本文主要是介绍微服务链路追踪ELK,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
微服务链路追踪&ELK
- 链路追踪概述
- 链路追踪sluth+zipkin
- elk日志管理平台
一 链路追踪
1 概述
1.1 为什么需要链路追踪
微服务架构是一个分布式架构,它按业务划分服务单元,一个分布式系统往往有很多个服务单元。由于服务单元数量众多,业务的复杂性,如果出现了错误和异常,很难去定位。主要体现在,一个请求可能需要调用很多个服务,而内部服务的调用复杂性,决定了问题难以定位。所以微服务架构中,必须实现分布式链路追踪,去跟进一个请求到底有哪些服务参与,参与的顺序又是怎样的,从而达到每个请求的步骤清晰可见,出了问题,很快定位。
作用:快速定位到问题出现在哪个地方
1.2 常见的链路追踪
-
cat 由大众点评开源,基于Java开发的实时应用监控平台,包括实时应用监控,业务监控 。 集成方案是通过代码埋点的方式来实现监控,比如: 拦截器,过滤器等。 对代码的侵入性很大,集成成本较高。风险较大。
-
zipkin 由Twitter公司开源,开放源代码分布式的跟踪系统,用于收集服务的定时数据,以解决微服务架构中的延迟问题,包括:数据的收集、存储、查找和展现《图形化》。该产品结合spring-cloud-sleuth 使用较为简单, 集成很方便, 但是功能较简单。
-
pinpoint 是韩国人开源的基于字节码注入的调用链分析,以及应用监控分析工具。特点是支持多种插件,UI功能强大,接入端无代码侵入。
-
skywalking 是本土开源的基于字节码注入的调用链分析,以及应用监控分析工具。特点是支持多种插件,UI功能较强,接入端无代码侵入。目前已加入Apache孵化器。
2 sleuth+Zipkin
2.1 sleuth介绍
SpringCloud Sleuth主要功能就是在分布式系统中提供追踪解决方案。它大量借用了Google Dapper的设计, 先来了解一下Sleuth中的术语和相关概念。
Trace (一条完整链路–包含很多span(微服务接口))
由一组Trace Id(贯穿整个链路)相同的Span串联形成一个树状结构。为了实现请求跟踪,当请求到达分布式系统的入口端点时,只需要服务跟踪框架为该请求创建一个唯一的标识(即TraceId),同时在分布式系统内部流转的时候,框架始终保持传递该唯一值,直到整个请求的返回。那么我们就可以使用该唯一标识将所有的请求串联起来,形成一条完整的请求链路。
Span
代表了一组基本的工作单元。为了统计各处理单元的延迟,当请求到达各个服务组件的时候,也通过一个唯一标识(SpanId)来标记它的开始、具体过程和结束。通过SpanId的开始和结束时间戳,就能统计该span的调用时间,除此之外,我们还可以获取如事件的名称。请求信息等元数据。
Annotation
用它记录一段时间内的事件,内部使用的重要注释:
cs(Client Send)客户端发出请求,开始一个请求的命令sr(Server Received)服务端接受到请求开始进行处理, sr-cs = 网络延迟(服务调用的时间)ss(Server Send)服务端处理完毕准备发送到客户端,ss - sr = 服务器上的请求处理时间cr(Client Reveived)客户端接受到服务端的响应,请求结束。 cr - cs = 请求的总时间
2.2 sleuth入门
微服务的pom.xml导入
<dependencies><dependency><groupId>org.springframework.cloud</groupId><artifactId>spring-cloud-starter-sleuth</artifactId></dependency></dependencies>
在要进行链路追踪的微服务的配置文件application.yml中添加
spring: sleuth: #springCloud链接追踪web:client:enabled: truesampler:probability: 1.0 # 将采样比例设置为 1.0,也就是全部都需要。默认是 0.1
测试,启动各个服务进行测试,其实在启动各个服务时,就已经可以看到控制台打印了很多的信息
通过zuul网关调用user服务,查看sleuth打印的日志
zuul-server日志

user-service日志
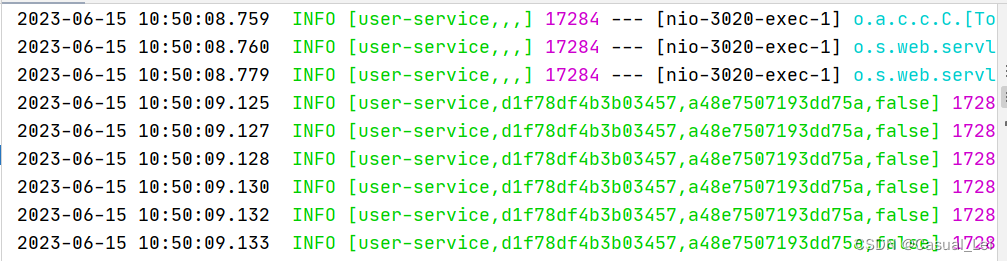
order-service日志

日志的格式为:[application name, traceId, spanId, export]
- application name — 应用的名称,也就是application.properties中的spring.application.name参数配置的属性。
- traceId — 为一个请求分配的ID号,用来标识一条请求链路。
- spanId — 表示一个基本的工作单元,一个请求可以包含多个步骤,每个步骤都拥有自己的spanId。一个请求包含一个TraceId,多个SpanId
- export — 布尔类型。表示是否要将该信息输出到类似Zipkin这样的聚合器进行收集和展示。
但是直接在控制台查看日志内容并不是一个很好的方法,当微服务越来越多日志文件也会越来越多,通过Zipkin可以将日志聚合,并进行可视化展示和全文检索。
2.3 集成zipkin
2.3.1 zipkin介绍
Zipkin 是 Twitter 的一个开源项目,它基于Google Dapper实现,它致力于收集服务的定时数据,以解决微服务架构中的延迟问题,包括数据的收集、存储展现、查找,我们可以使用它来收集各个服务器上请求链路的跟踪数据,并通过它提供的REST API接口来辅助我们查询跟踪数据以实现对分布式系统的监控程序,从而及时地发现系统中出现的延迟升高问题并找出系统性能瓶颈的根源
除了面向开发的 API 接口之外,它也提供了方便的UI组件来帮助我们直观的搜索跟踪信息和分析请求链路明细,比如:可以查询某段时间内各用户请求的处理时间等。
Zipkin 提供了可插拔数据存储方式:In-Memory、MySql、Cassandra 以及 Elasticsearch。
zipkin的核心由4部分组成
- Collector:收集器组件,它主要用于处理从外部系统发送过来的跟踪信息,将这些信息转换为Zipkin 内部处理的 Span 格式,以支持后续的存储、分析、展示等功能。
- Storage:存储组件,它主要对处理收集器接收到的跟踪信息,默认会将这些信息存储在内存中,我们也可以修改此存储策略,通过使用其他存储组件将跟踪信息存储到数据库中。
- RESTful API:API 组件,它主要用来提供外部访问接口。比如给客户端展示跟踪信息,或是外接系统访问以实现监控等。
- Web UI:UI 组件,基于 API 组件实现的上层应用。通过 UI 组件用户可以方便而有直观地查询和分析跟踪信息。
Zipkin 分为两端,一个是 Zipkin 服务端,一个是 Zipkin 客户端,客户端也就是微服务的应用。客户端会配置服务端的 URL 地址,一旦发生服务间的调用的时候,会被配置在微服务里面的 Sleuth 的监听器监听,并生成相应的 Trace 和 Span 信息发送给服务端。
2.3.2 zipkin服务端安装
zipkin安装服务端有两种方式,一是下载ZipKin的jar包,通过命令直接启动即可;二是手动添加依赖创建 Zipkin 服务器应用。本次我们采用直接下载启动zipkin的jar包的方式实现
jar包下载地址:
https://repo1.maven.org/maven2/io/zipkin/zipkin-server/
jar下载以后,通过命令启动
java -jar zipkin-server-2.19.3-exec.jar
启动完成,输入地址测试
http://localhost:9411
2.3.3 zipkin客户端集成
在微服务中导入jar包
<dependency><groupId>org.springframework.cloud</groupId><artifactId>spring-cloud-starter-zipkin</artifactId></dependency>
application.yml中添加配置
spring:zipkin:base-url: http://localhost:9411discovery-client-enabled: false # 不将zipkin注册到eureka
启动微服务,调用某一个接口,查看zipkin页面,观察调用情况
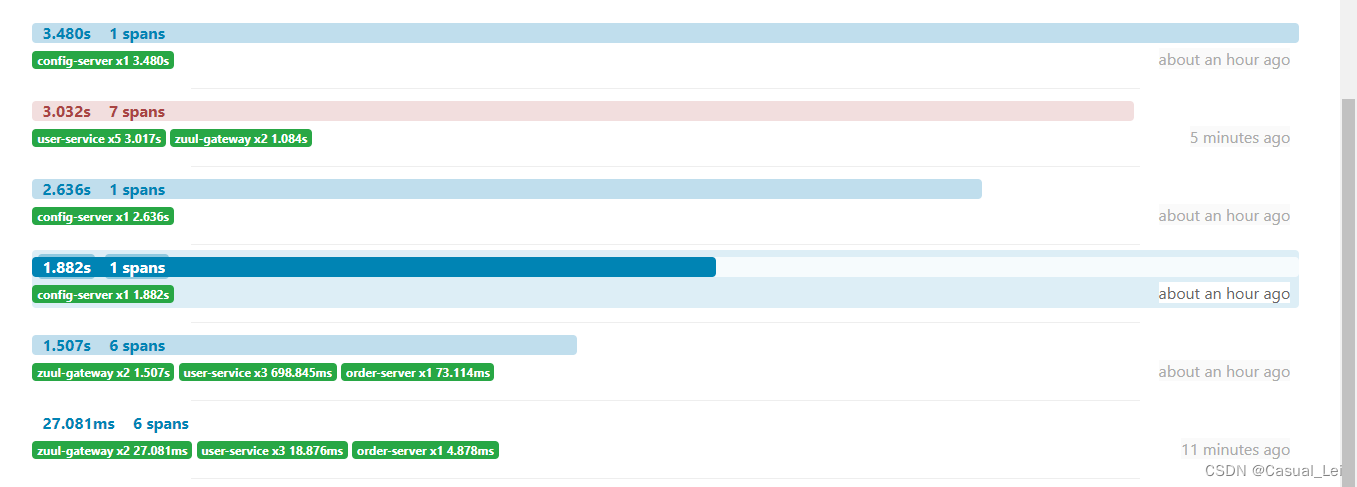
点开某一个调用链,可以查看到详情
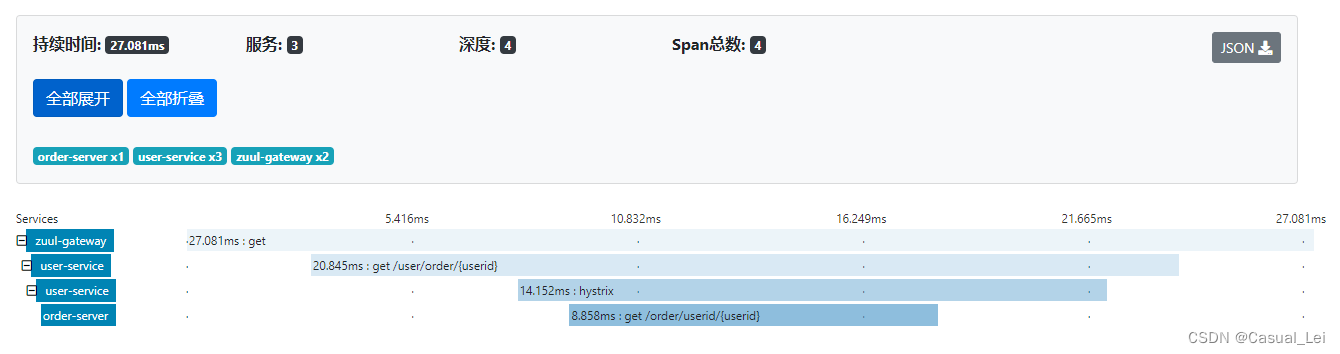
2.4 zipkin数据持久化-mysql
Zipkin Server默认会将追踪数据信息保存到内存,但这种方式不适合生产环境。Zipkin支持将追踪数据持久化到mysql数据库或elasticsearch中
2.4.1 创建mysql数据库表
导入zipkin.sql即可
这个sql文件是可以自己从github地址进行下载的
2.4.2 启动zipkin的服务端时指定存储类型为数据库
java -jar zipkin-server-2.19.3-exec.jar --STORAGE_TYPE=mysql --MYSQL_HOST=127.0.0.1 --MYSQL_TCP_PORT=3306 --MYSQL_DB=zipkin --MYSQL_USER=root --MYSQL_PASS=123456
2.5 zipkin数据持久化-elasticsearch
-
启动elasticsearch
-
启动zipkin server,指定要连接的es
java -jar zipkin-server-2.19.3-exec.jar --STORAGE_TYPE=elasticsearch --ES_HOSTS=127.0.0.1:9200
二 ELK
1 概述
1.1 是什么
ELK平台是一套完整的日志集中处理解决方案,将ElasticSearch、Logstash和Kibana 三个开源工具配合使用,完成更强大的用户对日志的查询、排序、统计需求。
一套好的日志分析系统可以详细记录系统的运行情况,方便我们定位分析系统性能瓶颈、查找定位系统问题。基于E(ElasticSearch)L(Logstash)K(Kibana)组合的日志分析系统可以说是目前各家公司普遍的首选方案
1.2 ELK组件
- Elasticsearch:
- 基于Lucene开发的分布式存储检索引擎,用来存储各类日志
- 是java开发的,可通过restFul接口,让用户可以通过浏览器与es通信。
- 是一个实时的,分布式的可扩展的搜索引擎,允许进行全文,结构化搜索,它通常用于搜索大容量的日志数据,也可用于搜索许多不同类型的文档。
- Kibana:通常与Elacticsearch一起部署,是es的一个功能强大的可视化工具,Kibana提供图形界面化的web界面来浏览Elasticsearch日志数据,可以用来汇总、分析和搜索重要数据。
- Logstash:
- 作为数据搜集引擎,它支持动态的从各种数据源搜集数据,并对数据进行过滤、分析、丰富、统一格式等操作,然后存储到用户指定的位置,这儿就是发送给Elasticsearch
- 由Ruby语言编写,可以实现数据传输,格式处理,格式化输出,Logstash具有强大的插件功能,常用于日志处理。
1.3 ELK工作原理
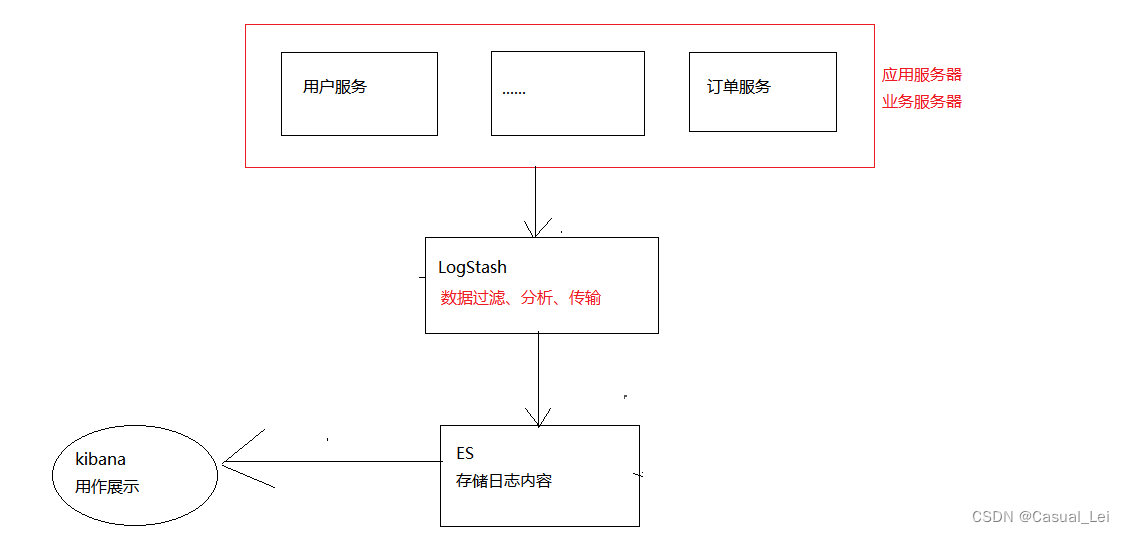
- 每个业务服务器/应用服务器,将日志内容传输到LogStash,做数据的过滤、分析等
- 做完数据过滤分析以后,就将日志存放到ES
- 最后通过kibana进行日志的查询等。
2 实现
以后在公司里面,ELK中es和kibana应该是搭建在一个专门的服务器上的,搭建在linux的系统里. 但是我们现在是在学习阶段,先搭建在windows
2.1 安装es+kibana
略过…
2.2 安装logstash
下载logstash压缩包,解压即可
解压完成:
复制logstash-sample.conf取名logstash.conf,配置输入信息和输出信息
# Sample Logstash configuration for creating a simple
# Beats -> Logstash -> Elasticsearch pipeline.input {tcp {mode => "server"host => "0.0.0.0"port => 4560codec => json_linestype => "manage"}tcp {mode => "server"host => "0.0.0.0"port => 4561codec => json_linestype => "manage"}
}output {elasticsearch {hosts => ["http://localhost:9200"]index => "elk-log-%{+YYYY.MM.dd}"#user => "elastic"#password => "changeme"}
}
进入bin目录,使用如下命令启动
logstash -f ../config/logstash.conf
2.3 修改业务服务
在业务服务的resources下添加logback.xml,内容如下:
<configuration><timestamp key="bySecond" datePattern="yyyy-MM-dd HH:mm:ss"/><!-- 日志目录 --><property name="LOG_HOME" value="D:/elk/logs"/><!--输出到logstash的appender--><appender name="INFO_LOGSTASH" class="net.logstash.logback.appender.LogstashTcpSocketAppender"><filter class="ch.qos.logback.classic.filter.LevelFilter"><!--返回DENY,日志将立即被抛弃不再经过其他过滤器;返回NEUTRAL,有序列表里的下个过滤器接着处理日志;返回ACCEPT,日志会被立即处理,不再经过剩余过滤器--><level>INFO</level><onMatch>NEUTRAL</onMatch><onMismatch>DENY</onMismatch></filter><!--可以访问的logstash日志收集端口--><destination>127.0.0.1:4560</destination><encoder charset="UTF-8" class="net.logstash.logback.encoder.LogstashEncoder"/></appender><appender name="WARN_LOGSTASH" class="net.logstash.logback.appender.LogstashTcpSocketAppender"><filter class="ch.qos.logback.classic.filter.LevelFilter"><!--返回DENY,日志将立即被抛弃不再经过其他过滤器;返回NEUTRAL,有序列表里的下个过滤器接着处理日志;返回ACCEPT,日志会被立即处理,不再经过剩余过滤器--><level>WARN</level><onMatch>NEUTRAL</onMatch><onMismatch>DENY</onMismatch></filter><!--可以访问的logstash日志收集端口--><destination>127.0.0.1:4560</destination><encoder charset="UTF-8" class="net.logstash.logback.encoder.LogstashEncoder"/></appender><appender name="ERROR_LOGSTASH" class="net.logstash.logback.appender.LogstashTcpSocketAppender"><filter class="ch.qos.logback.classic.filter.LevelFilter"><!--返回DENY,日志将立即被抛弃不再经过其他过滤器;返回NEUTRAL,有序列表里的下个过滤器接着处理日志;返回ACCEPT,日志会被立即处理,不再经过剩余过滤器--><level>ERROR</level><onMatch>NEUTRAL</onMatch><onMismatch>DENY</onMismatch></filter><!--可以访问的logstash日志收集端口--><destination>127.0.0.1:4560</destination><encoder charset="UTF-8" class="net.logstash.logback.encoder.LogstashEncoder"/></appender><appender name="STDOUT" class="ch.qos.logback.core.ConsoleAppender"><encoder><pattern>[%d][%-5level][%thread][%logger][%X{TRACE_ID}][%msg]%n</pattern></encoder></appender><!-- 仅针对这个Controller收集日志 --><logger name="cn.ronghuanet"><level value="INFO"/><appender-ref ref="INFO_LOGSTASH"/><appender-ref ref="WARN_LOGSTASH"/><appender-ref ref="ERROR_LOGSTASH"/></logger><root level="INFO"><appender-ref ref="STDOUT"/></root></configuration>
application.yml中添加配置
logging:config: classpath:logback.xml
pom.xml中导入lombok,用来输出日志
<!-- logback --><dependency><groupId>net.logstash.logback</groupId><artifactId>logstash-logback-encoder</artifactId><version>6.3</version></dependency>
<dependency><groupId>org.projectlombok</groupId><artifactId>lombok</artifactId></dependency>
在业务类中使用log进行日志打印
@RestController
@RequestMapping("/user")
@Slf4j
public class UserController {@Autowiredprivate OrderClient orderClient;@GetMapping("/order/{userId}")public List<Order> getOrderByUserId(@PathVariable("userId") Long userId){log.info("用户服务info..........................");log.warn("用户服务warn..........................");log.error("用户服务error..........................");List list = orderClient.getOrderByUserId(userId);return list;}
}
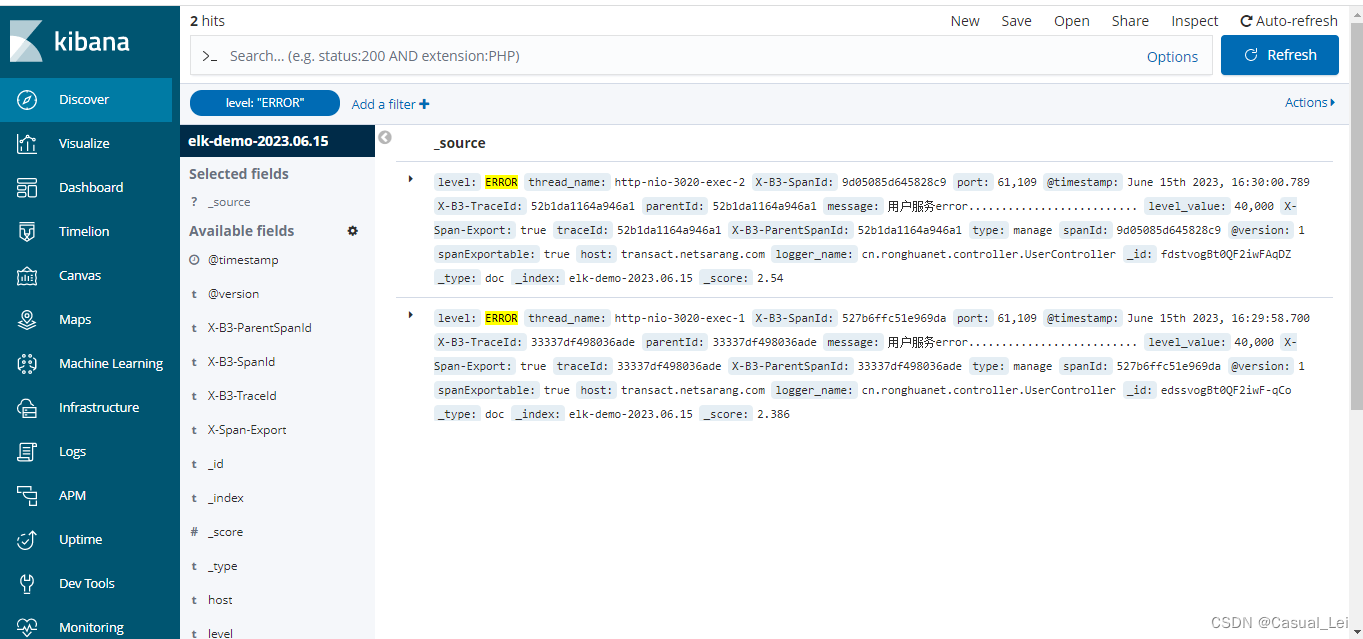
2.4 测试
postman发起请求,访问kibana,查看日志
3 ELK常见部署架构
3.1. Logstash作为日志收集器
这种架构是比较原始的部署架构,在各应用服务器端分别部署一个Logstash组件,作为日志收集器,然后将Logstash收集到的数据过滤、分析、格式化处理后发送至Elasticsearch存储,最后使用Kibana进行可视化展示。
这种架构不足的是:Logstash比较耗服务器资源,所以会增加应用服务器端的负载压力。
3.2. Filebeat作为日志收集器
该架构与第一种架构唯一不同的是:应用端日志收集器换成了Filebeat,Filebeat轻量,占用服务器资源少,所以使用Filebeat作为应用服务器端的日志收集器,一般Filebeat会配合Logstash一起使用,这种部署方式也是目前最常用的架构。
3.2.1 整合FileBeat
下载fileBeat压缩包,解压即可
修改filebeat.yml
-
添加path路径,这个路径要看你项目中将日志输出到了哪儿
filebeat.inputs:
# Each - is an input. Most options can be set at the input level, so
# you can use different inputs for various configurations.
# Below are the input specific configurations.-
type: log
# Change to true to enable this input configuration.
enabled: true# Paths that should be crawled and fetched. Glob based paths.
paths:- D:\elk\logs\info*.log
- D:\elk\logs\warn*.log
- D:\elk\logs\error*.log
- D:\elk\logs*.log
#- c:\programdata\elasticsearch\logs*
-
-
注释掉outpath.es,输出到logstash
#-------------------------- Elasticsearch output ------------------------------# output.elasticsearch:# Array of hosts to connect to.# hosts: ["localhost:9200"]# Enabled ilm (beta) to use index lifecycle management instead daily indices.#ilm.enabled: false# Optional protocol and basic auth credentials.#protocol: "https"#username: "elastic"#password: "changeme"
#----------------------------- Logstash output --------------------------------
output.logstash:# The Logstash hostshosts: ["localhost:5044"]
使用命令启动
filebeat.exe -e -c filebeat.yml
修改logstash的配置文件,要从filebeat来接收数据
3.2.2 业务微服务改造
修改logback.xml内容
<?xml version="1.0" encoding="UTF-8"?>
<configuration><!-- 定义常量 : 日志格式 --><property name="CONSOLE_LOG_PATTERN" value="%d{yyyy-MM-dd HH:mm:ss.SSS} ----> [%thread] ---> %-5level %logger{50} - %msg%n"/><!--ConsoleAppender 用于在屏幕上输出日志--><appender name="stdout" class="ch.qos.logback.core.ConsoleAppender"><!--定义控制台输出格式--><encoder><pattern>${CONSOLE_LOG_PATTERN}</pattern><!-- 设置字符集 --><charset>UTF-8</charset></encoder></appender><!--打印到文件--><appender name="file" class="ch.qos.logback.core.rolling.RollingFileAppender"><file>D:\logs\user.log</file><rollingPolicy class="ch.qos.logback.core.rolling.SizeAndTimeBasedRollingPolicy"><fileNamePattern>D:\logs\user-%d{yyyyMMdd}-%i.log</fileNamePattern><maxFileSize>1KB</maxFileSize><maxHistory>30</maxHistory><!--总上限大小--><totalSizeCap>5GB</totalSizeCap></rollingPolicy><!--定义控制台输出格式--><encoder><pattern>${CONSOLE_LOG_PATTERN}</pattern><!-- 设置字符集 --><charset>UTF-8</charset></encoder></appender><!--root是默认的logger 这里设定输出级别是debug--><root level="info"><!--定义了两个appender,日志会通过往这两个appender里面写--><appender-ref ref="stdout"/><appender-ref ref="file"/></root><!--如果没有设置 additivity="false" ,就会导致一条日志在控制台输出两次的情况--><!--additivity表示要不要使用rootLogger配置的appender进行输出--><logger name="cn.ronghuanet" level="debug" additivity="false"><appender-ref ref="stdout"/><appender-ref ref="file"/></logger></configuration>
3.3 引入缓存队列的部署架构
该架构在第二种架构的基础上引入了Kafka消息队列(还可以是其他消息队列),将Filebeat收集到的数据发送至Kafka,然后在通过Logstasth读取Kafka中的数据,这种架构主要是解决大数据量下的日志收集方案,使用缓存队列主要是解决数据安全与均衡Logstash与Elasticsearch负载压力。
这篇关于微服务链路追踪ELK的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!