本文主要是介绍保护模式总结(四)——分页机制,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
这是总结的最后一篇,来讲讲分页机制。为什么会有分页机制?如果没有分页机制,内存管理会出现“碎片化”的现象,另外,在虚拟存储中,将没有统一调度的内存大小。为了解决这些因为段长度不同而带来的各种内存管理问题,于是有了分页机制。
页的最小单位是4K。引入分页机制之后,段部件获得的地址就不再是物理地址了,而是线性地址,也就是虚拟地址。

于是线性地址和物理地址便存在一种一一映射的关系。那么映射关系如何记录呢?考虑建一张映射表。那么虚拟内存的每个页与其对应的物理内存页,都要记录在映射表里。一般来说,每个任务都可以拥有4GB的虚拟内存空间,而且每个任务都有自己的页映射表。那么我们可以计算一下,一个表4K字节,那么会有1M个表项,每个表项4字节,那么一张映射表大小是4M字节。是不是很大?是的,Intel的大叔们是不会允许这样的浪费存在的,于是现实情况是,多级的分页结构。
两级的分页结构有页目录表和页表。页目录表和每张页表的大小和页的大小一样,都是4KB。
先看图:
页目录项中包含指定页表的物理基地址,页表项中包含着页的物理基地址。所以当我们给出一个虚拟地址的时候,页部件会把它分成三部分,首先通过CR3找到页目录,然后再通过第一部分:页面索引,找到相应页目录项,由此找到相应页表,再通过第二部分页表索引找到页表项,再由其找到物理页面,再由页内偏移地址找到具体的物理地址。那么一开始的CR3是什么呢?
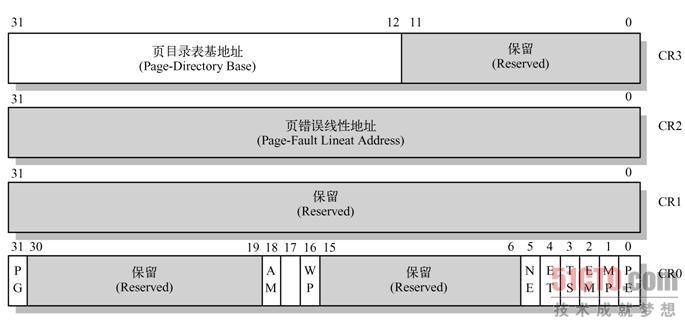
CR3给出了页目录表的基地址。CR0的31位PG(page),置1则打开分页机制。
值得说明的是,地址转换是通过固件,也就是所谓的页部件自动计算的。所以我们不论在操作系统还是应用程序中,在开启了分页机制以后,所用到的都是虚拟地址,具体是什么物理地址,我们不用再去管,我们只用把页目录和页表设置好,页部件就会根据设置自动计算出物理地址。
————————————————分隔符————————————————————————————————————————
讲完了分页机制顺带再补充点内容,关于中断和异常。
中断没什么好说的,异常其实就是实模式中的内部中断。异常以严重性可分三种:
1.故障Fault:通常可纠正
2.陷阱Traps:截获了陷阱条件立即发生,通常用于调试
3.终止Aborts:最严重的错误,程序和任务不能重新启动
中断到了保护模式中,没了中断向量表,变成了类似GDT的IDT(中断描述符表 Interrupt Descriptor Table),同样还有中断描述符寄存器IDTR用于寻址IDT。
中断处理过程如图:
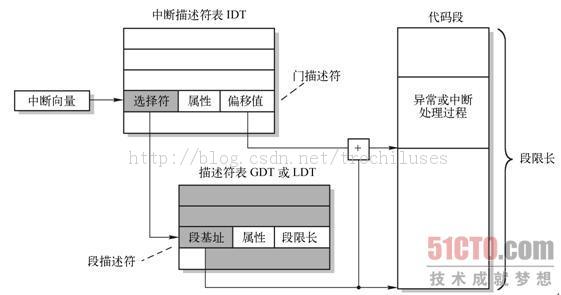
值得注意的是,中断过程若发生特权级的改变,要注意栈的处理。
——————————————————————再次分隔——————————————————————————————————————————
看完这本《从实模式到保护模式》,感觉就是从处理器的角度去认识操作系统。有了这些硬件的基础,相信会对日后对操作系统的学习会有不少帮助!共勉!

这篇关于保护模式总结(四)——分页机制的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!




