本文主要是介绍java之sql注入审计,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
1 基础环境搭建
1.1 mysql数据库搭建
phpStudy是一个PHP调试环境的程序集成包,PHP+Mysql+Apache。 通过phpstduy下载与安装指
定版本的mysql数据库【可以同时下载多个版本,便于应对不对的系统及复现漏洞便捷切换多个版本】
完成下载后,启动服务即可。
(2)使用navicat连接mysql服务后可进行相关操作,连接成功后,打开数据库,可以打开数据表直接读写,也可以执行相关SQL命令

1.2 mysql数据库配置
MySQL 安装包:MySQL :: Download MySQL Community Server
MySQL安装教程:MySQL 安装 | 菜鸟教程
MySQL配置文件


允许远程连接
mysql>GRANT ALL PRIVILEGES ON *.* TO ‘root’@‘%’ IDENTIFIED BY‘密码’ WITH GRANT OPTION; mysql>flush privileges
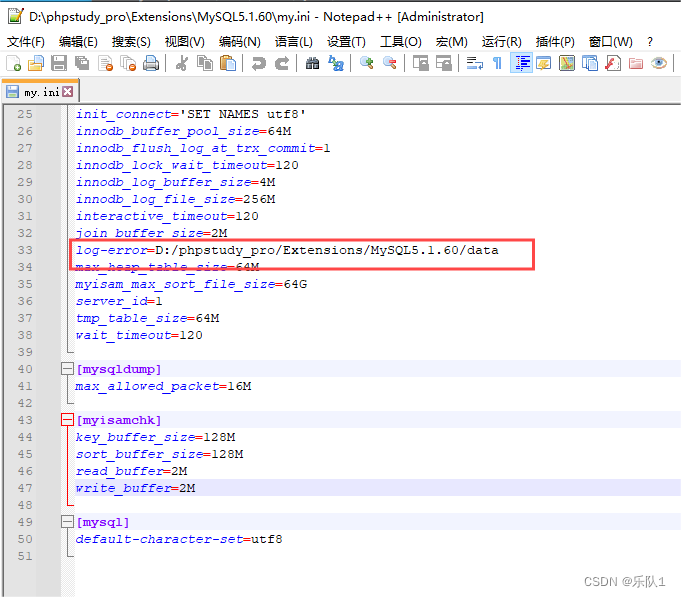
MySQL开启日志记录
找到MySQL的配置文件 my.ini,在 [mysqld] 中port参数下方添加一行记录:
log="D:/phpstudy_pro/Extensions/MySQL5.1.60/data" 保存重启数据库 此时会在指
定路径下新增一个日志文件。
2 在线SQL练习平台
2.1 SQL Fiddle
SQL Fiddle - Online SQL Compiler for learning & practice, SQL Fiddle 支持 MySQL、SQL Server、SQLite 等主流的 SQL 引擎,在这
里可以选择练习的数 据库以及版本号 。

2.2 SQLZOO
https://sqlzoo.net/, SQLZOO包括了 SQL 学习的教程和参考资料, 支持 SQL Sever、Oracle、MySQL、DB2、 PostgreSQL等多个 SQL 搜索引擎 。
2.3 SQL Bolt
SQLBolt - Learn SQL - Introduction to SQL, SQLBolt 是一个适合小白学习 SQL 的网站,这里由浅及深的介绍了 SQL 的知识,每一个章节是一组相关的 SQL 知识点,且配备着相应的练习 。
3 SQL语法学习
SQL (Structured Query Language:结构化查询语言) 用于管理关系数据库管理系统 (RDBMS),可以访问和处理数据库,包括数据插入、查询、更新和删除。
• 提示:
SQL 对大小写不敏感
分号:分号是在数据库系统中分隔每条 SQL 语句的标准方法,这样就可以在对服务器的相同 请求中执行一条以上的语句
3.1 Select查询
SELECT 语句用于从数据库中选取数据。
语法格式: SELECT column_name,column_name FROM table_name; 或 SELECT * FROM table_name
3.2 WHERE语句
WHERE 子句用于过滤记录.
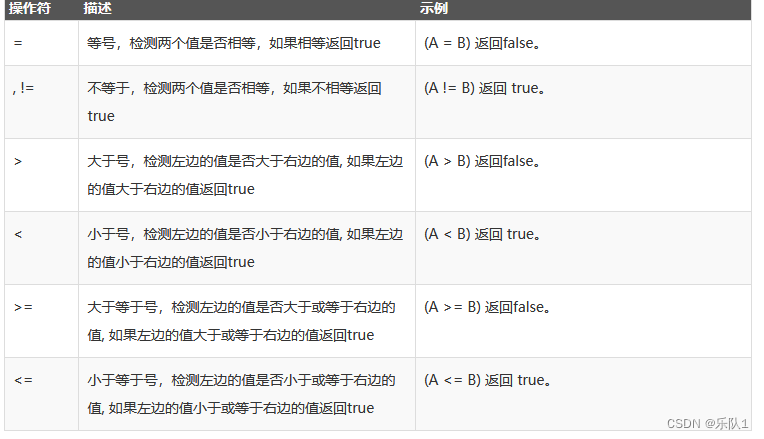
语法格式: SELECT column_name,column_name FROM table_name WHERE column_name operator value;
例如:
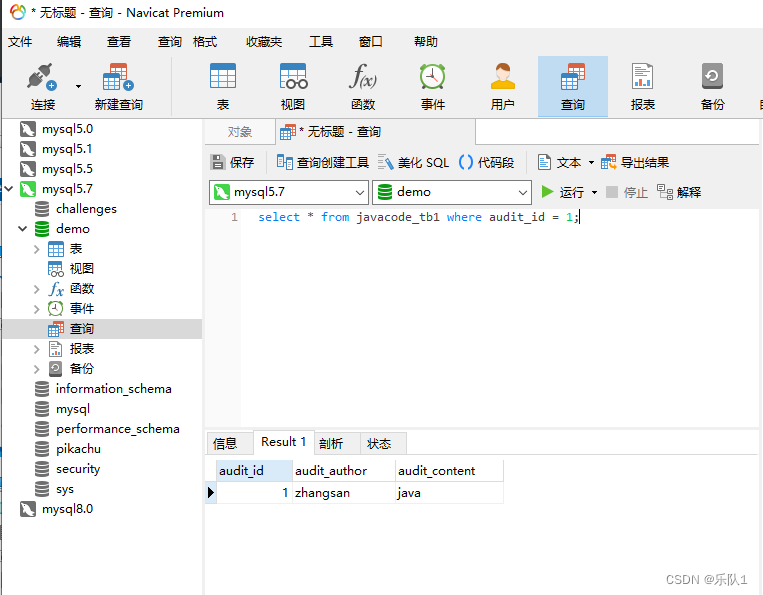
where之=查询数据:select * from javacode_tb1 where audit_id = 1;
3.3 UNION联合查询
UNION 用于合并两个或多个 SELECT 语句的结果集,并消去表中任何重复行。 UNION 内部的
SELECT 语句必须拥有相同数量的列,列也必须拥有相似的数据类型。 同时,每条 SELECT 语句中的
列的顺序必须相同。
语法格式: SELECT column_name FROM table1 UNION SELECT column_name FROM table2
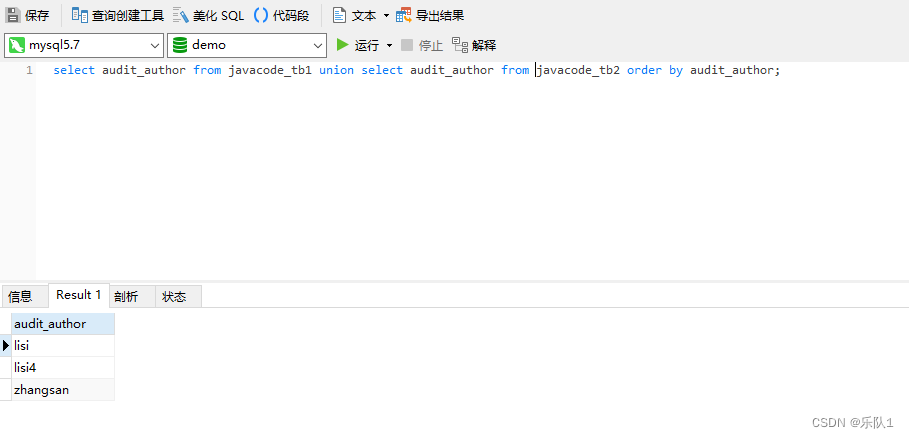
union查询:select audit_author from javacode_tb1 union select audit_author from javacode_tb2 order by audit_author;
提示:默认地,UNION 操作符选取不同的值。如果允许重复的值,请使用 UNION ALL
3.4 ORDER BY 关键字
ORDER BY 关键字用于对结果集进行排序。 默认按照升序对记录进行排序。如果需要按照降序对记录
进行排序,您可以使用 DESC 关键字。
语法结构: SELECT column_name,column_name FROM table_name ORDER BY
column_name,column_name ASC|DESC
例如: 按照 “alexa” 列升序排序: SELECT * FROM Websites ORDER BY alexa; 按照 “alexa”
列降序排序: SELECT * FROM Websites ORDER BY alexa DESC;
(1)order by 后面可以跟字段名,表达式和字段的位置号。
例如: select * from student_table order by student_age
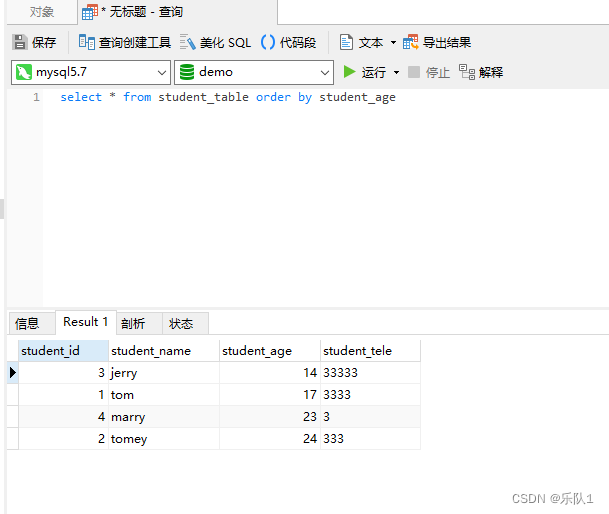
例如: select * from student_table order by 3;
思考:order by 后的索引是从0开始还是从1开始?经过测试mysql数据库的order by 索引从1开始,而非0

当表达式不成立时,执行后者,成立执行前者
提示:if语句返回的是字符类型,不是整型
select * from student_table order by if(1=1,student_age,student_tele)

3.5 like模糊查询
LIKE 操作符用于在 WHERE 子句中搜索列中的指定模式。 "%" 符号用于在模式的前后定义通配符(默认字母)。
基本语法: SELECT column_name(s) FROM table_name WHERE column_name LIKE pattern
例如:select * from javacode_tb1 where audit_author like '%s%';
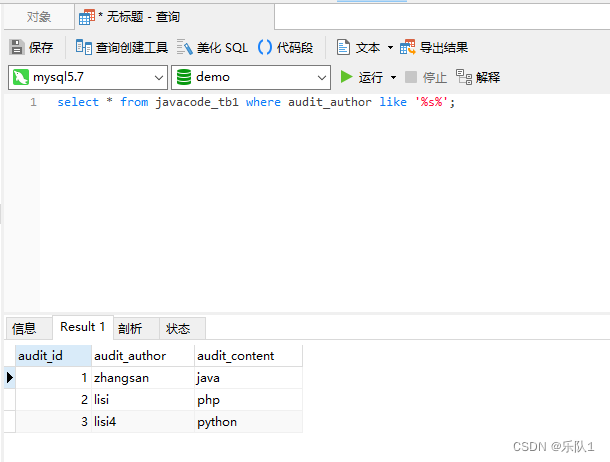
3.6 in关键字
IN 操作符通常用来在 WHERE 子句中规定多个值【而不是一个范围】
语法格式: SELECT column_name(s) FROM table_name WHERE column_name IN
(value1,value2,...) ;
例如: 选取 student_name 为 "tom" 或 ”jerry" 的所有网站,
SELECT * FROM student_table WHERE student_age IN (17,14);

3.6 group by 分组查询
GROUP BY 语句通常结合一些聚合函数来使用,根据一个或多个列对结果集进行分组。
常用聚合函数包括:count() —— 计数 、sum() —— 求和 、avg() —— 平均数 、max() —— 最大值 、min() —— 最小值
例如1:
(1)创建数据表:
DROP TABLE IF EXISTS employee_tbl; CREATE TABLE employee_tbl ( id INT(11) NOT NULL, name VARCHAR(100) NOT NULL DEFAULT '', date DATETIME NOT NULL, login_count TINYINT UNSIGNED NOT NULL DEFAULT 0 COMMENT '登录次数', PRIMARY KEY (id) ) ENGINE=InnoDB DEFAULT CHARSET=utf8;
(2)向数据表中插入数据:
INSERT INTO employee_tbl VALUES ('1','小明', '2016-04-22 15:25:33', '1'), ('2', '小王', '2016-04-20 15:25:47', '3'), ('3', '小丽', '2016-04-19 15:26:02', '2'), ('4', '小王', '2016-04-07 15:26:14', '4'), ('5', '小明', '2016-04-11 15:26:40', '4'), ('6','小明', '2016-04-04 15:26:54', '2');
(3)执行group by查询操作:
SELECT name, COUNT(*) FROM employee_tbl GROUP BY name;

3.8. 数据库常见函数
3.8.1 聚焦函数
-
avg:返回指定字段的数据的平均值
-
count:返回指定字段的数据的行数(记录的数量)
-
max:返回指定字段的数据的最大值
-
min:返回指定字段的数据的最小值
-
sum:返回指定字段的数据之和
3.8.2 处理字符串函数
-
合并字符串函数:concat(str1,str2,str3…)
-
比较字符串大小函数:strcmp(str1,str2)
-
获取字符串字节数函数:length(str)
-
获取字符串字符数函数:char_length(str)
-
字母大小写转换函数:大写:upper(x),ucase(x);小写lower(x),lcase(x)
-
字符串查找函数:find_in_set(str1,str2)、field(str,str1,str2,str3…)、locate(str1,str2)、position(str1 INstr2)、nstr(str1,str2)
-
获取指定位置的子串:elt(index,str1,str2,str3…)、left(str,n)、right(str,n)、substring(str,index,len)
-
字符串去空函数:ltrim(str)、rtrim(str)、trim()
-
字符串替换函数:insert(str1,index,len,str2)、replace(str,str1,str2)
3.8.3 处理时间日期的函数
-
获取当前日期:curdate(),current_date()
-
获取当前时间:curtime(),current_time()
-
获取当前日期时间:now()
-
从日期中选择出月份数:month(date),monthname(date)
-
从日期中选择出周数:week(date)
-
从日期中选择出年数:year(date)
-
从时间中选择出小时数:hour(time)
-
从时间中选择出分钟数:minute(time)
-
从时间中选择出今天是周几:weekday(date),dayname(date)
3.8.4 处理数值的函数
-
绝对值函数:abs(x)
-
向上取整函数:ceil(x)
-
向下取整函数:floor(x)
-
取模函数:mod(x,y)
-
随机数函数:rand()
-
四舍五入函数:round(x,y)
-
数值截取函数:truncate(x,y)
3.8.5 与安全相关的函数应用(重要)
-
获取当前用户:(1)select user();(2)select current_user();(3)select current_user;(4)selectsystem_user();(5)select session_user();
-
获取当前数据库:(1)select database();(2)select schema();
-
获取所有数据库:SELECT schema_name FROM information_schema.schemata;
-
元数据:人家Mysql自有的数据库中数据库所存储的数据
-
获取服务器主机名:select @@HOSTNAME;
-
查询用户是否有读写权限:SELECT grantee, is_grantable FROM information_schema.user_privileges WHERE privilege_type = 'file' AND grantee like '%username%';SELECT file_priv FROM mysql.user WHERE user = 'root';(需要root用户来执行)
-
注释:(1)单行注释:--(2)多行注释://
-
字符串截取:SELECT substr('abc',2,1);
-
MySQL特有的写法:/! SQL语句 / :这种格式里面的SQL语句可以被当成正常的语句执行。当版本号大于!后面的一串数据,SQL语句则执行
-
空格被过滤编码绕过:%20, %09, %0a, %0b, %0c, %0d, %a0%a0UNION%a0select%a0NULL
-
or,and绕过:or可以使用||代替,and可以使用&&代替。
-
union select被过滤:(1)union(select(username)from(admin)); :union和select之间用(代替空格。
-
select 1 union all select username from admin; :union和select之间用all,还可以用distinct3
-
select 1 union%a0select username from admin; :同样的道理%a0代替了空格。select 1 union/!select/username from admin; 。
-
select 1 union/hello/username from admin; 注释代替空格
-
关键字where被过滤使用limit来代替(limit被用于强制 SELECT 语句返回指定的记录数)
-
limit绕过:使用having函数(having:在聚合后对组记录进行筛选,类似于where作用,经常与grop by使用)
-
having函数绕过:group_concat():将相同的行组合起来
4 SQL注入漏洞
在输入的字符串中注入 SQL 语句,如果应用相信用户的输入而对输入的字符串没进 行任何的过滤处理,那么这些注入进去的 SQL 语句就会被数据库误认为是正常的 SQL 语句而 被执行。
4.1 万能密码绕过登陆
select * from admin where username='$username'and password='$password' 若输入 ' or 1=1-- (后面有个空格)
则后端变成: select * from admin where username='' or 1=1 -- 'and password='$password’
例如:
打开SQL注入漏洞测试(登录绕过)_SQL注入_在线靶场_墨者学院_专注于网络安全人才培养,
输入 ' or 1=1# 或'or 1=1--
4.2 SQL注入分类
-
有无回显:显注、盲注
-
按数据库类型:MySQL、Access、SQL Server、Oracle等
-
注入点参数类型:数字型、字符型 当发生注入点的参数为整数时,比如 ID,num,page等,这种形式的就属于数字型注入漏洞。 当注入点是字符串时,则称为字符型注入,字符型注入需要引号来闭合。
-
按请求方式:GET注入、POST登录框注入、Cookie验证注入、HTTP头注入
4.3 常见的注入点
应用程序和数据交互的地方:
-
Authentication(认证页面)
-
Search Fields (搜索页面)• Post Fields (Post请求)
-
Get Fields (Get请求)
-
HTTP Header(HTTP头部)
-
Cookie
4.4 数据库特性
(1) 数据库特定表
-
and exists(select count(*) from msysobjects)
mysysobjects表为access特有,一般返回权限不足
-
and exists(select count(*) from sysobjects)
sysobjects表为SqlServer特有,一般返回正常
-
and (select count(*) from information_schema.TABLES)>0
information_schema为MySQL 5.0 及以上版本特有
(2) 数据库报错
| 数据库 | 错误代码 | 错误描述 | 示例 |
|---|---|---|---|
| MySQL | 1064 | SQL语法错误 | ERROR 1064 (42000): You have an error in your SQL syntax; check the manual that corresponds to your MySQL server version for the right syntax to use near '...' at line X |
| Oracle | ORA-00933 | SQL命令未正确结束 | ORA-00933: SQL command not properly ended |
| Oracle | ORA-00904 | 无效的标识符 | ORA-00904: "COLUMN_NAME": invalid identifier |
| SQL Server | Msg 102 | 语法错误 | Msg 102, Level 15, State 1, Line X Incorrect syntax near '...'. |
| PostgreSQL | ERROR | 语法错误 | ERROR: syntax error at or near "..." LINE X: ... |
(3) 注释符
以下是一个表格,展示了各个数据库系统中常用的注释符:
| 数据库 | 单行注释符 | 多行注释符 |
|---|---|---|
| MySQL | # 或 --(注意--后面有一个空格) | /* ... */ |
| Oracle | -- | /* ... */ |
| SQL Server | -- | /* ... */ |
| PostgreSQL | -- | /* ... */ |
| Access | 无直接注释符,通常在代码编辑器中使用注释功能 | 无直接注释符 |
4.5 数据库特性
-
information_schema.schemata 存放所有数据库名,schema_name为数据库名字段
-
information_schema.tables 存放所有数据库的表名,table_schema存放数据库名,table_name字段存放表名
-
information_schema.columns 存放所有数据库表的所有列名,table_schema 库名,table_name表名,column_name列
4.6 SQL注入常规思路(MySQL)
-
判断注入点,检测网站脆弱性
-
判断数据库类型和版本 借助数据库特性进行判断,如数据库支持的函数、符号等
-
order by 判断列数
-
找到可以显示数据的位置
-
爆库名
-
爆表名
-
显示admin表中的字段名
-
显示字段内容
4.7 sql注入靶场
-
SQL注入在线靶场:RedTiger's Hackit
-
DVWA:https://dvwa.co.uk/
-
sqli-labs源码:https://github.com/Audi-1/sqli-labs
5 SQL注入漏洞审计
执行对象是SQL的执行者。 目前常用的执行对象接口有三种: Statement、PreparedStatement和
CallableStatement 。
5.1 JDBC
5.1.1 Statement
Statement 主要用于执行静态SQL语句,即内容固定不变的SQL语句。Statement 每执行一次都要对传入的SQL语句编译一次,效率较低 。
例如:
String name = "tom";
String sqlString = "select * from student_table where student_name = '" + name + "'";
Connection conn = open();
ResultSet rs = null;
Statement stmt = conn.createStatement();
rs = stmt.executeQuery(sqlString);
System.out.println(stmt);
while (rs.next()){
System.out.println("student_id:" + rs.getInt("student_id") + "\t"
+ "student_name:" + rs.getString("student_name") + "\t"
+ "student_age:" + rs.getString("student_age") + "\t"
+ "student_tele:" + rs.getString("student_tele") + "\t");}
}
若 name 为用户可控参数,当用户传入 ' or 1 = 1 # 则sqlString为:select * from student_table where student_name = ' ' or 1 = 1 # ', 可以看到程序输出 student_table 表中所有条目.

5.1.2 PreparedStatement
PreparedStatement是预编译参数化查询执行SQL语句的方式。
例如
String sql = "select * from student_table where name = ?"; Connection conn = open(); PreparedStatement pstmt = (PreparedStatement) conn.prepareStatement(sql); //对占位符进行初始化 pstmt.setString(1, "tom"); pstmt.executeQuery();
看到使用PreparedStatement之后,特殊符号被转义,无法按设想的SQL语句执行了。

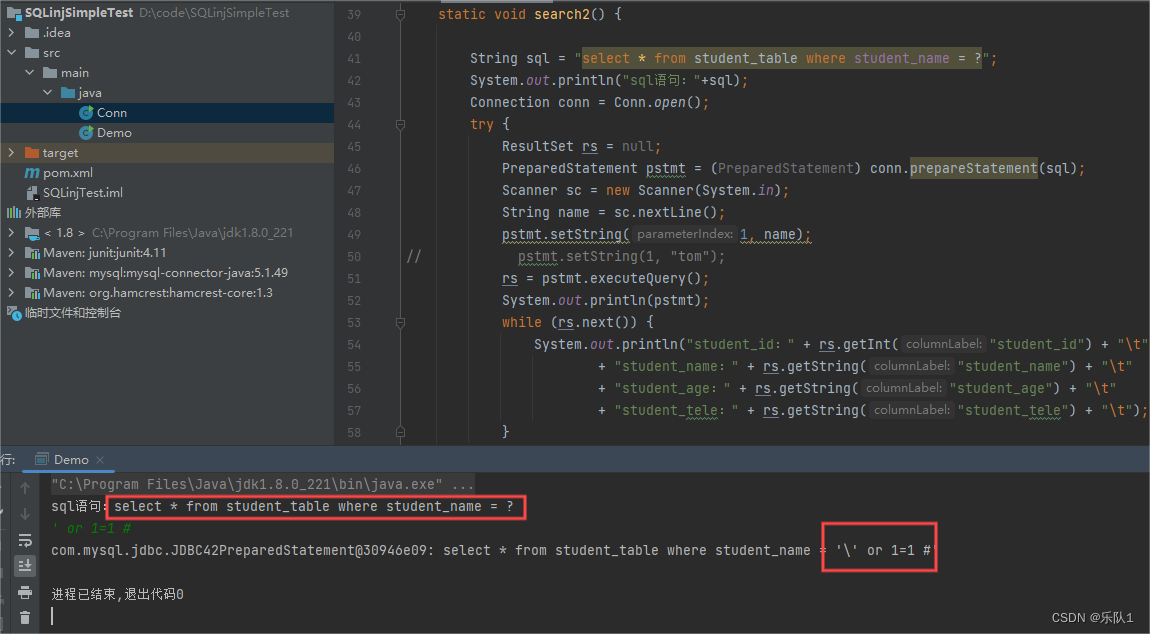

看到使用PreparedStatement之后,特殊符号被转义,无法按设想的SQL语句执行了。
早期开发为了满足需求,不得已的情况直接使用普通对象进行了变量的拼接执行了sql
5.1.3CallableStatement
SQL 语句
-- 创建表 CREATE TABLE student_table (student_id INT PRIMARY KEY,student_name VARCHAR(50) NOT NULL,student_age INT NOT NULL,student_tele VARCHAR(15) NOT NULL ); -- 插入数据 INSERT INTO student_table (student_id, student_name, student_age, student_tele) VALUES (1, 'Tom', 20, '123-456-7890'); INSERT INTO student_table (student_id, student_name, student_age, student_tele) VALUES (2, 'Alice', 22, '234-567-8901'); INSERT INTO student_table (student_id, student_name, student_age, student_tele) VALUES (3, 'Bob', 23, '345-678-9012'); INSERT INTO student_table (student_id, student_name, student_age, student_tele) VALUES (4, 'Charlie', 21, '456-789-0123');
Java 示例代码
import java.sql.*;
import java.util.Scanner;
public class CallableStatementSQLInjectionExample {public static void main(String[] args) {search();}
static void search() {String sql = "{CALL getStudentByName('" + getUserInput() + "')}";System.out.println("SQL Statement: " + sql);
Connection conn = null;CallableStatement callableStmt = null;
try {conn = Conn.open(); // 假设 Conn 是一个提供数据库连接的类callableStmt = conn.prepareCall(sql);
// 执行存储过程ResultSet rs = callableStmt.executeQuery();
// 处理结果集while (rs.next()) {System.out.println("student_id:" + rs.getInt("student_id") + "\t"+ "student_name:" + rs.getString("student_name") + "\t"+ "student_age:" + rs.getInt("student_age") + "\t"+ "student_tele:" + rs.getString("student_tele"));}} catch (SQLException e) {e.printStackTrace();} finally {try {if (callableStmt != null) callableStmt.close();if (conn != null) conn.close();} catch (SQLException e) {e.printStackTrace();}}}
static String getUserInput() {Scanner scanner = new Scanner(System.in);System.out.print("Enter student name: ");return scanner.nextLine();}
}
5.2 MyBatis框架介绍
5.2.1 MyBatis了解
MyBatis 是一款优秀的持久层框架,它支持定制化 SQL、存储过程以及高级映射。MyBatis 避免 了几
乎所有的 JDBC 代码和手动设置参数以及获取结果集。MyBatis 可以使用简单的 XML 或注 解来配置
和映射原生类型、接口和 Java 的 POJO(Plain Old Java Objects,普通老式 Java 对 象)为数据库
中的记录。
官方教程:https://mybatis.org/mybatis-3/zh/getting-started.htm
5.2.2 MyBatis基本使用--基于xml实现
实体类Student 各个参数与数据库中目标表的列名一一对应,包括参数名、参数类型

Dao接口文件:
package mybatis.dao;
import mybatis.pojo.Student;
public interface StudentDao {
public Student selectStudent(@Param("name")String name);
}
Mapper xml SQL语句映射文件 :
<?xml version="1.0" encoding="UTF-8" ?>
<!DOCTYPE mapper PUBLIC "-//mybatis.org//DTD Mapper 3.0//EN""http://mybatis.org/dtd/mybatis-3-mapper.dtd">
<!-- 这是一个MyBatis的Mapper文件,定义了与StudentDao接口相关的SQL映射 -->
<mapper namespace="mybatis.dao.StudentDao"><!-- 定义一个名为selectStudent的查询语句,用于从student_table表中查询学生信息 --> <!-- resultType指定了查询结果的Java类型,即mybatis.pojo.Student --> <select id="selectStudent" resultType="mybatis.pojo.Student">select * from student_table where student_name = #{name}<!-- #{name}是一个参数占位符,用于动态传入学生名称进行查询 --> </select><!-- 这里可以添加更多的SQL映射语句,例如插入、更新、删除等 -->
</mapper>
MyBatis xml 配置文件:
<?xml version="1.0" encoding="UTF-8"?> <!DOCTYPE configurationPUBLIC "-//mybatis.org//DTD Config 3.0//EN""http://mybatis.org/dtd/mybatis-3-config.dtd"> <configuration> <!-- <properties resource="config.properties"/>--><environments default="development"><environment id="development"><transactionManager type="JDBC" /><dataSource type="POOLED"><property name="driver" value="com.mysql.jdbc.Driver" /><property name="url" value="jdbc:mysql://localhost:3306/Demo?useSSL=false" /><property name="username" value="root" /><property name="password" value="root" /></dataSource></environment></environments><mappers><mapper resource="mybatis/StudentMapper.xml"/></mappers> </configuration>
事务管理器(transactionManager)
• 数据源(dataSource)类型有三种:
UNPOOLED:这个数据源的实现只是每次被请求时打开和关闭连接。有点慢,但对那些数据库 连接可用性要求不高的简单应用程序来说,是一个很好的选择。 POOLED:这种数据源的实现利用“池”的概念将 JDBC 连接对象组织起来,避免了创建新的 连接实例时所必需的初始化和认证时间。
JNDI:这个数据源的实现是为了能在如 EJB 或应用服务器这类容器中使用,容器可以集中或在 外部配置数据源,然后放置一个 JNDI 上下文的引用。
测试类
//1. 读取配置文件
String resource = "mybatis/mybatis-config.xml";
InputStream inputStream = Resources.getResourceAsStream(resource);
//2. 创建SqlSessionFactory工厂
SqlSessionFactory sqlSessionFactory = new
SqlSessionFactoryBuilder().build(inputStream);
//3. 使用SqlSessionFactory工厂生产SqlSession对象
SqlSession session = sqlSessionFactory.openSession();
try {
//4. 使用SqlSession创建Dao接口的代理对象
StudentDao studentMapper = session.getMapper(StudentDao.class);
//5. 使用代理对象执行方法
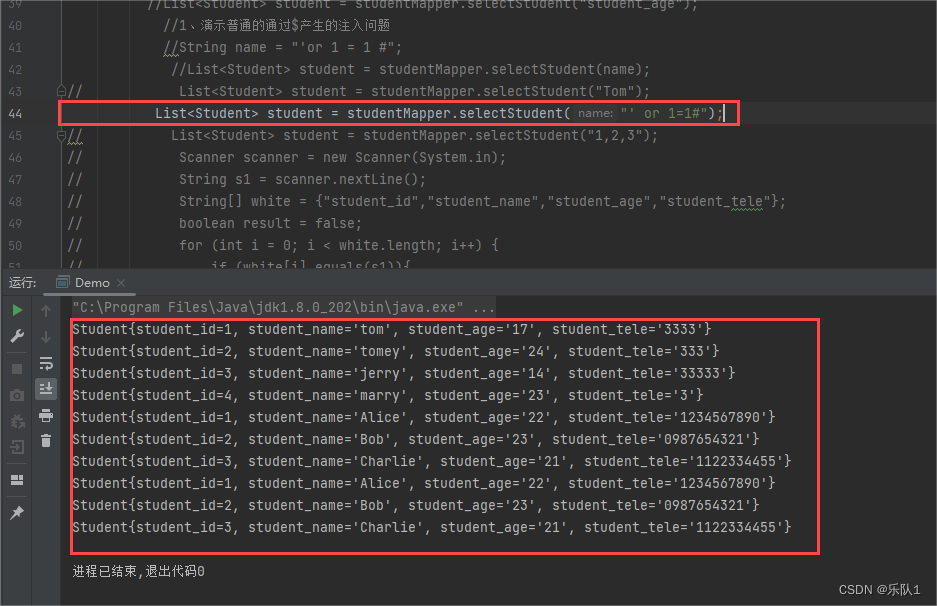
Student student = studentMapper.selectStudent("tom");
System.out.println(student);
} finally {
session.close();
inputStream.close();
}
5.3 MyBatis中注入问题
5.3.1 动态SQL
动态 SQL 是 mybatis 的主要特性之一,在 mapper 中定义的参数传到 xml 中之后,在查询之前
mybatis 会对其进行动态解析。 Mybatis框架中,接受用户参数有两种方式:
通过${param}方式
通过#{param}方式
#{ }会自动传入值加上单引号,而${ }不会。
例如:
<?xml version="1.0" encoding="UTF-8" ?>
<!DOCTYPE mapper
PUBLIC "-//mybatis.org//DTD Mapper 3.0//EN"
"http://mybatis.org/dtd/mybatis-3-mapper.dtd">
<mapper namespace="mybatis.dao.StudentDao">
<select id="selectStudent" resultType="mybatis.pojo.Student">
select * from student_table where student_name = #{name}
</select>
</mapper>
传入name为"tom”

实际提交的SQL为: select * from student_table where student_name = 'tom'
例如:
<?xml version="1.0" encoding="UTF-8" ?>
<!DOCTYPE mapper
PUBLIC "-//mybatis.org//DTD Mapper 3.0//EN"
"http://mybatis.org/dtd/mybatis-3-mapper.dtd">
<mapper namespace="mybatis.dao.StudentDao">
<select id="selectStudent" resultType="mybatis.pojo.Student">
select * from student_table where student_name = ${name}
</select>
</mapper>
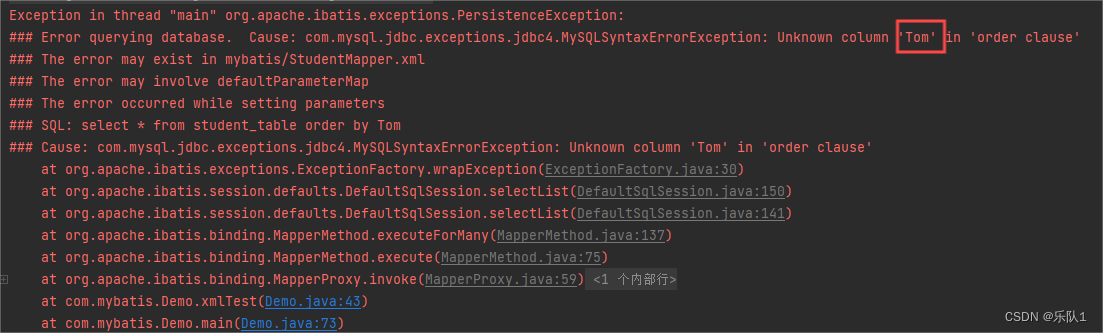
此时提交name为“tom”,会直接报错, 因为SQL语句中没有给name加引号: select * from student_table where student_name = tom
5.3.2 不安全的${ }
修改mapper文件,拼接引号:
<?xml version="1.0" encoding="UTF-8" ?>
<!DOCTYPE mapper
PUBLIC "-//mybatis.org//DTD Mapper 3.0//EN"
"http://mybatis.org/dtd/mybatis-3-mapper.dtd">
<mapper namespace="mybatis.dao.StudentDao">
<select id="selectStudent" resultType="mybatis.pojo.Student">
select * from student_table where student_name = '${name}'
</select>
</mapper>
提交 ' or 1=1 # , SQL语句成为: select * from student_table where student_name = '' or 1=1 #'
SQL注入防御- 使用#{ }
Mybatis 会处理为: select * from student_table where student_name = ?

5.4 java常见注入场景分析
5.4.1 like 模糊匹配
例如:
<?xml version="1.0" encoding="UTF-8" ?>
2 <!DOCTYPE mapper
3 PUBLIC "-//mybatis.org//DTD Mapper 3.0//EN"
4 "http://mybatis.org/dtd/mybatis-3-mapper.dtd">
5 <mapper namespace="mybatis.dao.StudentDao">
6 <select id="selectStudent" resultType="mybatis.pojo.Student">
7 select * from student_table where student_name like '%#{name}%'
8 </select>
9 </mapper>
Mybatis便会处理为: select * from student_table where student_name like '%?%'

常见的解决方案[反例】:
例如:
<?xml version="1.0" encoding="UTF-8" ?>
<!DOCTYPE mapper
PUBLIC "-//mybatis.org//DTD Mapper 3.0//EN"
"http://mybatis.org/dtd/mybatis-3-mapper.dtd">
<mapper namespace="mybatis.dao.StudentDao">
<select id="selectStudent" resultType="mybatis.pojo.Student">
select * from student_table where student_name like '%${name}%'
</select>
</mapper>
拼接为: select * from student_table where student_name like '%tom%

常见的解决方案[正解】:
#{ } 正确的写法
select * from student_table where student_name like concat('%',#{name}, '%')
最终提交的SQL语句是: select * from student_table where student_name like concat('%','tom', '%')
5.4.2 IN语句
例如: dao文件:定义id为String类型
public interface StudentDao {
public List<Student> selectStudent(@Param("id")String id);
}
Mapper文件:对用户输入预编译:
<?xml version="1.0" encoding="UTF-8" ?>
<!DOCTYPE mapper
PUBLIC "-//mybatis.org//DTD Mapper 3.0//EN"
"http://mybatis.org/dtd/mybatis-3-mapper.dtd">
<mapper namespace="mybatis.dao.StudentDao">
<select id="selectStudent" resultType="mybatis.pojo.Student">
select * from student_table where student_id in (#{id})
</select>
</mapper>
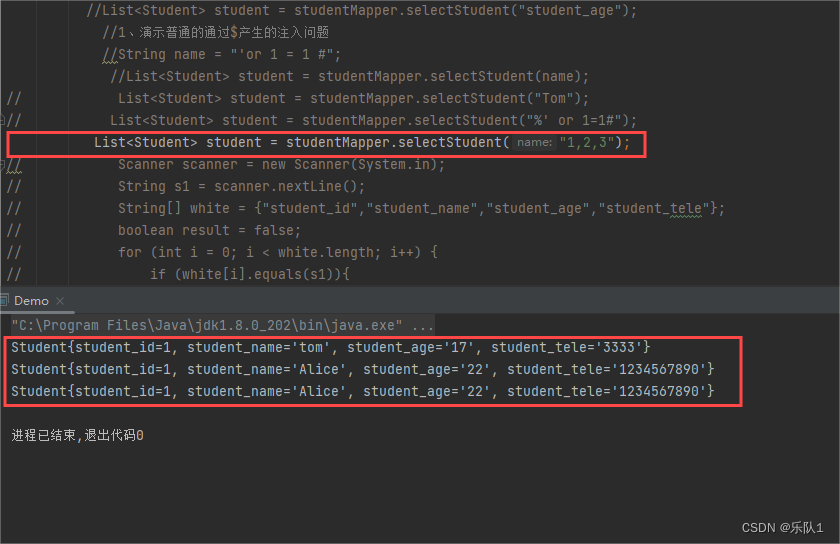
提交 id=“1,2”,实际提交的SQL语句为: select * from student_table where student_id in ('1,2');

修改Mapper文件:改为拼接的方式接收用户输入(${id}) 此时实际提交的SQL语句是:
select * from student_table where student_id in (1,2)
注入测试 :
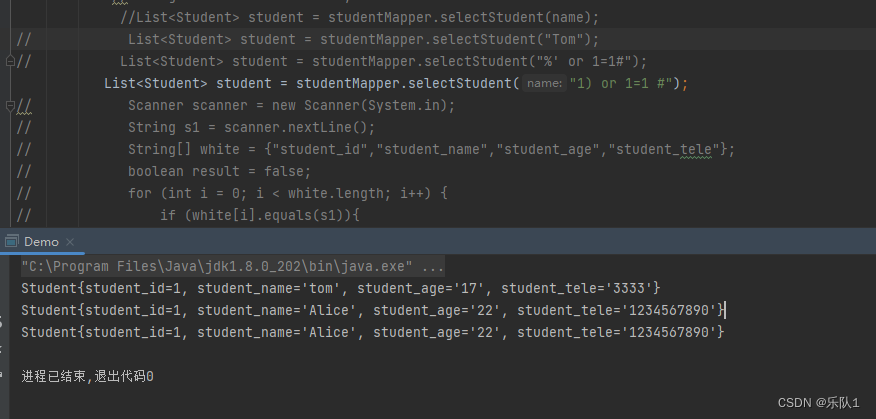
1) or 1=1 # SQL语句拼接成: select * from student_table where student_id in (1) or 1=1#)
解决方案: #{ } 正确的写法
首先要知道IN后的参数中有多少个元素,然后在语句中写入相同个数的占位符?,这一点在直接 使用
PreparedStatement时非常繁琐,需要编写额外的逻辑获取中元素个数后拼接占位符。
SELECT * FROM student_table WHERE id IN (?, ?, ?, ?)
<?xml version="1.0" encoding="UTF-8" ?>
<!DOCTYPE mapper
PUBLIC "-//mybatis.org//DTD Mapper 3.0//EN"
"http://mybatis.org/dtd/mybatis-3-mapper.dtd">
<mapper namespace="mybatis.dao.StudentDao">
<select id="selectStudent" resultType="mybatis.pojo.Student">
select * from student_table where student_id in
<foreach collection="list" item="id" index="index" open="(" close=")" separator=",">
#{id}
</foreach>
</select></mapper>
dao文件:
public interface StudentDao {
public List selectStudent(@Param("list")List list);
}
传入值为1和2的list变量,实际提交的SQL语句:
select * from student_table where student_id in ('1','2'); 顺利得到id为1和2的数据行。

5.4.3 order by语句
凡是字符串但又不能加引号的位置都不能预编译参数化,这种场景不仅order by,还有group by。执行SQL语句:select * from student_table order by student_age; 数据库表按照student_age列进行默认升序排序 Ø执行SQL语句: select * from student_table order by 'student_age'; 数据库表原样输出,没有任何排序,因为 order by 后跟一个字符串,为常量列排序,而常量列 所有值都相等,所以也就不会排序 。
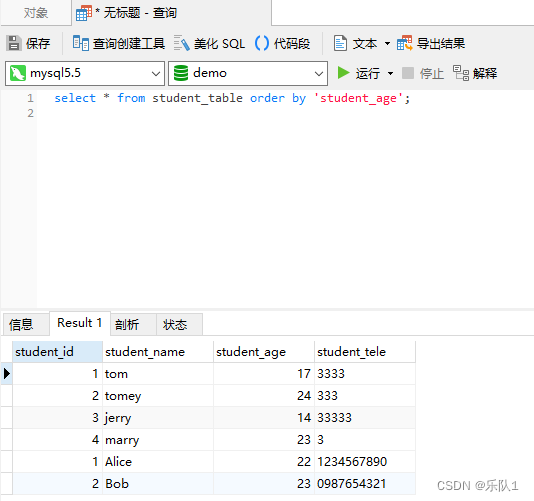
例如: Mapper文件中定义SQL语句为 select * from student_table order by #{name} 提 name=student_age,因为#{ }会对用户提交的数据自动添加单引号,所以这里实际提交的 SQL语句为:
select * from student_table order by 'student_age'

当我们替换为${ },即SQL语句为: select * from student_table order by ${name} 提交 name=student_age,则实际提交的SQL语句如下,是没有添加单引号的: select * from student_table order by student_age 如愿按 student_age 字段执行排序 .

注入测试
if(1=1,student_age,student_tele) 实际提交的SQL语句为:
select * from student_table order by if(1=1,student_age,student_tele)
说明: order by 中使用数字代替列名是不行的,因为if语句返回的是字符类型,不是整型 即不能替换成 if(1=1,3,4)
SQL语句为: select * from student_table order by if(1=1,3,4)
防御方案
这种场景下,通常采用白名单,只开放有限集合,使用间接对象引用,如果传来的参数不在白名单列表中,直接返回错误即可。 例如: 设置一个字段/表名数组,仅允许用户传入索引值。这样保证传入的字段或者表名都在白名单里面。
5.4.4 group by语句
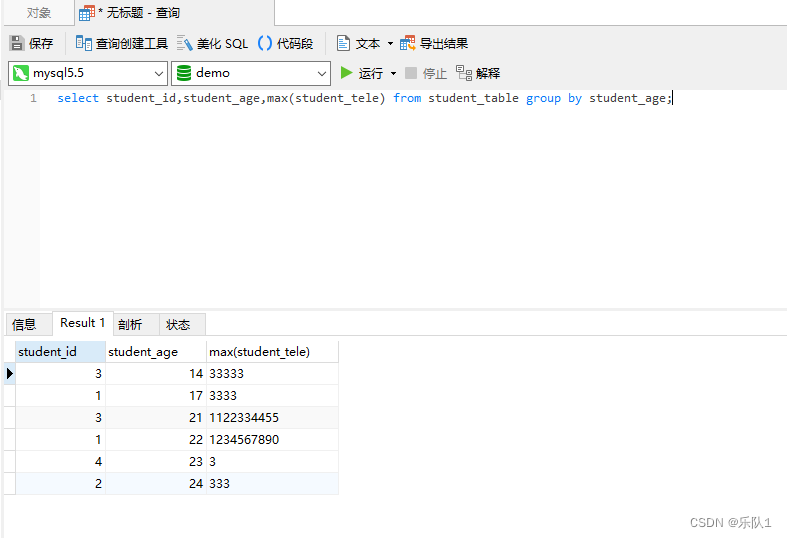
例如: mapper文件中SQL语句:
select student_id,student_age,max(student_tele) from student_table group by #{name}
dao文件:
public interface StudentDao {
public List<Student> selectStudent(@Param("name")String name);
}
传入name= “student_age”,提交的SQL语句为:
select student_id,student_age,max(student_tele) from student_table group by 'student_age' 相当于常
量列,无法按指定列聚合并输出。
当我们替换为${ },即mapper文件中SQL语句为:
select student_id,student_age,max(student_tele) from student_table group by ${name}
传入name=“student_age”,提交的SQL语句为:
select student_id,student_age,max(student_tele) from student_table group by student_age。
这种场景下解决方案与order by场景一样。
6.4.5 总结
易产生SQL注入漏洞的场景有:
-
Like 模糊查询: Select * from student where name like ‘%${name}%’
-
IN 查询: Select * from news where id in (${id})
-
order by、group by 查询: select * from studentwhere id order by ${id}
6.5 漏洞审计技巧和思路
1、需要关注的点:来自于前端的参数且用户可控且未安全处理后拼接到SQL中执行
2、发生场景:(1)在jdbc技术中直接使用“+”拼接 (2)在mybatis中使用$符号拼接 (3) 在hibernate中使用+
需要特别注意一下将从前端获取到的值作为数据sql语句执行的字段名称,而不仅仅是字段的value
String id = requrst.getParmtmter("id")
(1)不常见的sql注入表现形式id = " id = 1",select from user where + id 拼接之后 select * from user where id = 1;
假如id被黑客篡改,id = ‘ ,会导致注入风险(*)
(2)常见的sql注入表现形式:select * from user where + id1 = $id;
解决方案:(1)对于必须从前端获取的,梳理一份白名单【key,value】,从前端获得key,通过key从白名单中找到对应的value,将value拼接到sql中。
map = {id:id,id2:id,id3:id,id4:id,id5:id,id6:id}
Strig id = requrst.getParmtmter("id")
假如用户在此位置上,注入了id="id ’",发现id‘不在白名单的范围内,导致无法继续执行sql语句。
(4)因程序员有一定的安全意识,项目中直接拼接比较少,但是在in、like、order by、gruop by等关键字如何直接使用#等预编译处理会报错,所以才不得以使用了拼接,成为了注入的高发点。
3、通过前端页面,代码生成(SQL注入高频爆发点)功能疑似存在SQL注入
4、定位到后端分析相关SQL的执行过程
关于白洁提出的针对order by、group by 白名单修复意见的说明:
1、正常其后应该加的是字段、是因为第一这个字段来自于前端,第二使用了拼接、第三参数可控
2、如果使用#满足不了功能或者是报错,所以程序员不得以使用了拼接
3、允许使用了拼接,但是需要通过白名单修复
(1)一般情况下,传的字段并且固定,允许前来的参数,但是不能直接拼接。
(2)需要在后端匹配与其对应的value,用前端的参数作为key匹配value,最后将value拼接到参数中
Strting name = request.getParemeter("name");
String value = map.getKey("name");
String sql = select * from user order by value;
假如,黑客在前端注入了sql脚本,会导致该Key找不到value,那就是说没办法发生注入了,直接返回给前端输入不合法。
这篇关于java之sql注入审计的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





