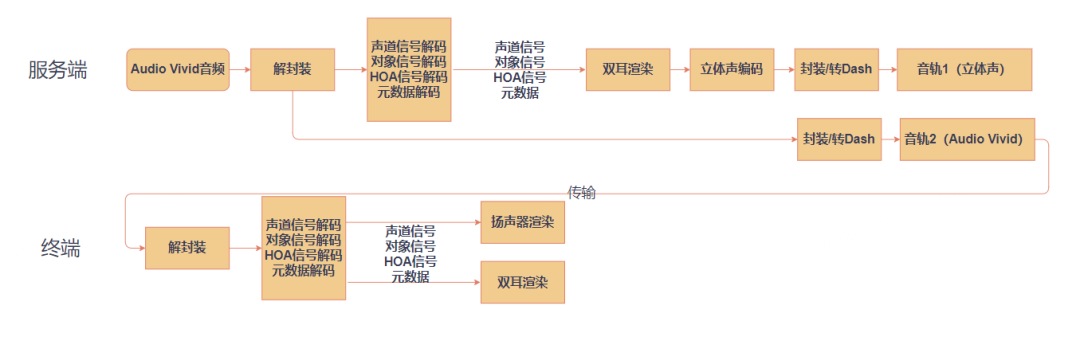
Audio Vivid服务端和终端处理流程示意图
我们在云端的转码过程中进行了大量的工作,以集成Audio Vivid。
参考处理流程
UWA联盟提供的参考代码是基于文件流的,如果不修改参考代码进行二进制渲染,我们只能先使用参考代码进行解封装,将以MP4封装的Audio Vivid音频解封装为xxx.av3a。
之后,需要调用参考代码的编译得到的解码二进制文件,将其用于解码为多通道WAV音频流。最后,调用参考代码将多通道WAV渲染为立体声WAV,并通过转码二进制进行立体声编码。
这种多步骤的双耳渲染方法效率较低,因此我们基于参考代码进行了一系列改造,并将其整合到现有的音频生产流程中
视频云处理流程
基于参考代码,进行相关改动
-
将仅支持windows平台的Audio Vivid解码的参考代码移植到linux,以支持服务端的的解码;
-
将仅支持文件流的解码模块修改为内存流,以方便接入其它流行的多媒体框架;
-
将解码模块和渲染模块重构后接入多媒体框架,以便进行流式处理;
重构前和重构之后的双耳渲染流程示意图如下图:
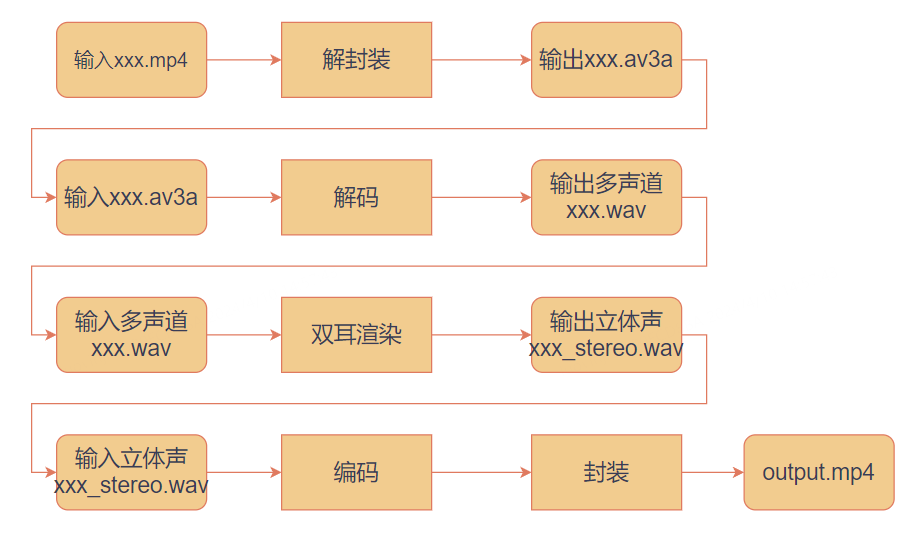
重构代码前的双耳渲染处理流程示意图

重构代码后的双耳渲染处理流程示意图
代码重构后,我们只需要一个转码二进制文件,就可以以流式方式对Audio Vivid音频进行解封装、解码、双耳渲染和编码等操作,而无需反复读写文件,从而避免性能下降的问题。这种优化不仅可以缩短处理时间,还可以减少中间过程对存储的消耗,并且非常适用于直播场景。除此,我们也修改了bento4的部分代码,来适配Audio Vivid的转Dash过程,以实现Audio Vivid的动态自适应流媒体传输。
参考资料
-
Multiview High Efficiency Video Coding (MV-HEVC) | HEVC(http://hevc.info/mvhevc)
-
265:High efficiency video coding(https://www.itu.int/rec/T-REC-H.265)
-
https://developer.apple.com/av-foundation/HEVC-Stereo-Video-Profile.pdf
-
三维菁彩声(Audio Vivid) 技术白皮书(V1.0)
-
T/UWA 009.1-2022 三维声音技术规范 第 1 部分:编码分发与呈现
-End-
作者丨lhcde、猫先生、老王
这篇关于视频云沉浸式音视频技术能力探索与建设的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






