本文主要是介绍【机器学习300问】126、词嵌入(Word Embedding)是什么意思?,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
人类的文字,作为一种高度抽象化的符号系统,承载着丰富而复杂的信息。为了让电脑也能像人类一样理解并处理这些文字,科学家们不断探索各种方法,以期将人类的语言转化为计算机能够理解的格式。
一、One-Hot编码的不足
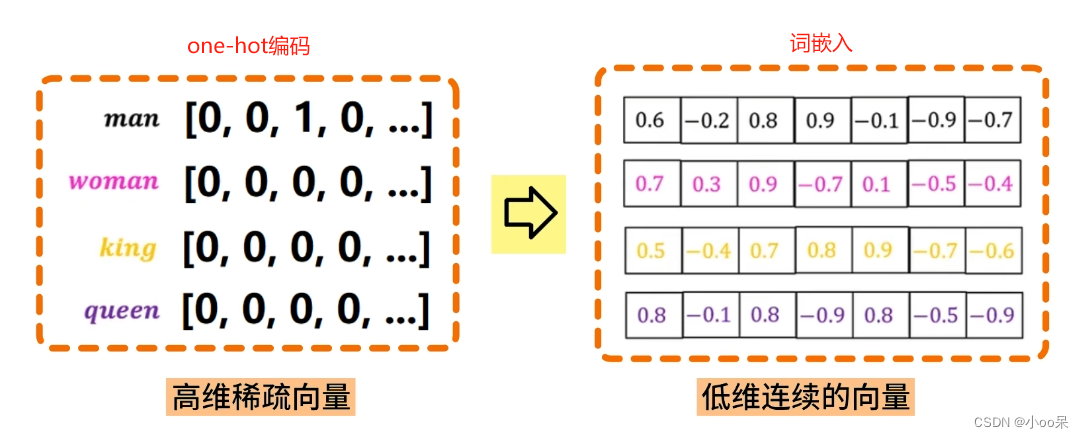
在自然语言处理发展的早期,给文字进行编码是处理文本数据的主要手段。其中,One-Hot编码是一种简单直观的方法,它将每个单词或字符映射为一个独特的二进制向量,该向量的长度等于词汇表的大小,并且只有一个位置是1(表示该单词或字符),其余位置都是0。像是下面这样:
假设我有一个四个单词的字典,分别存放了“man”、“woman”、“king”、“queen”这四个单词。我们可以为每个词分配一个唯一的索引(假设“man”为0,“woman”为1,“king”为2,“queen”为3),然后基于这个索引来创建一个向量,其中对应索引的位置为1,其余位置为0。
- man:
[1, 0, 0, 0] - woman:
[0, 1, 0, 0] - king:
[0, 0, 1, 0] - queen:
[0, 0, 0, 1]
但这样做电脑就真的理解了文字所蕴含的意义了吗?文字与文字之间的关系电脑能读懂吗?真实的世界中字词数量浩如烟海,计算机能处理过来吗?One-Hot编码存在着明显的不足:
-
高维稀疏性:每个词被编码为一个长向量,除了代表该词的那个位置为1,其余均为0,导致向量极其稀疏。对于词汇量大的语言而言,这种编码方式需要极高的维度,造成存储和计算资源的大量浪费。
-
缺乏语义信息:One-hot编码完全忽略了词与词之间的语义关系。每个词被视为独立的实体,即使含义相近的词(如“快乐”与“愉快”)在向量空间中也表现为正交,无法通过向量的距离或相似度来衡量它们的语义相似性。
-
无法捕捉上下文信息:在实际语言使用中,词的意义往往依赖于其上下文环境。One-hot编码无法体现这种上下文的变化,同一词语在不同句子中的语境差异无法通过编码反映出来。
-
模型复杂度增加:由于向量的高维性,基于One-hot编码的模型往往需要处理大量的参数,这不仅增加了计算复杂度,也可能导致过拟合问题。
二、自然语言处理中的词嵌入是什么意思?
(1)词嵌入的定义
词嵌入(Word Embedding)是自然语言处理(NLP)中一种表示文本中单词的方法。词嵌入的核心思想是将单词或短语映射为固定长度的连续向量。这些向量能够捕捉词之间的语义和句法关系。
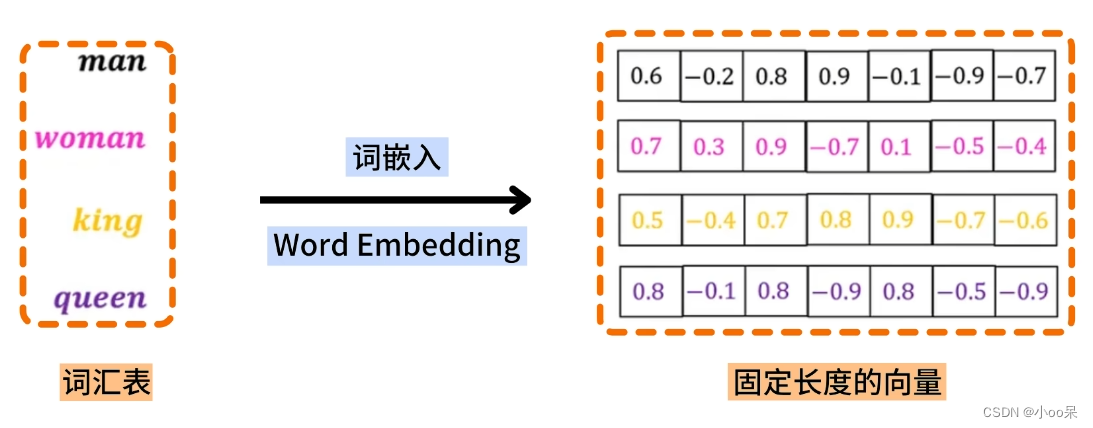
词嵌入方法的关键思想是将单词表示为高维空间中的点,这些点的位置由单词的意义决定。
上图直观的感受到,词汇表中的每个词映射到一个高维向量空间中的一个点。
(2)词嵌入的作用
高维的连续向量空间中的每个点(向量)代表一个词。词嵌入的作用主要包括以下几个方面:
① 降低模型维度
作为深度学习模型的输入,词嵌入相比传统的独热编码(One-hot Encoding)能大幅度减少模型的维度,降低计算复杂度,同时提供更多的语义信息,从而提升诸如文本分类、情感分析、机器翻译等任务的性能。
② 捕获语义信息
词嵌入能够捕捉词语的语义特征,使得具有相似意义的词语在向量空间中距离较近。例如,“猫cat”和“小猫kitten”的词嵌入向量会比“猫cat”和“房子houses”的向量更接近。
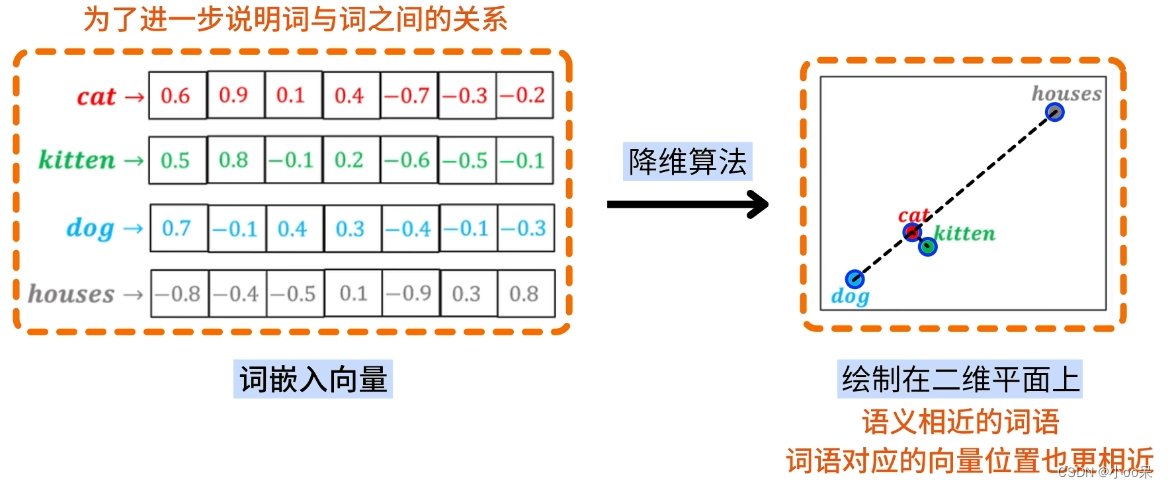
可以通过t-SNE算法将高维空间中的词映射到低纬空间中,便于可视化和探索词汇关系。 t-SNE(t-Distributed Stochastic Neighbor Embedding)是一种非线性降维技术,尤其擅长于将高维空间中的数据点映射到二维或三维的空间中,同时尽可能保持原数据点之间的局部邻近关系。
③ 支持向量运算
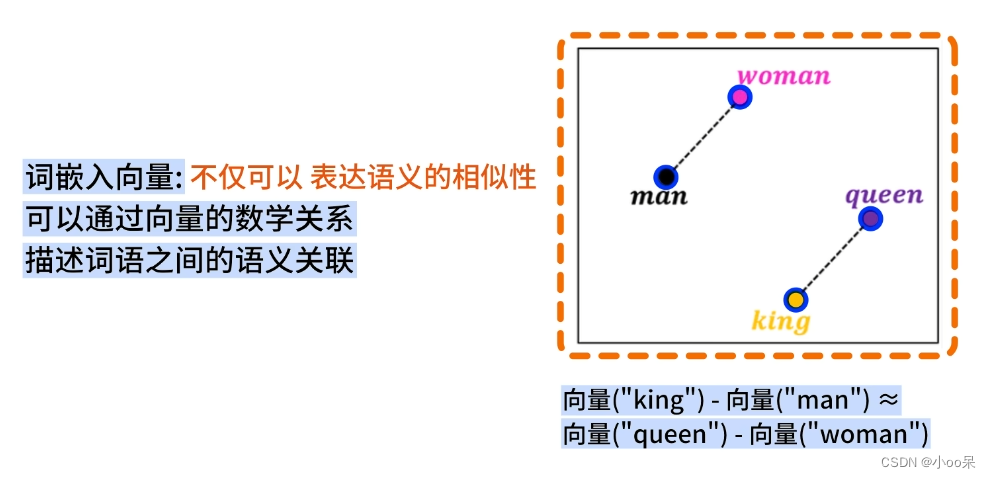
词嵌入允许对词语进行数学运算,比如向量加减可以表达某种语义上的关系。例如“King - Man + Woman = Queen”,这样的运算在某些词嵌入模型中能得出有意义的结果。
计算两个向量的相似度,通常使用余弦相似度来表示:
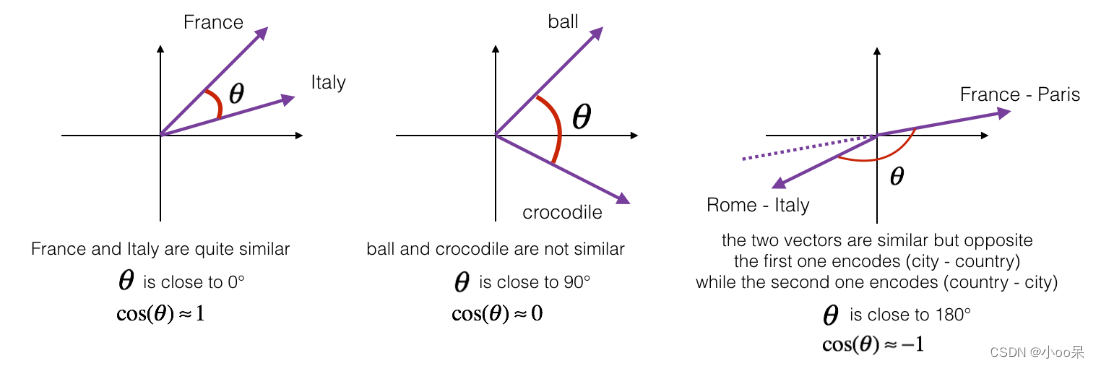
余弦相似度的值域在-1到1之间。值为1表示两个向量完全相同(方向一致),值为0表示两者正交(无相关性),值为-1则意味着两个向量方向完全相反。在实际应用中,正值表示某种程度的相似性,值越接近1相似度越高;负值虽然理论上可能出现,但在大多数自然语言处理任务中,由于向量通常是正向量,所以很少遇到。
④ 支持迁移学习
预训练的词嵌入模型(如Word2Vec、GloVe、FastText等)可以被用作其他NLP任务的起点,使得模型能够在没有大量标注数据的情况下也能学到高质量的文本表示,实现迁移学习的效果。
(3)词嵌入中“嵌”字怎么理解?
词嵌入中的“嵌”字,是指在一个高维向量空间中,一个词就好像嵌入其中一样。它形象地描述了将词语从高维的离散表示(如one-hot独热编码)转换并“嵌入”到一个低维的连续向量空间的过程。在这个过程中,每个词语不再是一个孤立的符号,而是变成了一个在多维空间中有具体位置的向量,这个向量蕴含了词语的语义信息和上下文关联。
这篇关于【机器学习300问】126、词嵌入(Word Embedding)是什么意思?的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!







