本文主要是介绍软考又考了,数据库范式这次一定要弄懂!,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
0. 引言
今年数据库范式又作为选择题在软考中出题了,范式和反范式同样也在我们日常开发的数据库表设计工作中提供重要理论,今天我们来彻底弄懂几大范式的概念和区别,以及常见的反范式设计方法
1. 定义
1.1 基础概念
在实际讲解之前,我们先普及一些基础概念,方便初次接触的同学理解
- 键(码/超键)
键也称为码,即能够唯一标识一条记录的属性或属性集,即可以是单个字段或者多个字段的组合。比如{员工id, 身份证号,姓名,电话}中,员工id,身份证号,电话都能唯一标识一个员工,则他们都是键,同时键也称为码
这里需要注意的是键没有声明最小化,也就是说{姓名,电话}组合起来也可以唯一标识一个员工,那么{姓名,电话}的组合我们也可以称为是一个键
- 候选键(候选码/超级码)
候选键即能够唯一标识一条记录的最小属性集,所以候选键是没有任何多余属性的键
这里就是声明了最小化的,我们能说{姓名,电话}是一个键,但不是一个候选键,再最小化后可以说电话是一个候选键,员工id, 身份证号这些都可以唯一标识,且已经最小化了,所以都可以作为候选键
- 主键(主码)
主键就是从候选键中挑选一个作为主键,而挑选的规则没有严格要求,但一般我们按照简单性来进行选择,比如选Integer类型不选String类型,选Long类型不选String类型,所以当员工id和身份证号时,我们更倾向于选择员工id作为主键
- 外键(外码)
另一个关系(数据库表)中的主键,用来关联个关系集(表)
比如{订单id, 订单创建时间,总金额} 和 {商品id, 商品名称,订单id},在{商品id, 商品名称,订单id}中订单id就是外键
- 自然键
自然生活中唯一能够标识一条记录的键,比如员工id和身份证号中,身份证号就是自然键,因为员工id在自然生活中并不存在,是我们在系统设计中人为定义的
- 全码
所有的属性共同构成一个候选码时,这时该候选码为全码
- 主属性
即候选码中的属性
1.2 第1范式
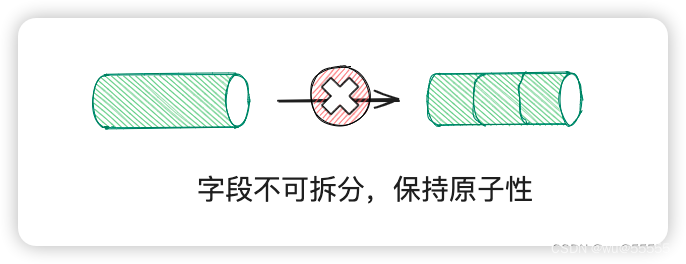
1NF: 属性值都是不可分的原子值
完整定义:在关系模式R中,当且仅当所有域只包含原子值,即每个属性都是不可再分的数据项,则称关系模式R是第一范式
案例:
第1范式的定义是比较好理解的,也就是强调原子性,属性是不可再分的
比如存在列字段:姓名、电话,根据业务场景判断,如果业务场景中有座机电话、手机电话,那么电话字段就不再保持原子性了,因为可以拆分为座机电话、手机电话,我们数据库设计就要调整为:姓名、座机电话、手机电话,才能让字段不能再拆分,保持原子性。
所以属性的原子性一方面还要根据业务场景来判断,结合业务场景出现的信息,如果已经不能再往下拆分了,那说明满足原子性了。
1.3 第2范式
2NF: 消除主属性对候选键的部分依赖
完整定义:当且仅当实体E是第一范式,且每个非主属性完全依赖主属性(即不存在部分依赖)时,则称实体E是第二范式
首先要明确什么是完全依赖,什么是部分依赖?
官方定义是这样的:
- 部分函数依赖:设X,Y是关系R的两个属性集合,存在X→Y,若X’是X的真子集,存在X’→Y,则称Y部分函数依赖于X
- 完全函数依赖:设X,Y是关系R的两个属性集合,X’是X的真子集,存在X→Y,但对每一个X’都有X’!→Y,则称Y完全函数依赖于X
举例子来说:
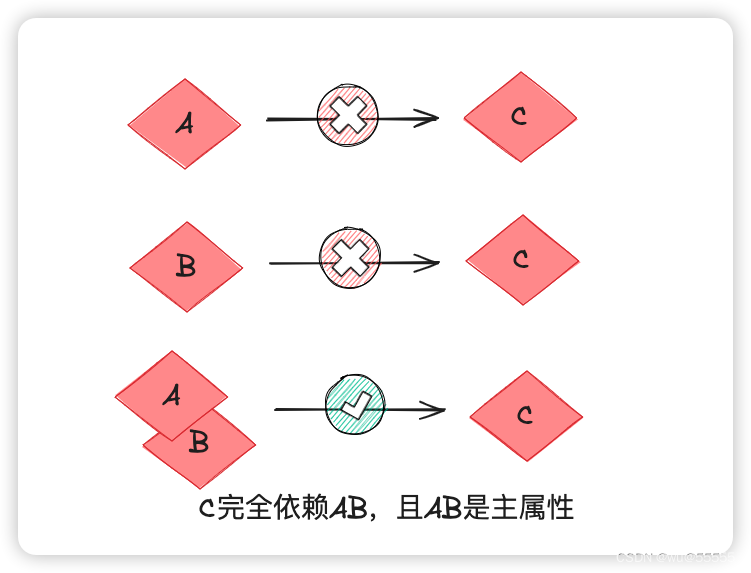
- 如果属性A能推导出C, 属性B也能推导出C, 那则说C部分依赖于AB,
- 如果AB一起可以推导出C, A和B单独都不能推导出C, 那说明C完全依赖于AB
- 如果C只能由A推导出,则C完全依赖于A
也就是说由一个或多个属性的集合中的一部分就能推导出某一属性,就说明这个属性部分依赖于这一集合。如果要这个集合全部组合在一起才能推导出这个属性,那么就说明这个属性完全依赖于这个集合。
案例:
比如订单表中包含字段:订单id, 订单创建时间,总金额,商品id, 商品名称,明显主键是订单id, 总金额、创建时间、商品id都完全依赖于于订单id, 即只由订单id可以关联出这几个信息,但是一个订单中可能有多个商品,因此商品名称是完全依赖于商品ID,部分依赖于订单ID
所以关系{订单id, 订单创建时间,总金额,商品id, 商品名称}是不能满足第2范式的,我们对其拆分{订单id, 订单创建时间,总金额}, {商品id, 商品名称,订单id},拆分成两个保持完全依赖的关系,则其满足第2范式
1.4 第3范式
3NF: 消除非主属性对候选键的传递依赖
完整定义:当且仅当实体E是第二范式,且E中没有非主属性传递依赖于候选键时,则称实体E是第三范式
首先这里要理解什么是传递依赖?
如果有A->B, B->C, 则A->C,这样的传递关系就称为依赖传递
举例来讲订单ID->商品ID, 商品ID->商品名称,则订单ID->商品名称,我们说商品名称传递依赖于订单ID
也就是说第3范式是要消除非主属性之间的传递依赖。这意味着非主属性不能依赖于其他非主属性
案例:
U={订单ID,创建时间,商品ID,商品名称}, F={订单ID->创建时间,订单ID->商品ID, 商品ID->商品名称},则可以推导订单ID->商品名称,因为订单ID是候选键,商品名称是非主属性,且商品名称传递依赖于订单ID, 所以不满足第3范式

1.5 BC范式
BCNF(Boyce-Codd范式): 消除主属性对候选键的部分和传递依赖
完整定义:设R是一个关系模式,F是它的依赖集,R属于BCNF当且仅当其F中每个依赖的决定因素必定包含R的某个候选码
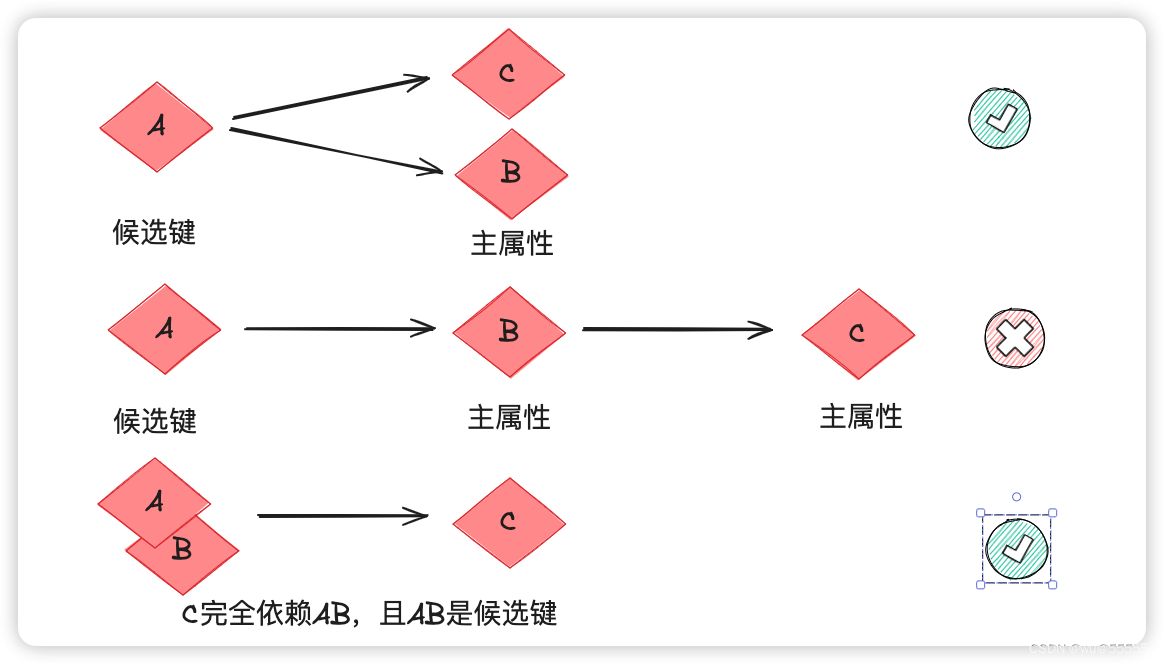
BC范式的定义比较难理解,翻译过来就是:每个属性都不部分依赖于候选键,也不传递依赖于候选键
第三范式要求的是非主属性不传递依赖于候选键,而BC是要求每个属性都不传递依赖和部分依赖于候选键,即包括候选键本身
案例:
设定选课表(学号, 课程号, 教师编号),且每位老师只教一门课,而一门课可以有多个老师。
那么候选键就是(学号、课程号)、(学号、教师编号),即存在两个复合候选键,任意单个属性都无法组成候选键
于是可以得到(学号、课程号)-> 教师编号,(学号、教师编号)-> 课程号,教师编号 -> 课程号
因为第3范式要求非主属性不能依赖于其他非主属性,而该模式不存在非主属性,所以明显满足第3范式
同时这里可以看出,主属性课程号传递依赖于候选键(学号,教师编号),因此不满足BCNF。
2. 反范式常用手段
范式带来的影响就是减少数据冗余,但带来了更多的查询消耗,所以反范式的目标就是提高查询效率,其常用的手段有
- 派生列冗余
所谓派生列,就是可以通过其他列推导出来的列,比如表字段有数量、单价,总金额就是派生列,因为其可以由单价*数量计算的来,但对他冗余,可以在查询时减少复杂计算带来的消耗,从而提高查询效率
- 普通列冗余
普通列冗余主要是为了减少关联表查询时带来的io操作,从而提高查询效率,所以其场景是涉及多表关联查询时
- 表结构重新设计
表结构重新设计带来的工作量比较大,其作用就是通过重新设计表结构,将常查询的字段组合到一张表,减少多次关联io操作,从而提高查询效率,因为设计表字段的重新组合,所以也有表垂直拆分的含义
- 表数据水平拆分
数据水平拆分就是将行数据拆分存储,比如按照地区、时间范围进行水平拆分存储,其目的是减少一次查询的数据量,从而提高查询效率
这篇关于软考又考了,数据库范式这次一定要弄懂!的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!







