本文主要是介绍机器学习能力自测题——常见简单机器学习问题,帮助理解应用,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
转自https://www.cnblogs.com/JZ-Ser/articles/7659920.html
一直苦于没有办法自测一下机器学习知识掌握程度,最近看到一篇Ankit Gupta写的博客:Solutions for Skilltest Machine Learning : Revealed。有40题机器学习自测题,马上可以看看你的机器学习知识能打几分?顺便还能查漏补缺相关术语,以及SVM, 隐马尔科夫, 特征选择, 神经网络, 线性回归等众多知识点.
以下是试题, 附答案:
Q1:在一个n维的空间中, 最好的检测outlier(离群点)的方法是:
A. 作正态分布概率图
B. 作盒形图
C. 马氏距离
D. 作散点图
答案:C
马氏距离是基于卡方分布的,度量多元outlier离群点的统计方法。更多请详见:这里和”各种距离“。
Q2:对数几率回归(logistics regression)和一般回归分析有什么区别?:
A. 对数几率回归是设计用来预测事件可能性的
B. 对数几率回归可以用来度量模型拟合程度
C. 对数几率回归可以用来估计回归系数
D. 以上所有
答案:D
A: 这个在我们第八期#8提到过,对数几率回归其实是设计用来解决分类问题的
B: 对数几率回归可以用来检验模型对数据的拟合度
C: 虽然对数几率回归是用来解决分类问题的,但是模型建立好后,就可以根据独立的特征,估计相关的回归系数。就我认为,这只是估计回归系数,不能直接用来做回归模型。
Q3:bootstrap数据是什么意思?(提示:考“bootstrap”和“boosting”区别)
A. 有放回地从总共M个特征中抽样m个特征
B. 无放回地从总共M个特征中抽样m个特征
C. 有放回地从总共N个样本中抽样n个样本
D. 无放回地从总共N个样本中抽样n个样本
答案:C
需要集成学习基础知识,详情请见:bootstrap, boosting, bagging 几种方法的联系
Q4:“过拟合”只在监督学习中出现,在非监督学习中,没有“过拟合”,这是:
A. 对的
B. 错的
答案:B
我们可以评估无监督学习方法通过无监督学习的指标,如:我们可以评估聚类模型通过调整兰德系数(adjusted rand score)
Q5:对于k折交叉验证, 以下对k的说法正确的是 :
A. k越大, 不一定越好, 选择大的k会加大评估时间
B. 选择更大的k, 就会有更小的bias (因为训练集更加接近总数据集)
C. 在选择k时, 要最小化数据集之间的方差
D. 以上所有
答案:D
k越大, bias越小, 训练时间越长. 在训练时, 也要考虑数据集间方差差别不大的原则. 比如, 对于二类分类问题, 使用2-折交叉验证, 如果测试集里的数据都是A类的, 而训练集中数据都是B类的, 显然, 测试效果会很差.
如果不明白bias和variance的概念, 务必参考下面链接:
- Gentle Introduction to the Bias-Variance Trade-Off in Machine Learning
- Understanding the Bias-Variance Tradeoff
Q6:回归模型中存在多重共线性, 你如何解决这个问题?
A. 去除这两个共线性变量
B. 我们可以先去除一个共线性变量
C. 计算VIF(方差膨胀因子), 采取相应措施
D. 为了避免损失信息, 我们可以使用一些正则化方法, 比如, 岭回归和lasso回归.
以下哪些是对的:
A. 1
B. 2
C. 2和3
D. 2, 3和4
答案: D
解决多重公线性, 可以使用相关矩阵去去除相关性高于75%的变量 (有主观成分). 也可以VIF, 如果VIF值<=4说明相关性不是很高, VIF值>=10说明相关性较高.
我们也可以用 岭回归和lasso回归的带有惩罚正则项的方法. 我们也可以在一些变量上加随机噪声, 使得变量之间变得不同, 但是这个方法要小心使用, 可能会影响预测效果.
Q7:模型的高bias是什么意思, 我们如何降低它 ?
A. 在特征空间中减少特征
B. 在特征空间中增加特征
C. 增加数据点
D. B和C
E. 以上所有
答案: B
bias太高说明模型太简单了, 数据维数不够, 无法准确预测数据, 所以, 升维吧 !
如果不明白bias和variance的概念, 务必参考下面链接:
- Gentle Introduction to the Bias-Variance Trade-Off in Machine Learning
- Understanding the Bias-Variance Tradeoff
Q8:训练决策树模型, 属性节点的分裂, 具有最大信息增益的图是下图的哪一个:
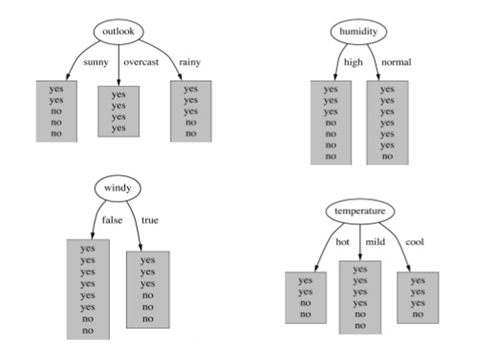
A. Outlook
B. Humidity
C. Windy
D. Temperature
答案: A
信息增益, 增加平均子集纯度, 详细研究, 请戳下面链接:
- A Complete Tutorial on Tree Based Modeling from Scratch (in R & Python)
- Lecture 4 Decision Trees (2): Entropy, Information Gain, Gain Ratio
Q9:对于信息增益, 决策树分裂节点, 下面说法正确的是:
A. 纯度高的节点需要更多的信息去区分
B. 信息增益可以用”1比特-熵”获得
C. 如果选择一个属性具有许多归类值, 那么这个信息增益是有偏差的
A. 1
B. 2
C.2和3
D. 所有以上
答案: C
详细研究, 请戳下面链接:
- A Complete Tutorial on Tree Based Modeling from Scratch (in R & Python)
- Lecture 4 Decision Trees (2): Entropy, Information Gain, Gain Ratio
Q10:如果SVM模型欠拟合, 以下方法哪些可以改进模型 :
A. 增大惩罚参数C的值
B. 减小惩罚参数C的值
C. 减小核系数(gamma参数)
答案: A
如果SVM模型欠拟合, 我们可以调高参数C的值, 使得模型复杂度上升.
LibSVM中,SVM的目标函数是:
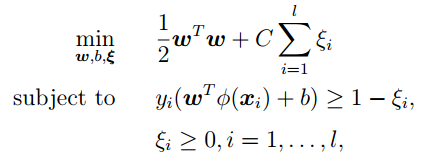
而, gamma参数是你选择径向基函数作为kernel后,该函数自带的一个参数.隐含地决定了数据映射到新的特征空间后的分布.
gamma参数与C参数无关. gamma参数越高, 模型越复杂.
Q11:下图是同一个SVM模型, 但是使用了不同的径向基核函数的gamma参数, 依次是g1, g2, g3 , 下面大小比较正确的是 :
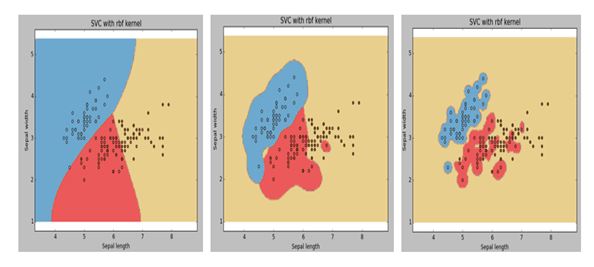
A. g1 > g2 > g3
B. g1 = g2 = g3
C. g1 < g2 < g3
D. g1 >= g2 >= g3
E. g1 <= g2 <= g3
答案: C
参考Q10题
Q12:假设我们要解决一个二类分类问题, 我们已经建立好了模型, 输出是0或1, 初始时设阈值为0.5, 超过0.5概率估计, 就判别为1, 否则就判别为0 ; 如果我们现在用另一个大于0.5的阈值, 那么现在关于模型说法, 正确的是 :
A. 模型分类的召回率会降低或不变
B. 模型分类的召回率会升高
C. 模型分类准确率会升高或不变
D. 模型分类准确率会降低
A. 1
B. 2
C.1和3
D. 2和4
E. 以上都不是
答案: C
这篇文章讲述了阈值对准确率和召回率影响 :
Confidence Splitting Criterions Can Improve Precision And Recall in Random Forest Classifiers
Q13:”点击率问题”是这样一个预测问题, 99%的人是不会点击的, 而1%的人是会点击进去的, 所以这是一个非常不平衡的数据集. 假设, 现在我们已经建了一个模型来分类, 而且有了99%的预测准确率, 我们可以下的结论是 :
A. 模型预测准确率已经很高了, 我们不需要做什么了
B. 模型预测准确率不高, 我们需要做点什么改进模型
C. 无法下结论
D. 以上都不对
答案: B
99%的预测准确率可能说明, 你预测的没有点进去的人很准确 (因为有99%的人是不会点进去的, 这很好预测). 不能说明你的模型对点进去的人预测准确, 所以, 对于这样的非平衡数据集, 我们要把注意力放在小部分的数据上, 即那些点击进去的人.
详细可以参考这篇文章: article
Q14:使用k=1的knn算法, 下图二类分类问题, “+” 和 “o” 分别代表两个类, 那么, 用仅拿出一个测试样本的交叉验证方法, 交叉验证的错误率是多少 :
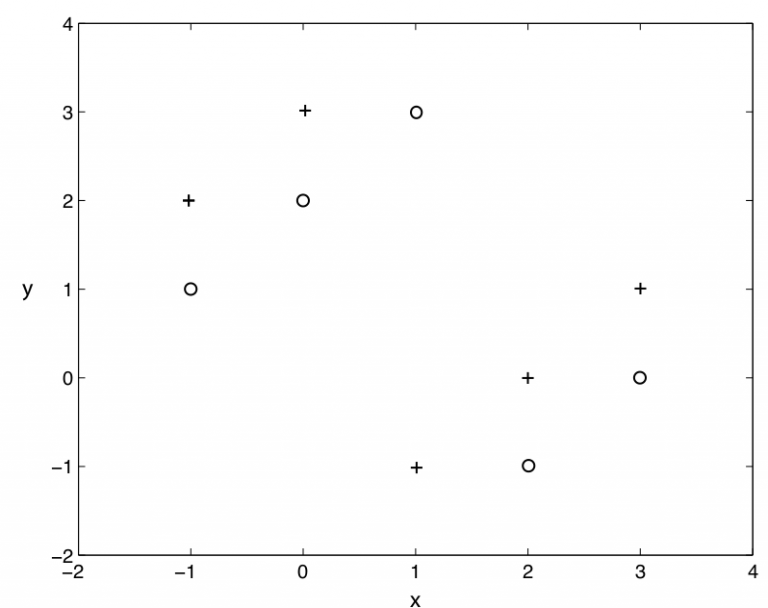
A. 0%
B. 100%
C. 0% 到 100%
D. 以上都不是
答案: B
knn算法就是, 在样本周围看k个样本, 其中大多数样本的分类是A类, 我们就把这个样本分成A类. 显然, k=1 的knn在上图不是一个好选择, 分类的错误率始终是100%
Q15:我们想在大数据集上训练决策树, 为了使用较少时间, 我们可以 :
A. 增加树的深度
B. 增加学习率 (learning rate)
C. 减少树的深度
D. 减少树的数量
答案: C
- 增加树的深度, 会导致所有节点不断分裂, 直到叶子节点是纯的为止. 所以, 增加深度, 会延长训练时间.
- 决策树没有学习率参数可以调. (不像集成学习和其它有步长的学习方法)
- 决策树只有一棵树, 不是随机森林.
Q16:对于神经网络的说法, 下面正确的是 :
1. 增加神经网络层数, 可能会增加测试数据集的分类错误率
2. 减少神经网络层数, 总是能减小测试数据集的分类错误率
3. 增加神经网络层数, 总是能减小训练数据集的分类错误率
A. 1
B. 1 和 3
C. 1 和 2
D. 2
答案: A
深度神经网络的成功, 已经证明, 增加神经网络层数, 可以增加模型范化能力, 即, 训练数据集和测试数据集都表现得更好. 但是, 在这篇文献中, 作者提到, 更多的层数, 也不一定能保证有更好的表现. 所以, 不能绝对地说层数多的好坏, 只能选A
Q17:假如我们使用非线性可分的SVM目标函数作为最优化对象, 我们怎么保证模型线性可分 :
A. 设C=1
B. 设C=0
C. 设C=无穷大
D. 以上都不对
答案: C
C无穷大保证了所有的线性不可分都是可以忍受的.
Q18:训练完SVM模型后, 不是支持向量的那些样本我们可以丢掉, 也可以继续分类:
A. 正确
B. 错误
答案: A
SVM模型中, 真正影响决策边界的是支持向量
Q19:以下哪些算法, 可以用神经网络去构造:
1. KNN
2. 线性回归
3. 对数几率回归
A. 1和 2
B. 2 和 3
C. 1, 2 和 3
D. 以上都不是
答案: B
1. KNN算法不需要训练参数, 而所有神经网络都需要训练参数, 因此神经网络帮不上忙
2. 最简单的神经网络, 感知器, 其实就是线性回归的训练
3. 我们可以用一层的神经网络构造对数几率回归
Q20:请选择下面可以应用隐马尔科夫(HMM)模型的选项:
A. 基因序列数据集
B. 电影浏览数据集
C. 股票市场数据集
D. 所有以上
答案: D
只要是和时间序列问题有关的 , 都可以试试HMM
Q21:我们建立一个5000个特征, 100万数据的机器学习模型. 我们怎么有效地应对这样的大数据训练 :
A. 我们随机抽取一些样本, 在这些少量样本之上训练
B. 我们可以试用在线机器学习算法
C. 我们应用PCA算法降维, 减少特征数
D. B 和 C
E. A 和 B
F. 以上所有
答案: F
Q22:我们想要减少数据集中的特征数, 即降维. 选择以下适合的方案 :
1. 使用前向特征选择方法
2. 使用后向特征排除方法
3. 我们先把所有特征都使用, 去训练一个模型, 得到测试集上的表现. 然后我们去掉一个特征, 再去训练, 用交叉验证看看测试集上的表现. 如果表现比原来还要好, 我们可以去除这个特征.
4. 查看相关性表, 去除相关性最高的一些特征
A. 1 和 2
B. 2, 3和4
C. 1, 2和4
D. All
答案: D
- 前向特征选择方法和后向特征排除方法是我们特征选择的常用方法
- 如果前向特征选择方法和后向特征排除方法在大数据上不适用, 可以用这里第三种方法.
- 用相关性的度量去删除多余特征, 也是一个好方法
所有D是正确的
Q23:对于 随机森林和GradientBoosting Trees, 下面说法正确的是:
- 在随机森林的单个树中, 树和树之间是有依赖的, 而GradientBoosting Trees中的单个树之间是没有依赖的.
- 这两个模型都使用随机特征子集, 来生成许多单个的树.
- 我们可以并行地生成GradientBoosting Trees单个树, 因为它们之间是没有依赖的, GradientBoosting Trees训练模型的表现总是比随机森林好
A. 2
B. 1 and 2
C. 1, 3 and 4
D. 2 and 4
答案: A
- 随机森林是基于bagging的, 而Gradient Boosting trees是基于boosting的, 所有说反了,在随机森林的单个树中, 树和树之间是没有依赖的, 而GradientBoosting Trees中的单个树之间是有依赖关系.
- 这两个模型都使用随机特征子集, 来生成许多单个的树.
所有A是正确的
Q24:对于PCA(主成分分析)转化过的特征 , 朴素贝叶斯的”不依赖假设”总是成立, 因为所有主要成分是正交的, 这个说法是 :
A. 正确的
B. 错误的
答案: B.
这个说法是错误的, 首先, “不依赖”和”不相关”是两回事, 其次, 转化过的特征, 也可能是相关的.
Q25:对于PCA说法正确的是 :
1. 我们必须在使用PCA前规范化数据
2. 我们应该选择使得模型有最大variance的主成分
3. 我们应该选择使得模型有最小variance的主成分
4. 我们可以使用PCA在低维度上做数据可视化
A. 1, 2 and 4
B. 2 and 4
C. 3 and 4
D. 1 and 3
E. 1, 3 and 4
答案: A
- PCA对数据尺度很敏感, 打个比方, 如果单位是从km变为cm, 这样的数据尺度对PCA最后的结果可能很有影响(从不怎么重要的成分变为很重要的成分).
- 我们总是应该选择使得模型有最大variance的主成分
- 有时在低维度上左图是需要PCA的降维帮助的
Q26:对于下图, 最好的主成分选择是多少 ? :
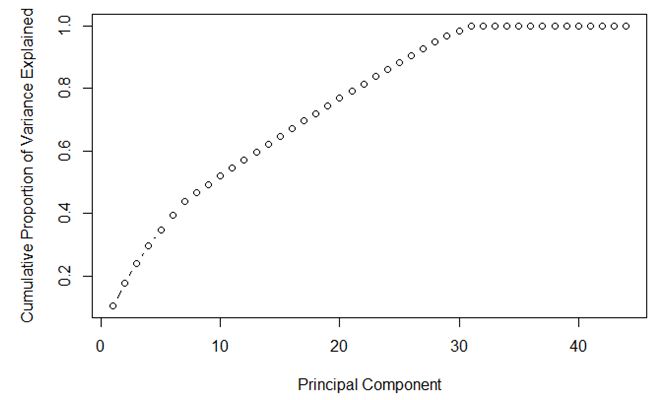
A. 7
B. 30
C. 35
D. Can’t Say
答案: B
- 主成分选择使variance越大越好, 在这个前提下, 主成分越少越好。
Q27:数据科学家可能会同时使用多个算法(模型)进行预测, 并且最后把这些算法的结果集成起来进行最后的预测(集成学习),以下对集成学习说法正确的是 :
A. 单个模型之间有高相关性
B. 单个模型之间有低相关性
C. 在集成学习中使用“平均权重”而不是“投票”会比较好
D. 单个模型都是用的一个算法
答案: B
- 详细请参考下面文章:
-
Basics of Ensemble Learning Explained in Simple English
- Kaggle Ensemble Guide
-
5 Easy questions on Ensemble Modeling everyone should know
-
Q28:在有监督学习中, 我们如何使用聚类方法? :
A. 我们可以先创建聚类类别, 然后在每个类别上用监督学习分别进行学习
B. 我们可以使用聚类“类别id”作为一个新的特征项, 然后再用监督学习分别进行学习
C. 在进行监督学习之前, 我们不能新建聚类类别
D. 我们不可以使用聚类“类别id”作为一个新的特征项, 然后再用监督学习分别进行学习
A. 2 和 4
B. 1 和 2
C. 3 和 4
D. 1 和 3
答案: B
我们可以为每个聚类构建不同的模型, 提高预测准确率。
“类别id”作为一个特征项去训练, 可以有效地总结了数据特征。
所以B是正确的
Q29:以下说法正确的是 :
A. 一个机器学习模型,如果有较高准确率,总是说明这个分类器是好的
B. 如果增加模型复杂度, 那么模型的测试错误率总是会降低
C. 如果增加模型复杂度, 那么模型的训练错误率总是会降低
D. 我们不可以使用聚类“类别id”作为一个新的特征项, 然后再用监督学习分别进行学习
A. 1
B. 2
C. 3
D. 1 and 3
答案: C
考的是过拟合和欠拟合的问题。
Q30:对应GradientBoosting tree算法, 以下说法正确的是 :
A. 当增加最小样本分裂个数,我们可以抵制过拟合
B. 当增加最小样本分裂个数,会导致过拟合
C. 当我们减少训练单个学习器的样本个数,我们可以降低variance
D. 当我们减少训练单个学习器的样本个数,我们可以降低bias
A. 2 和 4
B. 2 和 3
C. 1 和 3
D. 1 和 4
答案: C
- 最小样本分裂个数是用来控制“过拟合”参数。太高的值会导致“欠拟合”,这个参数应该用交叉验证来调节。
- 第二点是靠bias和variance概念的。
Q31:以下哪个图是KNN算法的训练边界 :
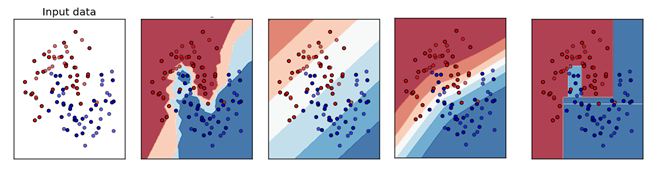
A) B
B) A
C) D
D) C
E) 都不是
答案: B
KNN算法肯定不是线性的边界, 所以直的边界就不用考虑了。另外这个算法是看周围最近的k个样本的分类用以确定分类,所以边界一定是坑坑洼洼的。
Q32:如果一个训练好的模型在测试集上有100%的准确率, 这是不是意味着在一个新的数据集上,也会有同样好的表现? :
A. 是的,这说明这个模型的范化能力已经足以支持新的数据集合了
B. 不对,依然后其他因素模型没有考虑到,比如噪音数据
答案: B
没有一个模型是可以总是适应新数据的。我们不可能可到100%准确率。
Q33:下面的交叉验证方法 :
i. 有放回的Bootstrap方法
ii. 留一个测试样本的交叉验证
iii. 5折交叉验证
iv. 重复两次的5折教程验证
当样本是1000时,下面执行时间的顺序,正确的是:
A. i > ii > iii > iv
B. ii > iv > iii > i
C. iv > i > ii > iii
D. ii > iii > iv > i
答案: B
- Boostrap方法是传统地随机抽样,验证一次的验证方法,只需要训练1次模型,所以时间最少。
- 留一个测试样本的交叉验证,需要n次训练过程(n是样本个数),这里,要训练1000个模型。
- 5折交叉验证需要训练5个模型。
- 重复2次的5折交叉验证,需要训练10个模型。
所有B是正确的
Q34. Removed
Q35:变量选择是用来选择最好的判别器子集, 如果要考虑模型效率,我们应该做哪些变量选择的考虑? :
1. 多个变量其实有相同的用处
2. 变量对于模型的解释有多大作用
3. 特征携带的信息
4. 交叉验证
A. 1 和 4
B. 1, 2 和 3
C. 1,3 和 4
D. 以上所有
答案: C
注意, 这题的题眼是考虑模型效率,所以不要考虑选项2.
Q36:对于线性回归模型,包括附加变量在内,以下的可能正确的是 :
1. R-Squared 和 Adjusted R-squared都是递增的
2. R-Squared 是常量的,Adjusted R-squared是递增的
3. R-Squared 是递减的, Adjusted R-squared 也是递减的
4. R-Squared 是递减的, Adjusted R-squared是递增的
A. 1 和 2
B. 1 和 3
C. 2 和 4
D. 以上都不是
答案: D
R-squared不能决定系数估计和预测偏差,这就是为什么我们要估计残差图。但是,R-squared有R-squared 和 predicted R-squared 所没有的问题。
每次你为模型加入预测器,R-squared递增或不变.
详细请看这个链接:discussion.
Q37:对于下面三个模型的训练情况, 下面说法正确的是 :
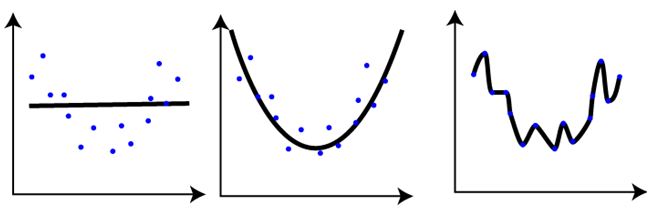
1. 第一张图的训练错误与其余两张图相比,是最大的
2. 最后一张图的训练效果最好,因为训练错误最小
3. 第二张图比第一和第三张图鲁棒性更强,是三个里面表现最好的模型
4. 第三张图相对前两张图过拟合了
5. 三个图表现一样,因为我们还没有测试数据集
A. 1 和 3
B. 1 和 3
C. 1, 3 和 4
D. 5
答案: C
Q38:对于线性回归,我们应该有以下哪些假设? :
1. 找到利群点很重要, 因为线性回归对利群点很敏感
2. 线性回归要求所有变量必须符合正态分布
3. 线性回归假设数据没有多重线性相关性
A. 1 和 2
B. 2 和 3
C. 1,2 和 3
D. 以上都不是
答案: D
- 利群点要着重考虑, 第一点是对的
- 不是必须的, 当然, 如果是正态分布, 训练效果会更好
- 有少量的多重线性相关性是可以的, 但是我们要尽量避免
Q39:当我们构造线性模型时, 我们注意变量间的相关性. 在相关矩阵中搜索相关系数时, 如果我们发现3对变量的相关系数是(Var1 和Var2, Var2和Var3, Var3和Var1)是-0.98, 0.45, 1.23 . 我们可以得出什么结论:
1. Var1和Var2是非常相关的
2. 因为Var和Var2是非常相关的, 我们可以去除其中一个
3. Var3和Var1的1.23相关系数是不可能的
A. 1 and 3
B. 1 and 2
C. 1,2 and 3
D. 1
答案: C
- Var1和Var2相关系数是负的, 所以这是多重线性相关, 我们可以考虑去除其中一个.
- 一般地, 如果相关系数大于0.7或者小于-0.7, 是高相关的
- 相关性系数范围应该是 [-1,1]
Q40:如果在一个高度非线性并且复杂的一些变量中, 一个树模型可能比一般的回归模型效果更好. 只是:
A. 对的
B. 错的
答案: A
这篇关于机器学习能力自测题——常见简单机器学习问题,帮助理解应用的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!




