本文主要是介绍【Linux】进程间通信上 (1.5万字详解),希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
目录
一.进程间通信介绍
1.1进程间通信的目的
1.2初步认识进程间通信
1.3进程间通信的种类
二.匿名管道
2.1何为管道
2.1实现原理
2.3进一步探寻匿名管道
2.4编码实现匿名管道通信
2.5管道读写特点
2.6基于管道的进程池设计
三.命名管道
3.1实现原理
3.2代码实现
四.共享内存
4.1共享内存的原理
4.2接口介绍
4.3命令行操作共享内存
4.4代码实现
hello,大家好呀。今天我们来学习关于进程间通信的内容,我们知道操作系统中会同时存在多个进程,这些进程有可能会共同完成一个任务,所以就需要通信。本文将讲解几种常见的进程间通信的方式。相信大家已经迫不及待的想要学习了,那我们就开始啦!
本节重点:进程间通信介绍,管道,消息队列,共享内存,信号量
一.进程间通信介绍
1.1进程间通信的目的
- 数据传输:数据一个进程需要将它的数据发送给另一个进程数据传输:
- 资源共享:多个进程之间共享同样的资源。
- 通知事件:一个进程需要向另一个或一组进程发送消息,通知它(它们)发生了某种事件(如进程终止时要通知父进程)。
- 进程控制:有些进程希望完全控制另一个进程的执行(如Debug进程),此时控制进程希望能够拦截另个进程的所有陷入和异常,并能够及时知道它的状态改变
其中,重要的目的是:数据传输,通知事件,进程控制。
1.2初步认识进程间通信
在没有正式接触通信之前,我们就应该知道:进程具有独立性,今天我们需要完成进程间相互通信,成本一定不低。
进程间通信的场景应该是这样的:一个进程将数据放入一块固定的区域中,另外一个进程从这块区域中读取数据。所以这块区域对通信双方来说,应该是一个公共资源。所以这块区域一定不能让两个进程提供(无论是哪个进程提供,都不会让另一个进程看到,因为进程具有独立性);这块区域只能由操作系统提供。
所以,通信的本质是什么?
- 操作系统必须直接或者间接的为通信双方提供可以交换数据的"内存空间"。
- 要通信的进程,必须看到一份公共资源。
- 不同的通信种类:本质就是上面的公共资源是操作系统的哪一个模块提供的。
总结来说,要完成通信,必须做好两件事情:
- 让通信进程双方看到同一份资源(我们其实学的就是这部分内容)。
- 通信。
1.3进程间通信的种类
根据操作系统给我们提供的公共资源属于操作系统中的哪一部分,前辈大佬们设计出了不同的通信方式。
管道通信:由文件系统提供
- 匿名管道pipe
- 命名管道
System V IPC:聚焦在本机通信
- System V 消息队列
- System V 共享内存
- System V 信号量
POSIX IPC:实现跨主机通信
- 消息队列
- 共享内存
- 信号量
- 互斥量
- 条件变量
- 读写锁
二.匿名管道
2.1何为管道
管道是Unix中最古老的进程间通信的形式。
我们把从一个进程连接到另一个进程的一个数据流称为一个“管道。例如我们在命令行中的“|”。
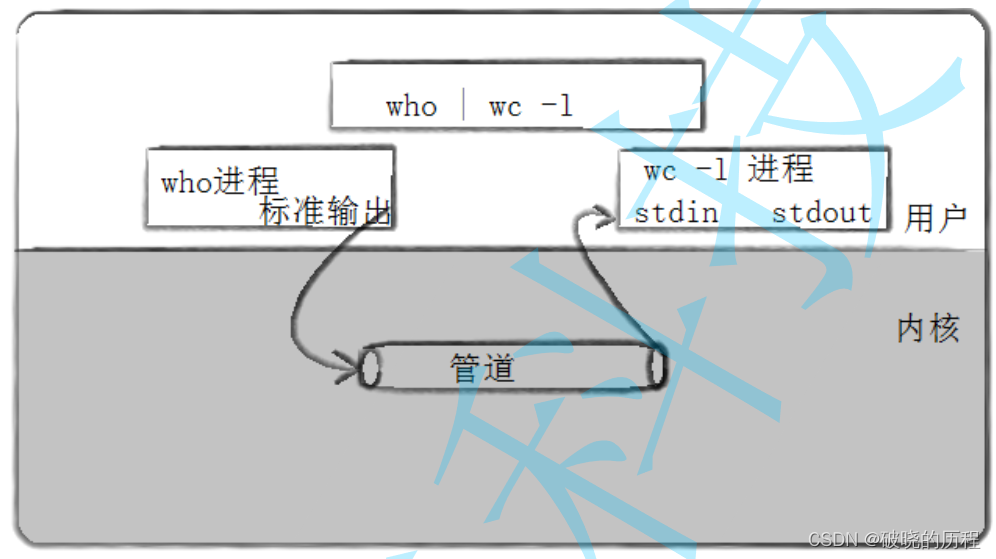
2.1实现原理
匿名管道是基于文件系统来实现的。
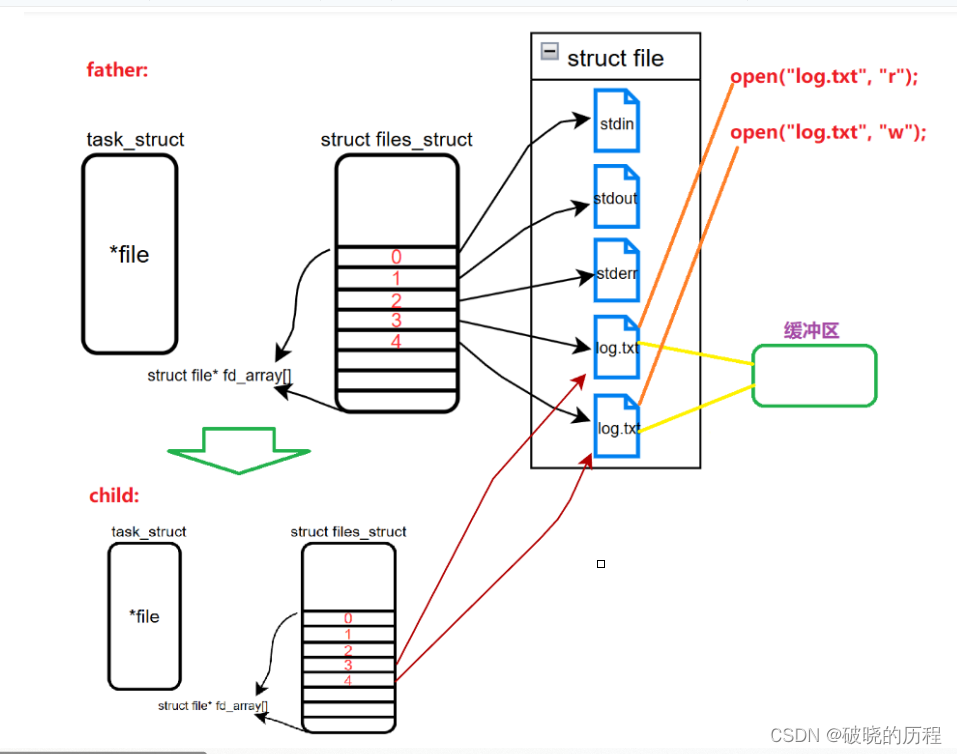
我们在学习文件系统时学到:一个进程会默认打开3个文件描述符,0号指向标准输入流,1号指向标准输出流,2号指向标准错误流。我们使用的文件描述符一般从3号开始。
如果对一个文件分别以“r”和“w”的形式打开,操作系统会分别为其分配不同的文件描述符来指向这个文件。一个文件仅有一个缓冲区。所以不管是对该文件进行读还是写操作,数据都会经过该缓冲区。

我们使用fork函数创建子进程时,操作系统会为子进程拷贝一份父进程的PCB,程序地址空间,列表等等。
但是父子进程会共用一个文件描述符数组吗? 不会,因为父子进程可能会打开不同的文件,为了确保独立性,并让父进程可以操作文件,操作系统会为子进程创建一个独立的文件描述符数组。
如果父子进程同时打开一个文件,这个文件就可以当做父子进程双方的共享资源,如果父子进程想要通信的话,就可以利用该文件进行通信(因为这个文件对父子进程来说都是可见的区域)。父子进程分别以读的方式和写的方式打开这个文件。一个进程向这个文件缓冲区中写入,另一个进程就可以从这个文件缓冲区中读取数据。这就是匿名管道的实现原理。采取匿名管道的方式通信利用的公共资源就是文件。
我们将操作系统提供的这个供进程间通信的文件就做管道文件。
问:刚刚,我们有提到:管道通信依据的是struct file结构体给文件提供的缓冲区来进行通信。为什么不让缓冲区内的数据刷新到磁盘上,然后再从磁盘中读取数据呢?这种方式可以吗?
答:这种方式是可以的,但是没有必要。因为这种通信太慢了。
管道通信依赖的仅仅是struct file结构体中的内核级的缓冲区。我们知道:一个文件被加载到内存,首先就是要为其创建struct file结构体,那操作系统可不可以为一个根本不存在的文件在内存中创建struct file结构体呢?可以。所以管道文件实际上是一个内存文件,要么这个文件根本不存在,要么即使存在,也不管新它在磁盘中的位置。
问:如何让父子进程看到同一个文件呢?
答:父进程打开文件,然后fork创建子进程,子进程继承文件描述符表,文件描述符中指向同一个文件的struct file结构体地址,所以父子进程看到同一个文件。这种看到同一个文件的方式不需要文件名的参与,所以这个这种管道又被称为匿名管道
2.3进一步探寻匿名管道
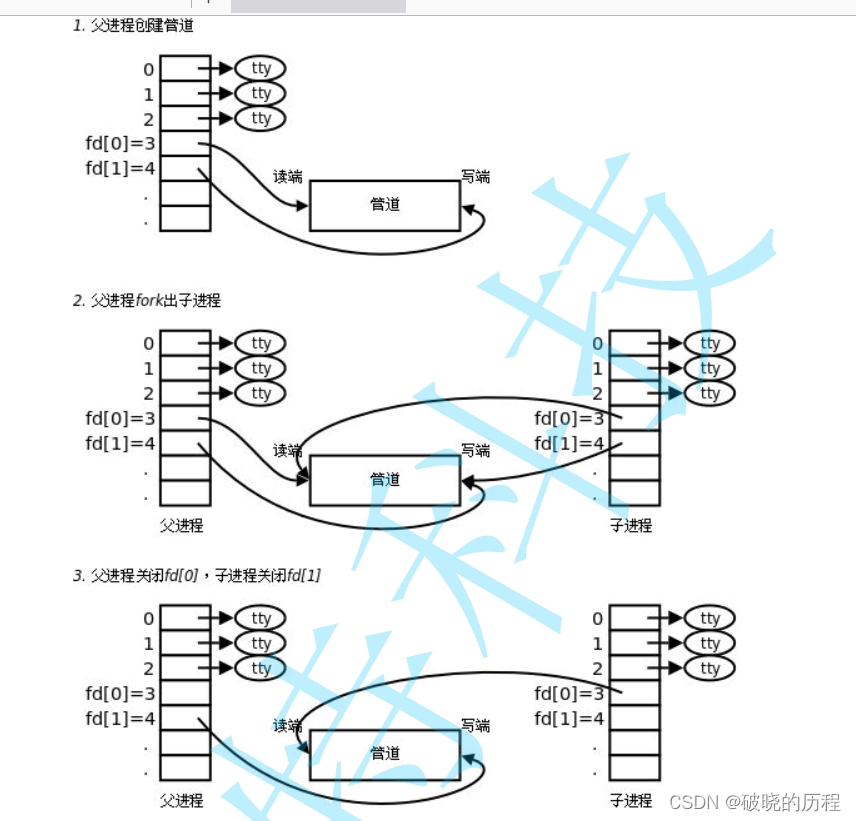
总结来说,创建管道的过程是:
- 分别让父进程以读和写的方式打开同一个文件。
- 用fork创建子进程。
- 一般而言,管道传输数据一般都是单向传输。所以根据传输方向的需要,关闭没有用的文件描述符。
问:为什么让父进程分别以读和写的方式打开同一个文件。
答:为了满足通信,通信双方会分别以读和写的方式打开同一个文件。父进程分别以读和写的方式打开同一个文件,子进程通过继承也会以读和写的方式打开同一个文件,这样一来,父子进程就可以选择数据传输的方向。
问:管道进行数据传输为什么是单项的?
答:这种通信方式之所以被命名为管道,是因为它符合现实生活中管道进行单向资源传输的特点。
设计出双向的管道在技术上是可行的,但也以为会更加麻烦,会添加更多的标定信息。如果我们想进行双向传输数据的话,我们可以创建两个管道来解决问题。
2.4编码实现匿名管道通信
目前,匿名管道用来父子进程间通信。
pipe函数
pipe()函数可用于创建一个管道,以实现进程间的通信。
pipe()函数的定义如下:
#include<unistd.h>/* @param fd,经参数fd返回的两个文件描述符* fd[0]为读而打开,fd[1]为写而打开* fd[1]的输出是fd[0]的输入* @return 若成功,返回0;若出错,返回-1并设置errno*/
int pipe(int fd[2]);
pipe函数定义中的fd参数是一个大小为2的数组类型指针。为输出型参数。
通过pipe函数创建的这两个文件描述符fd[0]和fd[1]分别构成管道的两端,往fd[1]写入的数据可以从fd[0]读出,并且fd[1]一端只能进行写操作,fd[0]一端只能进行读操作,不能反过来使用。要实现双向数据传输,可以使用两个管道。
默认情况下,这一对文件描述符都是阻塞的。此时,如果我们用read系统调用来读取一个空的管道,则read将被阻塞,直到管道内有数据可读;如果我们用write系统调用往一个满的管道中写数据,则write也将被阻塞,直到管道内有足够的空闲空间可用(read读取数据后管道中将清除读走的数据)。当然,用户可以将fd[0]和fd[1]设置为非阻塞的。
写一段小的测试代码:
#include <iostream>
#include <unistd.h>
#include <sys/types.h>
#include <sys/stat.h>
#include <sys/wait.h>
#include <fcntl.h>
#include <cassert>
#include<cstring>
int main()
{// 创建管道int fd[2];int n = pipe(fd);assert(n == 0);// fd[0]为读端// fd[1]为写端// 创建子进程pid_t fds = fork();assert(fds >= 0);const char *msg = "我是子进程,我正在给你发消息";int cnt = 0;if (fds == n){// 子进程// 关闭文件描述符// 子进程进行写入while (1){cnt++;close(fd[0]);char buffer[1024];snprintf(buffer, sizeof buffer, "子进程->父进程:%d[%s]", cnt, msg);write(fd[1], buffer, strlen(buffer));sleep(1);}exit(1);}close(fd[1]);char readbuffer[1024];while(1){read(fd[0],readbuffer,sizeof readbuffer-1);std::cout<<readbuffer<<std::endl;sleep(1);}int m = waitpid(fds, nullptr, 0);assert(m = fds);
}整个过程是严格按照我们刚刚的步骤进行的,运行一下:

整个过程非常流畅。
2.5管道读写特点
情况1:
管道写的快,读的慢。现在我们让子进程一直在写,父进程每隔5秒钟读一次,我们还是使用上面的测试代码:



综合打印结果,我们发现:读端从管道中读取数据时,当管道中数据足够多时, 读端会将缓冲区读满。所以读端就会一次性读取1023个字节的数据。
总结:读端读取数据,如果管道中数据足够多时,读端就会读满设定的缓冲区。如果管道中数据不够填满给读端准备的缓冲区时,读端就会一次性的把所有数据给读完。
情况2:
写端写入数据的速度非常慢,每10秒钟写入一条数据,读端一直读取。



在写端休眠的10秒中,读端一直阻塞在read函数那里,等待写端将数据写入。
结论:当管道中没有数据时,且写端没有关闭写文件描述符时,读端会一直阻塞等待,直到写端有数据写入。
情况3
写端正常写入,读端每10秒钟读取一次数据。当管道被写满时,写端在做什么?



管道瞬间被写满 ,然后写段会阻塞在那里,等待读端读取数据。
总结:当管道被写满时,写端会阻塞等待读端将数据读取。
情况4
读端正常读取,写端在写入过程中突然将写文件描述符关闭


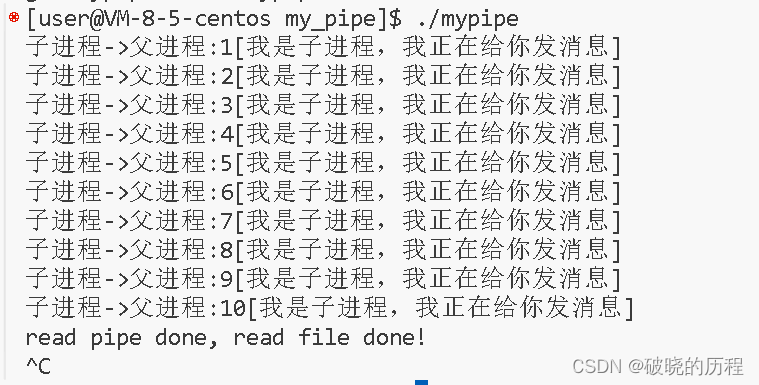
总结:当写端不再写入,并且关闭了pipe,那么读端将会把管道内的内容读完,最后就会读到返回值为0,表示读取结束,类似于读到了文件的结尾。
情况5
写端正常写入,但是读端正常读取过程中突然将读文件描述符关闭。

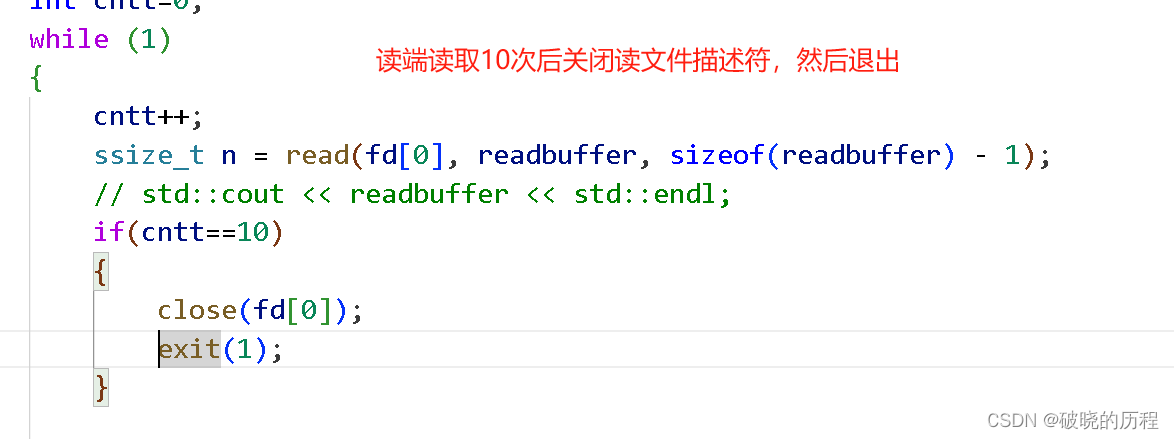

我们发现:当读端关闭读文件描述符的同时,写文件描述符也同时被关闭了。这是因为没有进程从管道读取数据了 ,所以往管道中写入的数据就是没有利用价值的,操作系统不会出现这种毫无价值的写入。
总结:当读端不再进行读取操作,并且关闭自己的文件描述符fd,此时的写就没有意义了。那么OS就会通过信号13(SIGPIPE)的方式直接终止写端的进程。
如何证明写进程是被13号信号杀死的呢?由于子进程退出后,父进程可以通过进程等待查到子进程的退出信息。所以我们:

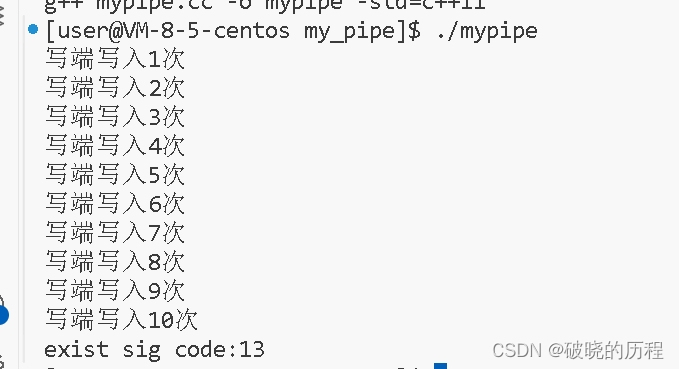
所以,的确是操作系统向子进程发送13号信号,来终止写进程的。
根据管道的几种特殊读写的情况,也间接创造出了管道的5个特征。
- 只能用于具有共同祖先的进程(具有亲缘关系的进程)之间进行通信;通常,一个管道由一个进程创建,然后该进程调用fork,此后父、子进程之间就可应用该管道。同样,兄弟进程,爷孙进程都可以利用管道进行通信。
- 管道提供流式服务。管道并不关系管道传输的是什么数据。
- 一般而言,进程退出,管道释放,所以管道的生命周期随进程
- 一般而言,内核会对管道操作进行同步与互斥
- 管道是半双工的,数据只能向一个方向流动;需要双方通信时,需要建立起两个管道
2.6基于管道的进程池设计
目标:父进程通过管道控制子进程。
实现原理:
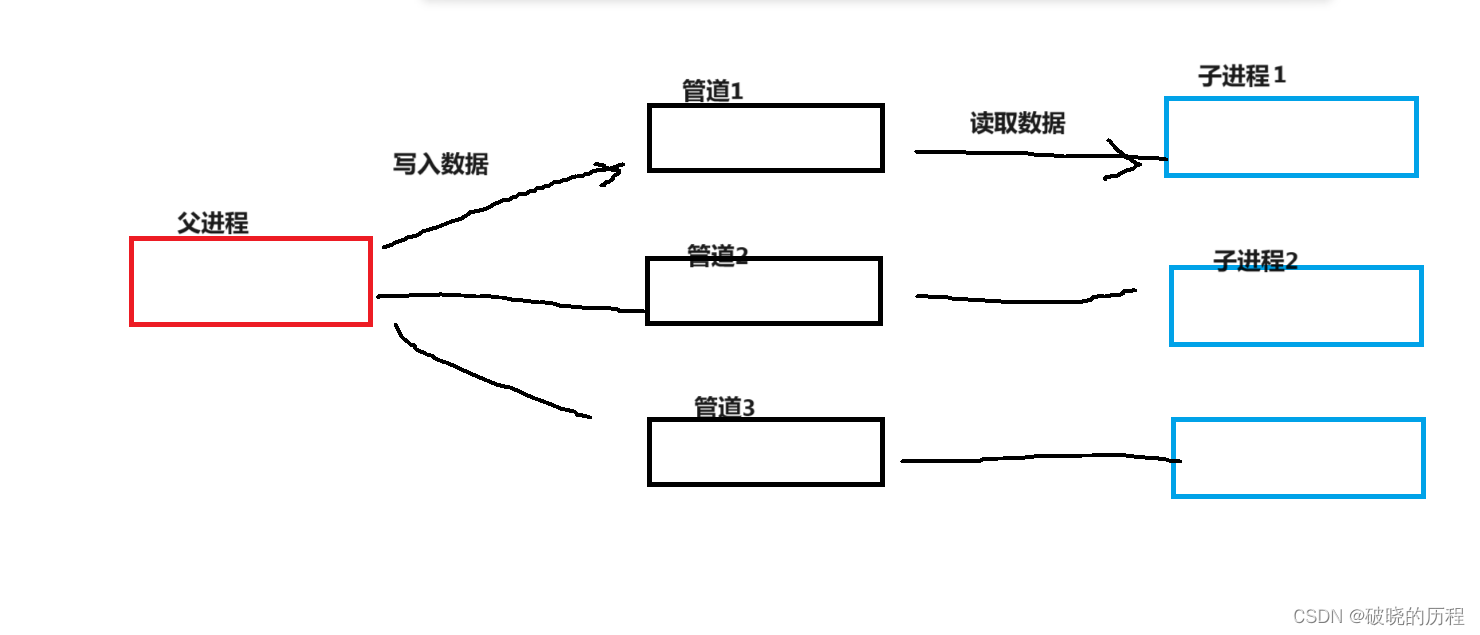
如图所示:创建若干子进程和管道,父子进程之间通过管道进行链接,父进程写入数据,子进程读取数据。然后子进程做特定的操作。
如下代码:
#include <iostream>
#include <string>
#include <vector>
#include <cstdlib>
#include <cassert>
#include <ctime>
#include <sys/types.h>
#include <sys/wait.h>
#include <unistd.h>#define MakeSeed() srand((unsigned long)time(nullptr) ^ getpid() ^ 0x171237 ^ rand() % 1234)#define PROCSS_NUM 10///子进程要完成的某种任务 -- 模拟一下/
// 函数指针 类型
typedef void (*func_t)();void downLoadTask()
{std::cout << getpid() << ": 下载任务\n"<< std::endl;sleep(1);
}void ioTask()
{std::cout << getpid() << ": IO任务\n"<< std::endl;sleep(1);
}void flushTask()
{std::cout << getpid() << ": 刷新任务\n"<< std::endl;sleep(1);
}void loadTaskFunc(std::vector<func_t> *out)
{assert(out);out->push_back(downLoadTask);out->push_back(ioTask);out->push_back(flushTask);
}/下面的代码是一个多进程程序//
class subEp // Endpoint
{
public:subEp(pid_t subId, int writeFd): subId_(subId), writeFd_(writeFd){char nameBuffer[1024];snprintf(nameBuffer, sizeof nameBuffer, "process-%d[pid(%d)-fd(%d)]", num++, subId_, writeFd_);name_ = nameBuffer;}public:static int num;std::string name_;pid_t subId_;int writeFd_;
};int subEp::num = 0;int recvTask(int readFd)
{int code = 0;ssize_t s = read(readFd, &code, sizeof code);if(s == 4) return code;else if(s <= 0) return -1;else return 0;
}void sendTask(const subEp &process, int taskNum)
{std::cout << "send task num: " << taskNum << " send to -> " << process.name_ << std::endl;int n = write(process.writeFd_, &taskNum, sizeof(taskNum));assert(n == sizeof(int));(void)n;
}void createSubProcess(std::vector<subEp> *subs, std::vector<func_t> &funcMap)
{std::vector<int> deleteFd;for (int i = 0; i < PROCSS_NUM; i++){int fds[2];int n = pipe(fds);assert(n == 0);(void)n;// 父进程打开的文件,是会被子进程共享的// 你试着多想几轮pid_t id = fork();if (id == 0){for(int i = 0; i < deleteFd.size(); i++) close(deleteFd[i]);// 子进程, 进行处理任务close(fds[1]);while (true){// 1. 获取命令码,如果没有发送,我们子进程应该阻塞int commandCode = recvTask(fds[0]);// 2. 完成任务if (commandCode >= 0 && commandCode < funcMap.size())funcMap[commandCode]();else if(commandCode == -1) break;}exit(0);}close(fds[0]);subEp sub(id, fds[1]);subs->push_back(sub);deleteFd.push_back(fds[1]);}
}void loadBlanceContrl(const std::vector<subEp> &subs, const std::vector<func_t> &funcMap, int count)
{int processnum = subs.size();int tasknum = funcMap.size();bool forever = (count == 0 ? true : false);while (true){// 1. 选择一个子进程 --> std::vector<subEp> -> index - 随机数int subIdx = rand() % processnum;// 2. 选择一个任务 --> std::vector<func_t> -> indexint taskIdx = rand() % tasknum;// 3. 任务发送给选择的进程sendTask(subs[subIdx], taskIdx);sleep(1);if(!forever){count--;if(count == 0) break; }}// write quit -> read 0for(int i = 0; i < processnum; i++) close(subs[i].writeFd_); // waitpid();
}void waitProcess(std::vector<subEp> processes)
{int processnum = processes.size();for(int i = 0; i < processnum; i++){waitpid(processes[i].subId_, nullptr, 0);std::cout << "wait sub process success ...: " << processes[i].subId_ << std::endl;}
}int main()
{MakeSeed();// 1. 建立子进程并建立和子进程通信的信道, 有bug的,但是不影响我们后面编写// 1.1 加载方发表std::vector<func_t> funcMap;loadTaskFunc(&funcMap);// 1.2 创建子进程,并且维护好父子通信信道std::vector<subEp> subs;createSubProcess(&subs, funcMap);// 2. 走到这里就是父进程, 控制子进程,负载均衡的向子进程发送命令码int taskCnt = 3; // 0: 永远进行loadBlanceContrl(subs, funcMap, taskCnt);// 3. 回收子进程信息waitProcess(subs);return 0;
}三.命名管道
匿名管道通信仅仅适用于有血缘关系的进程间的通信,有较大的局限性。有没有一种能用于没有血缘关系的进程间的通信呢?有,命名管道。
创建命名管道文件的操作:mkfifo +filename
示例演示:
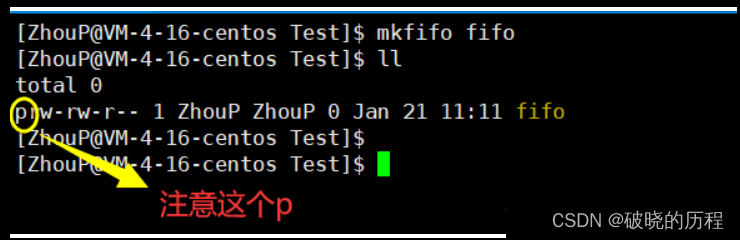
我们可以发现它的文件类型前面以P开头,当大家看到P开头的,会能想到什么?在之前我给大家在讲我们Linux基础命令的时候说过一个话题叫做文件类型:以 - 开头普通文件、以D开头为目录文件、以L开头为链接文件L开头的叫做软链接、这里以P开头叫做管道文件,这时候在磁盘上存在了一个管道文件。

【解释说明】
在我们的理解中把它写到文件当中,此时就相当于当我一敲回车,echo对应的这个东西就会变成进程;
然后,执行我们向显示器当中打印,经过重定向,它最终不向显示器文件打印,而向管道文件中打印,所以底层作为重定向是没问题的;
紧接着我们就尝试去写了,但当前呢它卡在这里的,什么都没做,我们再看一下当前这个管道文件里,当前显示的是零,好像没有写入啊;
这是因为管道文件有种特殊特性,虽然在磁盘当中创建了这个 fifo,但它仅仅是一种符号,那么对于这种符号呢,将来你向这个文件里写入的消息,并没有或者并不会刷新落实到磁盘上,而是只帮我们在这里直接 echo,然后写入管道文件当中,但是管道文件当前是内存级的,所以你的大小没有变。
接下来,我们来试一下重定向:

3.1实现原理
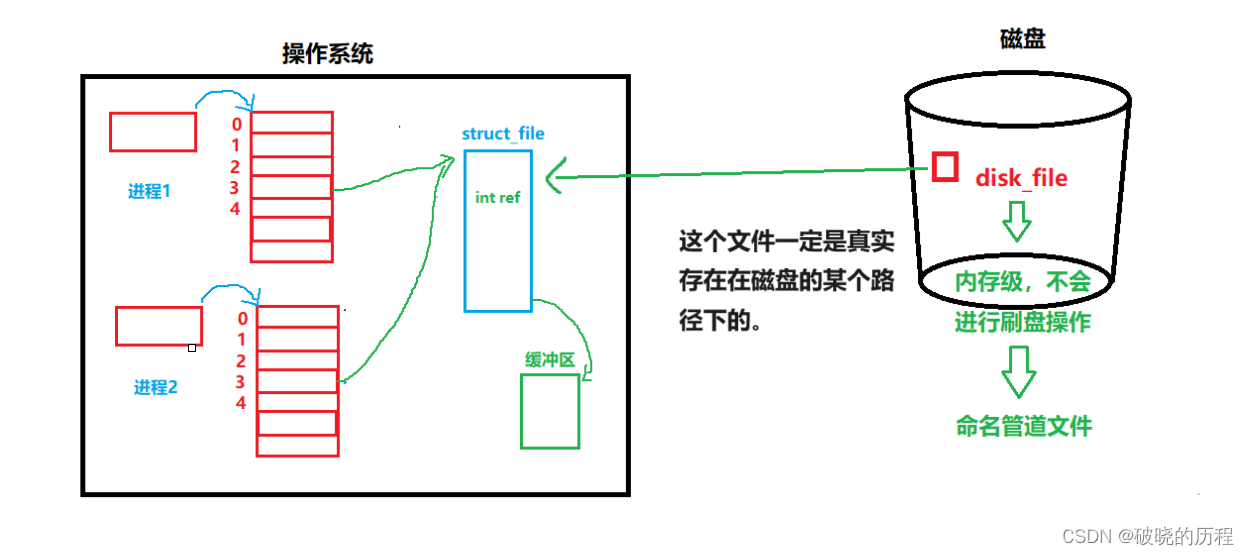
我们在磁盘中创建并命名一个文件,这个文件是真是存在在磁盘的某个路径下的。所以任意进程都可以打开这个文件。如果系统中有两个想要通信的进程,这个文件对双方进程来说就是公共资源。
一个进程向该文件中写入数据,另一进程从该软件中读取数据,进程双方就可以达到通信的目的。但是要通信的数据不会真的刷新到文件中,还是利用文件的缓冲区来进行通信的。所以你查询该文件,总会发现这个文件的大小一直是0。
问:要通信的两个进程如何找到同一个文件呢?
答:命名文件一定是真实存在于磁盘的某个目录下的,也就是说会有具体的路径,所以通信进程双方可以使用路径和文件名相结合的方式找到同一个文件。路径+文件名=唯一性
问:两个进程同时打开同一个文件,操作系统会为该文件创建两个struct file结构体吗?
答:不会,操作系统在计算机里是一个精打细算的角色,尤其是内存这种有限且非常重要的资源。
同一个文件的struct file结构体内部的数据应该是一样的,既然如此,操作系统为什么还要花费资源去维护另外一块空间呢?
如图所示:
问:为什么不进行文件数据的刷新工作?
答:没有必要,我们想要的仅仅是读取数据而已,数据在缓冲区内依旧可以完成数据的写入和读取。理论上可以从将数据刷新到磁盘,然后再从磁盘中将数据读取出来,但这样做,进程间通信的成本就会大大增加,因为磁盘属于外设,将数据从内存中写入外设是很慢的。
3.2代码实现
我们创建4个文件:
- client.cc :充当文件的写入端,为一个进程
- server.cc:充当文件的读取端,为一个进程
- comm.hpp完成创建管道文件的工作
- makefile:编译
client.cc
#include "comm.hpp"// 你可不可以把刚刚写的改成命名管道呢!
int main()
{std::cout << "client begin" << std::endl;int wfd = open(NAMED_PIPE, O_WRONLY);std::cout << "client end" << std::endl;if(wfd < 0) exit(1); //writechar buffer[1024];while(true){std::cout << "Please Say# ";fgets(buffer, sizeof(buffer), stdin); // abcd\nif(strlen(buffer) > 0) buffer[strlen(buffer)-1] = 0;ssize_t n = write(wfd, buffer, strlen(buffer));assert(n == strlen(buffer));(void)n;}close(wfd);return 0;
}server.cc
#include "comm.hpp"int main()
{bool r = createFifo(NAMED_PIPE);assert(r);(void)r;std::cout << "server begin" << std::endl;int rfd = open(NAMED_PIPE, O_RDONLY);std::cout << "server end" << std::endl;if(rfd < 0) exit(1);//readchar buffer[1024];while(true){ssize_t s = read(rfd, buffer, sizeof(buffer)-1);if(s > 0){buffer[s] = 0;std::cout << "client->server# " << buffer << std::endl;}else if(s == 0){std::cout << "client quit, me too!" << std::endl;break;}else{std::cout << "err string: " << strerror(errno) << std::endl;break;}}close(rfd);// sleep(10);removeFifo(NAMED_PIPE);return 0;
}comm.hpp
#pragma once
#include<iostream>
#include<string>
#include<cstring>
#include<cerrno>
#include<assert.h>
#include<unistd.h>
#include<sys/types.h>
#include<sys/stat.h>
#include<fcntl.h>#define NAMED_PIPE "/home/user/exercise/my_pipe/named_pipe/name_pipe"
bool createFiFo(const std::string &path)
{umask(0);int n=mkfifo(path.c_str(),0600);if(n==0){return true;}else{std::cout<<"errno:"<<errno<<"err string"<<strerror(errno)<<std::endl;}
}
void deleteFifo(const std::string &path)
{int n=unlink(path.c_str());assert(n==0);(void)n;
}makefile
.PHONY:all
all:client server
client:client.ccg++ -o $@ $^ -std=c++11
server:server.ccg++ -o $@ $^ -std=c++11
.PHONY:clean
clean:rm -f client server四.共享内存
写在最前面:共享内存虽然作为进程间通信的一种方式,但是在实际工作中,使用的次数缺很少,具体原因我会在讲解中说明。这次,我们打破以往的讲解顺序:先讲原理,然后写代码,最后是概念。
4.1共享内存的原理
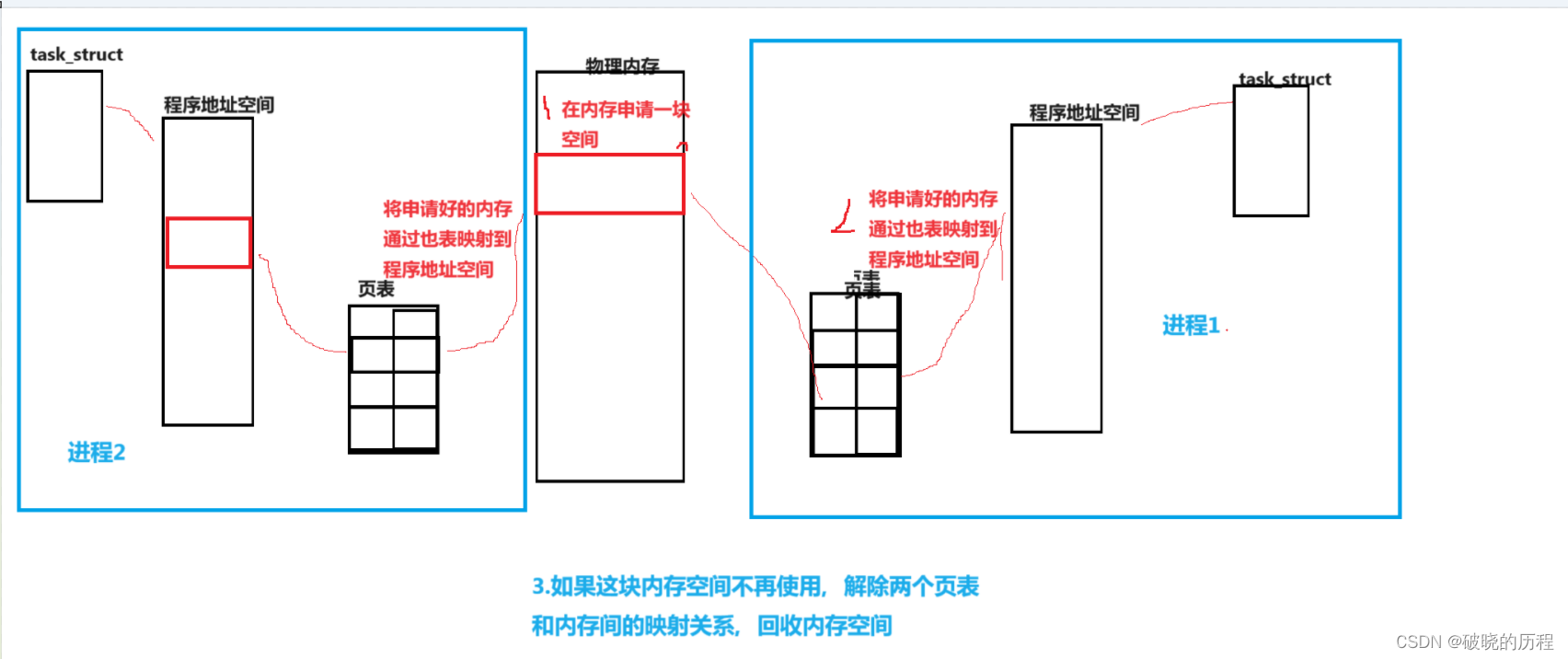
依上图,我简单讲解一下:通过学习管道,我们知道两个进程要实现通信,必须看到同一块资源。其中,我们在内存中申请的这块空间就可以充当进程双方通信的资源,这块内存就叫做共享内存。
我们需要知道:
- 操作系统中一定会存在很多共享的内存,这些共享内存空间要不要管理?如何被管理?我们后面说。
- 共享内存是一种通信方式,如果愿意,所有的内存都可以使用共享内存进行通信。
4.2接口介绍
操作系统为了方便我们使用共享内存,对外提供了一批接口。
shmget:在内存中申请一块指定大小的共享内存空间

参数介绍
①:key
我们提到操作系统中一定会存在多个共享内存,所以一定要有一个数据来标定这个共享内存的唯一性,key的作用便是标定这个唯一性,未来key值要被写入到共享内存相关属性集中的。
我们可以使用函数ftok来获取这个key的值。这个值是多少一点都不重要,能进行唯一性标识最重要。就像我们的身份证号,具体是多少对警察👮♀️来说无关紧要,重要的是它只属于你一个人。
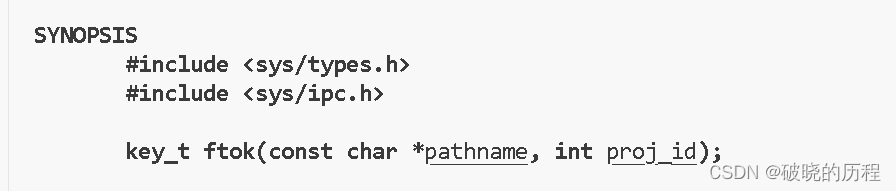
有两个参数
- pathname是一个路径,必须是真是存在且可以被访问的路径。
- proj_id为任意一个不为0的数字。
![]()
成功的话,返回计算的key_t值,失败返回-1。
这个函数的作用是将用户传入的路径和数字通过算法得到一个值。并且传入的参数不同,得到的结果也一定不同。 在使用共享内存时,进程双方要想访问同一块共享内存,必须传入相同的路径和数字,通过ftok得到同一个返回值,然后将返回值传入shmget中,才能访问到同一块共享内存。
②size:
在内存中要开辟的共享内存空间大小,单位为字节。
③proj_id:
该参数用于确定创建共享内存的选项。使用二进制标志位通过位图的形式传给该函数。
选项有两个:

- IPC_CREAT:共享内存不存在,就创建;如果存在,获取之。
- IPC_EXCL:这个选项不可以单独使用,必须结合IPC_CREAT使用。如果共享内存已经存在,出错返回。也就是说,如果创建成功,给用户返回的一定是一块新的共享内存。
返回值:
程序员使用该返回值来对该共享内存进行相关的操作。这个返回值在作用上和open函数的返回值一样。但这两个返回值之间是相互割裂的,所以这就造成在后期学习网络时,我们很少使用共享内存来进行通信。
🌿再谈key值
key值和shmget的返回值有什么区别呢?
问:大家在学C语言时,使用malloc申请一块堆空间时,要传入要申请的堆空间的大小,为什么使用free要释放空间时,只需传入堆空间的起始地址即可? 系统怎么知道我要释放多大的空间呢?
答:假如我们申请4KB的空间,系统会为我们分配超过4KB的空间,多出来的空间要维护这块空间,包括这块堆空间的起始地址,大小,权限等信息。这就是先描述,再组织。共享内存也是如此
所以,我们申请一块共享内存空间,我们不能简单的认为操作系统仅仅为我们在内存中申请了一块空间。共享内存=共享内存块+共享内存的属性信息。 所以,操作系统为每块共享内存都创建了一个对应的结构体,用来保存共享内存相关信息。所以,对共享内存的管理就变为对相应结构体的管理。
有一次,张三请李四去吃饭,张三提前去酒店定了包间,因为包间说话方便嘛!吃饭之前,张三通过微信把包间号发给了李四,比如:好再来酒店,6号包间。然后张三就早早的在包间里等着李四,李四找到了对应的包间,一看张三在等着呢。两人见面习惯性的含蓄了一番,然后就吃了起来。
我问:假如张三定的是6号包间,李四会问张三为什么要定6号包间吗?
不会,因为数字的作用仅仅是用来标识这个房间的唯一性,数值毫无意义。
我们提到每一个共享内存都有相应的数据块用来保存这个内存的属性信息。然后我们又说key值毫无意义,可以用来标识唯一性即可。
我们通过ftok函数得到key值,当我们通过shmget函数申请共享内存时,将key值传入,这是key值就被当作属性的一部分被设置到了共享内存相应的数据块中。等到再有进程拿着相同的key值申请内存时,系统就会遍历系统内所有的共享内存的数据块,然后将自己的key值和数据块中的key值进行对比。一句话:key值的作用在于标识这个共享内存,等待着其他进程通过这个key值来找到这块内存来进行通信。
问:如何理解shmget的返回值shmid和key值的关系呢?这两个值是什么关系呢?
答:我们在学习文件系统时,操作系统内核中是通过inode编号来区分文件的。而我们对文件进行操作是利用文件描述符fd。shmid和key值的关系就好似fd和inode的关系,shmid暴露给上层供程序员进行操作,而底层标识一个共享内存使用的却是key值。前辈大佬们使用两套规则来标识共享内存,其用意是实现底层和上层的解耦,而且方便上层操作,两套规则之间不会相互干扰。
接下来:我们认识其他几个接口
🍃shmctl :对共享内存进行销毁


该接口本身用于控制共享内存,可用于销毁。
shmid不再介绍,cmd传入IPC_RMID,buf传nullptr。
成功返回0,失败返回-1。
🍃shmat:共享内存和进程地址空间的链接
创建共享内存后还不能直接使用,需要找到内存地址后才能使用,即连接。

shmid即shmget返回值。
shmaddr用于确定将共享内存挂在进程虚拟地址哪个位置,一般填nullptr即可代表让内核自己确定位置。
shmflg用于确定挂接方式,一般填0。
连接成功返回共享内存在进程中的起始地址,失败返回-1。
🍃hmdts—分离
当使用完毕后,需要分离挂接的共享内存。

shmaddr与shmat的相同,为共享内存在进程中地址位置,一般填nullptr。
分离成功返回0,失败返回-1。
4.3命令行操作共享内存
查看共享内存
ipcs -m

共享内存的生命周期是随操作系统的,也就是除非计算机关机,如果我们不使用函数或者指令的方式对空间进行释放的话,共享内存的空间会一直存在。
删除共享内存空间: ipcs -m +shmid
4.4代码实现
现在我们已经把准备工作全部做完了,可以写完整的代码了。
我们创建4个文件即可,分别为makefile,comm.hpp,shm_client,ipcShmServer.cpp:。
comm.hpp
#include <iostream>
#include <cstring>
#include <cstdlib>
#include <cerrno>
#include <sys/ipc.h>
#include <sys/shm.h>
#include <sys/types.h>
#include <sys/stat.h>
#include <fcntl.h>
#include <string>
#include <unistd.h>
#include <cassert>#define SHM_SIZE 4096
#define PATH_NAME ".fifo"
#define PROJ_ID 0x14#define FIFO_FILE ".fifo"// 创建命名管道文件
void CreatFifo() {umask(0);if(mkfifo(FIFO_FILE, 0666) < 0){std::cerr << strerror(errno) << std::endl;exit(-1);}
}#define READER O_RDONLY
#define WRITER O_WRONLY// 以一定的方式打开管道文件
int Open(const std::string &filename, int flags)
{return open(filename.c_str(), flags);
}// 用于服务端, 等待读取管道文件数据, 即读取信号
int Wait(int fd) {uint32_t value = 0;ssize_t res = read(fd, &value, sizeof(value));return res;
}// 用于客户端, 向管道中写入数据, 即写入信号
void Signal(int fd) {uint32_t cmd = 1;write(fd, &cmd, sizeof(cmd));
}// 关闭管道文件, 删除管道文件
void Close(int fd, const std::string& filename) {close(fd);unlink(filename.c_str());
}
ipcShmServer.cpp:
// ipcShmServer 服务端代码, 即 接收端
// 需要创建、删除共享内存块
// 需要创建、删除命名管道
#include "common.hpp"
using std::cout;
using std::endl;
using std::cerr;int main() {// 0. 创建命名管道CreatFifo();int fd = Open(FIFO_FILE, READER); // 只读打开命名管道assert(fd >= 0);// 1. 创建共享内存块int key = ftok(PATH_NAME, PROJ_ID);if(key == -1) {cerr << "ftok error. " << strerror(errno) << endl;exit(1);}cout << "Create share memory begin. " << endl;int shmId = shmget(key, SHM_SIZE, IPC_CREAT | IPC_EXCL | 0666);if(shmId == -1) {cerr << "shmget error" << endl;exit(2);}cout << "Creat share memory success, key: " << key << " , shmId: " << shmId << endl;// 2. 连接共享内存块sleep(2);char* str = (char*)shmat(shmId, nullptr, 0);if(str == (void*)-1) {cerr << "shmat error" << endl;exit(3);}cout << "Attach share memory success. \n" << endl;// 3. 使用共享内存块while(true) {if (Wait(fd) <= 0)break; // 如果从管道读取数据失败, 或管道文件关闭, 则退出循环cout << str;sleep(1);}cout << "\nThe server has finished using shared memory. " << endl;sleep(1);// 3. 分离共享内存块int resDt = shmdt(str);if(resDt == -1) {cerr << "shmdt error" << endl;exit(4);}cout << "Detach share memory success. \n" << endl;// 4. 删除共享内存块int res = shmctl(shmId, IPC_RMID, nullptr);if(res == -1) {cerr << "shmget error" << endl;exit(5);}cout << "Delete share memory success. " << endl;// 5. 删除管道文件Close(fd, FIFO_FILE);cout << "Delete FIFO success. " << endl;return 0;
}
ipcShmClient.cpp:
// ipcShmClient 客户端代码, 即 发送端
// 不参与共享内存块的创建与删除
// 不参与命名管道的创建与删除
#include "common.hpp"
using std::cout;
using std::endl;
using std::cerr;int main() {// 0. 打开命名管道int fd = Open(FIFO_FILE, WRITER);// 1. 获取共享内存块int key = ftok(PATH_NAME, PROJ_ID);if(key == -1) {cerr << "ftok error. " << strerror(errno) << endl;exit(1);}cout << "Get share memory begin. " << endl;sleep(1);int shmId = shmget(key, SHM_SIZE, IPC_CREAT);if(shmId == -1) {cerr << "shmget error" << endl;exit(2);}cout << "Creat share memory success, key: " << key << " , shmId: " << shmId << endl;// 2. 连接共享内存块sleep(2);char* str = (char*)shmat(shmId, nullptr, 0);if(str == (void*)-1) {cerr << "shmat error" << endl;exit(3);}cout << "Attach share memory success. " << endl;// 3. 使用共享内存块while (true) {printf("Please Enter $ ");fflush(stdout);ssize_t res = read(0, str, SHM_SIZE); // 从标准输入读取数据写入到 共享内存(str) 中if(res > 0) {str[res] = '\0';}Signal(fd); // 向命名管道写入信号}cout << "\nThe client has finished using shared memory. " << endl;// 3. 分离共享内存块int res = shmdt(str);if(res == -1) {cerr << "shmdt error" << endl;exit(4);}cout << "Detach share memory success. " << endl;return 0;
}
makefile
.PHONY:all
all:ipcShmClient ipcShmServeripcShmClient:ipcShmClient.cppg++ $^ -o $@
ipcShmServer:ipcShmServer.cppg++ $^ -o $@.PHONY:clean
clean:rm -f ipcShmClient ipcShmServer .fifo
本篇到这里就结束了,如何您觉得内容还可以的话,给作者点一个免费的关注呀!

这篇关于【Linux】进程间通信上 (1.5万字详解)的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!








