本文主要是介绍论文学习day01,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
1.自我反思的检索增强生成(SELF-RAG)
1.文章出处:
Chan, C., Xu, C., Yuan, R., Luo, H., Xue, W., Guo, Y., & Fu, J. (2024). RQ-RAG: Learning to Refine Queries for Retrieval Augmented Generation. ArXiv, abs/2404.00610.
2.摘要:
尽管具有显著的能力,大型语言模型(LLMs)往往会因完全依赖其封装的参数性知识而产生包含事实错误的回应。检索增强生成(RAG)是一种临时方法,它通过检索相关知识来降低这类问题。然而,无差别地检索和合并固定数量的检索段落,不考虑检索是否必要或段落是否相关,会降低LM的多功能性,或导致生成无用的回应。我们介绍了一种名为“自我反思的检索增强生成”(SELF-RAG)的新框架,通过检索和自我反思来增强LM的质量和事实准确性。我们的框架训练一个单一的任意LM,**在需要时自适应地检索段落,并使用称为反思标记的特殊标记生成和反思检索段落及其自己的生成。生成反思标记使LM在推理阶段可控,使其能够根据不同的任务需求来调整其行为。**实验表明,SELF-RAG(7B和13B参数)在各种任务上显著优于最先进的LLMs和检索增强模型。具体而言,SELF-RAG在开放域QA、推理和事实验证任务上优于ChatGPT和检索增强的Llama2-chat,在改进长篇生成中的事实性和引用准确性方面相对于这些模型显示出明显的增益。
总结: 传统RAG没有考虑到需要检索内容和所检索段落的关系,因此降低了响应能力,该文章提出了一个方法:“自我反思的检索以此增强RAG检索能力”,主要是通过token标记检索的段落以及对应的生成,通过这个token使其LM在推理可控,方便调整行为。
3.Introduction:
第一段:现代语言模型在处理事实错误方面仍然存在困难(Mallen等,2023年;Min等,2023年),尽管它们的模型规模和数据规模不断增大(Ouyang等,2022年)。检索增强生成(RAG)方法(见图1左侧;Lewis等,2020年;Guu等,2020年)通过增加LLMs的输入相关检索段落,减少知识密集任务中的事实错误(Ram等,2023年;Asai等,2023a年)。然而,由于这些方法不加选择地检索段落,可能会阻碍LLMs的多功能性,或者引入不必要或离题的段落,导致生成质量低【1error】(Shi等,2023年)。此外,由于模型没有显式训练来利用和遵循提供的段落中的事实,生成结果也不能保证与检索的相关段落一致【2error】(Gao等,2023年)。本项工作引入了自我反思的检索增强生成(SELF-RAG),通过按需检索和自我反思来提高LLM的生成质量,包括事实准确性,而不损害其多功能性。我们以端到端的方式训练一个任意的语言模型,在给定任务输入的情况下,通过生成任务输出和临时的特殊标记(即反思标记)来学习反思自己的生成过程。反思标记被分类为检索和批评标记【way】,以指示检索的需求及其生成的质量(见图1右侧)。具体而言,给定一个输入提示和先前的生成结果,SELF-RAG首先确定是否在继续生成过程中增加检索到的段落是否有帮助【method】。如果有帮助,它会输出一个检索标记,以便根据需要调用一个检索模型(第1步)。接着,SELF-RAG同时处理多个检索到的段落,评估它们的相关性,然后生成相应的任务输出(第2步)。然后,它生成批评标记来批评自己的输出,并选择最佳输出(第3步),评估其准确性和整体质量【method】。这个过程与传统的RAG有所不同(见图1左侧)。
【总结:利用反思标记,分为检索标记和批评标记;检索标记-判断检索的片段是否跟生成内容相关;批评标记-批评自己的输出,选择最佳输出(应该有个并行,选择最佳输出)】
流程图如下所示:
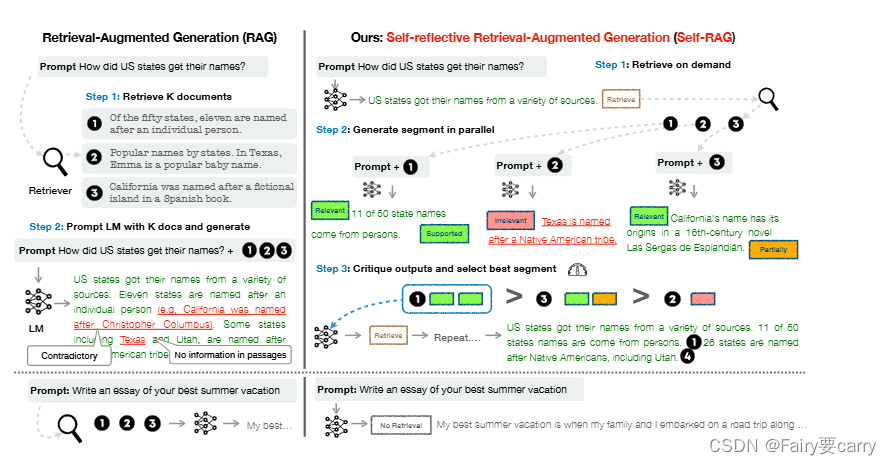
传统的RAG方法(图中左侧): 传统的RAG方法首先从数据库中检索相关文档(步骤1),然后使用检索到的文档和初始提示作为输入,通过语言模型生成文本(步骤2)。这个方法有助于减少知识密集任务中的事实错误,但可能会引入与任务无关或不必要的内容,影响生成的质量。此外,生成的内容不一定与检索到的相关文档保持一致,因为模型并未明确训练以利用和遵循提供的文档中的事实。
自反射检索增强生成(SELF-RAG)方法(图中右侧): SELF-RAG方法首先根据输入提示和前序生成内容决定是否需要通过检索增强继续生成内容。如果需要,它会输出一个检索令牌,调用检索器模型按需检索(步骤1)。然后,SELF-RAG同时处理多个检索到的文档,评估它们的相关性,然后生成相应的任务输出(步骤2)。接下来,它生成批评令牌来批评自己的输出,并选择最佳输出(步骤3),以提高事实性和整体质量。【图中1和3与输入相关,根据批评令牌得知1的相关性最高】
第二段:“SELF-RAG是一种技术,可以在生成文档时始终检索固定数量的文档,而不考虑检索的必要性【speciality1】(例如,底部的示例中并不需要事实知识),并且不会二次访问生成质量。此外,SELF-RAG为每个段落提供引用,同时通过自我评估判断输出是否由文段支持,从而使事实验证变得更加容易【speciality2】。SELF-RAG通过统一将反思标记訓练任意语言模型生成文本,使其成为扩展模型词汇表中的下一个标记预测【speciality3】。我们将生成器语言模型训练在各种文本和检索段落的交错集合上,这些文本中插入的反思标记灵感来自于强化学习中使用的奖励模型(Ziegler 等, 2019; Ouyang 等,2022),由经过训练的评论模型线下插入原始语料库。这消除了在训练期间托管评论模型的需要,从而减少了开销。评论模型在一定程度上是通过促使专有语言模型(即 GPT-4;OpenAI 2023)收集的输入、输出和相应的反思标记数据集进行监督的。虽然我们受到使用控制标记来开始和引导文本生成的研究的启发(Lu 等,2022; Keskar 等,2019),但我们训练的语言模型在生成每个段落后使用评价标记来评估自己的预测输出,作为生成输出的一个组成部分。SELF-RAG进一步实现了一个可定制的解码算法,以满足硬性或软性约束,这些约束由反思标记的预测定义。特别是,我们的推理算法使我们能够(1)灵活调整不同下游应用的检索频率,以及(2)通过使用反思标记通过基于段的加权线性总和的分数,定制模型行为到用户偏好【speciality4】。六项任务的实证结果,包括推理和长篇生成,表明SELF-RAG明显优于具有更多参数和被广泛采用的RAG方法的预训练和指导调节的LLMs,以及具有更高引用准确性的方法。特别是,在四项任务中,SELF-RAG优于增强检索的ChatGPT,Llama2-chat(Touvron 等,2023)和Alpaca(Dubois 等,2023)在所有任务上的表现统计学分析表明,通过反思标记进行训练和推理可以在整体表现提升以及测试时模型自定义方面(例如,平衡引用准确性和完整性之间的权衡)取得显着效果。”
【speciality1】无需事实的生成与自我评估: SELF-RAG能够在生成文本时根据需要检索信息,而不是无论何时都检索固定数量的文档。这意味着,即使某些任务(如创造性写作)可能不需要事实支持,它也能适应并避免不必要的检索,从而提高效率。
例如,如果任务是编写一首诗,SELF-RAG将识别出这一任务不需要事实性背景,因此不会执行不必要的文档检索。【我的想法是:需要决策模型进行判断】
【speciality2】段落引用和自我评估: SELF-RAG为每个生成的段落提供引用,并通过自我评估来判断输出是否由支持的文段(即检索到的文档)支撑。这意味着,当模型生成一个段落时,它会同时标识出这段内容的信息来源,并评估这些信息与生成内容的相关性和支持程度。这样做使得事实验证更加容易,因为每部分内容都有明确的来源标记,用户或系统可以快速验证信息的准确性和可靠性。
自我评估功能使得SELF-RAG系统能够在生成过程中实时检查和评估生成内容的质量和相关性。这包括对生成文本的准确性、完整性和符合任务要求的程度进行评估。
【speciality3】反思标记的使用: SELF-RAG通过插入“反思标记”(reflection tokens)来训练语言模型,这些标记是基于强化学习中使用的奖励模型灵感设计的。在生成文本时,这些标记帮助模型评估和调整其生成策略,提高生成内容的相关性和质量。
反思标记是自我评估过程的一部分,它们被设计为在生成文本中标记出需要特别注意或可能需要修改的部分。这些标记帮助模型在生成过程中进行自我反思,评估其输出的质量,并据此调整未来的生成策略。反思标记的存在使得模型能够识别和响应生成过程中出现的问题,从而优化输出内容。
【speciality4】定制解码算法: SELF-RAG采用了一个可定制的解码算法,允许根据预测的反思标记来灵活调整检索频率和模型行为。这意味着可以根据不同的应用需求定制模型的行为。
根据反思标记对生成文本的评估,进行检索频率的调整以保证信息的准确性。
3.我的感受:
根据introduction的过程可以知道,作者利用并行的方式得到与输入提示词相关的prompt给到llm大模型,然后对得到的响应进行批判进而得到最准确的回答。这样精准性是毋庸置疑的,但是会不会丢掉其他相关的部分呢?比如图中3部分也有和问题相关的内容,难道它就应该丢弃吗?我们能不能将1和3组合起来,然后利用一个合适的prompt【比如:请帮我把以下几段话结合起来成为一段话:…】,这样是不是可以保证信息的完整性呢?
4.示例:生成关于“气候变化对全球农业的影响”的文章
假设用户请求SELF-RAG生成一篇关于“气候变化对全球农业的影响”的详细分析文章。
- 任务解析:
系统识别出这是一个需要事实支持的信息密集型任务。
- 执行检索:
模型检索相关的科学研究报告、数据和专家文章,例如关于气候模型的预测、作物产量的统计数据等。
- 内容生成与反思标记插入:
使用检索到的信息,模型开始撰写文章,同时插入反思标记来标记那些需要进一步验证或可能需要调整的内容段落。
- 自我评估:
模型评估生成的每个段落,使用反思标记作为指导来检查信息的准确性和论点的合理性。
- 调整与优化:
根据评估结果,模型对文章进行必要的调整,例如增加缺失的统计数据,修改不准确的预测信息。
- 输出最终文本:
最终,模型完成文章的生成,确保文本不仅信息全面,而且论据支持充分,准确性高。
通过这一过程,SELF-RAG能够有效地生成符合高标准的专业文章,满足用户对于高质量、高准确性文本的需求。
这篇关于论文学习day01的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!








