本文主要是介绍【MySQL】聊聊数据库是如何保证数据不丢的,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
对于一个存储系统来说,其中比较关键的核心组件包含,网络、存储模型、持久化、数据结构等。而数据如何保证不丢失,对于不同的存储系统来说,比如Redis采用AOF和RDB的方式进行混合使用,而MySQL采用日志进行保证。也就是redo\undo\bin log。本篇就聊聊数据库是如何进行不丢失的。
总体流程
对于数据不丢失,其实就是针对更新语句(update\delete\insert)的操作流程,其中主要靠redo log保证恢复事务,undo log 回滚事务。
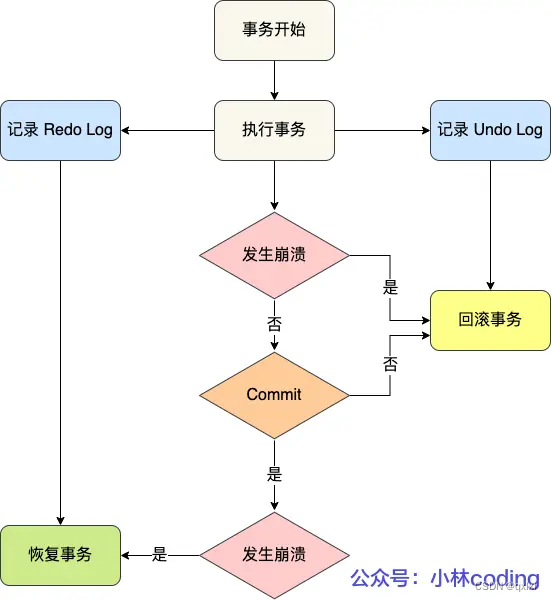
bin log的写入机制
binlog在事务执行过程中,把日志写到binlog cache中,等事务提交的时候,再把binlog cache写到binlog中。而操作的维度就是一个事务。
系统给binlog cache分配了一片内存,每个线程一个。binlog_cache_size 控制单个线程内binlog cache所占内存的大小,超过之后,就暂存到磁盘中。
事务提交的时候,执行器把binlog cache里的完整事务写入到binlog中。并清空binlog cache
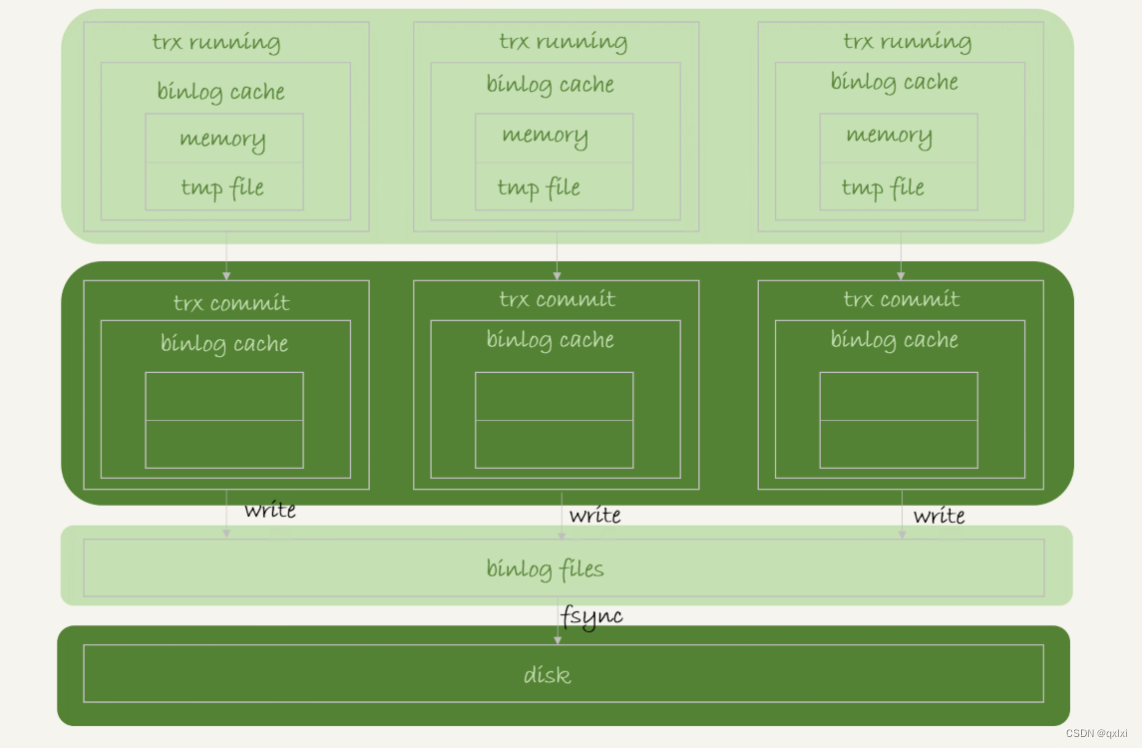
每个线程都有自己的binlog cache,但是对于bin log来说共用的。
- write:把日志文件binlog cache写入到binlog files中,也就是paeg cache中,因为是内存操作,所以速度比较快。
- fsync: 将数据从page cache写入到本次磁盘中,这个比较费时,所以可能是影响IOPS的一个因素。
决定执行write和fsync由sync_binlog参数决定。
- sync_binlog=0 每次提交事务只write,不fsync
- sync_binlog=1 提交事务的时候都fsync
- sync_binlog>1 提交事务的只write ,但是积累到N个事务才fsync。其实就是批处理。
其实就是在性能和可用性之间进行权衡,在时机中,一般都是设置成100-1000中的某个值。但是当系统发生宕机的时候,可能丢失N个事务的binlog 日志。
redo log的写入机制
redo log是先写入redo log buffer-> page cache -> 磁盘

从而就对应三种写入状态
写入时机
- 存储在redo log buffer中,其实就是MySQL进程内存中。红色部分
- 写到磁盘write,但是没有持久化(fsync) 文件系统的page cache里面,黄色部分
- 持久化到磁盘里,就是hard disk,绿色部分。
InnoDB 提供了 innodb_flush_log_at_trx_commit 参数,控制写入策略。
- 0 : 事务提交时,只把redo log留在redo log buffer中。
- 1 : 事务提交时,redo log 持久化到磁盘
- 2 : 事务提交时,redo log 写到page cache中。
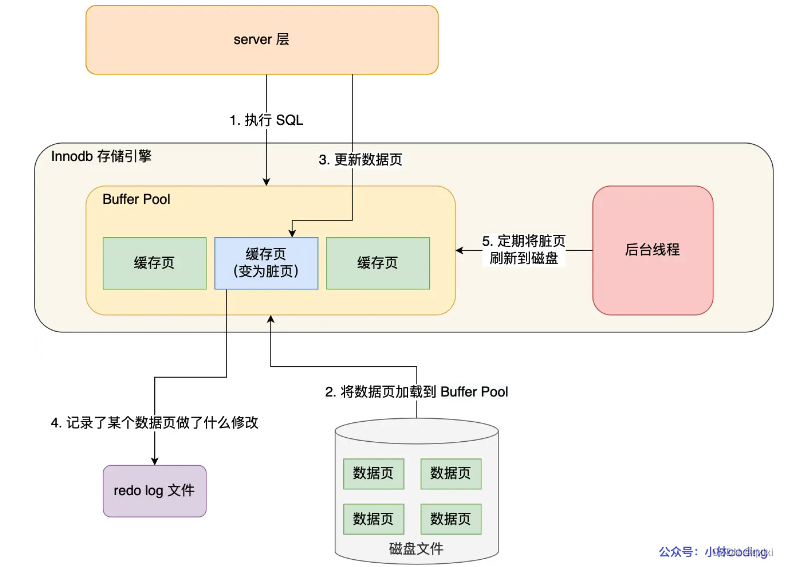
如图5就是将定时将脏页进行刷新操作。而对于bin log来说,是依靠每次事务提交的时候进行刷盘。
InnoDB由一个后台线程,间隔1S把redo log buffer中的日志,调用write写到文件系统的page cache,调用fscyn持久化到磁盘中。
所以这里可能存在一种情况,可能一个事务执行过程中,也可能被定时后台线程持久化到磁盘中。
刷盘时机
- 定时1S刷盘操作
- redo log buffer达到
innodb_log_buffer_size一半的空间。只写write - 每次事务提交时都将缓存在 redo log buffer 里的 redo log 直接持久化到磁盘
- mysql正常关闭的时候。
组提交机制(group commit)
日志逻辑序列号 log sequence number LSN 对应redo log的一个个写入点,每次写入长度为length的redo log LSN的值就会加上length。
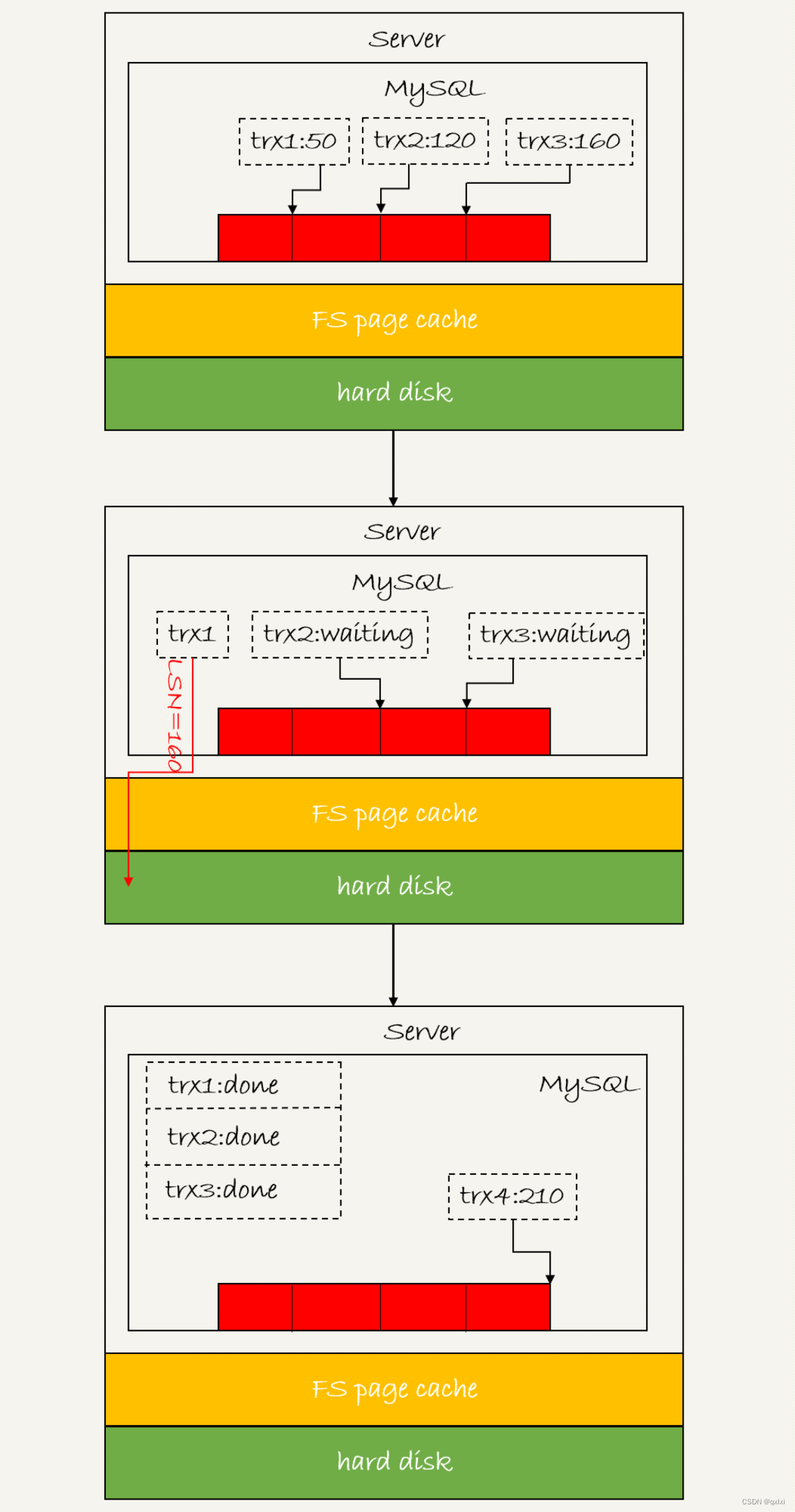
图中有三个事务trx1、trx2、trx3 分别是50、120、160。
当trx1 第一个到达,提交的时候就会把2 3也一起进行提交fsync。所以一组提交的事务越多IOPS的效果越好。其实就是批处理的概念,一次多处理,而不是分批处理。比如批量插入SQL等,Kafka的批处理消息等。
WAL其实就只依赖于两个方面,redo log 和 bin log 都是顺序写,磁盘的顺序写比随机写快,另外一个是组提交,大幅度降低磁盘的IOPS消耗。
这篇关于【MySQL】聊聊数据库是如何保证数据不丢的的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





