本文主要是介绍mysql:简单理解mysql mvcc的可重复读,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
# 原理
假设有这样的sql
begin
select(或update、insert、delete) ...
commit
- 当执行【begin】的时候,标记有一个新事务要开始,但是事务还没有真正开始,事务id还没有产生
- 当执行事务里面的第一个sql语句时(这里是select),该事务才真正开始,这时事务id才产生。
- 后面所有的【快照读】查询都会基于这个事务id进行数据的查询,【其它事务id】大于【本事务id】的数据不会被查出来
# 实验与证明
假设有这样的sql语句
select now(); begin;select id, name from chz_user where id = 1;
select * from information_schema.INNODB_TRX;commit;
先执行:
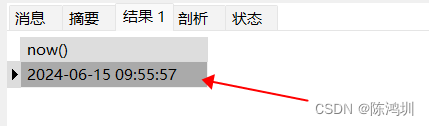
select now();
begin;
执行这两句的目的是先查看当前时间,可以看到当前时间【09:55:57】,然后标记开始一个新的事务。
注意【begin】差不多也是这个时间被执行的。
等十几秒左右,接着执行:
select id, name from chz_user where id = 1;
select * from information_schema.INNODB_TRX;
之所以在前面放一句【select】是因为不执行任何语句的话新的事务是不会开始的,这里执行【select】之后事务才真正开始,事务id才真正产生。
然后下一句查询【information_schema.INNODB_TRX】就是为了查询【当前事务id】和【事务开始时间】,结果如下:
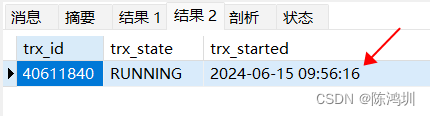
可以看出事务的开始时间是比执行【begin】的时候晚了【19秒】的
# 参考资料
https://pdai.tech/md/db/sql-mysql/sql-mysql-mvcc.html
这篇关于mysql:简单理解mysql mvcc的可重复读的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!







