本文主要是介绍C语言杂谈:结构体内存对齐,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
#include<stdio.h>
struct S1
{char c1;int i;char c2;
};
struct S2
{char c1;char c2;int i;
};
int main()
{printf("%d\n", sizeof(struct S1));printf("%d\n", sizeof(struct S2));return 0;
}看上面的代码,我们想想应该会输出什么,都是一个整形,两个字符类型。肯定会有说是6字节
的,我们输出来看。

为什么会是12和8呢,这就是谈到结构体在内存中的存储了,即 结构体的内存对齐。
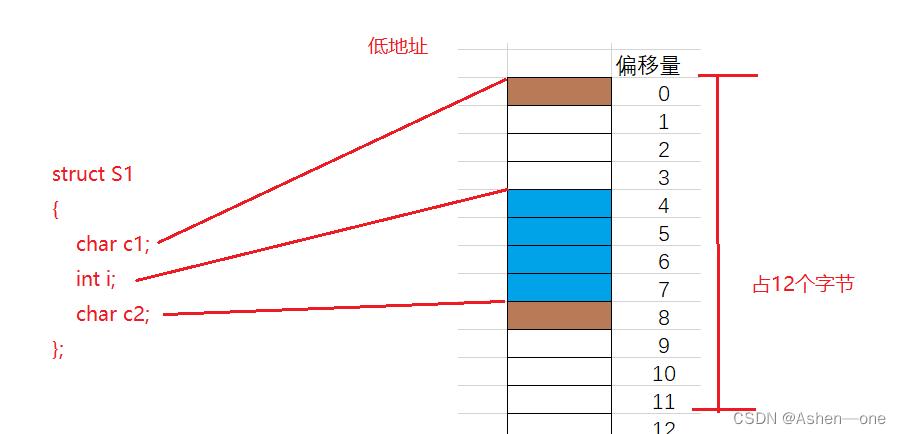
这是s1在内存中存储情况,
我们看到c1存放完后,i并不是紧挨着c1进行存放,而是从偏移量为4的地方开始存储,中间空出三个字节的空间。这就是结构体的内存对齐,下面我们来了解其内存对齐的规则:
1,结构体的第一个成员在与结构体变量偏移量为0的地址处
2,其他成员变量要对齐到某个数字(我们称作对齐数)的整数倍的地址处
3,对齐数=编译器默认的一个对齐数与该变量大小的较小值。vs的默认对齐数为8
4,结构体的总大小为最大对齐数(每个成员变量都有一个对齐数)的整数倍
5,对于嵌套了结构体的情况,嵌套的结构体对齐到自己的最大对齐数的整数倍处,结构体的整体大小就是所有最大对齐数(含嵌套结构体的对齐数)的整数倍。
如何理解这段话呢,
我们需要理解对齐数是怎么找到的
对齐数是当前变量大小和编译器默认对齐数的较小值(以下使用vs对齐数8)
比如我有一个int变量,他比8小,所以对齐数就是1
如果我有int变量,他的对齐数就是4。
知道对齐数之后,我们需要知道他们存储时,偏移量是对齐数的整数倍,
struct stu
{int a;char b;int c;
}我们来看这段代码,先是一个int变量,对齐数是4,直接在偏移量0的地方开始存储,占四个字节
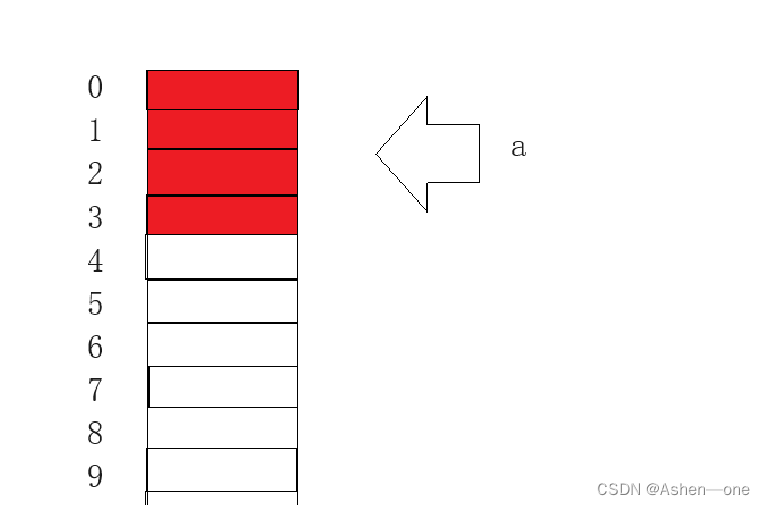
下面是char,对齐数一个字节
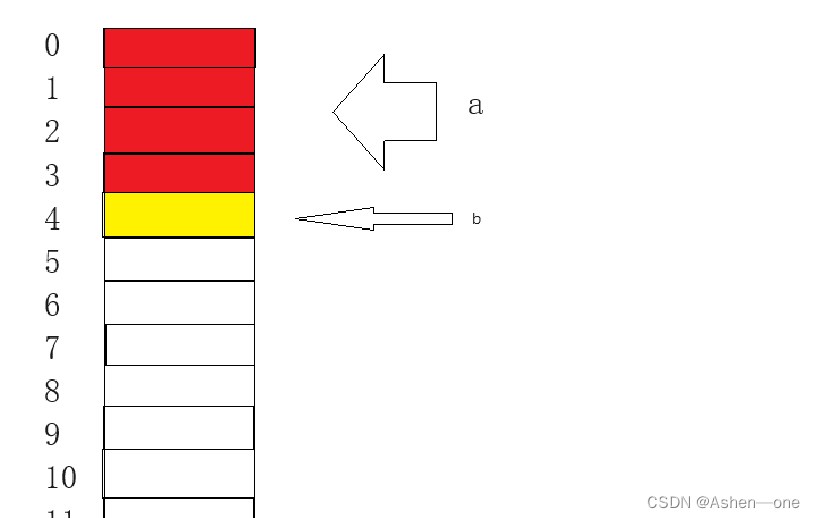
最后是int,偏移量4个字节
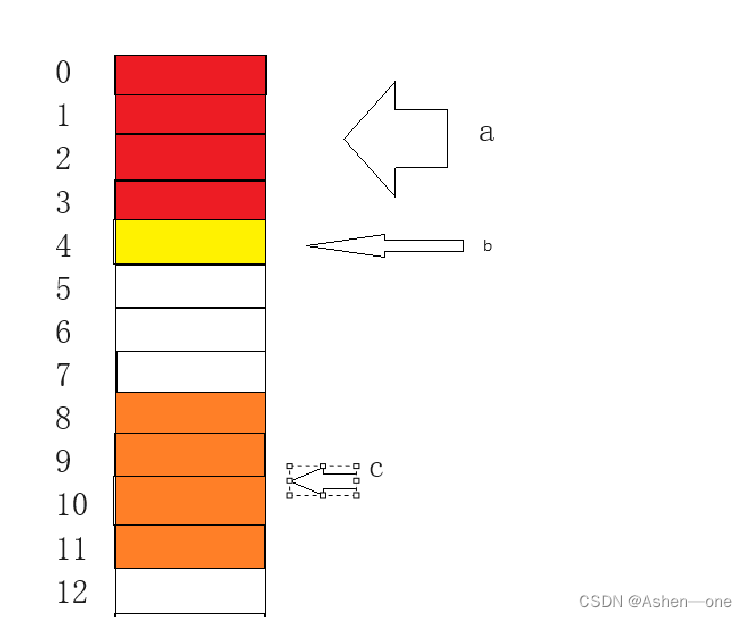
为什么需要偏移到8开始呢,因为前面说过了,偏移量必须是对齐数的整数倍。
C语言给我们提供了offsetof宏来计算结构体成员的偏移量
#include<stddef.h>
#include<stdio.h>
struct S1
{char c1;int i;char c2;
};
struct S2
{char c1;char c2;int i;
};
int main()
{printf("结构体S1中c1的偏移量为%zd\n",offsetof(struct S1,c1 ));printf("结构体S1中i的偏移量为%zd\n", offsetof(struct S1, i));printf("结构体S1中c2的偏移量为%zd\n", offsetof(struct S1, c2));printf("结构体S2中c1的偏移量为%zd\n", offsetof(struct S2, c1));printf("结构体S2中c2的偏移量为%zd\n", offsetof(struct S2, c2));printf("结构体S2中i的偏移量为%zd\n", offsetof(struct S2, i));return 0;

这篇关于C语言杂谈:结构体内存对齐的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!




