本文主要是介绍spark2.4开始支持image图片数据源操作!!,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
相关知识
色彩理论之颜色模式:
https://www.colortell.com/1463.html
java.awt.Color介绍:
https://www.cnblogs.com/21summer/p/9309435.html
javax.imageio.ImageIO:
https://blog.csdn.net/tanga842428/article/details/78573354
https://docs.oracle.com/javase/7/docs/api/javax/imageio/package-summary.html
使用例子
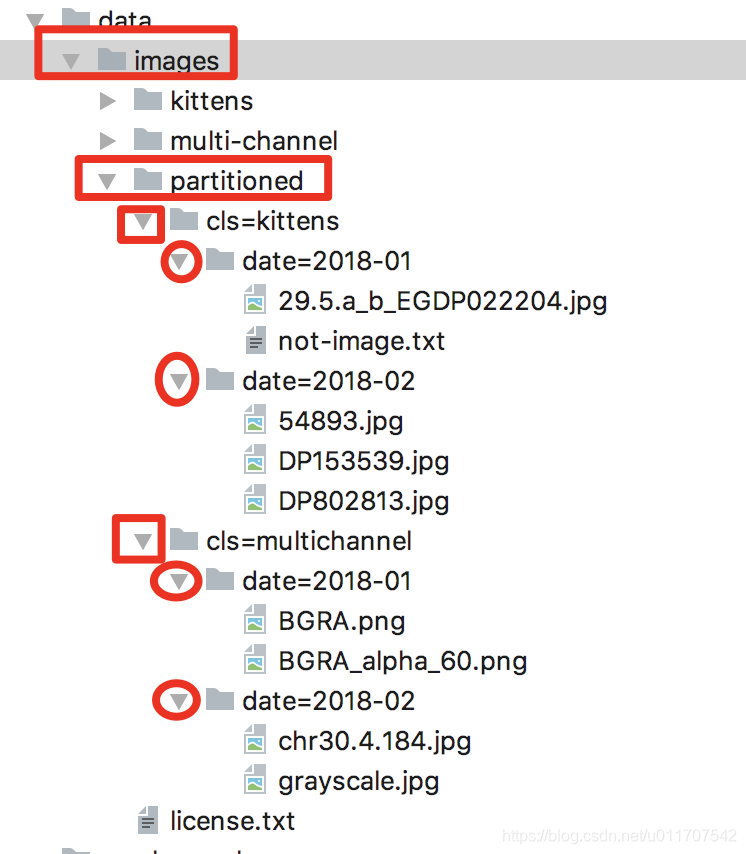
val spark = SparkSession.builder().appName("Spark SQL basic example").master("local").getOrCreate()val dataFrame = spark.read.format("image").option("dropInvalid", true).load("data/images/partitioned")dataFrame.printSchema()dataFrame.select(col("cls"),col("date"),col("image.origin"),col("image.height"),col("image.width"),col("image.nChannels"),col("image.mode")).show(false)
当前支持的参数只有一个:dropInvalid:是否从结果中删除无效的图片。
暂不支持图片数据源写到文件中。
上述代码运行结果如下:
cls 和date都是根据分区读取出来的,图片的格式只有一个字段就是image,但是image是一个嵌套的类型。
从这里面我们可以灵活使用分区字段,比如放到机器学习中,我们可以当作 label,不同图片存放在不同的label下面,可以将其归类。

dropInvalid参数设置为false的输出结果:

例子分析
format(“image”)
上述代码展示了使用sparksession读写image数据源的例子,下面我们具体分析。format参数是image意味着会去找到DataSourceRegister 的子类,重写了shortName为image的具体实现类。下面的代码即使所要使用的类,ImageFileFormat 集成了FileFormat实现了 DataSourceRegister 接口。
private[image] class ImageFileFormat extends FileFormat with DataSourceRegister {override def inferSchema(sparkSession: SparkSession,options: Map[String, String],files: Seq[FileStatus]): Option[StructType] = Some(ImageSchema.imageSchema)override def shortName(): String = "image"......
}图片数据的schema
那么我们来看一下image数据格式是什么,上面代码中重写了inferSchema方法,我们可以看到调用了ImageSchema.imageSchema,我们看看具体实现:
//我们会发现读取image图片后dataframe只有单一的一列,名字是image,而image对应的列的类型就是columnSchema
val imageSchema = StructType(StructField("image", columnSchema, true) :: Nil)//那么columnSchema是什么呢?其实很明显dataframe虽然只有一列名字叫做image,但是它的类型却是嵌套类型val columnSchema = StructType(StructField("origin", StringType, true) ::StructField("height", IntegerType, false) ::StructField("width", IntegerType, false) ::StructField("nChannels", IntegerType, false) ::// OpenCV-compatible type: CV_8UC3 in most casesStructField("mode", IntegerType, false) ::// Bytes in OpenCV-compatible order: row-wise BGR in most casesStructField("data", BinaryType, false) :: Nil)
对于image列对应的schema类型其实就是Row(String, Int, Int, Int, Int, Array[Byte])。
image中每一列字段解释:
- origin :图片路径
- height:图片高度
- width:图片宽度
- nChannerls:图片通道数量
- mode:openCV兼容的类型
- data:以openCV兼容的方式排列,大多数情况下按行排列BGR
打印出来的schema信息:
root|-- image: struct (nullable = true)| |-- origin: string (nullable = true)| |-- height: integer (nullable = true)| |-- width: integer (nullable = true)| |-- nChannels: integer (nullable = true)| |-- mode: integer (nullable = true)| |-- data: binary (nullable = true)|-- cls: string (nullable = true)|-- date: string (nullable = true)mode字段取值:openCV支持的类型:
CV_<bit_depth>(S|U|F)C<number_of_channels>
val ocvTypes: Map[String, Int] = Map(undefinedImageType -> -1,"CV_8U" -> 0, "CV_8UC1" -> 0, "CV_8UC3" -> 16, "CV_8UC4" -> 24)
1--bit_depth---比特数---代表8bite,16bites,32bites,64bites---举个例子吧--比如说,如果你现在创建了一个存储--灰度图片的Mat对象,这个图像的大小为宽100,高100,那么,现在这张灰度图片中有10000个像素点,它每一个像素点在内存空间所占的空间大小是8bite,8位--所以它对应的就是CV_82--S|U|F--S--代表---signed int---有符号整形U--代表--unsigned int--无符号整形F--代表--float---------单精度浮点型3--C<number_of_channels>----代表---一张图片的通道数,比如:1--灰度图片--grayImg---是--单通道图像2--RGB彩色图像---------是--3通道图像3--带Alph通道的RGB图像--是--4通道图像
颜色的通道:
对于灰度图像,典型值为1,对于彩色图像(例如,RGB),典型值为3,对于具有alpha通道的彩色图像,典型值为4。
例子举例说明
//简单例子
//isGray是判断是否是灰度图像的
val (nChannels, mode) = if (isGray) {(1, ocvTypes("CV_8UC1"))} else if (hasAlpha) {(4, ocvTypes("CV_8UC4"))} else {(3, ocvTypes("CV_8UC3"))}
我们简单看一个灰度图像例子:下面的图像是我们所读路径下的一个图片,具体路径如下
data/images/partitioned/cls=multichannel/date=2018-02/grayscale.jpg

对应的输出如下:
字段如下:
|cls |date |origin |height |width |nChannels |mode|分别对应如下:
multichannel
2018-02
file:///Users/hehuiyuan/ideawarehouse/DebugCode/data/images/partitioned/cls=multichannel/date=2018-02/grayscale.jpg
215
300
1
0
这篇关于spark2.4开始支持image图片数据源操作!!的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





