本文主要是介绍C语言 | Leetcode C语言题解之第148题排序链表,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
题目:
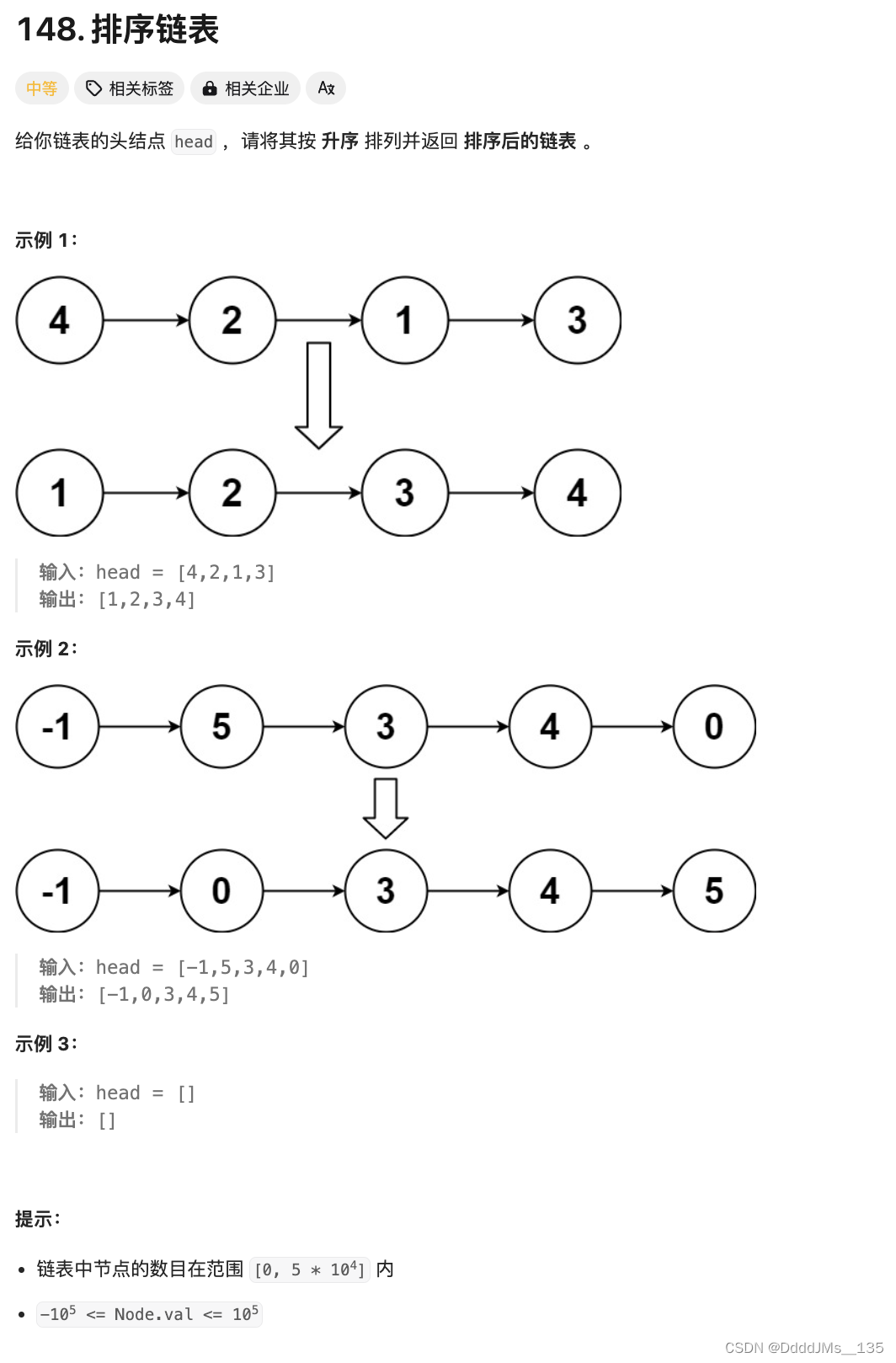
题解:
struct ListNode* merge(struct ListNode* head1, struct ListNode* head2) {struct ListNode* dummyHead = malloc(sizeof(struct ListNode));dummyHead->val = 0;struct ListNode *temp = dummyHead, *temp1 = head1, *temp2 = head2;while (temp1 != NULL && temp2 != NULL) {if (temp1->val <= temp2->val) {temp->next = temp1;temp1 = temp1->next;} else {temp->next = temp2;temp2 = temp2->next;}temp = temp->next;}if (temp1 != NULL) {temp->next = temp1;} else if (temp2 != NULL) {temp->next = temp2;}return dummyHead->next;
}struct ListNode* sortList(struct ListNode* head) {if (head == NULL) {return head;}int length = 0;struct ListNode* node = head;while (node != NULL) {length++;node = node->next;}struct ListNode* dummyHead = malloc(sizeof(struct ListNode));dummyHead->next = head;for (int subLength = 1; subLength < length; subLength <<= 1) {struct ListNode *prev = dummyHead, *curr = dummyHead->next;while (curr != NULL) {struct ListNode* head1 = curr;for (int i = 1; i < subLength && curr->next != NULL; i++) {curr = curr->next;}struct ListNode* head2 = curr->next;curr->next = NULL;curr = head2;for (int i = 1; i < subLength && curr != NULL && curr->next != NULL;i++) {curr = curr->next;}struct ListNode* next = NULL;if (curr != NULL) {next = curr->next;curr->next = NULL;}struct ListNode* merged = merge(head1, head2);prev->next = merged;while (prev->next != NULL) {prev = prev->next;}curr = next;}}return dummyHead->next;
}
这篇关于C语言 | Leetcode C语言题解之第148题排序链表的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!




