本文主要是介绍multiprocessing对僵尸进程的处理,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
关于僵尸进程的相关资料,这篇博客讲的挺透彻的,可以参考进行学习了解。
之所以想写这么一篇博客,是在学TCP/IP网络编程时,讲到多进程服务器的构建时,父进程需要对子进程进行处理,不然的话会产生一堆的僵尸进程,最后会危害整个系统。然后想到我之前写的爬虫,Dwonloader使用的就是多进程的方式来并发下载数据。在Downloader中,我的做法是凑够一定数量的请求,然后开启一个进程,让这个进程去处理这堆请求。而我只开启了进程,并没有去管理这些进程,突然有点心慌慌,这个bug可能会让我的系统崩溃。
代码一
将Downloader的代码抽象出来,会是如下所示:
import multiprocessing as mp
import os
import timedef work():print ("os.pid is ", os.getpid())if __name__ == '__main__':print ("parent ", os.getpid())while True:p = mp.Process(target = work)p.start()time.sleep(1)主进程的while(True)表示源源不断的的请求,其中的sleep是为了不太快产生大量进程,work就是负责处理请求的进程。
代码非常简单,原本以为,这样跑那么一会儿,会产生一大摞的僵尸进程。但查看了系统的进程后,发现如下图所示,并没有产生大量的僵尸进程丫。
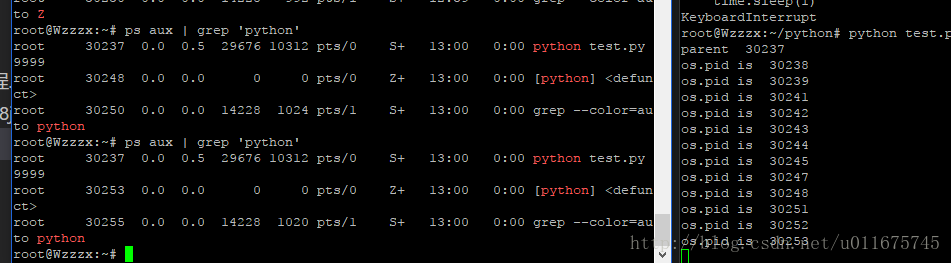
从图中可以看出,每次都仅仅只有一个僵尸进程,再次查看的时候,会发现其已经被解决掉了,换成了另一个僵尸进程。顿时就有点凌乱了。
代码二
所以尝试用C写了另一段代码,如下
#include <stdio.h>
#include <stdlib.h>
#include <signal.h>int main()
{pid_t pid;while (1){pid = fork();if (pid < 0){puts("fock error");exit(1);}else if(pid == 0){printf("I am a Child Process, pid is %d.\n", getpid());sleep(1);exit(1);}elsesleep(3);}return 0;
}这段代码却能够产生一大堆的僵尸进程,如下图所示:
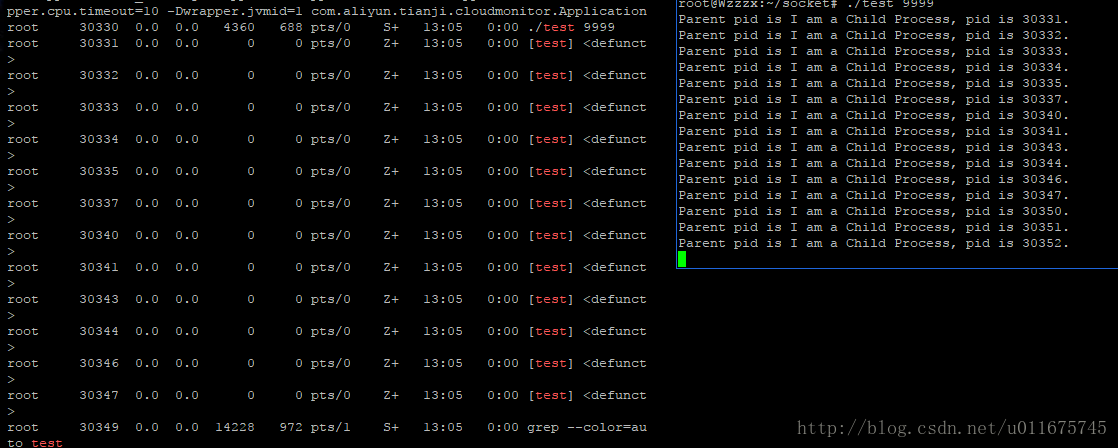
如图,可以发现确实是产生了大量的僵尸代码。
代码三
所以初步我是怀疑python会自动的对僵尸进程进行清理,所以就顺手又写了下面的代码。然而问题又出乎我的意料。
from multiprocessing import Process
import os
import timedef run():print ("pid is ", os.getpid())p = Process(target = run)
p.start()
time.sleep(100)这段代码,产生了一个僵尸进程,一直卡在那里,并没有被清理掉。如下图:

原因
这个问题困扰了我一天,然后放到segmentfault上问了下,也算是找到了正确答案,所以在此记录下来。
结论是,multiprocessing确实会自动的对僵尸进程进行处理,python真的就是方便,很多细节的东西各种第三方的库就已经帮你考虑好了,我们只需要去解决逻辑问题就可以了。
Process这个类继承于BaseProcess,该文件位于Lib\multiprocessing\process.py.
子进程的start方法代码如下
_children = set()def start(self):'''Start child process'''assert self._popen is None, 'cannot start a process twice'assert self._parent_pid == os.getpid(), \'can only start a process object created by current process'assert not _current_process._config.get('daemon'), \'daemonic processes are not allowed to have children'_cleanup()self._popen = self._Popen(self)self._sentinel = self._popen.sentinel_children.add(self)代码中的_children是一个集合,其中包含的就是父进程所产生的子进程集合,保存着所有BaseProcess实例,该函数最后的_children.add(self)将当前进程对方(即所创建的子进程)添加到集合中。
注意到其中的_cleanup()函数,这个函数就是用于清理僵尸进程的关键函数了。
def _cleanup():# check for processes which have finishedfor p in list(_children):if p._popen.poll() is not None:_children.discard(p)初步看这个函数,实现非常的简单。刚开始看这个函数的时候,感觉仅仅是将该子进程从子进程集合中删去,并没有对其进行处理工作。后来在回答者的提示下找到了原因,处理的工作是在poll函数中进行的,处理完了再将其删除。
所以我们找到multiprossing/popen_fork.py这个问题,该文件中的Popen有着该函数的实现,代码如下:
def poll(self, flag=os.WNOHANG):if self.returncode is None:while True:try:pid, sts = os.waitpid(self.pid, flag)except OSError as e:# Child process not yet created. See #1731717# e.errno == errno.ECHILD == 10return Noneelse:breakif pid == self.pid:#如果进程由于信号而退出,则返回True,否则返回False。if os.WIFSIGNALED(sts):# 返回导致进程退出的信号,这里不是很理解为什么要返回一个相反数self.returncode = -os.WTERMSIG(sts)else:#如果进程是以exit()方式退出的,则返回True,否则返回False。assert os.WIFEXITED(sts)#返回exit退出时候的调用的参数,否则返回值是未定义的self.returncode = os.WEXITSTATUS(sts)return self.returncode其中关于python中os模块的各类参数作用,可以参考这篇博客,讲的也是比较透彻清楚。
对于_children中的每一个进程,都会调用该函数进行处理。在该函数的pid, sts = os.waitpid(self.pid, flag),因为flag设置为os.WNOHANG,所以会不阻塞的判断该进程时候已经死亡。如果该进程没死亡,直接就返回一个None。否则会返回其返回码。但是该返回码在我们这里并没有什么太大价值,我们知道其已经死亡就可以。
剩余问题
对于该问题,目前来看应该是全部解决了。但是不小心将代码二的代码改成如下所示
from multiprocessing import Process
import os
import timedef run():print ("pid is ", os.getpid())print ("parent pid is ", os.getpid())
p = Process(target = run)
p.start()
time.sleep(3)
p1 = Process(target = run)
p1.start()
time.sleep(3)
p2 = Process(target = run)
p2.start()
time.sleep(3)
time.sleep(100)如果调用子进程后不使用sleep函数,最后会得到三个僵尸进程,但是调用了sleep,前两个僵尸进程都会被清理,剩下最后一个子进程成为僵尸进程。
这个问题我觉得应该跟sleep的实现方式有关,所以有空自己再去看看源代码,看看能不能折腾出结果吧
这篇关于multiprocessing对僵尸进程的处理的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






