本文主要是介绍【机器学习300问】127、怎么使用词嵌入?,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
在探讨如何使用词嵌入之前,我们首先需要理解词嵌入模型的基础。之前的文章已提及,词嵌入技术旨在将文本转换为固定长度的向量,从而使计算机能够解析和理解文本内容。可以跳转下面链接去补充阅读哦!
【机器学习300问】126、词嵌入(Word Embedding)是什么意思?![]() https://blog.csdn.net/qq_39780701/article/details/139803883 那么,词嵌入模型又是什么呢?简而言之,词嵌入模型是一套特定的方法(通常是深度学习算法),它通过这些方法生成一个词嵌入矩阵。这个矩阵究竟是什么呢?它实际上是由一系列词嵌入向量组合而成的,每个向量代表一个词汇,从而构成了一个独特的词汇表示矩阵。更多的细节在下文中逐一展开。
https://blog.csdn.net/qq_39780701/article/details/139803883 那么,词嵌入模型又是什么呢?简而言之,词嵌入模型是一套特定的方法(通常是深度学习算法),它通过这些方法生成一个词嵌入矩阵。这个矩阵究竟是什么呢?它实际上是由一系列词嵌入向量组合而成的,每个向量代表一个词汇,从而构成了一个独特的词汇表示矩阵。更多的细节在下文中逐一展开。
一、词嵌入矩阵
一上来直接看词嵌入矩阵长什么样:
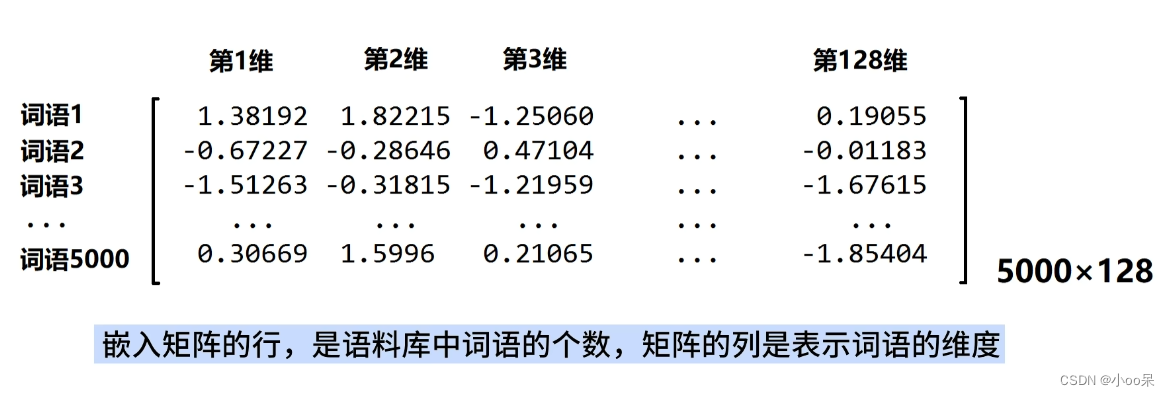
词嵌入矩阵长什么样子其实很清楚,没什么神秘的,但知道它张什么样并不是最关键的。关键点在于它的本质是什么?它怎么来的?以及它有什么用?想要回答出这些问题就得先从最一开始的问题:如何才能让计算机读懂人类的文字?实际上众多NLP概念都上从这个问题出发的,始终带着这个最初问题去学习,能让你有清晰的感受,解答众多“为什么这样做?”的疑惑。
(1)词嵌入矩阵的本质
词嵌入矩阵,本质是一个词汇表,就是把词向量堆叠了起来,它的行数对应词汇表中词的数量,列数则是词嵌入的维度,即每个词向量的长度。矩阵中的每个元素代表了词汇表中某个词的一个特定维度上的值。
例如上图中,词汇表有5000个不同的词,且词嵌入维度设为128,那么词嵌入矩阵就是一个5000行 x 128列的矩阵。计算机要想读懂某个词,通过查找词汇表中每个词的索引,就可以直接从矩阵中获取其对应的词嵌入向量。
(2)词嵌入矩阵怎么构建的?
上面说到了词嵌入矩阵本质是一个特殊的词汇表(能让计算机真正读懂文字的词汇表),词嵌入矩阵通常是词嵌入机器学习算法在训练过程中动态学习得到。这一部分比较庞大,而且很重要,所以我单独写一篇文章来说,这里先简单提一下。矩阵可以通过无监督学习方法(如Word2Vec、GloVe)预先训练好,然后固定或微调使用。
生成词嵌入矩阵的算法模型,被叫做“词嵌入模型或词嵌入算法”如:Word2Vec
(3)词嵌入矩阵有什么用?
词嵌入矩阵一旦构建完成后,通过与分词后的One-Hot编码矩阵进行运算,即可得到每一个词的词向量。
用数学公式表达:
其中,是指某个词的one-hot编码,
是词嵌入矩阵,
是指这个词对应的词向量。
这里讲的“有什么用?”不是指嵌入矩阵能用在什么地方,而是特指:词嵌入矩阵能够和one-hot编码向量相乘得到该词的词向量。

二、 怎么使用词嵌入?
使用词嵌入技术通常有固定的基本步骤,下面就逐一介绍:
(1)基本步骤说明
① 选择或构建词嵌入模型
- 选择现有模型:如Word2Vec、GloVe、FastText等,这些是预训练好的词嵌入模型,可以直接下载使用。
- 自定义训练:如果你的领域有特定的语言习惯或术语,可能需要基于自己的语料库训练词嵌入模型。
② 准备语料库
- 清洗和预处理文本数据,去除噪声,如标点符号、数字、停用词等。
- 可能需要分词,尤其是对于非英语语言,如中文需要进行分词处理。
③ 构建词汇表并编码
- 将语料库中所有出现过的单词或短语对应一个唯一的索引。
- 利用这个索引,将词汇编码成一个One-Hot词汇表。
④ 转换文本为向量表示(词嵌入)
- 将One-Hot编码通过与嵌入矩阵相乘得到想要词汇的词向量。
- 然后你还可以采用平均法、加权平均法或者使用RNN/LSTM等模型结合上下文信息来聚合单个词向量为整个句子或文档的向量表示。
(2)举例说明
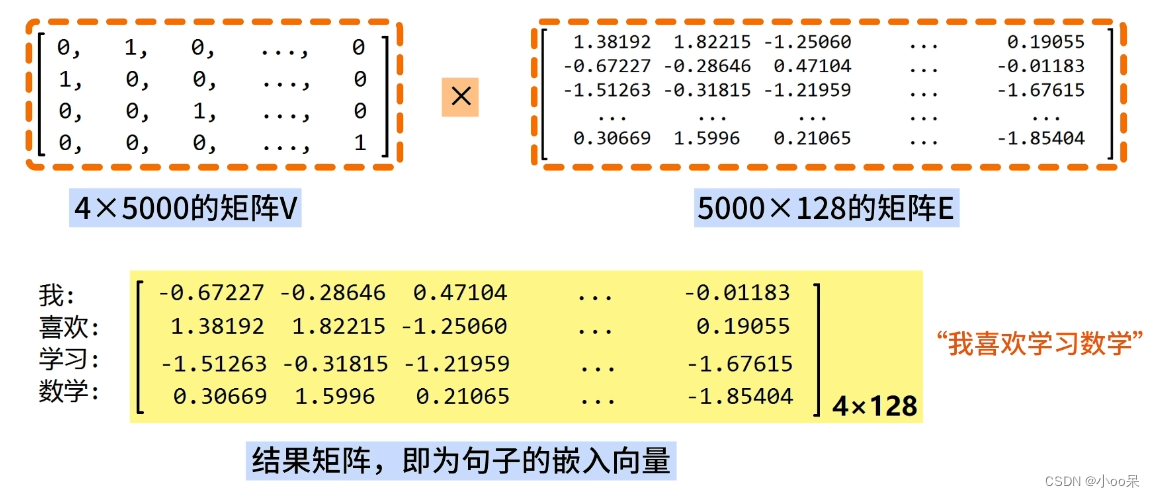
用一个简化的过程来说明,如何使用词嵌入技术处理句子“我喜欢学习数学”,并假设有一个词汇表大小为5000,每个词的嵌入维度为128的词嵌入矩阵。
① 步骤1:选择一个现有的模型
② 步骤2:准备语料库
使用只有一句话的语料库,简单说明一下。s=“我喜欢学习数学”
③ 步骤3:文本预处理
- 分词:将句子“我喜欢学数学”分词为
["我", "喜欢", "学习", "数学"]。 - 构建词汇表索引:假设这四个词都在我们的5000词词汇表内,且分别对应索引1、2、3、5000。
- 进行One-Hot编码:将词语使用One-Hot进行编码,产生一个词汇矩阵

③ 步骤3:文本转为向量(词嵌入)
假设我们已有一个(5000, 128)的词嵌入矩阵,其中每一行代表一个词的128维向量。

通过运算得出想要的词向量:

这篇关于【机器学习300问】127、怎么使用词嵌入?的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!



