本文主要是介绍学习笔记0411----正则三剑客之sed、awk,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
正则三剑客之sed、awk
- 预习内容
- 1.sed 替换指定字符
- 1.1 sed 选项参数
- 1.2 sed 删除字符
- 1.3 sed 替换字符
- 2.awk 工具
- 2.1 awk常见的一些符号作用
- 2.2 awk 条件操作符
- 2.3 awk内置变量
- 2.4 awk的数学运算
- 课后总结
- 1.awk语法结构
- 2.打印某行到某行之间的内容
- 3.sed转换大小写
- 3.1. 把每个单词的第一个小写字母变大写:
- 3.2 把每个单词的最后一个变为大写字母
- 3.3 把所有小写变大写:
- 3.4. 大写变小写:
- 4. sed在某一行最后添加一个数字
- 5.打印1到100行含某个字符串的行
- 6.awk 中使用外部shell变量
- 7. awk 合并一个文件
- 8.把一个文件多行连接成一行
- 9.awk中gsub函数的使用
- 10.awk 截取指定多个域为一行
- 11.过滤两个或多个关键词
- 12. awk用print打印单引号
预习内容
9.4/9.5 sed
9.6/9.7 awk
以下内容为扩展部分,先挑着能看懂的练习练习。
打印某行到某行之间的内容http://ask.apelearn.com/question/559
sed转换大小写 http://ask.apelearn.com/question/7758
sed在某一行最后添加一个数字http://ask.apelearn.com/question/288
删除某行到最后一行 http://ask.apelearn.com/question/213
打印1到100行含某个字符串的行 http://ask.apelearn.com/question/1048
awk 中使用外部shell变量http://ask.apelearn.com/question/199
awk 合并一个文件 http://ask.apelearn.com/question/493
把一个文件多行连接成一行 http://ask.apelearn.com/question/266
awk中gsub函数的使用 http://ask.apelearn.com/question/200
awk 截取指定多个域为一行 http://ask.apelearn.com/question/224
过滤两个或多个关键词 http://ask.apelearn.com/question/198
用awk生成以下结构文件 http://ask.apelearn.com/question/5494
awk用print打印单引号 http://ask.apelearn.com/question/1738
合并两个文件 http://ask.apelearn.com/question/945
awk的BEGIN和END http://blog.51cto.com/151wqooo/1309851
awk的参考教程 http://www.cnblogs.com/emanlee/p/3327576.html
1.sed 替换指定字符
1.1 sed 选项参数
sed命令的选项(option):
-n :只打印模式匹配的行
-e :直接在命令行模式上进行sed动作编辑,此为默认选项
-f :将sed的动作写在一个文件内,用–f filename 执行filename内的sed动作
-r :支持扩展表达式
-i :直接修改文件内容
## 打印出含有root的行 ##
[root@linux-01 ceshi]# sed -n '/root/'p passwd
#Root:x:0:0:root:/root:/bin/bash
operator:x:11:0:operator:/root:/sbin/nologin## 打印出包含r.t的行(点代表匹配一个字符) ##
[root@linux-01 ceshi]# sed -n '/r.t/'p passwd
operator:x:11:0:operator:/root:/sbin/nologin
sshd:x:74:74:Privilege-separated SSH:/var/empty/sshd:/sbin/nologin## 打印出包含r*t的行(*代表匹配n个字符,0个或者多个) ##
[root@linux-01 ceshi]# sed -n '/r*t/'p passwd
#Root:x:0:0:root:/root:/bin/bash
shutdown:x:6:0:shutdown:/sbin:/sbin/shutdown
halt:x:7:0:halt:/sbin:/sbin/halt
operator:x:11:0:operator:/root:/sbin/nologin
ftp:x:14:50:FTP User:/var/ftp:/sbin/nologin
systemd-network:x:192:192:systemd Network Management:/:/sbin/nologin
dbus:x:81:81:System message bus:/:/sbin/nologin
polkitd:x:999:998:User for polkitd:/:/sbin/nologin
sshd:x:74:74:Privilege-separated SSH:/var/empty/sshd:/sbin/nologin
postfix:x:89:89::/var/spool/postfix:/sbin/nologin## 打印出第二行 ##
[root@linux-01 ceshi]# sed -n '2'p passwd
#bin:x:1:1:bin:/bin:/sbin/nologin## 打印出第25行到末尾 ##
[root@linux-01 ceshi]# sed -n '25,$'p passwd
r-o
r5o
r=o
r.o
o111o
oo
user1:x:1003:100::/home/user1:/bin/bash## 打印出包含root的行,把user1的行也打印出来 ##
[root@linux-01 ceshi]# sed -e '/root/'p -e '/user/'p -n passwd
#Root:x:0:0:root:/root:/bin/bash
operator:x:11:0:operator:/root:/sbin/nologin
user1:x:1003:100::/home/user1:/bin/bash
1.2 sed 删除字符
## 删除1到25行的内容,-i直接修改源文件 ##
[root@linux-01 ceshi]# sed -i '1,25'd passwd
[root@linux-01 ceshi]# cat passwd
r5o
r=o
r.o
o111o
oo
user1:x:1003:100::/home/user1:/bin/bash
[root@linux-01 ceshi]#
1.3 sed 替换字符
## 把1到10行中出现的root替换为测试 ##
[root@linux-01 ceshi]# sed '1,10s/root/ceshi/g' passwd
#Root:x:0:0:ceshi:/ceshi:/bin/bash
#bin:x:1:1:bin:/bin:/sbin/nologin
daemon:x:2:2:daemon:/sbin:/sbin/nologin
adm:x:3:4:adm:/var/adm:/sbin/nologin
lp:x:4:7:lp:/var/spool/lpd:/sbin/nologin
sync:x:5:0:sync:/sbin:/bin/sync
shutdown:x:6:0:shutdown:/sbin:/sbin/shutdown
halt:x:7:0:halt:/sbin:/sbin/halt
mail:x:8:12:mail:/var/spool/mail:/sbin/nologin
operator:x:11:0:operator:/ceshi:/sbin/nologin
games:x:12:100:games:/usr/games:/sbin/nologin
ftp:x:14:50:FTP User:/var/ftp:/sbin/nologin
nobody:x:99:99:Nobody:/:/sbin/nologin
systemd-network:x:192:192:systemd Network Management:/:/sbin/nologin
dbus:x:81:81:System message bus:/:/sbin/nologin
polkitd:x:999:998:User for polkitd:/:/sbin/nologin
sshd:x:74:74:Privilege-separated SSH:/var/empty/sshd:/sbin/nologin
postfix:x:89:89::/var/spool/postfix:/sbin/nologin
xihaji:x:1000:1000::/home/xihaji:/bin/bash
xihaji2:x:1001:1001::/home/xihaji2:/bin/bash
readonly:x:1002:1002::/home/readonly:/bin/bash
roooooor
o1o
r?o
r-o
r5o
r=o
r.o
o111o
oo
user1:x:1003:100::/home/user1:/bin/bash## 把1到10行中的ro+(+代表1个或者多个)字符替换为xihaji ##
[root@linux-01 ceshi]# sed -r '1,10s/ro+/xihaji/g' passwd |head
#Root:x:0:0:xihajit:/xihajit:/bin/bash
#bin:x:1:1:bin:/bin:/sbin/nologin
daemon:x:2:2:daemon:/sbin:/sbin/nologin
adm:x:3:4:adm:/var/adm:/sbin/nologin
lp:x:4:7:lp:/var/spool/lpd:/sbin/nologin
sync:x:5:0:sync:/sbin:/bin/sync
shutdown:x:6:0:shutdown:/sbin:/sbin/shutdown
halt:x:7:0:halt:/sbin:/sbin/halt
mail:x:8:12:mail:/var/spool/mail:/sbin/nologin
operator:x:11:0:operator:/xihajit:/sbin/nologin
[root@linux-01 ceshi]# 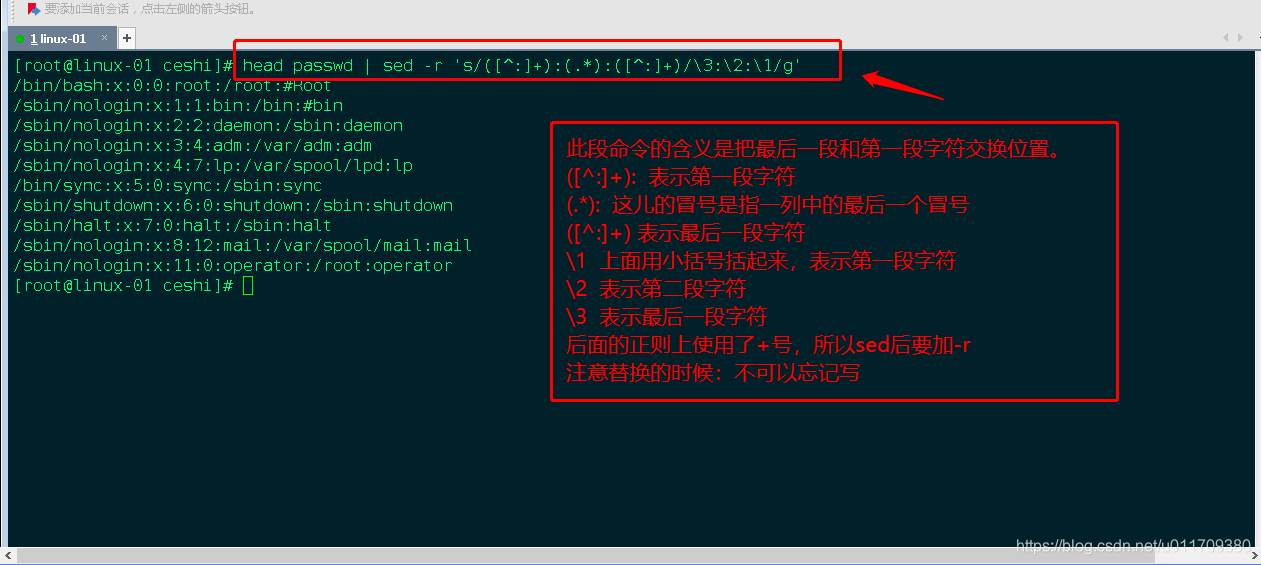
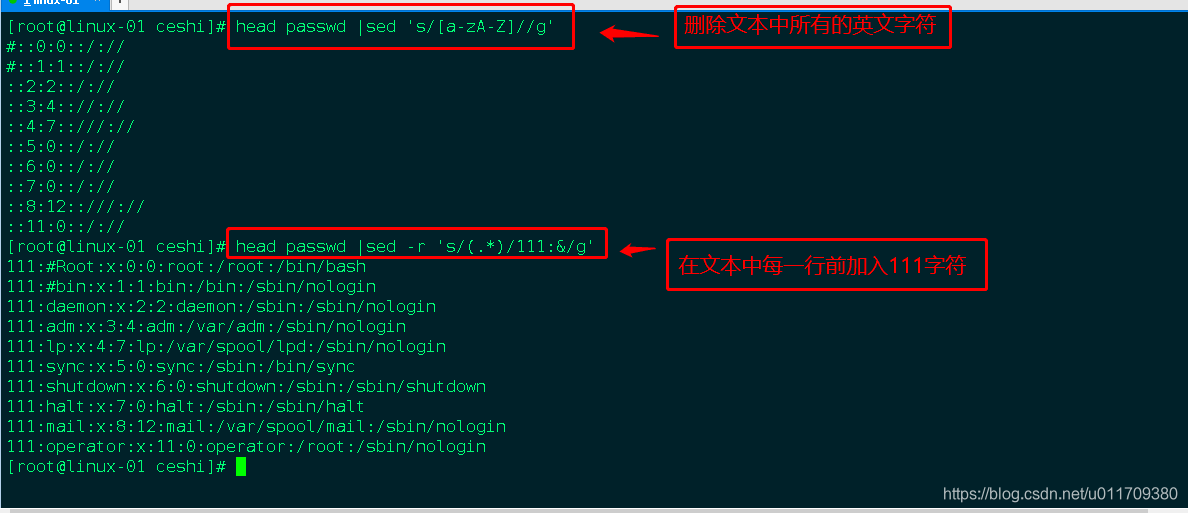
2.awk 工具
awk 需要搞清楚它的语法结构 , awk -F ‘分隔符’ BEGIN{} { (条件) {print在这里}} END{}
2.1 awk常见的一些符号作用
| 符号 | 作用 |
|---|---|
| -F | 指定分隔符,后面需要紧跟单引号,单引号里为分隔符,如果不加-F选项,则以空格或者tab为分隔符。 |
| $0 | 代表整行 |
| $1 | $1代表第1个字段,$2为第2个字段,以此类推 |
| print{} | print的动作要用{}括起来,否则会报错,print还可以打印自定义的内容,但是自定义的内容要用双引号引起来 |
| ~ | 匹配字符或者字符串,’$1 ~ /oo/'表示第1个字段包含oo字符 |
| == | 等于,在和数字比较时候,若把比较的数字用双引号引起来,那么awk不会认为是数字,而会认为是字符,不加双引号会认为是数字 |
| > | 大于 |
| >= | 大于等于 |
| < | 小于 |
| <= | 小于等于 |
| != | 不等于 |
| && | 并且 |
| || | 或者 |
awk以冒号为分隔符打印出多列数据
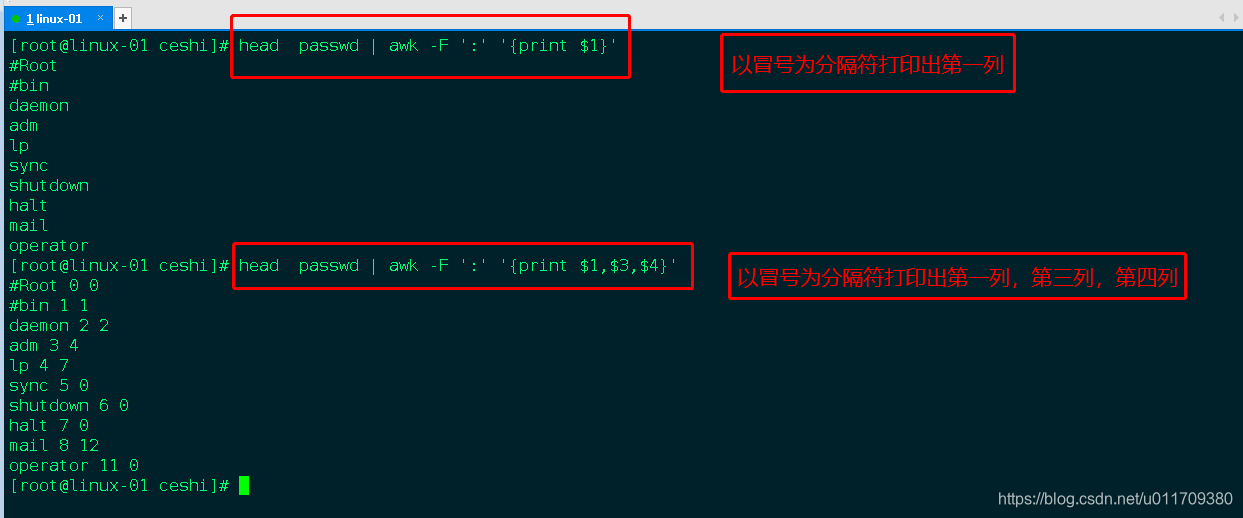
awk以分号为分隔符打印出指定格式
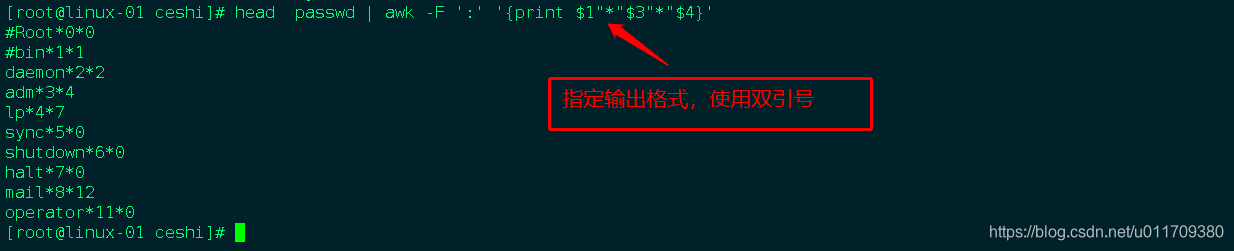
awk匹配多次条件,打印机输出
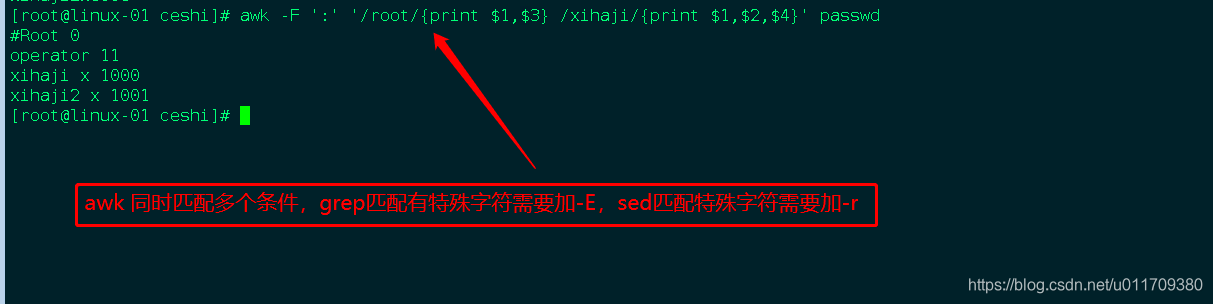
2.2 awk 条件操作符
## 把/etc/passwd中uid大于500的行列出来。##
[root@linux-01 ~]# awk -F ':' '$3 > 500' /etc/passwd
polkitd:x:999:998:User for polkitd:/:/sbin/nologin
xihaji:x:1000:1000::/home/xihaji:/bin/bash
xihaji2:x:1001:1001::/home/xihaji2:/bin/bash
readonly:x:1002:1002::/home/readonly:/bin/bash
user1:x:1003:100::/home/user1:/bin/bash
[root@linux-01 ~]# ## 如果使用双引号把500括起来,awk会认为是一个字符 ##
[root@linux-01 ~]# awk -F ':' '$3 > "500"' /etc/passwd
shutdown:x:6:0:shutdown:/sbin:/sbin/shutdown
halt:x:7:0:halt:/sbin:/sbin/halt
mail:x:8:12:mail:/var/spool/mail:/sbin/nologin
nobody:x:99:99:Nobody:/:/sbin/nologin
dbus:x:81:81:System message bus:/:/sbin/nologin
polkitd:x:999:998:User for polkitd:/:/sbin/nologin
sshd:x:74:74:Privilege-separated SSH:/var/empty/sshd:/sbin/nologin
postfix:x:89:89::/var/spool/postfix:/sbin/nologin
[root@linux-01 ~]# ## 使用‘~’匹配,‘||’ 两个条件操作 ##
[root@linux-01 ceshi]# cat passwd | awk -F ':' '$3 >'1000' ||$7 ~/bash/ '
root:x:0:0:root:/root:/bin/bash
xihaji:x:1000:1000::/home/xihaji:/bin/bash
xihaji2:x:1001:1001::/home/xihaji2:/bin/bash
readonly:x:1002:1002::/home/readonly:/bin/bash
user1:x:1003:100::/home/user1:/bin/bash
[root@linux-01 ceshi]# 2.3 awk内置变量
| 变量 | 作用 |
|---|---|
| OFS | 与-F有类似的功能,也是用来定义分隔符的,但是它是在输出的时候定义 |
| NF | 表示用分隔符分割后一共有多少段 |
| NR | 表示行号 |
## OFS的用法示例 ##
[root@linux-01 ~]# head -n5 /etc/passwd |awk -F ':' '{OFS="#"}{print $1,$3,$4}'
root#0#0
bin#1#1
daemon#2#2
adm#3#4
lp#4#7
[root@linux-01 ~]# ## 变量NF的用法如下 ##
[root@linux-01 ~]# head -n3 /etc/passwd | awk -F ':' '{print NF}'
7
7
7
[root@linux-01 ~]# ## $NF 代表的是最后一段的值 ##
[root@linux-01 ~]# head -n3 /etc/passwd | awk -F ':' '{print $NF}'
/bin/bash
/sbin/nologin
/sbin/nologin
[root@linux-01 ~]# ## 变量NR的使用方法,用做判断 ##
[root@linux-01 ~]# head -n10 /etc/passwd | awk 'NR<5'
root:x:0:0:root:/root:/bin/bash
bin:x:1:1:bin:/bin:/sbin/nologin
daemon:x:2:2:daemon:/sbin:/sbin/nologin
adm:x:3:4:adm:/var/adm:/sbin/nologin
[root@linux-01 ~]# ## if判断 ##
[root@linux-01 ceshi]# awk -F ':' '{OFS=":"} {if($3>1000) {print $1,$2,$3,$4}} ' passwd
xihaji2:x:1001:1001
readonly:x:1002:1002
user1:x:1003:100
[root@linux-01 ceshi]#
2.4 awk的数学运算
## awk更改段值 ##
[root@linux-01 ~]# head -n10 /etc/passwd | awk -F ':' '$1="root"'
root x 0 0 root /root /bin/bash
root x 1 1 bin /bin /sbin/nologin
root x 2 2 daemon /sbin /sbin/nologin
root x 3 4 adm /var/adm /sbin/nologin
root x 4 7 lp /var/spool/lpd /sbin/nologin
root x 5 0 sync /sbin /bin/sync
root x 6 0 shutdown /sbin /sbin/shutdown
root x 7 0 halt /sbin /sbin/halt
root x 8 12 mail /var/spool/mail /sbin/nologin
root x 11 0 operator /root /sbin/nologin## awk对各段的值进行运算 ##
[root@linux-01 ceshi]# awk -F ':' '{OFS=":"} {if($3>1000) {print $0}} ' passwd
xihaji2:x:1001:1001::/home/xihaji2:/bin/bash
readonly:x:1002:1002::/home/readonly:/bin/bash
user1:x:1003:100::/home/user1:/bin/bash
[root@linux-01 ceshi]# awk -F ':' '{OFS=":"} {if($3>1000) {print $1,$2,$3,$4}} ' passwd
xihaji2:x:1001:1001
readonly:x:1002:1002
user1:x:1003:100## 计算某段总和 ##
[root@linux-01 ceshi]# awk -F ':' '{(tot=tot+$3)};END {print tot}' passwd
5613
[root@linux-01 ceshi]# 课后总结
1.awk语法结构
awk -F ‘:’ ‘BEGIN{语句} {if(条件){语句1;语句2;语句3} } END{语句}’ filename
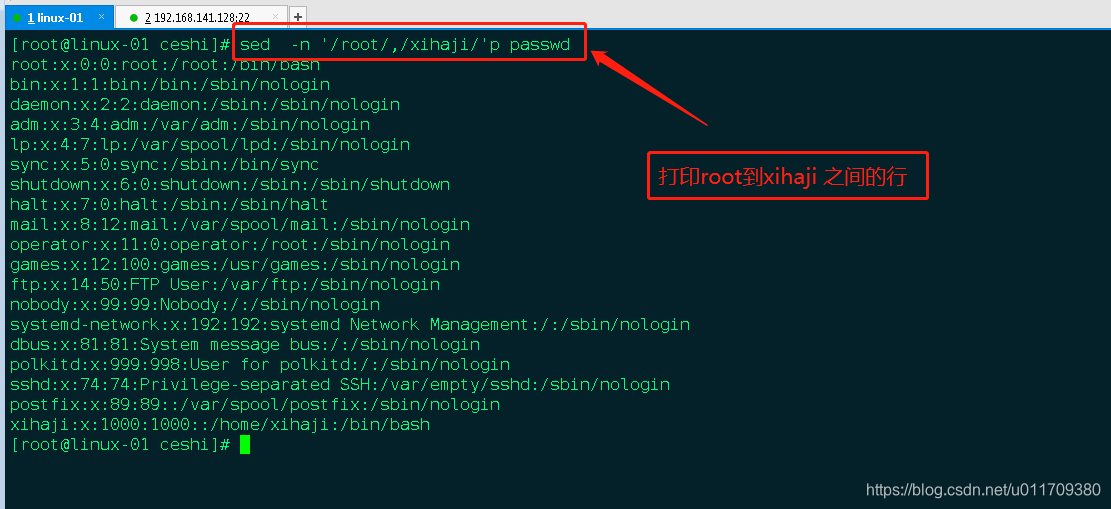
2.打印某行到某行之间的内容
sed -n ‘/tss/,/sas/p’ /etc/passwd
3.sed转换大小写
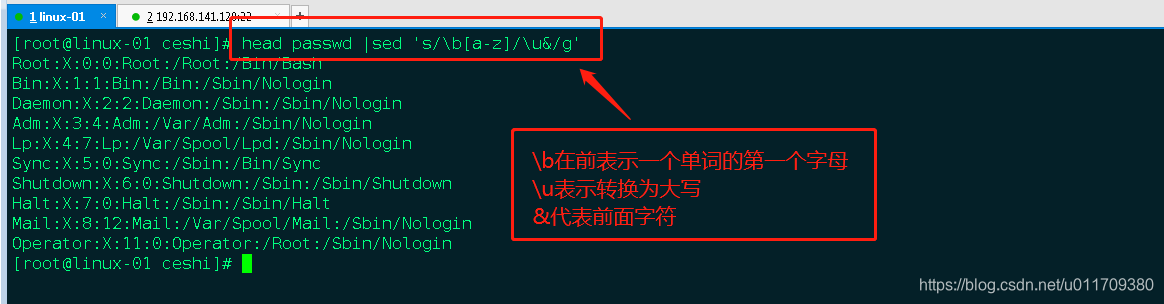
3.1. 把每个单词的第一个小写字母变大写:
sed ‘s/\b[a-z]/\u&/g’ filename
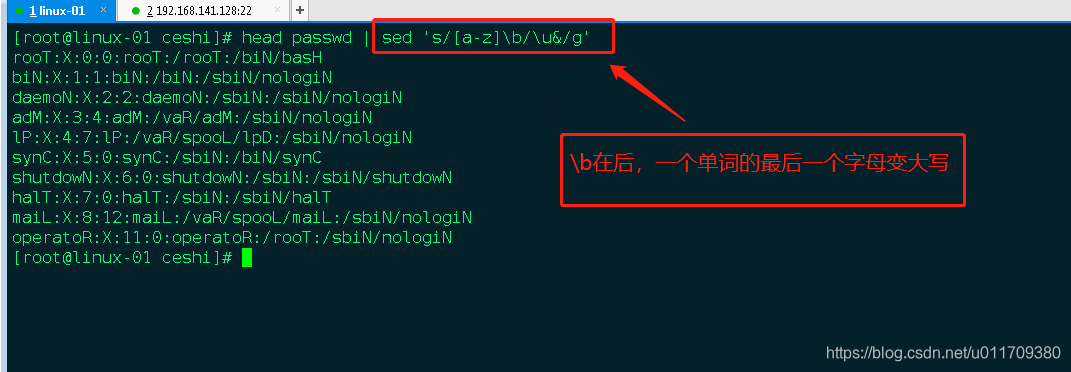
3.2 把每个单词的最后一个变为大写字母
sed ‘s/[a-z]/\u&/g’ filename
3.3 把所有小写变大写:
sed ‘s/[a-z]/\u&/g’ filename
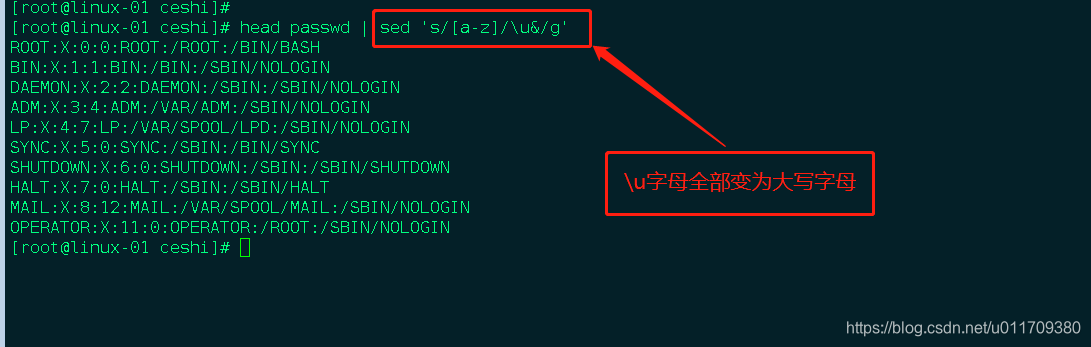
3.4. 大写变小写:
sed ‘s/[A-Z]/\l&/g’ filename
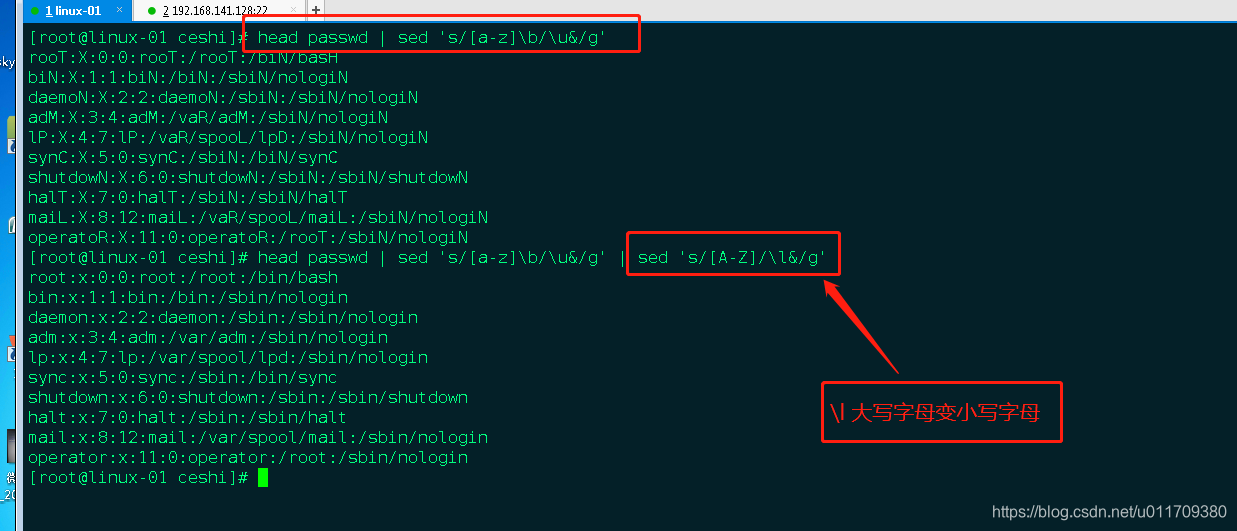
4. sed在某一行最后添加一个数字
sed -r ‘s/(^a.)/\1 12/’ test
sed -r 's/^a./& 12/’ test

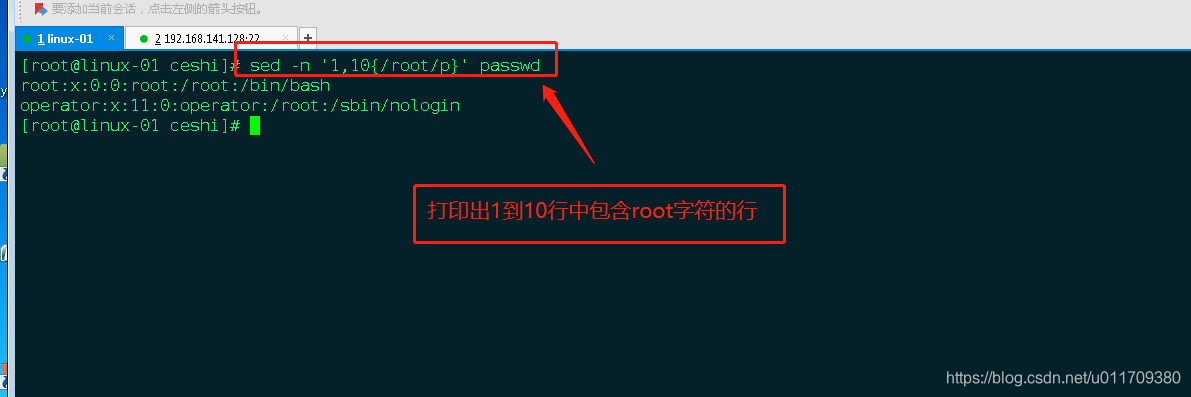
5.打印1到100行含某个字符串的行
sed -n ‘1,100{/abc/p}’ 1.txt
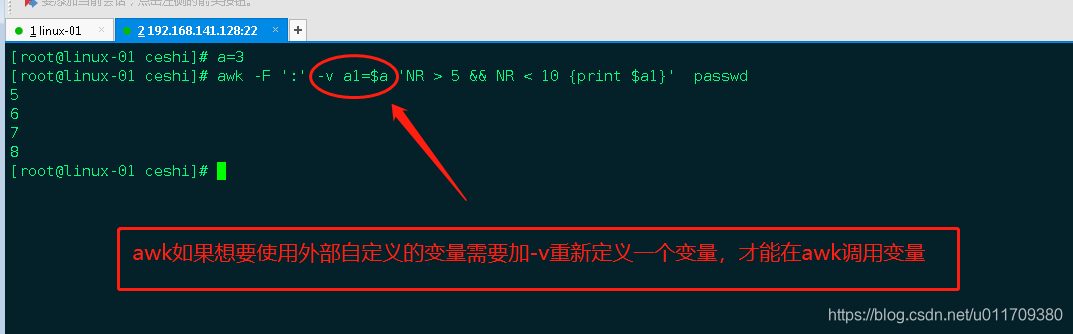
6.awk 中使用外部shell变量
a=2; echo “a?️c:d”|awk -F “:” -v get_a=$a ‘{print $get_a}’
7. awk 合并一个文件
awk ‘NR==FNR {a[$1]=$2} NR>FNR {print $0,a[$1]}’ 1.txt 2.txt
说明:
awk ‘{print NR,FNR}’ 1.txt 2.txt //首先理解NR和FNR的不同(awk支持同时操作多个文件内容)
当NR==FNR其实就是第一个文件的内容
当NR>FNR,其实就是第二个文件的内容
扩展 paste 1.txt 2.txt
8.把一个文件多行连接成一行
方法一:
a=cat file;echo $a
方法二:
awk ‘{printf("%s ",$0)}’ file
方法三:
cat file |xargs
9.awk中gsub函数的使用
awk ‘gsub(/www/,“abc”)’ /etc/passwd // passwd文件中把所有www替换为abc

awk -F ‘:’ ‘gsub(/www/,“abc”,$1) {print $0}’ /etc/passwd // 替换$1中的www为abc

10.awk 截取指定多个域为一行
用awk指定分隔符把文本分为若干段。如何把相同段的内容弄到一行?
以/etc/passwd为例,该文件以":"作为分隔符,分为了7段。
for i in `seq 1 7`
do
awk -F ':' -v a=$i '{printf $a " "}' /etc/passwd
echo
done
11.过滤两个或多个关键词
grep -E ‘123|abc’ filename // 找出文件(filename)中包含123或者包含abc的行
egrep ‘123|abc’ filename //用egrep同样可以实现
awk ‘/123|abc/’ filename // awk 的实现方式
12. awk用print打印单引号
awk ‘BEGIN{print "a’"’"‘s"}’
awk ‘BEGIN{print "a’’‘s"}’
awk ‘BEGIN{print “a"s”}’
注意:使用print打印单引号的时候,需要注意使用双引号引起来,在使用单引号引起。

这篇关于学习笔记0411----正则三剑客之sed、awk的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






