本文主要是介绍属性归因和对齐在商品企划中的应用,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!

公众号 系统之神与我同在
业务背景:
在电商运营中,分析哪些变量会对顾客是否购买产生影响是十分重要的。然而我们对顾客进行商品描述和对工厂进行商品描述时所采用的语言是完全不同的,顾客看到的是关键词“仙女、超仙、气质”等等,而我们对工厂的要求就要具体到衣服的面料,工艺等等。也就是说,生产语言和营销语言之间存在描述的鸿沟!

PART1:属性归因
相关研究:
对于属性归因的相关研究有下:
·GAM广义加性模型——优点:具有很强的可解释性,缺点:对复杂任务的拟合能力较弱。
·LIME——优点:模型无关,简单模型解释复杂模型,缺点:拟合准确率不高 ,二次误差,时间复杂度高。
·Lstm+attention+adversarial——优点:考虑了混淆变量的影响。
·Lstm+attention+Res——优点:考虑了混淆变量的影响。
形式化因果关系:
问题描述:属性归因要解决的问题则是,如何找到商品中哪些属性影响了买家的决策。
在实际业务场景下,我们将变量分为如下三种:
·类文本变量cpv(类目-属性-属性值)简称T:解释变量。
·混淆变量(简称C),包括:品牌,人气,库存,淘宝卖家交易数据, 店铺人气,店铺·评分,店铺销量、商品好评率,价格等。
·目标变量ipv(item page view)简称Y:被解释变量。
我们使用网站用户的搜索数据进行训练,来预测ipv,目标是降低混淆变量的干扰,预测准确。
衡量准确性的指标为加权准确率(Weighted Mean Absolute Percentage Error):
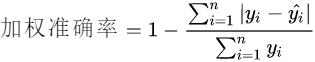
为了达到该目标,目前推出了三个版本的模型:
V1:Transformer+Attention+Residualization

该模型分为两部分:使用cpv预测ipv和使用混淆变量预测ipv,然后将两部分进行加和。其中loss=loss(ipv)+loss(ipv’)
模型的acc和loss如下:

V1的缺陷:
加性模型会受到变量自身方差的影响,会出现两个描述基本相同的商品,最终ipv相差很大的情况。

基于V1的缺陷,对目标函数进行如下修正:
ipv由两部分组成:
1.商品被用户看到的概率(曝光率)
2.用户看到商品后,点击商品的概率(点击率)
基于数据观察,提出假设:ipv由曝光率*点击率决定,cpv 中一部分决定了曝光率,混淆变量一部分在曝光后影响点击,cpv 中一部分直接影响流量,混淆变量中一部分直接影响流量。
![[公式]](https://img-blog.csdnimg.cn/1d30d1d662e74f09b0b6107d259e1074.png)
其中,X为混淆变量,Gate表示门控机制,E代表cpv的encoding,f是FNN层。
V2:Transformer+Attention+Residualization+GateNN
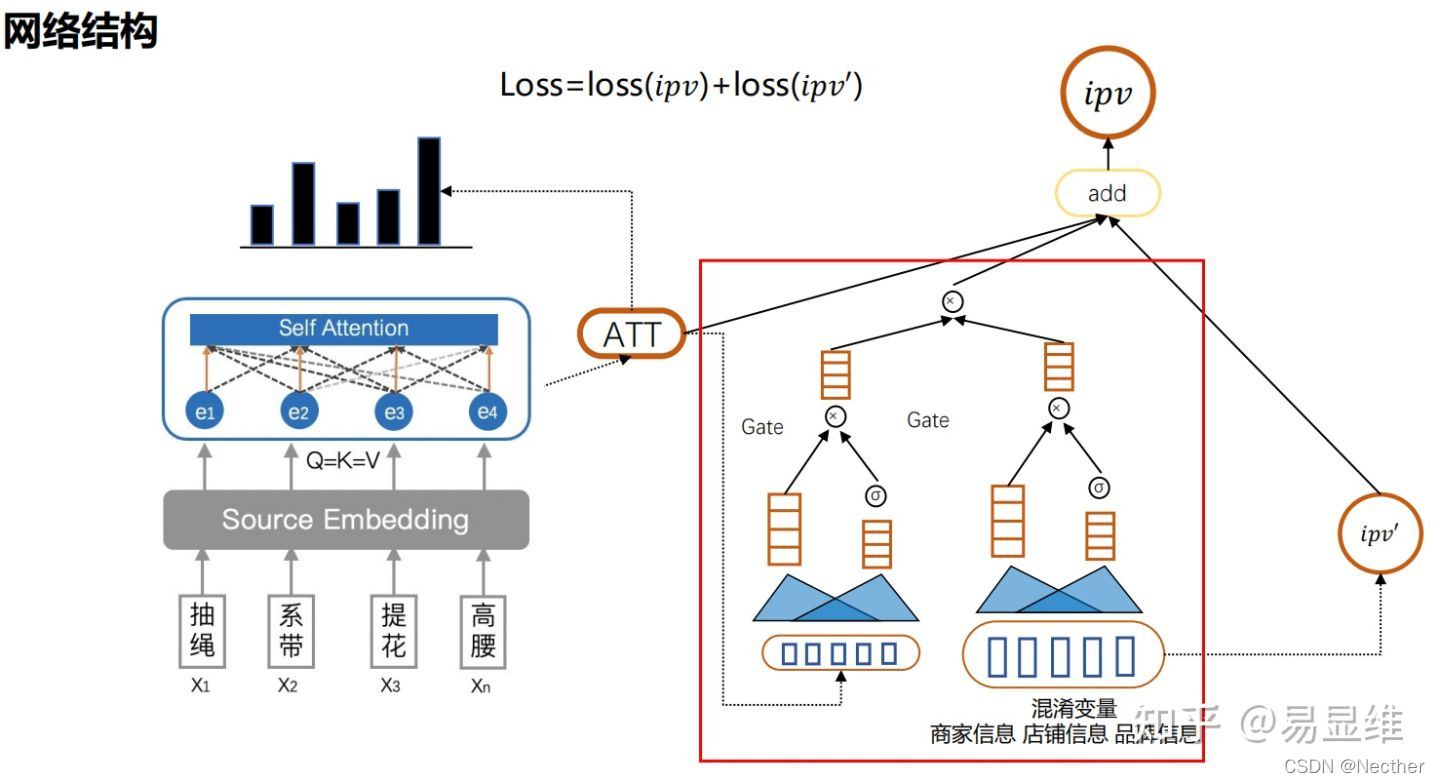
模型V2的acc和loss如下:

V3: Transformer+Attention+Res+GateNN+mutil_learning
V3中加入了多目标学习,约束模型的学习方向。并且加入另外两个策略:
1.额外信息:query命中cpv的次数,query命中越多的cpv,相对越重要。
2.采用指数衰减的学习率,通过query count在训练初期纠正模型训练的方向。
V2和V3在不同变量的重要性得分对比如下:


V3的acc和loss如下:

V3模型的结果:

PART2:属性对齐
相关研究:
目前许多属性对齐是基于神经机器翻译的词对齐来实现的。



研究的热点:如何在Transformer上改进解释效果?
痛点:缺少平⾏语料和弱监督信号,如何从数据本身挖掘?
属性分类-冷启动数据准备:



商品属性分类:




商品属性对⻬—数据集构造:
数据来源于宝贝详情+标题NER,将数据分为两部分:生产属性集source和营销属性集target。

属性对齐模型有如下三个版本:
属性对齐模型 – V1版:Vanilla bi-LSTM Encoder + Decoder

问题:

对问题的分析:
·RNN的编码方式耦合了输入顺序
·本质:CPV不严格是序列关系
·Over/under translation problem
·需要追踪之前的注意力分布做模型约束
改进:
·编码器替换为Transformer
·平均池化作为全局语义向量
·考虑到解释性,折中使用单层
·引入Coverage机制作为多目标loss
·分类标签修正,增加差异性
属性对齐模型 – V2版:Transformer Encoder + Decoder
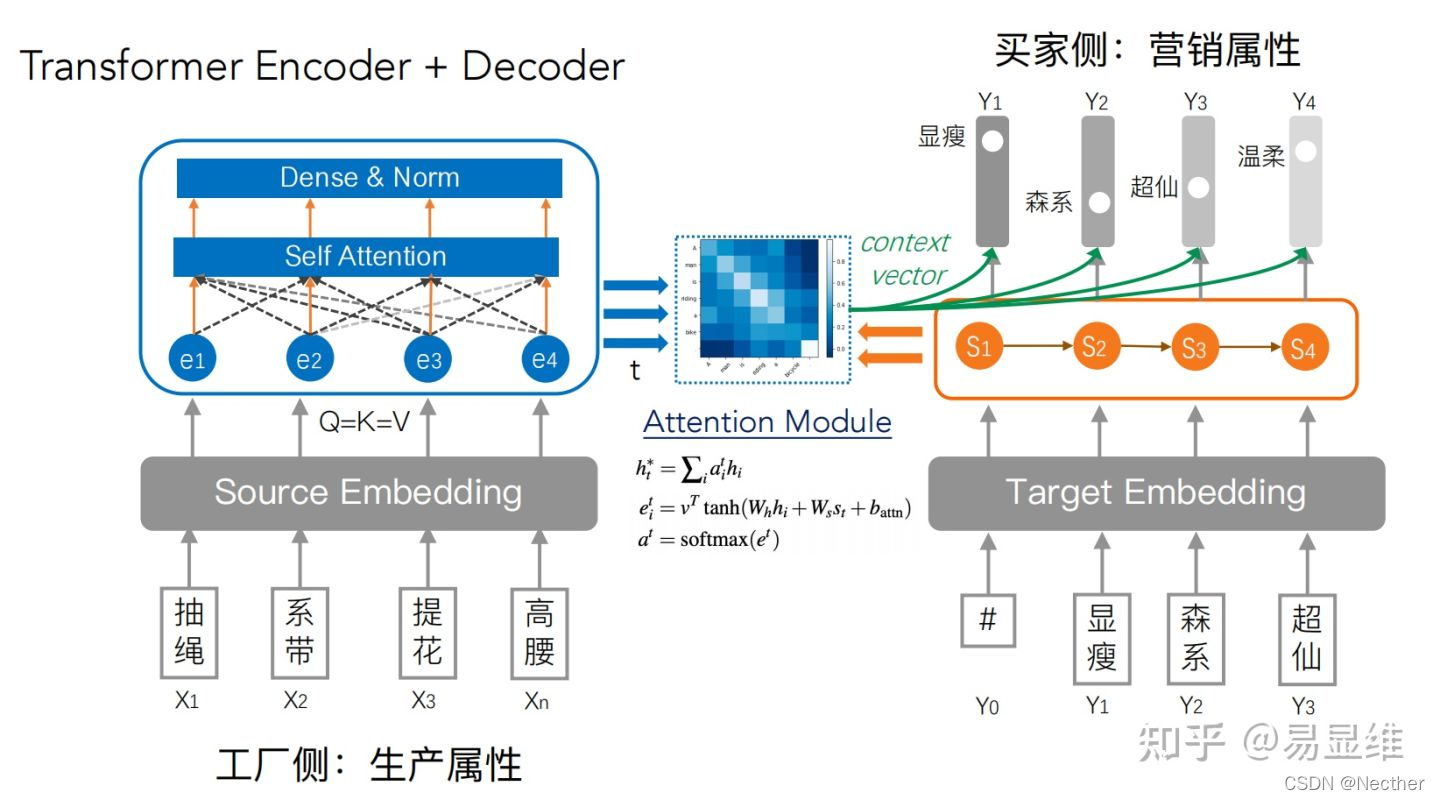
属性对齐模型 – V3版:V2 + Coverage constraint

矩阵分解+后处理:
1.矩阵分解:对营销属性x,取score Top2生产属性y,组成pair对(x, y)作为候选。以叶子类目为单位,聚合所有pair对。
2.排序规则:

3.对⻬结果导出:
CPV对⻬表1:⽣产 → 营销
CPV对⻬表2:营销 → ⽣产



后续改进:1.针对丰富度、差异性不⾜的类⽬优化,2.pipeline形式的误差累积。
PART3:场景应⽤
应用:



多场景赋能:

这篇关于属性归因和对齐在商品企划中的应用的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





