本文主要是介绍记录一个flink跑kafka connector遇到的问题,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
【报错】
D:\Java\jdk1.8.0_231\bin\java.exe "-javaagent:D:\Program Files\JetBrains\IntelliJ IDEA 2022.2.3\lib\idea_rt.jar=56647:D:\Program Files\JetBrains\IntelliJ IDEA 2022.2.3\bin" -Dfile.encoding=UTF-8 -classpath D:\Java\jdk1.8.0_231\jre\lib\charsets.jar;D:\Java\jdk1.8.0_231\jre\lib\deploy.jar;D:\Java\
Exception in thread "main" java.lang.RuntimeException: Failed to fetch next result
Caused by: java.util.concurrent.ExecutionException:
Caused by: org.apache.flink.runtime.client.JobExecutionException: Job execution failed.
Caused by: org.apache.flink.runtime.JobException: Recovery is suppressed by NoRestartBackoffTimeStrategy
Caused by: java.io.IOException: Failed to deserialize consumer record due to
Caused by: java.io.IOException: Failed to deserialize consumer record ConsumerRecord(topic
Caused by: java.lang.RuntimeException: Row length mismatch. 3 fields expected but was 2.进程已结束,退出代码1
Job execution failed.
Recovery is suppressed by NoRestartBackoffTimeStrategy
Failed to deserialize consumer record due to
Failed to deserialize consumer record ConsumerRecord(topic = topicA, partition = 1, leaderEpoch = 2, offset = 4, CreateTime = 1718247641082, serialized key size = -1, serialized value size = 7, headers = RecordHeaders(headers = [], isReadOnly = false), key = null, value = [B@3ecd79e3).
Failed to deserialize CSV row '1,dahua'.
Row length mismatch. 3 fields expected but was 2.
上面這幾個是bug中我找的关于问题的关键点
【解决】
将报错粘到网上,说是我分区数据坏了,kafka解析不了,所以把对应的这个topicA删除,重建一次,再往里写数据就好了
删除对应主题: bin/kafka-topics.sh --bootstrap-server hadoop102:9092 --delete --topic
重建对应主题:bin/kaftopics.sh --bootstrap-server hadoop102:9092 --create --partitions 1 --replication-factor 2 --topic topicA
启个对应主题的生产者:bin/kafka-consolroducer.sh --bootstrap-server hadoop102:9092 --topic topicA
往里写数据(先保证对应的这个java程序你已经启动了):
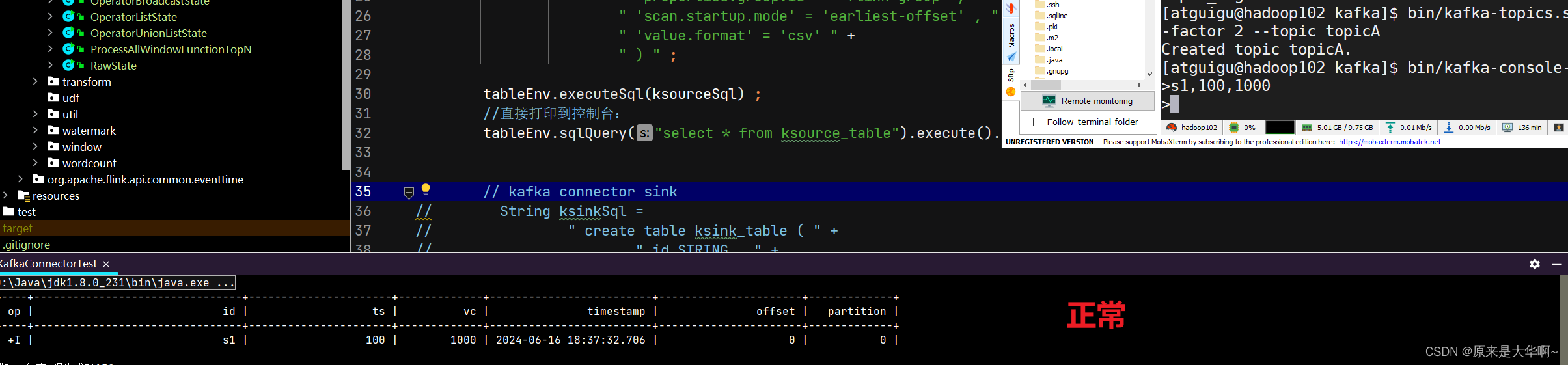
这篇关于记录一个flink跑kafka connector遇到的问题的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!









