本文主要是介绍mysql高级(一)——索引和explain介绍,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
什么是索引?
可以理解为排好序的快速查找数据结构
优势:
1.类似大学图书馆建书目索引,提高数据检索的效率,降低数据库的IO成本
2.通过索引对数据进行排序,降低数据排序的成本,降低了CPU的消耗
劣势:
1.实际上索引也是一张表,保存了主键和索引字段,并指向实体表的记录,所以索引也是要占用空间的
2.虽然索引提高了查询速度,但同时却降低了更新表的速度,因为每次更新表,mysql不仅要更新数据。每次更新添加了索引列的字段,都会调整因为更新带来的键值变化后的索引信息
3.索引只是提高效率的一个因素,如果mysql有大量的数据表,就需要研究建立最优索引,或优化查询
索引的分类
- 单值索引:一个索引只包含单个列,一个表可以有多个单列索引
- 唯一索引:索引列的值必须唯一,但允许空值(CREATE UNIQUE INDEX indexName ON mytable(colName))
- 复合索引:即一个索引包含多个列
基本语法
- 创建:CREATE [UNIQUE] INDEX indexName ON mytable(colName)
ALTER TABLE mytable ADD [UNIQUE] INDEX indexName(colName) - 删除:DROP INDEX [indexName] ON mytable
- 查看:SHOW INDEX FROM table_name
索引结构
BTree索引- Hash索引
- full-text全文索引
- R-Tree索引
哪些情况需要创建索引
- 主键自动建立唯一索引
- 频繁作为查询条件的字段应该创建索引
- 查询中与其他表关联的字段,外键关系建立索引
- 频繁更新的字段不适合创建索引
- Where条件里用不到的字段不创建索引
- 高并发下倾向于创建组合索引
- 查询中排序的字段,排序字段若通过索引去访问将大大提高排序速度
- 查询中统计或者分组的字段
SQL性能分析
EXPLAIN
使用EXPLAIN关键字可以模拟优化器执行SQL查询语句,从而知道Mysql是如何处理你的SQL语句的。分析你的查询语句或是表结构的性能瓶颈。

下面我们就来分析表头的这些字段代表什么。
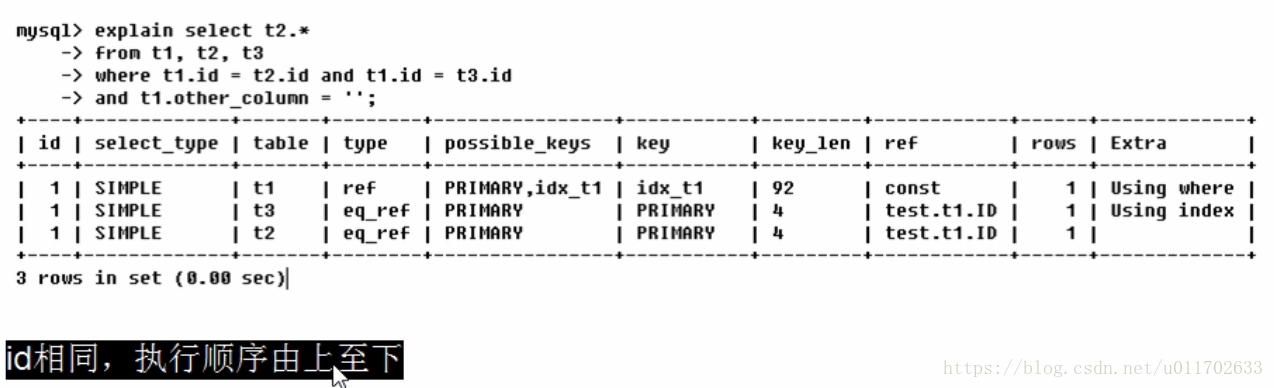
id
id相同:
id不同:
id相同又不同:
select_type


常见的有:
SIMPLE、PRIMARY、SUBQUERY、DERIVED、UNION、UNION RESULT

- type

- possible_keys key

- key_len

- ref
显示索引的哪一列被使用了,如果可能的话,是一个常数。哪些列或者常量被用于查找索引列上的值。
- rows
根据表统计信息及索引选用的情况,大致估算出找到所需的记录所需要读取的行数
- Extra
根包含不适合在其他列中显示但十分重要的额外信息

这篇关于mysql高级(一)——索引和explain介绍的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!




