本文主要是介绍学习分享-Redis 中的压缩列表 (Ziplist),希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
Redis 中的压缩列表 (Ziplist)
压缩列表 (Ziplist) 是 Redis 内部用于优化小规模数据存储的一种紧凑数据结构。它设计用于高效地存储包含少量元素的列表、哈希表或有序集合,以减少内存占用和提高性能。以下是压缩列表的详细介绍:
1. 压缩列表的结构
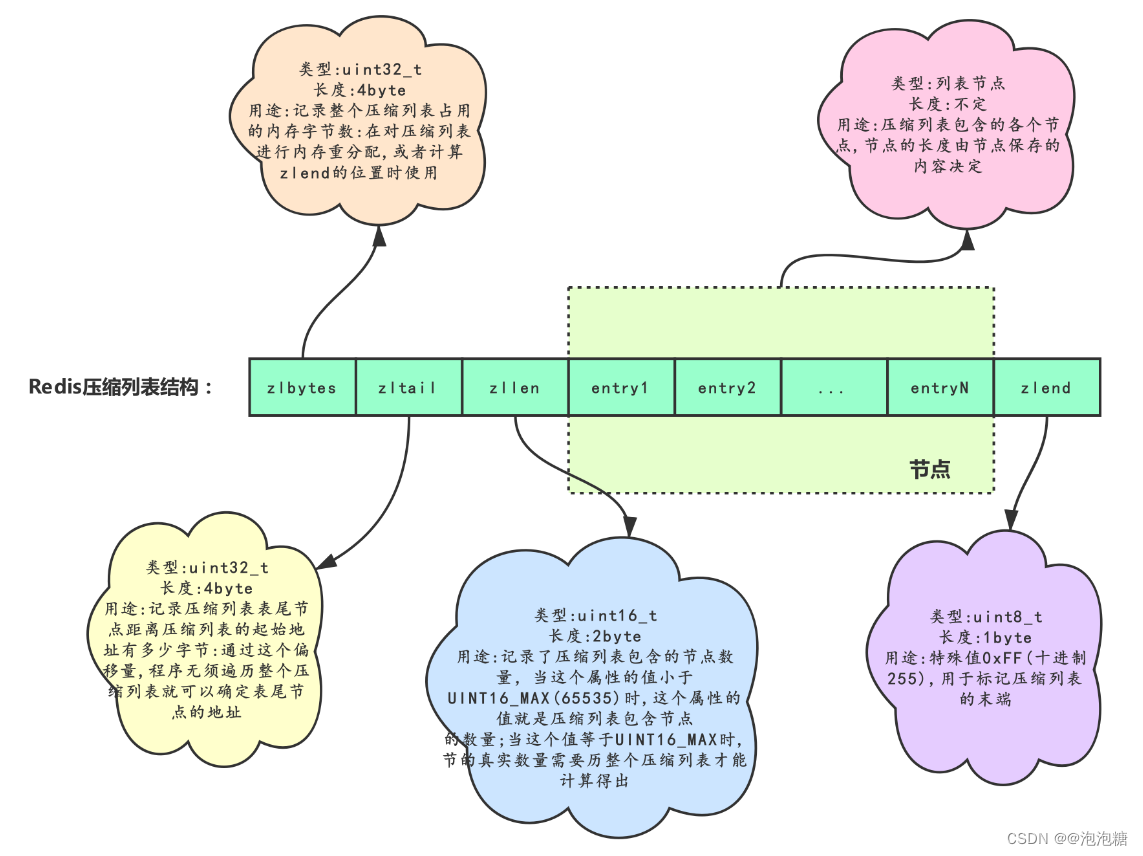
压缩列表是一种连续的内存块,包含多个数据项 (entries)。每个数据项可以是整数或字节数组。整个列表的布局分为以下几个部分:
- zlbytes:用 4 个字节存储整个压缩列表占用的字节数。这便于在内存中复制或重新分配时知道需要处理的数据长度。
- zltail:用 4 个字节存储列表中最后一个数据项距离列表起始位置的字节偏移量。这使得从列表尾部向前遍历时更为高效。
- zllen:用 2 个字节存储列表中的数据项数目。当数据项数目超过 65535 时,zllen 不再准确,仅作为参考。
- entries:实际的数据项列表,每个数据项按顺序存储在这里。
- zlend:一个特殊的字节 (0xFF) 标志着压缩列表的结束。
听到“压缩”两个字,直观的反应就是节省内存。之所以说这种存储结构节省内存,是相较于数组的存储思路而言的。我们知道,数组要求每个元素的大小相同,如果我们要存储不同长度的字符串,那我们就需要用最大长度的字符串大小作为元素的大小(假设是20个字节)。存储小于 20 个字节长度的字符串的时候,便会浪费部分存储空间。

数组的优势占用一片连续的空间可以很好的利用CPU缓存访问数据。如果我们想要保留这种优势,又想节省存储空间我们可以对数组进行压缩。
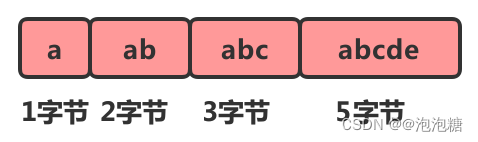
但是这样有一个问题,我们在遍历它的时候由于不知道每个元素的大小是多少,因此也就无法计算出下一个节点的具体位置。这个时候我们可以给每个节点增加一个lenght的属性。
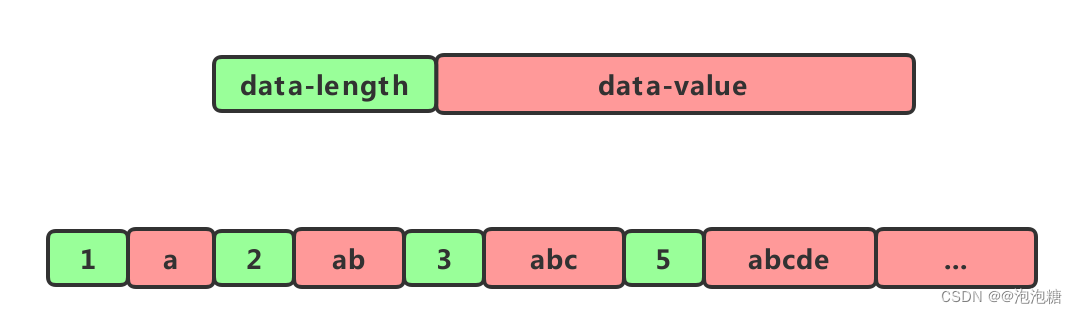
如此。我们在遍历节点的之后就知道每个节点的长度(占用内存的大小),就可以很容易计算出下一个节点再内存中的位置。这种结构就像一个简单的压缩列表了。
2. 数据项的结构
每个数据项由三个部分组成:
- 前置长度 (prevlen):记录前一个数据项的长度。这有助于在内存中反向遍历列表。该长度使用 1 或 5 个字节存储,具体取决于前一个数据项的长度。如果前一个数据项的长度小于 254 字节,则使用 1 个字节;否则,使用 5 个字节(前 1 个字节为 254,后 4 个字节存储实际长度)。
- 数据长度 (encoding):记录当前数据项的长度和类型。这部分使用变长编码 (variable-length encoding) 存储,既可以是整数,也可以是字节数组。根据数据类型,可能使用 1 至 5 个字节。
- 数据 (content):存储实际的数据内容。
3. 数据项的编码
压缩列表支持多种数据类型的编码,以提高存储效率:
- 整数编码:对于可以表示为整数的数据项,压缩列表使用特定的编码方式以减少空间。
- 4 位标识符和 4 位实际值(用于 0 至 12 之间的整数)。
- 8 位、16 位、24 位、32 位和 64 位整数编码(分别适用于不同范围的整数)。
- 字节数组编码:对于其他类型的数据项,压缩列表使用变长编码来表示长度(1 至 5 个字节),然后存储实际的字节数据。
4. 操作和效率
压缩列表的设计初衷是高效处理小规模数据,具体操作包括:
- 插入:在压缩列表中插入一个数据项时,Redis 可能需要调整后续数据项的前置长度字段,导致链式更新。如果新数据项插入到中间位置,尤其是前一个数据项的长度变化较大时,这种更新成本会更高。
- 删除:删除数据项后,Redis 也可能需要调整相邻数据项的前置长度字段。
- 查找:由于压缩列表是一个连续的内存块,直接索引查找数据项比链表更高效。遍历也可以在正向和反向都高效进行,尤其是在尾部插入和删除时。
5. 使用场景
压缩列表被 Redis 用于以下场景:
- 短列表:当列表包含的元素数量较少且每个元素较小时,Redis 使用压缩列表来替代常规的链表。
- 小哈希表:当哈希表的字段数量较少且字段和值都较小时,压缩列表可以用来替代标准哈希表结构。
- 有序集合 (Sorted Set):当有序集合包含的元素数量较少时,压缩列表可用来替代跳跃表 (skiplist) 和散列表 (hash table) 的组合。
Redis 对于何时使用压缩列表有特定的配置选项,可以通过调整这些选项来控制其使用阈值。
6. 优缺点
- 优点:
- 内存占用低:通过紧凑的内存布局和变长编码,压缩列表减少了内存使用。
- 高效的顺序访问:由于数据存储在连续的内存块中,顺序访问和遍历非常高效。
- 缺点:
- 插入和删除复杂度高:在中间位置进行插入和删除操作时,可能需要调整多个数据项的前置长度字段,增加了操作成本。
- 不适合大规模数据:对于大量数据,压缩列表的链式更新会带来显著的性能开销。
参考资料
- Redis 官方文档:Redis Data Types
- Redis 源代码:ziplist.c
这篇关于学习分享-Redis 中的压缩列表 (Ziplist)的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





