本文主要是介绍使用gradio搭建服务(二),希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
使用gradio搭建逐步执行的服务
# coding:utf-8
import os
from time import time
os.environ["CUDA_VISIBLE_DEVICES"] = '1'
import torch
from PIL import Image,ImageFont,ImageDraw
import requestsimport gradio as gr
from infer_llvm import infer_llvm
from call_openai import openai_reply
from llm import llmfrom create_app import conf
from clife_svc.libs.log import klogger as logger
# translator = Translator(to_lang="zh")
os.environ['CUDA_LAUNCH_BLOCKING'] = '1'
USE_GPU = Truewebui_title = '''毕业相册demo'''def generate_text(image,multimodal_input):generated_text = infer_llvm(multimodal_input, image)return generated_textdef generate_llm(generated_text,radio,llm_input):llm_prompt = f'{generated_text},{llm_input}'print('llm_prompt',llm_prompt)if radio == 'chatgpt-3.5':llm_output = openai_reply(llm_prompt)elif radio == '星火大模型':llm_output = llm(llm_prompt)line = f'大模型:{radio} 提示词:{llm_prompt} 多模态输出结果:{llm_output}'logger.info(line)return llm_outputwith gr.Blocks() as demo:gr.HTML(F"""<h1 align="center">{webui_title}</h1>""") ## 9with gr.Row():with gr.Column():image = gr.Image(label='幼儿照片') ## 1llvm_prompt = gr.Textbox(label='多模态提示词(请用英文,可以不填写)') ## 2out_llvm = gr.Textbox(label='多模态输出') ##3_button1 = gr.Button(value='步骤1:开始生成图像描述', scale=1) ## 4with gr.Column():radio = gr.Radio(choices=["chatgpt-3.5", "星火大模型"], label="选择一个大模型",value='chatgpt-3.5') ## 5llm_prompt = gr.Textbox(label='大模型提示词(请用中文,必填)') ## 6out_llm = gr.Textbox(label='成长相册输出') ## 7 _button2 = gr.Button(value='步骤2:开始成长相册描述', scale=1) #8_button1.click(fn=generate_text,inputs=[image, llvm_prompt],outputs=out_llvm)_button2.click(fn=generate_llm,inputs=[out_llvm,radio,llm_prompt],outputs=out_llm)
demo.launch(server_name="0.0.0.0")
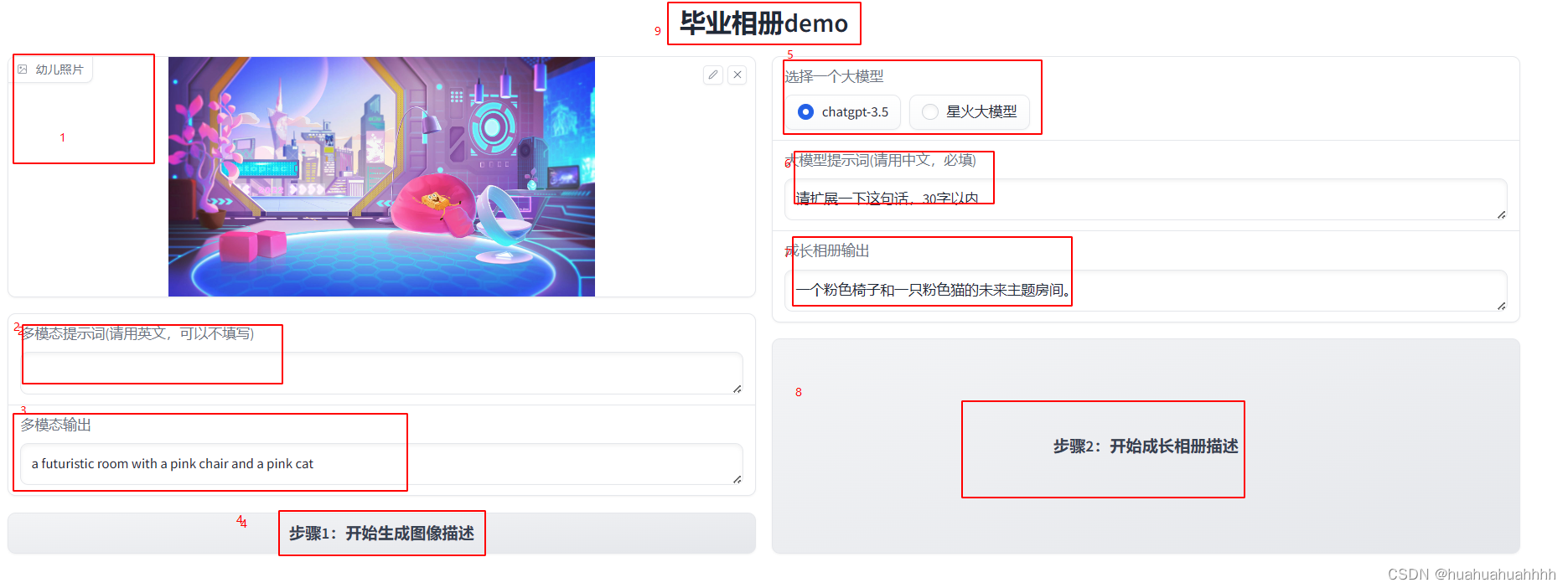
这里通过设置两个按钮,_button2的输入中包含_button1的输出,来实现分布执行
这篇关于使用gradio搭建服务(二)的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!




