本文主要是介绍基于电商常识图谱的知识表示与应用,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!

公众号 系统之神与我同在
1.电商常识图谱的背景:
电商知识图谱要求用一套数据体系联系用户和商品,通过定义拆解用户需求和多粒度的商品理解,来提升搜索与推荐的匹配效率与体验。
一个电商知识图谱中包括许多常识关系:
·isA
·搭配
·不同类型之间的映射关系:风格对应款式、时间需要款式、场景需要品类…

2.电商常识挖掘的方法:
电商常识挖掘采用的方法是一种阅读理解式的关系抽取。对于一个问题:什么样的连衣裙是减龄的? 通过阅读理解的方式,经由Content:(淘宝攻略)…娃娃领连衣裙穿起来很减龄, 假两件的款型为衣衣增添个性 …,抽取出查询:<风格: 减龄,关系: 风格对应领型,领型: 娃娃领,限制: 品类-连衣裙>。
采用阅读理解的方式进行抽取具有以下几个特点:
·在question中将品类限制和头实体(概念)进行联合encode
·充分利用如今取得极大进展的机器阅读理解技术
·生成的question可以天然地提供给众包和外包进行标注,提高知识审核的效率
电商常识阅读理解数据集包含65k个问题,420k条作为内容的产品描述,95k个不同的答案,举例如下:

在该数据集上不同的模型表现为:

3.电商常识的表示方法
电商常识表示的难点在于:
1.常识图谱关系稀疏,比事实类图谱密度低约100倍,常用的知识表示模型对稀疏图谱的表征效果不佳。
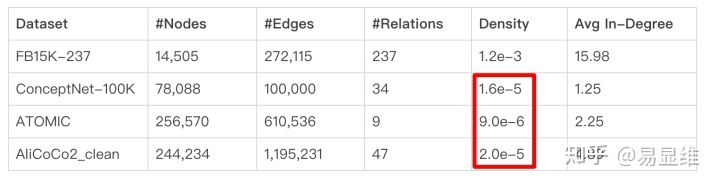
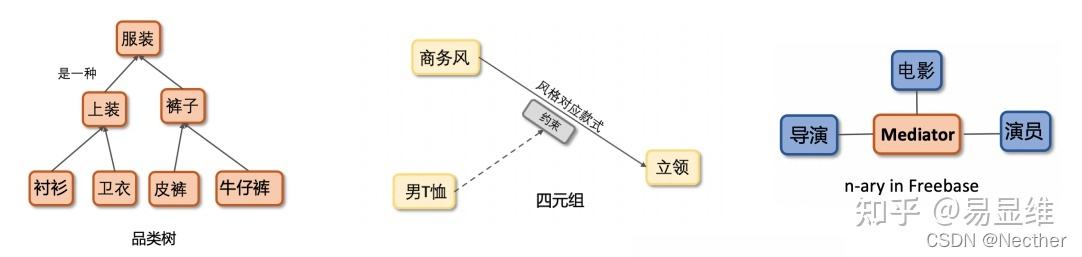
2.电商图谱特有的数据结构,如品类树型结构,品类约束下的n-ary结构(四元组)等,常用的三元组模型不适合直接套用。
对于常识图谱关系稀疏的问题,通过如下两种方法来解决:
·引入外部语义增强:BERT
·结构特征增强:Graph Embedding
对于电商图谱特有的数据结构:
·针对不同数据结构单独建模,多任务共享embedding联合训练
·树型结构: Poincare Embedding
·n-ary结构:品类映射Decoder

在进行实验时,为了保证实验的公平性,采取了如下做法:
·增加虚拟节点和虚拟边,将一条四元组拆分成语义等价的七条三元组(1+6)
·保持四元组的必要性:信息冗余

在三个方面链接实验的预测结果:
·整体性能
·分数据结构的性能
·虚拟边的帮助
实验结果如下:

4.电商常识的应用方法
拿电商常识在淘宝推荐上的应用来举例:
1.解决query和title之间的语义存在gap的问题:query中经常会出现偏口语、非正式(12% in Taobao)的语言,而title则是相对正式和标准的商家语言。
电商常识则可以进行Query改写:直接利用高准电商常识关系数据,将偏口语非正式的query词改写成商家语言,得以召回相关的商品。例如Query: 漏肚子连衣裙,Rewrite Query: 露脐连衣裙。
2.为模型提供识别搜索相关性的能力:query中口语化的表述和title中偏标准的描述之间的映射可以被电商常识关系关联起来;将知识表示算法学到的表征隐式建模到相关性模型中。
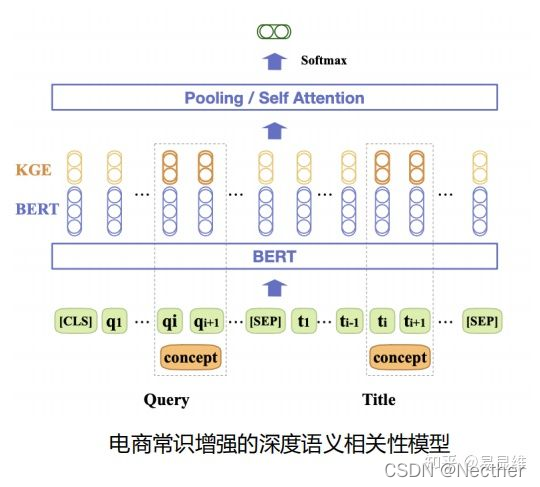
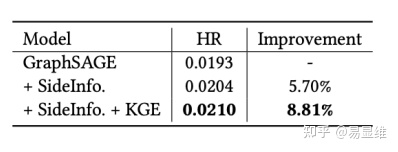
3.推荐商品召回:通过电商常识关系建模不同表述和维度的side info,使得side info语义相关的商品在向量空间的距离更近。电商常识则可以将能链接到常识图谱中的side info对应的KGE表征建模到图表征学习模型中。

这篇关于基于电商常识图谱的知识表示与应用的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!







