本文主要是介绍Spring线程池异步传递MDC信息和TraceId,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
目录
1. 什么是MDC
2. 引入MDC打印步骤
2.1 pom依赖
2.2 log4j2打印日志配置文件
3 步骤演示
3.1 单线程业务使用示例
postman查询示例
查询代码
查询日志
3.2 自定义MDC异步线程池
自定义异步MDC线程池代码
初始化线程池
通过注解和注入方式使用
入口代码
结果示例
3.3 包装单个线程
包装MDCRunable
包装MDCCallable
声明普通线程池
使用包装线程
4 总结
1. 什么是MDC
MDC,英文全称是 Mapped Diagnostic Context,含义是映射调试上下文。它是 log4j 和 logback 提供的一种方便在多线程条件下记录日志的类。MDC 可以看成是一个与当前线程绑定的哈希表,可以往其中添加键值对。
2. 引入MDC打印步骤
基于springboot项目中集成MDC。
1 引入log4j2的jar包
2 配置log4j3的配置
3 在打印日志前往MDC中塞入值
2.1 pom依赖
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 https://maven.apache.org/xsd/maven-4.0.0.xsd"><modelVersion>4.0.0</modelVersion><parent><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-parent</artifactId><version>2.1.18.RELEASE</version><relativePath/> <!-- lookup parent from repository --></parent><groupId>com.example.demo</groupId><artifactId>elasticsearch</artifactId><version>0.0.1-SNAPSHOT</version><name>elasticsearch</name><description>Demo project for Spring Boot</description><properties><java.version>1.8</java.version><elasticsearch.client.version>6.8.5</elasticsearch.client.version><lombok.version>1.18.12</lombok.version></properties><dependencies><!-- 排除包冲突 --><dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter</artifactId><exclusions><exclusion><artifactId>spring-boot-starter-logging</artifactId><groupId>org.springframework.boot</groupId></exclusion></exclusions></dependency><dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-test</artifactId><scope>test</scope></dependency><dependency><groupId>org.elasticsearch.client</groupId><artifactId>elasticsearch-rest-high-level-client</artifactId><version>${elasticsearch.client.version}</version></dependency><dependency><groupId>org.elasticsearch</groupId><artifactId>elasticsearch</artifactId><version>${elasticsearch.client.version}</version></dependency><dependency><groupId>org.projectlombok</groupId><artifactId>lombok</artifactId><version>${lombok.version}</version></dependency><dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-web</artifactId></dependency><!-- 引入log4j2依赖 --><dependency> <groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-log4j2</artifactId></dependency></dependencies><build><plugins><plugin><groupId>org.springframework.boot</groupId><artifactId>spring-boot-maven-plugin</artifactId></plugin></plugins></build></project>
2.2 log4j2打印日志配置文件
resource目录下创建log4j.xml配置如下
application.properties中添加:
## 这个是做es留下来的,不需要写
host.address.array==192.168.40.129:9200,192.168.40.129:9201,192.168.40.129:9202logging.config=classpath:log4j.xml
logging.level.root=info
log4j.xml中添加:
<?xml version="1.0" encoding="UTF-8"?>
<Configuration status="INFO"><Appenders><!--添加一个控制台追加器--><Console name="Console" target="SYSTEM_OUT" follow="true"><PatternLayout><pattern>[%-5p] %d %c [%X{REQUEST_UUID}] - %m%n</pattern></PatternLayout></Console><!--添加一个文本追加器,文件位于根目录下,名为log.log--><File name="File" fileName="logs/log.log"><PatternLayout><pattern>[%-5p] %d %c %X{REQUEST_UUID} - %m%n</pattern></PatternLayout></File></Appenders><Loggers><Root level="INFO"><AppenderRef ref="Console" /></Root><!--把org.springframework包下的所有日志输出到log文件,additivity="false"表示不输出到控制台--><Logger name="org.springframework" level="DEBUG" additivity="true"><AppenderRef ref="File" /></Logger></Loggers>
</Configuration>
3 步骤演示
3.1 单线程业务使用示例
设想场景,查询根据书名查询书籍的信息。
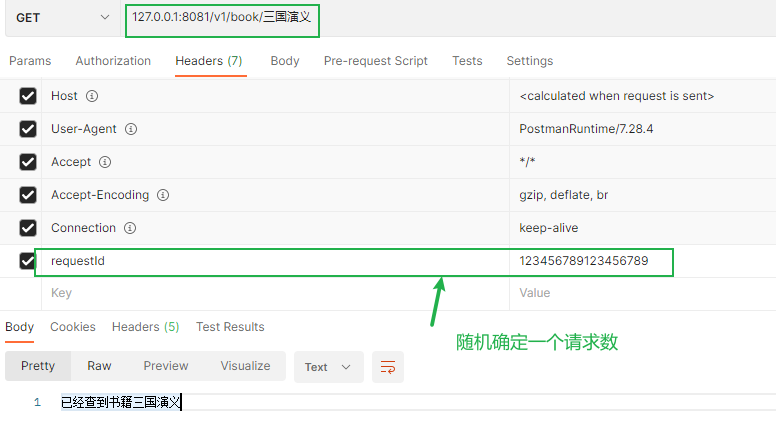
postman查询示例
一般在header中设置属性requestId为32位随机数,以保证这次请求唯一,在后端比较好查询这次数据流。
查询代码
这里简单的从request中header获取前端传入的requestId。
当然也有更优雅的方式,比方自定义filter,controller执行前的filter中提前初始化MDC信息。
@GetMapping("/{bookName}")public String queryBookInfos(HttpServletRequest request,@PathVariable String bookName){String requestId = request.getHeader("requestId");if(StringUtils.isEmpty(requestId)){requestId=new UUIDGenerator().toString();}// 这里的key值需要与log4j.xml中的MDC传递的信息关键字一致MDC.put("REQUEST_UUID", requestId);// 模拟查询数据库打印log.info("开始查询名字叫{}的书籍",bookName);MDC.clear();return "已经查到书籍"+bookName;}查询日志
查询的日志中有MDC的requestid信息,方便定位问题。
[DEBUG] 2022-01-24 15:46:03,560 org.springframework.web.servlet.DispatcherServlet [] - GET "/v1/book/%E4%B8%89%E5%9B%BD%E6%BC%94%E4%B9%89", parameters={}
[DEBUG] 2022-01-24 15:46:03,564 org.springframework.web.servlet.mvc.method.annotation.RequestMappingHandlerMapping [] - Mapped to public java.lang.String com.example.demo.elasticsearch.controller.BookController.queryBookInfos(javax.servlet.http.HttpServletRequest,java.lang.String)
[INFO ] 2022-01-24 15:46:03,575 com.example.demo.elasticsearch.controller.BookController [123456789123456789] - 开始查询名字叫三国演义的书籍
[DEBUG] 2022-01-24 15:46:03,584 org.springframework.web.servlet.mvc.method.annotation.RequestResponseBodyMethodProcessor [] - Using 'text/plain', given [*/*] and supported [text/plain, */*, text/plain, */*, application/json, application/*+json, application/json, application/*+json, application/x-jackson-smile, application/cbor]
[DEBUG] 2022-01-24 15:46:03,584 org.springframework.web.servlet.mvc.method.annotation.RequestResponseBodyMethodProcessor [] - Writing ["已经查到书籍三国演义"]
[DEBUG] 2022-01-24 15:46:03,588 org.springframework.web.servlet.DispatcherServlet [] - Completed 200 OK
3.2 自定义MDC异步线程池
自定义MDC线程池是常用的一种手段。
自定义异步MDC线程池代码
import java.util.Map;
import java.util.concurrent.Callable;
import java.util.concurrent.Future;import lombok.NonNull;
import org.slf4j.MDC;
import org.springframework.scheduling.concurrent.ThreadPoolTaskExecutor;/*** 异步线程池,带有MDC的那种** @author zhangzhongqiu* @version 1.0* @since 2022/1/21*/
public class MdcThreadPoolTaskExecutor extends ThreadPoolTaskExecutor {/*** @param corePoolSize* @param maxPoolSize* @param keepAliveTime* @param queueCapacity* @param poolNamePrefix*/public MdcThreadPoolTaskExecutor(int corePoolSize, int maxPoolSize,int keepAliveTime, int queueCapacity, String poolNamePrefix) {setCorePoolSize(corePoolSize);setMaxPoolSize(maxPoolSize);setKeepAliveSeconds(keepAliveTime);setQueueCapacity(queueCapacity);setThreadNamePrefix(poolNamePrefix);}/*** @return*/private Map<String, String> getContextForTask() {return MDC.getCopyOfContextMap();}/*** All executions will have MDC injected. {@code ThreadPoolExecutor}'s submission methods ({@code submit()} etc.)* all delegate to this.*/@Overridepublic void execute(@NonNull Runnable command) {super.execute(wrap(command, getContextForTask()));}@NonNull@Overridepublic Future<?> submit(@NonNull Runnable task) {return super.submit(wrap(task, getContextForTask()));}@NonNull@Overridepublic <T> Future<T> submit(@NonNull Callable<T> task) {return super.submit(wrap(task, getContextForTask()));}/*** @param task* @param context* @param <T>* @return*/private static <T> Callable<T> wrap(final Callable<T> task, final Map<String, String> context) {return () -> {if (null! = context) {MDC.setContextMap(context);}try {return task.call();} finally {if (!context.isEmpty()) {MDC.clear();}}};}/**** @param runnable* @param context* @return*/private static Runnable wrap(final Runnable runnable, final Map<String, String> context) {return () -> {if (null!=context) {MDC.setContextMap(context);}try {runnable.run();} finally {if (!context.isEmpty()) {MDC.clear();}}};}}初始化线程池
@Configuration
public class MyConfig {@Bean(name = "mdcThreadPoolTaskExecutor" )public AsyncTaskExecutor mdcThreadPoolTaskExecutor() {// 这里也可以用metrics来监控线程池,上报数据到prometheusreturn new MdcThreadPoolTaskExecutor(null,3,5, 2, TimeUnit.SECONDS,1000,"mdcThreadPoolTaskExecutor");}
}通过注解和注入方式使用
注解方式,主要使用@Async注解
@Slf4j
@Component
public class IndexService {@Async("mdcThreadPoolTaskExecutor")public void doSomething(Long networkId){log.info("errptsfsdfds {}",networkId);}
}
注入方式,有三种注入,这里列举一种注入。
@Bean(name = "newMdcThreadPoolTaskExecutor" )public MdcThreadPoolTaskExecutor newMdcThreadPoolTaskExecutor() {// 这里也可以用metrics来监控线程池,上报数据到prometheusreturn new MdcThreadPoolTaskExecutor(null,3,5, 2, TimeUnit.SECONDS,1000,"mdcThreadPoolTaskExecutor");}@Slf4j
@Component
public class IndexService {@Autowiredprivate MdcThreadPoolTaskExecutor mdcThreadPoolTaskExecutor;public void doSomething(Long networkId) {// 如果使用这种方式,不需要自定义线程池,使用原始线程池,自定义单个线程,并在单个线程种包装MDC信息即可mdcThreadPoolTaskExecutor.submit(() -> {log.info("对 {} 做了操作", networkId);});}}入口代码
@Slf4j
@RestController
@RequestMapping("/v1/index")
public class IndexController {@Autowiredprivate IndexService indexService;@GetMappingpublic String get(HttpServletRequest request){String requestId = request.getHeader("requestId");if(StringUtils.isEmpty(requestId)){requestId=new UUIDGenerator().toString();}// 模拟要查询的列表,每个列表值开启了一个新的线程Long[] networkIds={123L,45L,67L,78L,899L,1000L};MDC.put("REQUEST_UUID",requestId);String s = MDC.get("REQUEST_UUID");for(Long networkId:networkIds){// 这里传入的reuqest+列表值,组成新的requestId,注意新的requestId长度MDC.put("REQUEST_UUID",s+"-"+networkId);indexService.doSomething(networkId);}return "HHHHH";}
}
结果示例

PS:这里不探讨分布式调用链。
3.3 包装单个线程
包装单个线程也是一种实现方式,利用构造函数可以携带额外的参数,比较灵活。
包装MDCRunable
public class MDCRunable implements Runnable {private Map<String, String> copyOfContextMap;private Runnable runnable;public MDCRunable(Runnable runnable) {this.copyOfContextMap = MDC.getCopyOfContextMap();this.runnable = runnable;}@Overridepublic void run() {if (!copyOfContextMap.isEmpty()) {MDC.setContextMap(copyOfContextMap);}try {runnable.run();} finally {if (!copyOfContextMap.isEmpty()) {MDC.clear();}}}
}包装MDCCallable
public class MDCCallable implements Callable<Object> {private Map<String, String> copyOfContextMap;private Callable<Object> callable;public MDCCallable(Callable<Object> callable) {this.copyOfContextMap = MDC.getCopyOfContextMap();this.callable = callable;}@Overridepublic Object call() throws Exception {if (!copyOfContextMap.isEmpty()) {MDC.setContextMap(copyOfContextMap);}try {return callable.call();} finally {if (!copyOfContextMap.isEmpty()) {MDC.clear();}}}
}
声明普通线程池
@Bean(name = "threadPoolTaskExecutor" )public ThreadPoolTaskExecutor threadPoolTaskExecutor() {// 这里也可以用metrics来监控线程池,上报数据到prometheusThreadPoolTaskExecutor threadPoolTaskExecutor = new ThreadPoolTaskExecutor();threadPoolTaskExecutor.setCorePoolSize(22);threadPoolTaskExecutor.setMaxPoolSize(22);threadPoolTaskExecutor.setThreadNamePrefix("pool");return threadPoolTaskExecutor;}使用包装线程
@Slf4j
@Component
public class IndexService {@Autowiredprivate ThreadPoolTaskExecutor threadPoolTaskExecutor;public void doSomething(Long networkId) {// 如果使用这种方式,不需要自定义线程池,使用原始线程池,自定义单个线程,并在单个线程种包装MDC信息即可threadPoolTaskExecutor.execute(new MDCRunable(() -> log.info("对 {} 做了操作", networkId)));}}4 总结
- 这里不介绍分布式调用链
- 这里的线程池调用写得有点问题,带有执行的结果应该用线程池submit,没有执行结果的直接用execute即可。
5 跨线程调用传递TraceId
在线程池中用 RunnableWrapper 包裹Runnable,使用CallableWrapper包裹Callable。
这篇关于Spring线程池异步传递MDC信息和TraceId的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!







