本文主要是介绍【Linux文件篇】磁盘到用户空间:Linux文件系统架构全景,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!

W...Y的主页 😊
代码仓库分享 💕

前言:我们前面的博客中一直提到的是被进程打开的文件,而系统中不仅仅只有被打开的文件还有很多没被打开的文件。如果没有被打开,那么文件是在哪里进行保存的呢?那我们又如何快速定位一个文件的具体位置呢?话不多说,开始我们今天的旅程。
磁盘
说到文件的存储,我们先来了解一下磁盘的构成。
磁盘的机械构成

磁盘是计算机存储设备的一种,它用于存储和读取数据。磁盘的机械构成主要包括以下几个部分:
1. 盘片(Platter):这是磁盘的主要部分,通常由铝或其他磁性材料制成。数据以磁性形式存储在盘片上。现代硬盘驱动器(HDD)通常包含多个盘片,它们被堆叠在一起。
2. 读写头(Read/Write Head):这些是用于读取和写入数据到磁盘表面的精密设备。每个盘片的每个面都有一个读写头,它们悬浮在盘片上方非常微小的距离上。
3. 磁头臂(Actuator Arm):这是连接读写头和驱动器主体的机械臂。当数据被请求时,磁头臂会移动读写头到正确的盘片位置。
4. 主轴(Spindle):这是盘片中心的轴,盘片固定在主轴上并随其旋转。主轴的旋转速度通常以每分钟转数(RPM)来衡量,常见的转速有5400 RPM、7200 RPM等。
5. 电机(Motor):电机用于驱动主轴旋转,使盘片旋转到所需的速度。
6. 控制电路板(Control Circuit Board):这是硬盘的电子部分,包含用于控制磁盘操作的微处理器和接口电路。它负责协调读写头的位置、数据传输和与计算机的通信。
7. 外壳(Enclosure):这是硬盘的外部结构,用于保护内部组件免受物理损害。
8. 缓存(Cache):硬盘可能包含一个小型的快速存储器,称为缓存,用于临时存储频繁访问的数据,以提高性能。
9. 接口(Interface):这是硬盘与计算机其他部分通信的接口,常见的接口类型有SATA、SAS等。
硬盘的工作原理是通过电机驱动盘片旋转,磁头臂移动读写头到正确的盘片位置,然后读写头通过改变盘片表面的磁性来存储或读取数据。这个过程需要非常精密的机械协调和电子控制。随着技术的发展,固态硬盘(SSD)逐渐取代了传统的机械硬盘,因为它们没有移动部件,读写速度更快,耐用性更高。
磁盘的物理存储

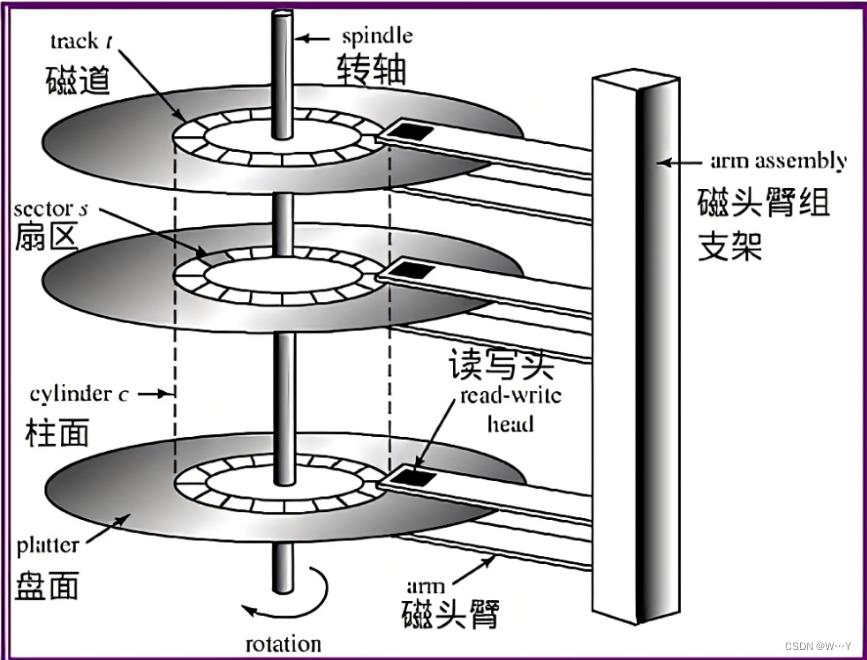
磁盘的物理存储主要是指硬盘驱动器(HDD)中数据的物理存储方式。
盘片(Platter):硬盘驱动器包含一个或多个圆形的盘片,这些盘片通常由铝、玻璃或陶瓷材料制成,并覆盖有磁性涂层。数据以磁性的方式存储在盘片上。
磁性颗粒(Magnetic Particles):盘片上的磁性涂层由数以亿计的微小磁性颗粒组成。这些颗粒可以被磁化成两种不同的状态,通常表示二进制数据的0和1。
磁道(Track):数据在盘片上以同心圆的形式存储,每个同心圆称为一个磁道。磁道是数据存储的物理路径。
扇区(Sector):磁道被进一步划分为更小的单元,称为扇区。扇区是数据存储的基本单元,通常大小为512字节或4096字节(在现代硬盘中)。
读写头(Read/Write Head):硬盘驱动器的每个盘片面都有一个读写头,用于读取或写入数据。读写头通过电磁场的变化来检测或改变盘片上的磁性颗粒状态。
磁头臂(Actuator Arm):读写头安装在磁头臂上,磁头臂可以移动读写头到盘片上的不同位置,以便访问不同的磁道。
伺服系统(Servo System):硬盘驱动器使用伺服系统来精确控制磁头臂的位置,确保读写头能够准确地定位到正确的磁道和扇区。
旋转速度(Rotational Speed):盘片的旋转速度影响数据访问速度。转速以每分钟转数(RPM)来衡量,常见的转速有5400 RPM、7200 RPM等。
硬盘驱动器的物理存储方式依赖于磁头和盘片的精确协调。数据的读写是通过改变磁性颗粒的极性来实现的。
虽然说一个磁盘是一个圆形的物体,但是在上面存储的数据并不是杂乱无章的。其实磁盘上有很多同心圆——也叫磁道。而同心圆中的一小段被称作扇区,是磁盘IO的基本单位,但不一定是系统的基本单位,一般情况下大小为4kb或521字节。虽然扇区的面积不同,但是可以通过密度的调整让其扇区的大小都是一样的。
扇区、磁头、盘面、磁道都有自己的唯一编号,所以我们想要访问一个具体的扇区,首先我们先通过磁头定位到哪一个磁道/柱面,然后确认使用哪一个磁头进行读取(本质就是使用哪一个盘面),最后确认到哪一个扇区。这种在硬件层面上定位一个扇区被我们称为——CHS定位法。
磁盘的逻辑存储
磁带我们想必都见过,小学时使用的英语听力一般使用的就是磁带。磁带存储内容就是我们下图所看到的长条。当我们将磁带拉直像不像我们所学的一种数据结构——线性表。
 我们通过磁带来类比磁盘,如果我们将一个个扇区看作一段空间,将他们全部拼接起来不也就是线性表吗!假设一个磁盘有800GB内存,一个扇区所占空间是512字节,那么我们就可以看到下图:
我们通过磁带来类比磁盘,如果我们将一个个扇区看作一段空间,将他们全部拼接起来不也就是线性表吗!假设一个磁盘有800GB内存,一个扇区所占空间是512字节,那么我们就可以看到下图:

所以我们对磁盘的管理,也就变成了对数组的增删查改!!!
但操作系统觉得一个扇区512字节太小,因为磁盘是一个硬件而硬件的速度是很慢的,磁盘IO太麻烦,所以OS就将文件IO定在4KB。操作系统会选择连续的8个扇区作为数据块,这样操作系统又会形成一个数组,大小为4kb的数据块。

这样的操作系统也可以将自己的IO转换到磁盘中,4kb等于8个512字节,所以当数据块下标为1时,想要对应磁盘中的扇区只需要,1*8 + [0,1,2,3,4,5,6,7]即可一一对应。我们只需要知道起始扇区+偏移量就可以做到对应。
所以从此往后整个磁盘不会以扇区作为单位,而是以数据块作为单位,我们将数据块的下标叫做LBA地址。
系统对内容的管理
我们都见过Windows中的C盘D盘E盘等等,为什么要分这么多盘呢?因为系统要对我们的内存进行管理,如果800GB放一个盘中会比较大,不好进行管理,而且分盘可以对电脑的性能提升。所以我们要分区/分盘管理,Linux下也是如此。

分盘管理是将大的空间进行缩小化,磁盘的管理方式都是类似相同的,所以我们要把512GB内存管理好从而就进化到管理好256GB内存即可。但是256GB还是有些大,这时操作系统就会做一些我们看不到的事情——分组。
将256GB内存分成10GB左右更小的内存进行管理,这样我们的问题从如何管理好256GB转移到如何管理好10GB内存了。
作系统中的内存分组是指操作系统将内存划分成多个逻辑组或分区,以便于更有效地管理内存资源。内存分组可以基于不同的标准,例如用途、访问频率、安全性等。
代码区:存储程序的指令代码,通常被设置为只读,以防止程序代码被意外或恶意修改。
数据区:用于存储程序运行时的数据,包括全局变量和局部变量等。
堆栈区:每个线程或进程都有自己的堆栈,用于存储函数调用的参数、局部变量和返回地址。
堆区:动态内存分配区域,程序在运行时可以申请和释放内存。
内核区:操作系统内核代码和数据结构的存储区域,通常与用户空间隔离,以提高安全性。
缓存区:用于存储频繁访问的数据,以提高访问速度。
I/O缓冲区:用于临时存储输入输出操作的数据,可以减少I/O操作的延迟。
虚拟内存区:当物理内存不足时,操作系统可以使用硬盘空间作为虚拟内存,通过页面置换算法管理内存。
共享内存区:允许多个进程共享同一块内存区域,用于进程间通信。
保护模式:在某些操作系统中,内存分组还包括不同的保护级别,以确保进程不能访问不属于它们的内存区域。
内存分组的好处包括:
- 提高安全性:通过隔离不同区域的内存,防止恶意程序访问或修改其他程序的内存。
- 优化性能:通过合理分配内存资源,可以减少内存碎片,提高内存访问速度。
- 便于管理:分组管理使得操作系统更容易跟踪内存使用情况,简化内存分配和回收的过程。
- 支持多任务处理:允许多个任务同时运行,每个任务都有自己的内存空间,提高了系统的多任务处理能力。
- 提高可靠性:当一个程序崩溃时,分组管理可以限制错误的影响范围,减少系统崩溃的风险。
内存分组是操作系统内存管理的一个重要方面,它有助于提高系统的稳定性、安全性和效率。
那问题又来了,操作系统如何管理好分组中的内存呢?
理解文件系统
我们使用ls -l的时候看到的除了看到文件名,还看到了文件元数据。
[root@localhost linux]# ls -l
总用量 12
-rwxr-xr-x. 1 root root 7438 "9月 13 14:56" a.out
-rw-r--r--. 1 root root 654 "9月 13 14:56" test.c每行包含7列:
模式
硬链接数
文件所有者
组
大小
最后修改时间文件名
ls -l读取存储在磁盘上的文件信息,然后显示出来
其实这个信息除了通过这种方式来读取,还有一个stat命令能够看到更多信息
[root@localhost linux]# stat test.c
File: "test.c"
Size: 654 Blocks: 8 IO Block: 4096 普通文件
Device: 802h/2050d Inode: 263715 Links: 1
Access: (0644/-rw-r--r--) Uid: ( 0/ root) Gid: ( 0/ root)
Access: 2017-09-13 14:56:57.059012947 +0800
Modify: 2017-09-13 14:56:40.067012944 +0800
Change: 2017-09-13 14:56:40.069012948 +0800系统文件 = 属性 + 内容,那内容是可大可小的但是属性都是固定大小,他们被放在一个struct inode的结构体中进行存储,只能说他们的属性内容不同,但是大小一定是相同的,在Linux操作系统下规定固定大小为128字节。所以文件的属性和内容就要分开进行存储。
我们又回到刚才的问题,10GB的内容我们要怎么样管理?我们先来看一张图:

Linux ext2文件系统,上图为磁盘文件系统图(内核内存映像肯定有所不同),磁盘是典型的块设备,硬盘分组被划分为一个个的block。一个block的大小是由格式化的时候确定的,并且不可以更改。例如mke2fs的-b选项可以设定block大小为1024、2048或4096字节。而上图中启动块(Boot Block)的大小是确定的。
而在系统中标识一个文件用的不是其文件名,而是其inode。
那我们就来认识一下文件系统图中的各个区域的含义:
Block Group:ext2文件系统会根据分区的大小划分为数个Block Group。而每个Block Group都有着相同的结构组成。政府管理各区的例子
i节点表(inode table):存放文件属性 如 文件大小,所有者,最近修改时间等。
inode位图(inode Bitmap):每个bit表示一个inode是否空闲可用。比特位的位置:第几个inode。比特位的内容:表示该inode是否被使用。
数据区(data blocks):存放文件内容。我们可以想象成数据区中是一个特别大的内存,内存中有非常多的4kb数据块,当我们想要存放数据时无非就是数据库使用的多少问题。
块位图(Block Bitmap):Block Bitmap中记录着Data Block中哪个数据块已经被占用,哪个数据块没有被占用。比特位的位置:第几个数据块。比特位的内容:表示该数据块是否被使用。
那inode属性区怎么与block数据区进行关联呢?在属性结构体struct inode中有一个数组,数组中存放的就是这个文件在数据区中使用数据块的下标。所以无论是内容还是属性,只要找到inode就可以将全部信息获取到。而我们删除一个文件的内容,不会去删除inode table 与data blocks中的内容,只会删除位图中的内容,让后面来的文件进行覆盖即可。
inode是在整个分区内唯一的,而想要寻找一个文件的inode首先我们得确认在哪个分组中。每个分区中都有其起始编号和终止编号,我们只需要将inode进行范围比较即可确认在哪个分组中。然后再减去分组中的起始编号后就可以得到inode table。
现在又有一个问题,inode table中存放文件的属性,而文件的属性中又有一个block[15]数组用来存放数据块的下标,但是有的文件是非常大的15个位置15个数据块是不够的,那怎么办?实际上block数组中0~11是直接保存的数据块的编号,而12~13并不是保存数据块的编号而是保存其他数据块的编号,其他数据块是内容。而14保存的是其他数据块的编号,其他数据块也是指向更多的数据块编号。这样我们就可以存储非常大的文件编号了。
GDT,Group Descriptor Table:块组描述符,描述块组属性信息。
即全局描述符表(Global Descriptor Table),是x86架构的CPU中用于定义不同内存段的一块内存区域。GDT是操作系统用来实现内存保护、分页和多任务处理的关键组成部分。每个条目(Descriptor)在GDT中定义了一个内存段的属性,包括段的基地址、大小、访问权限等。
所以GDT是对一个块组整体做管理的管理数据结构。描述了起始LBA是多少、起始inode编号是多少、一共有多少个inode多少个数据块、已经使用了多少个inode和数据块、下一次怎么分配等等信息。
超级块(Super Block):存放文件系统本身的结构信息。记录的信息主要有:bolck 和 inode的总量,未使用的block和inode的数量,一个block和inode的大小,最近一次挂载的时间,最近一次写入数据的时间,最近一次检验磁盘的时间等其他文件系统的相关信息。Super Block的信息被破坏,可以说整个文件系统结构就被破坏了。整个分区是由super block进行管理的。而GDT是管理分区中的一个分组的数据结构。
还有一个Boot Block一般是在第一个分区才有,它是和开机有关系的。当开机时我们首先要识别磁盘,才可以将操作系统加载到内存中。我们可以简单理解为,了解整个磁盘的分区情况并且告诉操作系统在哪个分区中。
而这些文件信息不是在我们分区后就有的,而是在格式化后进行写入的。
我们可以在分区中写入相同或者不同的文件系统,以上的文件系统属于Ext*(2),现在我们用到的一般是Ext*(3)以上,但是核心原理是不变的。
文件系统中最核心的就是super block,所以操作系统在管理文件时就可以将每一个分组的super block加载到内存中建立一个数据结构进行管理,所以对文件的管理就进而转化成对super block的z增删查改工作。
现在我们已经知道文件系统的底层逻辑后,我们创建一个文件的逻辑是什么呢?

1. 存储属性
内核先找到一个空闲的i节点(这里是263466)。内核把文件信息记录到其中。
2. 存储数据
该文件需要存储在三个磁盘块,内核找到了三个空闲块:300,500,800。将内核缓冲区的第一块数据
复制到300,下一块复制到500,以此类推。
3. 记录分配情况
文件内容按顺序300,500,800存放。内核在inode上的磁盘分布区记录了上述块列表。
4. 添加文件名到目录
新的文件名abc。linux如何在当前的目录中记录这个文件?内核将入口(263466,abc)添加到目录文件。文件名和inode之间的对应关系将文件名和文件的内容及属性连接起来。
因为目录也算文件,而任何一个文件都在目录中,那目录文件中就存放文件名和inode编号的映射关系,如果目录文件中没有写权限,我们就不能在目录中创建新的文件,因为它要修改目录文件内容。而差一个目录的内容都是从根目录开始的,因为它是从前一个目录中进行查找目录内容的,所以是逆向递归查找的。
一个inode是在一个分区中是唯一的,但是不知道其在哪一个分区。所以这时候我们的路径就出马了。一个文件写入文件系统的分区,要被Linux使用,必须要先把具有系统文件的分区进行“挂载”。一个文件系统所对应的分区挂载到对应的目录中我们才可以访问。所以分区的访问就是所挂载路径的访问。这里我们不讲什么是挂载,有兴趣的可以自己去学习以及mount指令。
以上就是我们本次的全部内容,感谢大家观看!!!
这篇关于【Linux文件篇】磁盘到用户空间:Linux文件系统架构全景的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!







