本文主要是介绍《一头扎进》系列之Python+Selenium框架设计篇24 - 价值好几K的框架,哎呦!这个框架还真有点料啊!!!,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
宏哥微信粉丝群:https://bbs.csdn.net/topics/618423372 有兴趣的可以扫码加入
1. 简介
其实,到前面这一篇文章,简单的Python+Selenium自动化测试框架就已经算实现了。接下来的主要是介绍,unittest管理脚本,如何如何加载执行脚本,再就是采用第三方插件,实现输出html的测试报告。本文来介绍下,在同一个类中,多个测试函数时候,测试固件如何写和进一步实现POM和可能遇到问题解决办法。
2. 一个类文件多个测试方法情况下测试固件的写法
为了说明这个问题,我们在之前的测试类基础上,再写一个test_search2()的测试用例,看看会发生什么。
2.1 代码实现:
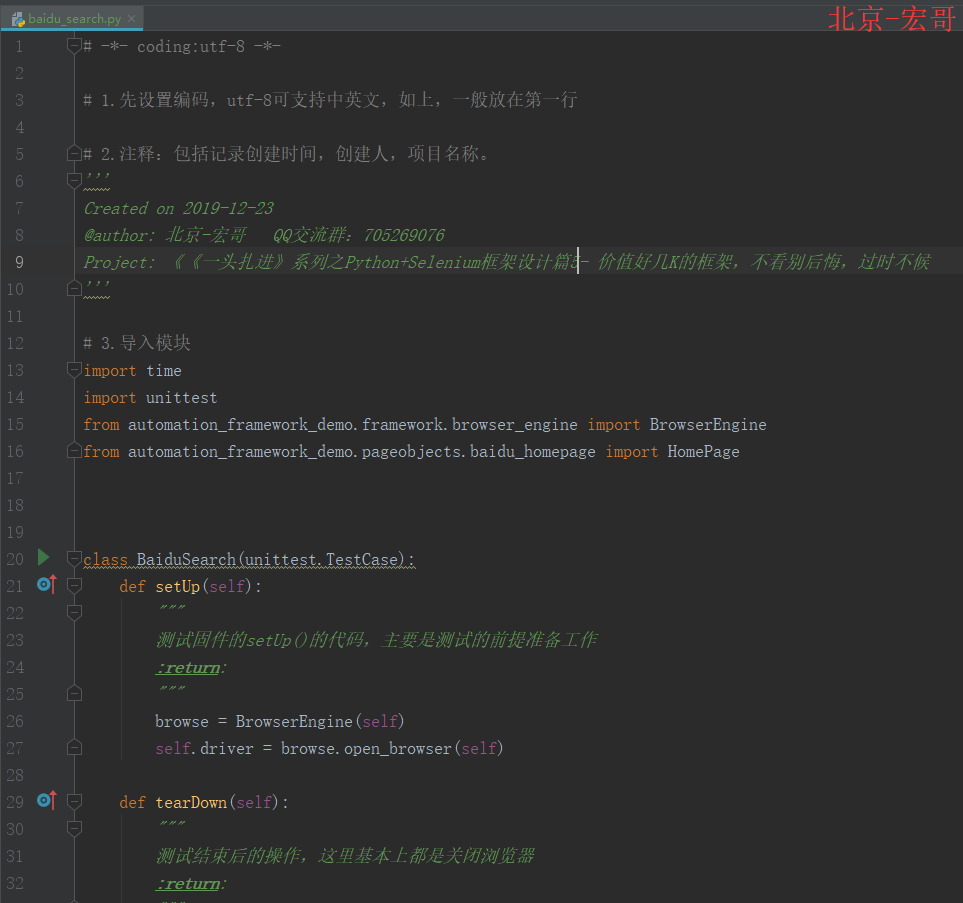
2.2 参考代码:
# -*- coding:utf-8 -*-# 1.先设置编码,utf-8可支持中英文,如上,一般放在第一行# 2.注释:包括记录创建时间,创建人,项目名称。
'''
Created on 2019-12-23
@author: 北京-宏哥 QQ交流群:260612819
@公众号:北京宏哥(微信搜索,关注宏哥提示解锁更多测试干货)
Project: 《《一头扎进》系列之Python+Selenium框架设计篇5- 价值好几K的框架,不看别后悔,过时不候
'''# 3.导入模块
import time
import unittest
from automation_framework_demo.framework.browser_engine import BrowserEngine
from automation_framework_demo.pageobjects.baidu_homepage import HomePageclass BaiduSearch(unittest.TestCase):def setUp(self):"""测试固件的setUp()的代码,主要是测试的前提准备工作:return:"""browse = BrowserEngine(self)self.driver = browse.open_browser(self)def tearDown(self):"""测试结束后的操作,这里基本上都是关闭浏览器:return:"""self.driver.quit()def test_baidu_search(self):"""这里一定要test开头,把测试逻辑代码封装到一个test开头的方法里。:return:"""homepage = HomePage(self.driver)homepage.type_search('selenium') # 调用页面对象中的方法homepage.send_submit_btn() # 调用页面对象类中的点击搜索按钮方法time.sleep(2)homepage.get_windows_img() # 调用基类截图方法try:assert 'selenium' in homepage.get_page_title() # 调用页面对象继承基类中的获取页面标题方法print('Test Pass.')except Exception as e:print('Test Fail.', format(e))def test_search2(self):homepage = HomePage(self.driver)homepage.type_search('python') # 调用页面对象中的方法homepage.send_submit_btn() # 调用页面对象类中的点击搜索按钮方法time.sleep(2)homepage.get_windows_img() # 调用基类截图方法if __name__ == '__main__':unittest.main()
2.3 运行结果:
运行代码后,控制台打印如下图的结果

问题发现了没,我们的浏览器启动和关闭了两次,是不是这个问题?其实细心地小伙伴或者童鞋们在上一篇文章里就可能发现这个问题了,由于时间的关系宏哥在这里把它单独拿出来分享讲解一下,希望可以加深小伙伴或者童鞋们的印象。问题是原来每执行一次
test开头的函数,都要执行一次测试固件,也就是说执行setUp()和()一次,如果有N个test开头的函数,测试固件就执行N次,我们到底有没有,只需要执行一次测试固件,支持执行多次测试函数。
我们测试中,肯定需要,打开一个页面,然后测试这个页面的多个用例,才关闭这个页面,去测试其他页面,在unittest是有相关测试固件方法去支持这种行为。请看下面调整,自己对比下,能不能找出不同。
2.4 代码实现:
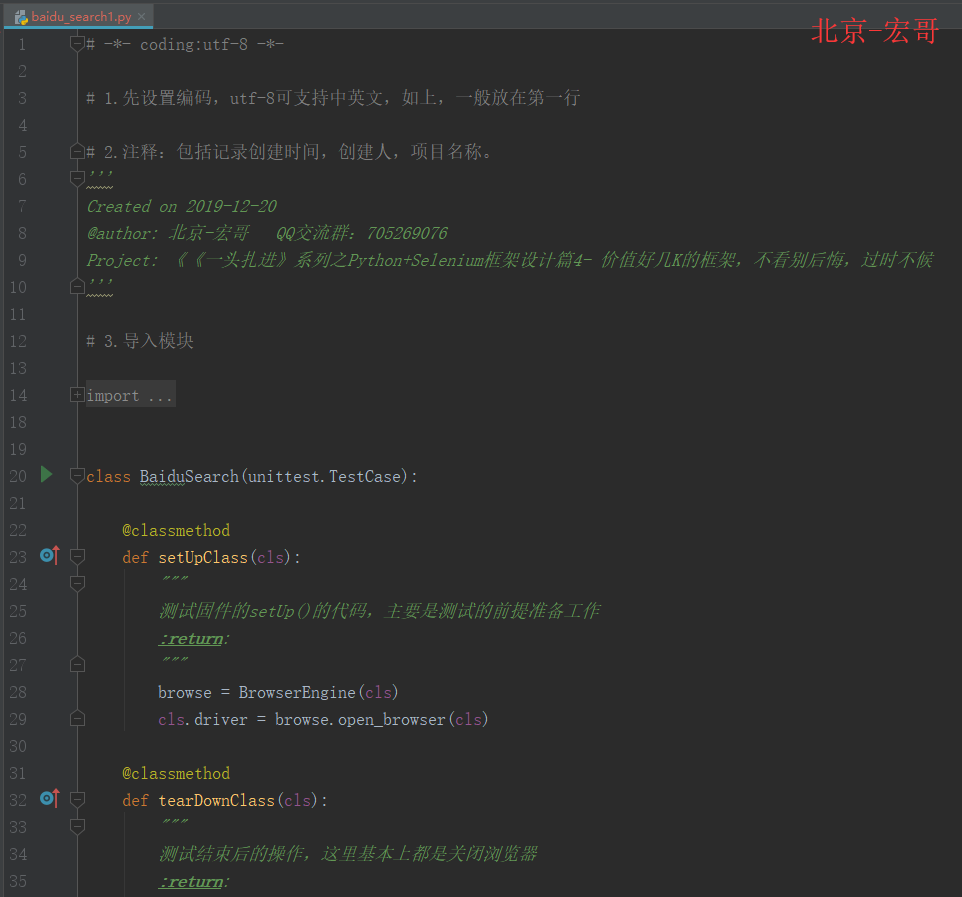
2.5 参考代码:
# -*- coding:utf-8 -*-# 1.先设置编码,utf-8可支持中英文,如上,一般放在第一行# 2.注释:包括记录创建时间,创建人,项目名称。
'''
Created on 2019-12-20
@author: 北京-宏哥 QQ交流群:260612819
@公众号:北京宏哥(微信搜索,关注宏哥提示解锁更多测试干货)
Project: 《《一头扎进》系列之Python+Selenium框架设计篇4- 价值好几K的框架,不看别后悔,过时不候
'''# 3.导入模块import time
import unittest
from automation_framework_demo.framework.browser_engine import BrowserEngine
from automation_framework_demo.pageobjects.baidu_homepage import HomePageclass BaiduSearch(unittest.TestCase):@classmethoddef setUpClass(cls):"""测试固件的setUp()的代码,主要是测试的前提准备工作:return:"""browse = BrowserEngine(cls)cls.driver = browse.open_browser(cls)@classmethoddef tearDownClass(cls):"""测试结束后的操作,这里基本上都是关闭浏览器:return:"""cls.driver.quit()def test_baidu_search(self):"""这里一定要test开头,把测试逻辑代码封装到一个test开头的方法里。:return:"""# self.driver.find_element_by_id('kw').send_keys('selenium')# time.sleep(1)homepage = HomePage(self.driver)homepage.type_search('selenium') # 调用页面对象中的方法time.sleep(12)homepage.send_submit_btn() # 调用页面对象类中的点击搜索按钮方法time.sleep(12)homepage.get_windows_img() # 调用基类截图方法print(self.driver.title)try:assert('selenium' in HomePage.get_page_title(self))print('Test Pass.')except Exception as e:print('Test Fail.', format(e))def test_search2(self):homepage = HomePage(self.driver)homepage.type_search('python') # 调用页面对象中的方法homepage.send_submit_btn() # 调用页面对象类中的点击搜索按钮方法time.sleep(2)homepage.get_windows_img() # 调用基类截图方法if __name__ == '__main__':unittest.main()
2.6 运行结果:
运行代码后,控制台打印如下图的结果
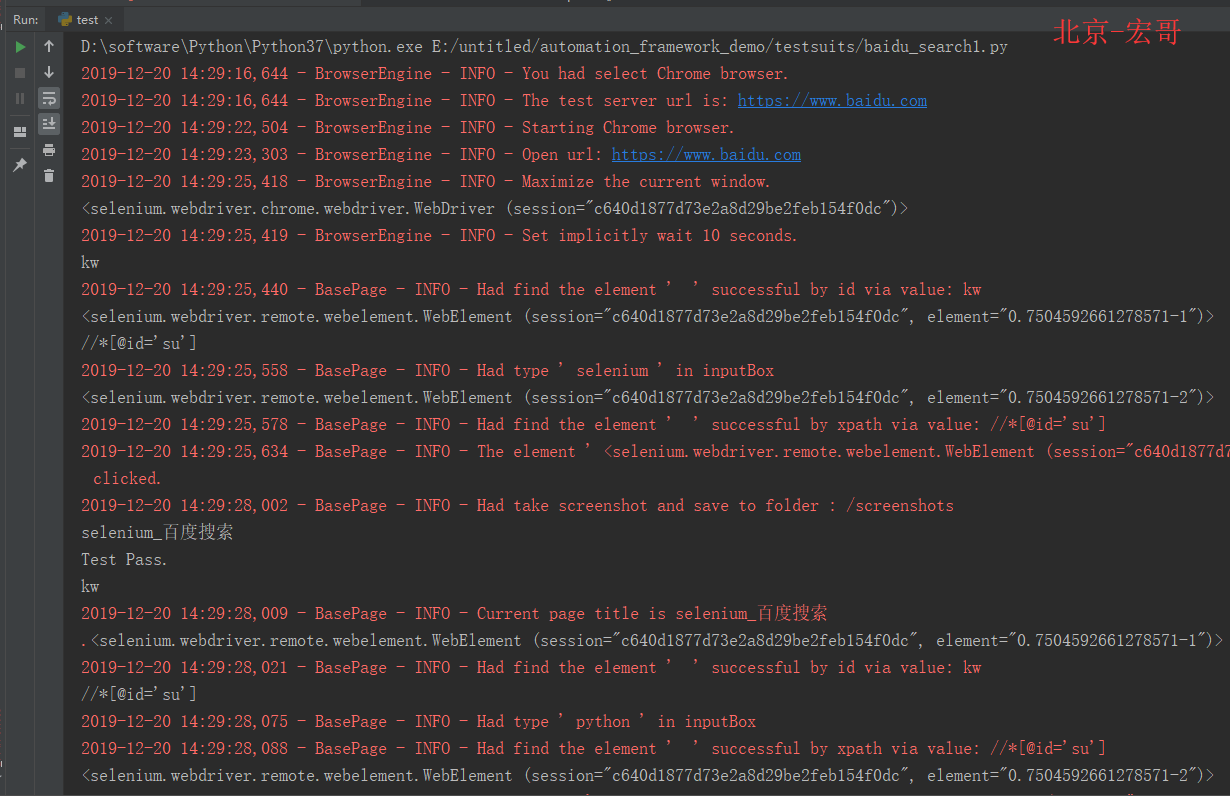
运行一下,是不是,只需要打开和关闭浏览器一次,就执行了2个搜索用例?以后,项目中基本采用这种方法来执行同一个功能不同测试用例的编写。
3. 进一步实现POM
本小节宏哥将会进一步演示POM的具体实现,前面POM只是一个页面,一个测试脚本,现在我们要实现三个页面,两个测试脚本。在pageobjects包下,我新建了2个页面对象:百度新闻首页,百度体育新闻首页,具体文件结构如下图,其他和之前项目层级结构保持不变。

1. 百度首页页面类代码(baidu_homepage.py),定义了百度新闻的入口
3.1 代码实现:

3.2 参考代码:
# -*- coding:utf-8 -*-# 1.先设置编码,utf-8可支持中英文,如上,一般放在第一行# 2.注释:包括记录创建时间,创建人,项目名称。 ''' Created on 2019-12-23 @author: 北京-宏哥 QQ交流群:260612819 @公众号:北京宏哥(微信搜索,关注宏哥提示解锁更多测试干货) Project: 《《一头扎进》系列之Python+Selenium框架设计篇5- 价值好几K的框架,不看别后悔,过时不候 ''' # 3.导入模块from automation_framework_demo.framework.base_page import BasePageclass HomePage(BasePage):input_box = "id=>kw"search_submit_btn = "xpath=>//*[@id='su']"#百度新闻入口#news_link = "xpath=>//*[@id='u1']/a[@name='tj_trnews']"news_link = "xpath=>//*[@id='u1']/a[@name='tj_trnews']"def type_search(self, text):self.type(self.input_box, text)def send_submit_btn(self):self.click(self.search_submit_btn)def click_news(self,):self.click(self.news_link)self.sleep(2)
2. 百度新闻首页的页面类代码(baidu_news_home.py),定义了体育新闻入口
3.3 代码实现:
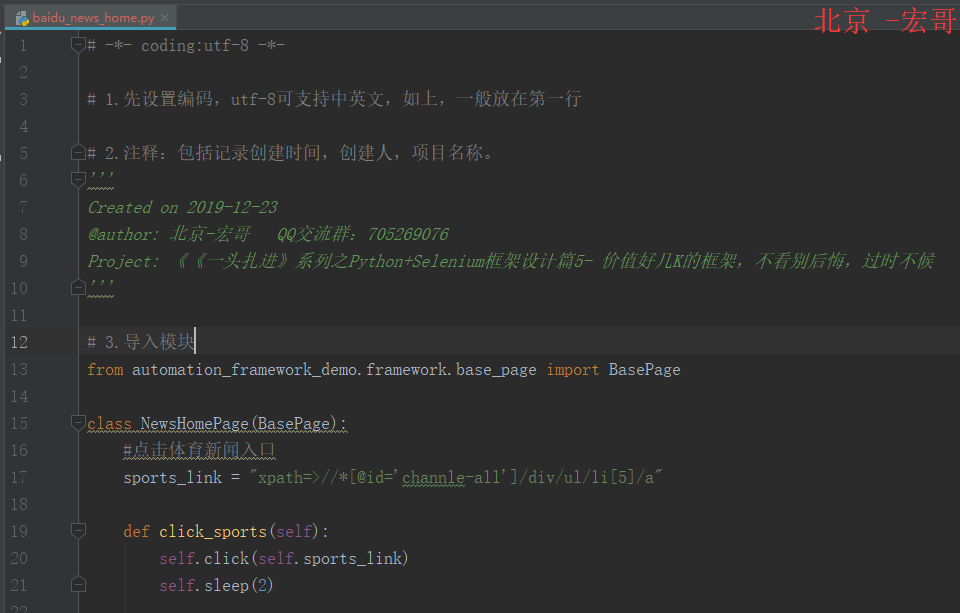
3.4 参考代码:
# -*- coding:utf-8 -*-# 1.先设置编码,utf-8可支持中英文,如上,一般放在第一行# 2.注释:包括记录创建时间,创建人,项目名称。 ''' Created on 2019-12-23 @author: 北京-宏哥 QQ交流群:260612819 @公众号:北京宏哥(微信搜索,关注宏哥提示解锁更多测试干货) Project: 《《一头扎进》系列之Python+Selenium框架设计篇5- 价值好几K的框架,不看别后悔,过时不候 '''# 3.导入模块 from automation_framework_demo.framework.base_page import BasePageclass NewsHomePage(BasePage):#点击体育新闻入口sports_link = "xpath=>//*[@id='channle-all']/div/ul/li[7]/a"def click_sports(self):self.click(self.sports_link)self.sleep(2)
3. 百度体育新闻页面类代码(news_sports_home.py)
3.5 代码实现:
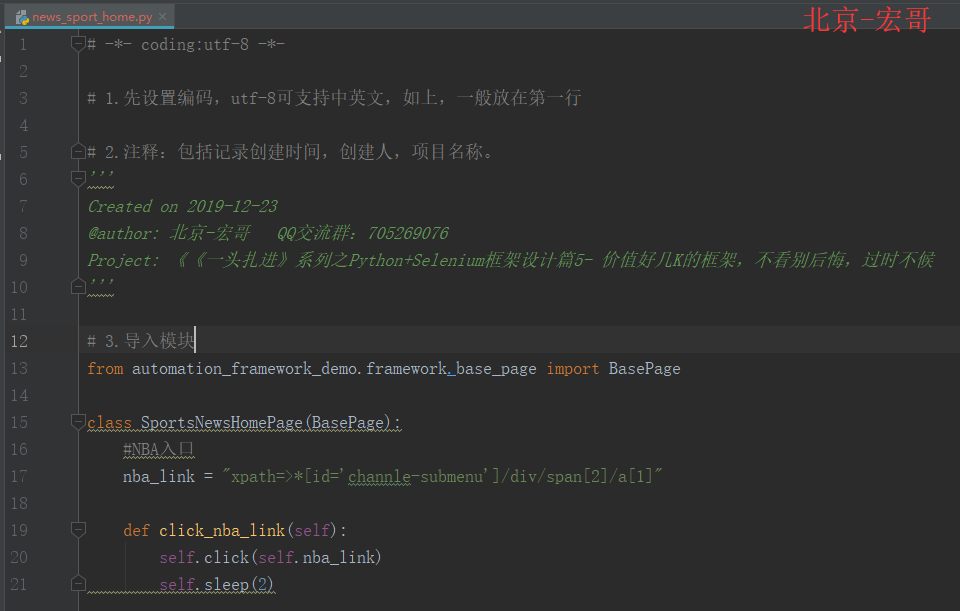
3.6 参考代码:
# -*- coding:utf-8 -*-# 1.先设置编码,utf-8可支持中英文,如上,一般放在第一行# 2.注释:包括记录创建时间,创建人,项目名称。 ''' Created on 2019-12-23 @author: 北京-宏哥 QQ交流群:260612819 @公众号:北京宏哥(微信搜索,关注宏哥提示解锁更多测试干货) Project: 《《一头扎进》系列之Python+Selenium框架设计篇5- 价值好几K的框架,不看别后悔,过时不候 '''# 3.导入模块 from automation_framework_demo.framework.base_page import BasePageclass SportsNewsHomePage(BasePage):#NBA入口nba_link = "xpath=>.//*[@id='col_focus']/div[1]/div[2]/div/div[2]/div/ul/li[1]/a"def click_nba_link(self):self.click(self.nba_link)self.sleep(2)
4. 测试类代码(test_nba_news_view.py)
测试步骤大概是:百度首页点击新闻链接-进入新闻主页,点击体育-进入体育新闻主页,点击NBA-进入NBA页面-其他后续脚本操作。为什么要采用这样的步骤呢,干嘛不直接driver.get('nba的链接')?因为我们就是要利用POM的思想去写我们测试脚本,才有上面的测试步骤。
4.1 代码实现:
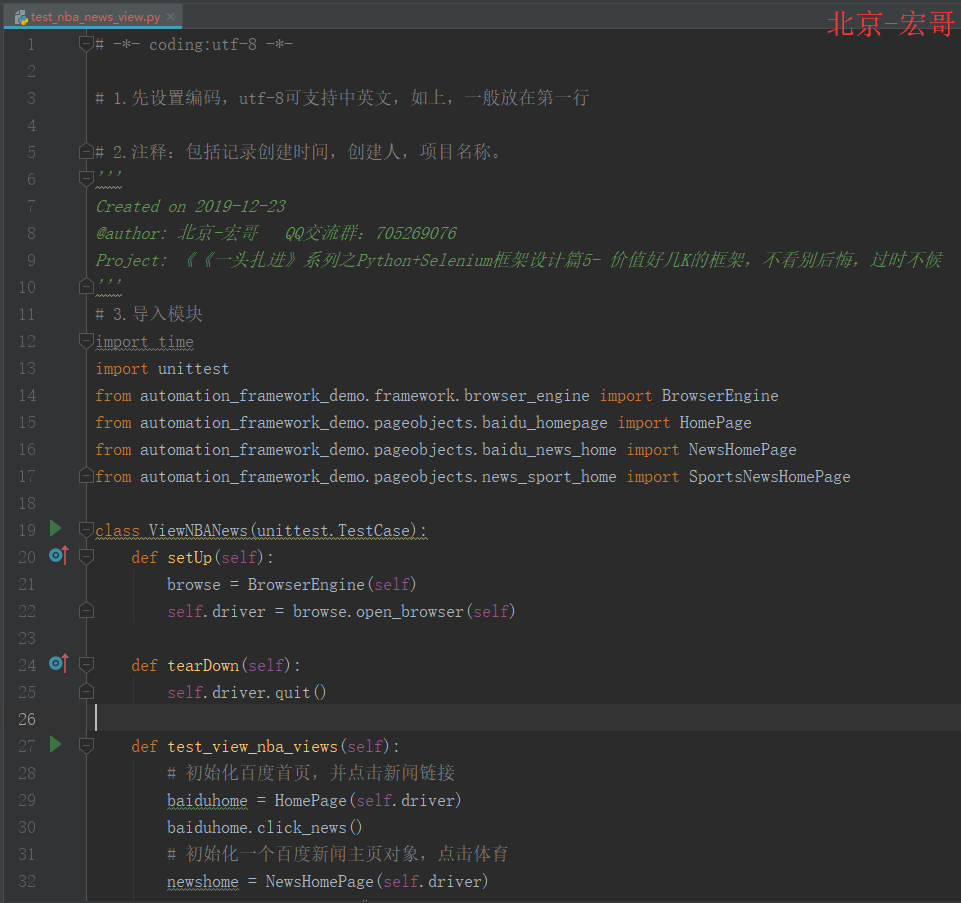
4.2 参考代码:
# -*- coding:utf-8 -*-# 1.先设置编码,utf-8可支持中英文,如上,一般放在第一行# 2.注释:包括记录创建时间,创建人,项目名称。 ''' Created on 2019-12-23 @author: 北京-宏哥 QQ交流群:260612819 @公众号:北京宏哥(微信搜索,关注宏哥提示解锁更多测试干货) Project: 《《一头扎进》系列之Python+Selenium框架设计篇5- 价值好几K的框架,不看别后悔,过时不候 ''' # 3.导入模块 import time import unittest from automation_framework_demo.framework.browser_engine import BrowserEngine from automation_framework_demo.pageobjects.baidu_homepage import HomePage from automation_framework_demo.pageobjects.baidu_news_home import NewsHomePage from automation_framework_demo.pageobjects.news_sport_home import SportsNewsHomePageclass ViewNBANews(unittest.TestCase):def setUp(self):browse = BrowserEngine(self)self.driver = browse.open_browser(self)def tearDown(self):self.driver.quit()def test_view_nba_views(self):# 初始化百度首页,并点击新闻链接baiduhome = HomePage(self.driver)baiduhome.click_news()# 初始化一个百度新闻主页对象,点击体育newshome = NewsHomePage(self.driver)newshome.click_sports()# 初始化一个体育新闻主页,点击NBAsportnewhome = SportsNewsHomePage(self.driver)sportnewhome.click_nba_link()sportnewhome.get_windows_img()if __name__ == '__main__':unittest.main()
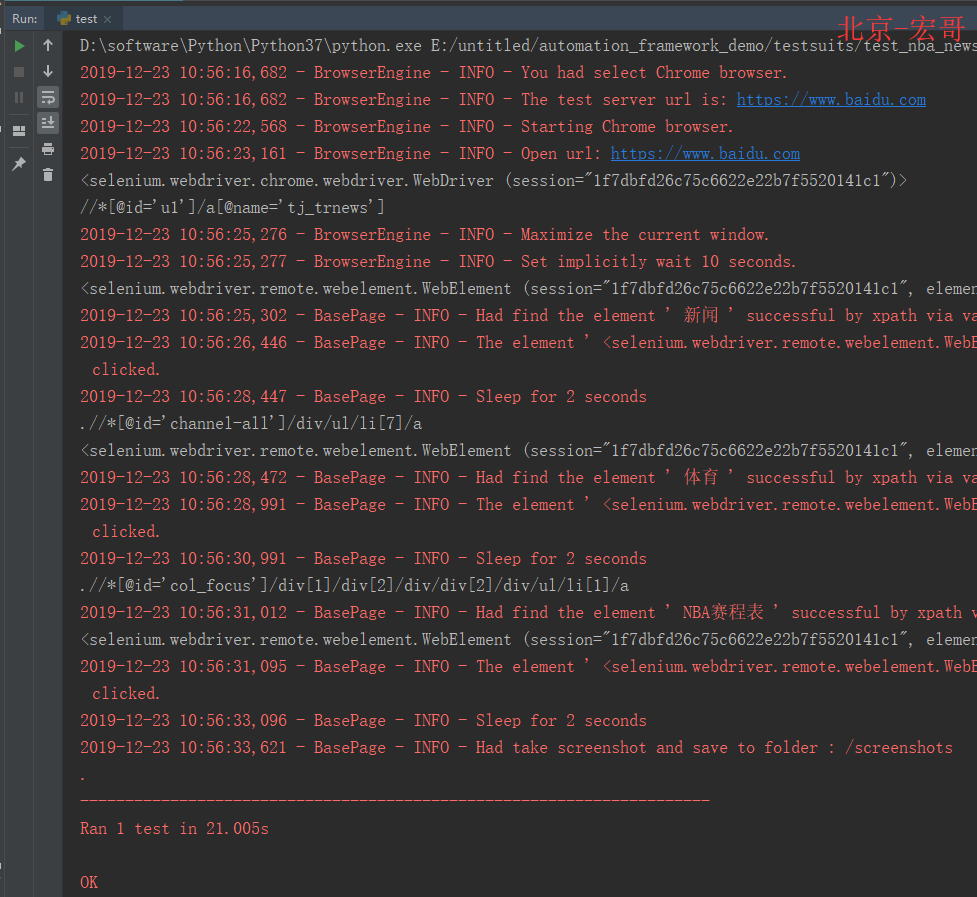
4.3 运行结果:
运行代码后,控制台打印如下图的结果
5. 小结
5.1 遇到问题
人品好的小伙伴或者童鞋们或许不会遇到下面的问题,反之则会遇到下面的问题。通过上面的脚本,进入一个新的页面,就要初始化这个页面的对象,然后才能调用这个页面相关的方法,driver这个实例对象在不同页面之间切换,这个就是POM的核心内容。我们来测试运行这个类看看,结果报错。
StaleElementReferenceException: Message: stale element reference: element is not attached to the page document
5.2 原因分析:
字面意思是说,页面元素不在当前页面对象没有加载到页面,就不能找到元素,不能进行点击,这个报错发生在,百度新闻首页点击体育这行代码里。
由于我们的driver这个实例对象在不同的页面里切换,可能造成了这个报错,这个问题在python+selenium遇到过,java+selenium没有遇到,国外网站,有人建议,既然找不到这个元素,那么在脚本里,就直接driver.find_elemen(xpath)再找一次。也就是说,可能我们
利用页面对象方法,点击不了这个体育链接,那么我们直接在脚本里通过find_element方法去定位体育这个元素,然后再点击。这个也算是一个bug,目前暂时没有更好办法解决,不知道以后chromedriver.exe升级会不会解决这个问题不好说。
我们调整下我们测试类代码,添加find_element()语句
5.3 参考代码
# -*- coding:utf-8 -*-# 1.先设置编码,utf-8可支持中英文,如上,一般放在第一行# 2.注释:包括记录创建时间,创建人,项目名称。
'''
Created on 2019-12-23
@author: 北京-宏哥 QQ交流群:260612819
@公众号:北京宏哥(微信搜索,关注宏哥提示解锁更多测试干货)
Project: 《《一头扎进》系列之Python+Selenium框架设计篇5- 价值好几K的框架,不看别后悔,过时不候
'''
# 3.导入模块
import time
import unittest
from automation_framework_demo.framework.browser_engine import BrowserEngine
from automation_framework_demo.pageobjects.baidu_homepage import HomePage
from automation_framework_demo.pageobjects.baidu_news_home import NewsHomePage
from automation_framework_demo.pageobjects.news_sport_home import SportsNewsHomePageclass ViewNBANews(unittest.TestCase):def setUp(self):browse = BrowserEngine(self)self.driver = browse.open_browser(self)def tearDown(self):self.driver.quit()def test_view_nba_views(self):# 初始化百度首页,并点击新闻链接baiduhome = HomePage(self.driver)# baiduhome.click_news()self.driver.find_element_by_xpath("//*[@id='u1']/a[@name='tj_trnews']").click()# 初始化一个百度新闻主页对象,点击体育newshome = NewsHomePage(self.driver)# newshome.click_sports()self.driver.find_element_by_xpath("//*[@id='channel-all']/div/ul/li[7]/a").click()# 初始化一个体育新闻主页,点击NBAsportnewhome = SportsNewsHomePage(self.driver)# sportnewhome.click_nba_link()self.driver.find_element_by_xpath(".//*[@id='col_focus']/div[1]/div[2]/div/div[2]/div/ul/li[1]/a").click()sportnewhome.get_windows_img()if __name__ == '__main__':unittest.main()
其实,我们之前页面对象调用点击相关元素进入下一个页面,在回放脚本是看起作用了,但是就是报错,所以这里,只好在三个地方点击进入下一个页面的时候,采用self.driver.find_element()方法。这个和我们POM的思想,页面对象只写元素定位和相关方法,脚本类一般不写页面元素定位相矛盾,是吧。也许未来能解决这个问题,或者你接受当前这个方法,或者,你单独写一个进入到NBA的类,例如直接driver.get()然后封装静态类,当做其他NBA页面脚本的测试固件引入,这样也可以。
实际项目脚本开发也应该有一些公共方法封装成模块或者静态类,例如,把登录事件写成静态类,第二个用例是收藏一篇文章,收藏的测试前提就是登录,所以在收藏类的测试固件中的setUp()里就调用登录的模块脚本。同样,你写登录的事件,可能封装了浏览器的调用。具体问题要具体分析,实际脚本开发过程要随机应变,一种方法实现起来困难,就想办法绕过去,这个是自动化测试工程师要一直面临的挑战。
好了,今天的分享就到这里吧!!!谢谢各位的耐心阅读。有问题加群交流讨论。
每天学习一点,今后必成大神-
往期推荐(由于跳转参数丢失了,所有建议选中要访问的右键,在新标签页中打开链接即可访问)或者微信搜索: 北京宏哥 公众号提前解锁更多干货。
Appium自动化系列,耗时80天打造的从搭建环境到实际应用精品教程测试
Python接口自动化测试教程,熬夜87天整理出这一份上万字的超全学习指南
Python+Selenium自动化系列,通宵700天从无到有搭建一个自动化测试框架
Java+Selenium自动化系列,仿照Python趁热打铁呕心沥血317天搭建价值好几K的自动化测试框架
Jmeter工具从基础->进阶->高级,费时2年多整理出这一份全网超详细的入门到精通教程
Fiddler工具从基础->进阶->高级,费时100多天吐血整理出这一份全网超详细的入门到精通教程
Pycharm工具基础使用教程
这篇关于《一头扎进》系列之Python+Selenium框架设计篇24 - 价值好几K的框架,哎呦!这个框架还真有点料啊!!!的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!



