本文主要是介绍GAN相关工作介绍,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
GAN介绍
GenerativeAdversarial Nets
生成对抗网络的思想在2014年提出,在原始的paper中,作者用博弈论来阐释GAN框架背后的思想。每一个GAN框架,都包含一个生成模型G和一个判别模型D,判别模型的任务是判断给定图像是否看起来‘自然’,换句话说,是否像是机器生成的。而生成器的任务是,生成看起来‘自然’的图像,要求与原始数据分布尽可能一致。作者在文中有一个形象的比喻:生成模型G就像小偷,要尽可能地提高自己的偷窃手段去欺骗身为警察的判别模型D,而D也要尽可能的训练自己的火眼金睛去防止被欺骗。实现的方法是让两个网络相互竞争,其中生成器网络不断捕捉训练库里真实图片的概率分布,将输入的随机噪声z转变成新的样本(也就是假数据)。判别器网络可以同时观察真实和假造的数据,判断这个数据到底是不是真的。所以,体现在公式上,就是下面这样一个 minmax 的形式。

其中,D(x)代表x来自真实数据而不是生成器产生的数据的概率,通过训练G使得log(1-d(g(z)))的值最小。
如图所示,我们手上有真实数据(黑色点,data)和模型生成的伪数据(绿色线,model distribution,是由我们的 z 映射过去的)(画成波峰的形式是因为它们都代表着各自的分布,其中纵轴是分布,横轴是我们的 x)。而我们要学习的 D 就是那条蓝色的点线,这条线的目的是把融在一起的 data 和 model 分布给区分开。(写成公式就是 data 和 model分布相加做分母,分子则是真实的 data 分布。我们最终要达到的效果是:D 无限接近于常数 1/2。换句话说就是要 Pmodel 和 Pdata 无限相似。这个时候,我们的 D 分布再也没法分辨出真伪数据的区别了。这时候,我们就可以说我们训练出了一个炉火纯青的造假者(生成模型)。)
GAN这种竞争的方式不再要求一个假设的数据分布,而是直接进行采样,从而真正达到了理论上可以完全逼近真实数据。这也是 GAN 最大的优势。
虽然GAN不再需要预先建模,但这个优点也带来了一些麻烦。
尽管它用一个noise z作为先验,但生成模型如何利用这个z是无法控制的。也就是说,GAN 的学习模式太过于自由了,使得 GAN 的训练过程和训练结果很多时候都不太可控。在这篇paper中,每次学习参数的更新过程,被设为 D 更新 k 回,G 才更新 1 回,就是出于减少G 的“自由度”的考虑。

ConditionalGenerative Adversarial Nets
为了解决GAN太过自由的这个问题,一个很自然的思想便是给 GAN 加上一点点束缚,于是便有了Conditional Generative Adversarial Nets(CGAN)。这篇工作的改进非常直接,就是在D和G的建模中分别加入 条件变量 y。也因此,CGAN 可以看做把无监督的 GAN 变成有监督的模型的一种改进。后来这一方式也被证明非常有效。
Deep Generative Image Models using a LaplacianPyramid of Adversarial Networks
同样,为了改进GAN 太自由的问题,还有一个想法就是不要让 GAN 一次完成全部任务,而是一次生成一部分,分多次生成一张完整的图片。本篇paper就是采用这样的思想,在GAN 基础上做出了改进。
采用了Laplacian Pyramid 实现了“序列化”,也因此起名做 LAPGAN 。
在学习序列中,LAPGAN 不断地进行 downsample 和 upsample 操作,然后在每一个 Pyramid level 中,只将残差传递给判别模型D进行判断。这样的“序列化+ 残差结合”的方式,能有效减少 GAN 需要学习的内容和难度,从而达到了 “辅助”GAN 学习的目的。
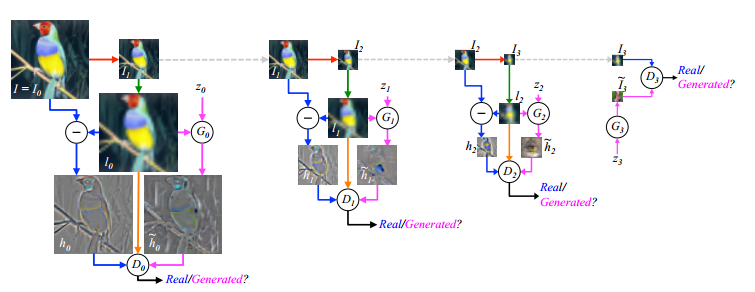
这个图中,当图像是较大像素时,便需要进行Laplacian Pyramid 过程,并且在每一个Pyramidlevel ,传给 D 的只是针对残差的比较。另一方面,当像素足够小的时候,也就是最右边的 step,则不再需要进行upsample和downsample的过程,这时给 D 的传送则是未经处理的样本和生成的图像。通过这种方法,能够得到高分辨率图像。
Unsupervised Representation Learning with DeepConvolutional Generative Adversarial Networks
DCGAN理论创新不大,但是工程经验值得借鉴
LAPGAN 中指出 Batch Normalization(BN)被用在 GAN 中的 D 上会导致整个学习的崩溃,但是DCGAN中则成功将 BN 用在了 G 和 D 上。
学习了 ICLR 2016 论文《Generating Sentences From aContinuous Space》中的interpolate space的方式,将生成图片中的hidden states都展示了出来,可以看出图像逐渐演变的过程。

比如本图中,第六行从左至右,显示了图中窗户生成的过程,
与此同时,他们还做了一个有创造性的工作,将向量计算运用在了图像上,得到了如下的一些结果。
比如没有戴眼镜的男人减去不戴眼镜的男人加上不戴眼镜的女人就得到了戴眼镜的女人。
最后,我还运行了一下DCGAN的开源代码,使用MNIST数据库,得到了一些生成的图片。程序运行的比较慢,跑了12个小时,大概进行了8个epoch。
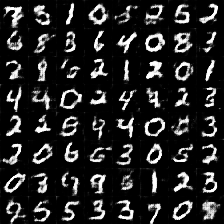
这是训练时第一个epoch中第99次迭代时生成的图片,可见一开始还是比较模糊的。
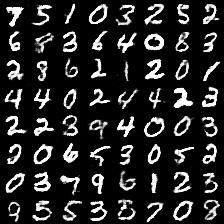
这是第6个epoch中生成的图片,可见已经比较清楚了。
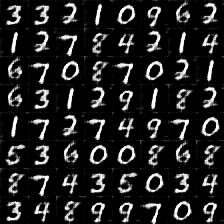
这是使用现有模型测试生成的图片,可见效果还是比较好的,完全看不出是机器生成的。
这篇关于GAN相关工作介绍的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





