本文主要是介绍【计算机系统结构期末复习】第五章,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
系列文章
第一章
第二章
第三章
第四章
目录
- 系列文章
- 1. 选择题
- 1.1 解释下列术语
- 1.2 地址映象方法有哪几种?它们各有什么优缺点?
- 1.3 简述减小Cache失效开销的几种方法
- 1.4 在“Cache—主存”层次中,主存的更新算法有哪两种?它们各有什么特点?
- 2. 计算题
- 2.1 Cache性能分析
- 2.2 例题
- 2.2.1 例1
- 2.2.2 例2
- 2.2.3 例3
- 2.2.4 例4
1. 选择题
1.1 解释下列术语
- 多级存储层次:采用不同的技术实现的存储器,处在离CPU不同距离的层次上,各存储器之间一般满足包容关系,即任何一层存储器中的内容都是其下一层(离CPU更远的一层)存储器中内容的子集。目标是达到离CPU最近的存储器的速度,最远的存储器的容量。
- 全相联映象:主存中的任一块可以被放置到Cache中任意一个地方。
- 直接映象:主存中的每一块只能被放置到Cache中唯一的一个地方。
- 组相联映象:主存中的每一块可以放置到Cache中唯一的一组中任何一个地方(Cache分成若干组,每组由若干块构成)。
- 替换算法:由于主存中的块比Cache中的块多,所以当要从主存中调一个块到Cache中时,会出现该块所映象到的一组(或一个)Cache块已全部被占用的情况。这时,需要被迫腾出其中的某一块,以接纳新调入的块。
- LRU:选择最近最少被访问的块作为被替换的块。实际实现都是选择最久没有被访问的块作为被替换的块。
- 写直达法:在执行写操作时,不仅把信息写入Cache中相应的块,而且也写入下一级存储器中相应的块。
- 写回法:只把信息写入Cache中相应块,该块只有被替换时,才被写回主存。
- 按写分配法:写失效时,先把所写单元所在的块调入Cache,然后再进行写入。
- 不按写分配法:写失效时,直接写入下一级存储器中,而不把相应的块调入Cache。
- 命中时间:访问Cache命中时所用的时间。
- 失效率:CPU访存时,在一级存储器中找不到所需信息的概率。
- 失效开销:CPU向二级存储器发出访问请求到把这个数据调入一级存储器所需的时间。
- 强制性失效:当第一次访问一个块时,该块不在Cache中,需要从下一级存储器中调入Cache,这就是强制性失效。
- 容量失效:如果程序在执行时,所需要的块不能全部调入Cache中,则当某些块被替换后又重新被访问,就会产生失效,这种失效就称作容量失效。
- 冲突失效:在组相联或直接映象Cache中,若太多的块映象到同一组(块)中,则会出现该组中某个块被别的块替换(即使别的组或块有空闲位置),然后又被重新访问的情况。
- 2:1Cache经验规则:大小为N的直接映象Cache的失效率约等于大小为N /2的两路组相联Cache的实效率。
- 相联度:在组相联中,每组Cache中的块数。
- Victim Cache:位于Cache和存储器之间的又一级Cache,容量小,采用全相联策略。用于存放由于失效而被丢弃(替换)的那些块。每当失效发生时,在访问下一级存储器之前,先检查Victim Cache中是否含有所需块。
- 故障性预取:在预取时,若出现虚地址故障或违反保护权限,就会发生异常。
- 非故障性预取:在预取时,若出现虚地址故障或违反保护权限,不发生异常。
- 非阻塞Cache:Cache在等待预取数据返回时,还能继续提供指令和数据。
- 尽早重启动:在请求字没有到达时,CPU处于等待状态。一旦请求字到达,就立即发送给CPU,让等待的CPU尽早重启动,继续执行。
- 请求字优先:调块时,首先向存储器请求CPU所要的请求字。请求字一旦到达,就立即送往CPU,让CPU继续执行,同时从存储器调入该块的其余部分。
- 虚拟Cache:地址使用虚地址的Cache。
- 多体交叉存储器:具有多个存储体,各体之间按字交叉的存储技术。
- 存储体冲突:多个请求要访问同一个体。
TLB:一个专用高速存储器,用于存放近期经常使用的页表项,其内容是页表部分内容的一个副本。
1.2 地址映象方法有哪几种?它们各有什么优缺点?
- 全相联映象。实现查找的机制复杂,代价高,速度慢。Cache空间的利用率较高,块冲突概率较低,因而Cache的失效率也低。
- 直接映象。实现查找的机制简单,速度快。Cache空间的利用率较低,块冲突概率较高,因而Cache的失效率也高。
- 组相联映象。组相联是直接映象和全相联的一种折衷。
1.3 简述减小Cache失效开销的几种方法
让读失效优先于写、写缓冲合并、请求字处理技术、非阻塞Cache或非锁定Cache技术、采用二级Cache。
1.4 在“Cache—主存”层次中,主存的更新算法有哪两种?它们各有什么特点?
- 写直达法。易于实现,而且下一级存储器中的数据总是最新的。
- 写回法。速度快,“写”操作能以Cache存储器的速度进行。而且对于同一单元的多个写最后只需一次写回下一级存储器,有些“写”只到达Cache,不到达主存,因而所使用的存储器频带较低。
2. 计算题
2.1 Cache性能分析
两个重要公式:
-
平均访存时间=命中时间+不命中率×不命中开销 -
CPU时间=(CPU执行周期数+访存次数×不命中率×不命中开销)× 时钟周期时间
其中,不命中开销是指不命中、访存所需要的周期数。
2.2 例题
2.2.1 例1


2.2.2 例2
假设在3000次访存中,第一级Cache 不命中110次,第二级Cache不命中55次。试同:在这种情况下,该Cache系统的局部不命中率和全局不命中率各是多少?
第一级Cache局部不命中率=全局不命中率=110/3000==3.67%
第二级Cache局部不命中率=55/110=50%
第二级Cache全局不命中率=55/3000≈1.83%
- 知识点:

2.2.3 例3
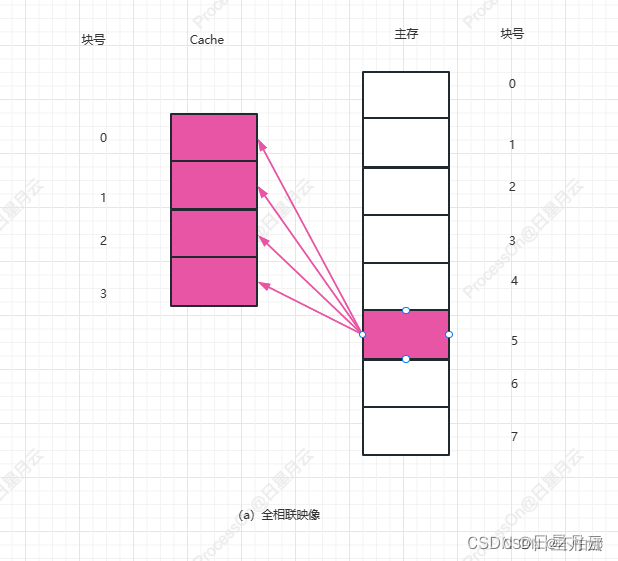
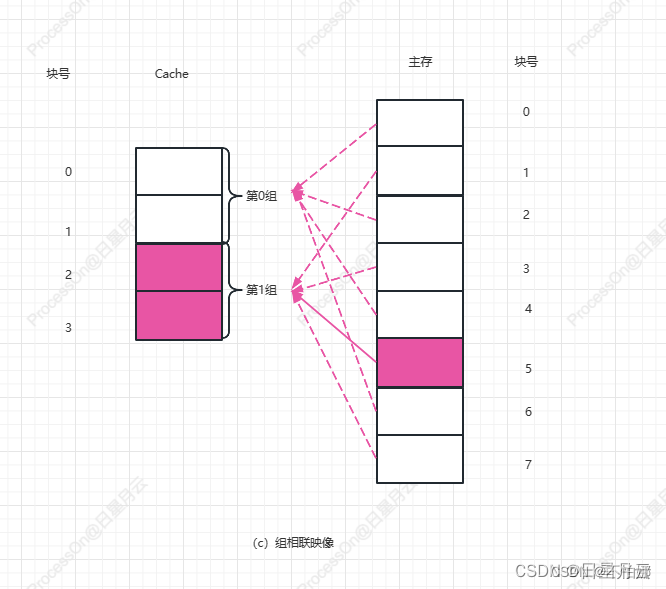
设有一个"Cache-主存”层次,Cache为4块,主存为8块:试分别对于以下3种情况,画出
其映像关系示意图,并计算访存块地址为5时的索引(index)
- 全相联
- 组相联,每组两块
- 直接映像

2.2.4 例4
给定以下的假设,试计算直接映像Cache和两路组相联Cache的平均访问时间以及CPU的性能由计算结果能得出什么结论?
(1)理想Cache情况下的CPI为,时钟周期为2ns,平均每条指令访存1.2次;
(2)两者Cache容量均为64KB,块大小都是32字节;
(3)组相联Cache 中的多路选择器使CPU的时钟周期增加了10%;
(4)这两种Cache的失效开销都是80ns;
(5)命中时间为1个时钟周期;
(6)64KB直接映象Cache的失效率为1.4%,64KB两路组相联Cache的失效率为1.0%。
平均访问时间=命中时间+失效率×失效开销
平均访问时间1-路=2ns+1.4%*80ns=3.12ns
平均访问时间2-路=2ns*(1+10%)+1%*80ns=3.00ns
两路组相联的平均访问时间比较低CPU time= (CPU执行+存储等待周期)*时钟周期
CPU time=IC (CPI执行+总失效次数/指令总数*失效开销)*时钟周期
=IC((CPI执行*时钟周期)+(每条指令的访存次数*失效率*失效开销*时钟周期))
用80代替失效开销*时钟周期
CPU time 1-way=IC(2.0*2ns+1.2*1.4%*80ns)=5.344×IC ns
CPU time 2-way=IC(2.0*2ns*1.1+1.2*1%*80ns)= 5.360×IC ns相对性能比∶
平均访问时间1-路>平均访问时间2-路
CPU time 1way<CPU time 2way
直接映象cache的访问速度比两路组相联cache要慢,
而两路组相联Cache的平均性能比直接映象cache要高。
因此这里选择两路组相联。这篇关于【计算机系统结构期末复习】第五章的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!







