本文主要是介绍11.第十一章 字典,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
11. 字典
本章介绍另一种内置类型: 字典.
字典是Python最好的语言特性之一, 它是很多高效而优雅的算法的基本构建块.
11.1 字典是一个映射
字典类似于列表, 但更加通用.
在列表中, 下标必须是整数. 而字典的下标(几乎)可以是任意类型.
字典包含'下标(称为键)集合'和'值集合'.
每个键都与一个值关联, 键和值之间的关联被称为键值对(key-value pair), 或者有时称为--项(item).
用数学语言来描述, 字典体现了键到值的映射, 所以可以说每个键'映射'到一个值.
作为示例, 我们构建一个字典, 将英语单词映射到西班牙语上, 所以键和值的类型都是字符串.函数dict新建一个不包含任何项的字典. 因为dict是内置函数的名称, 应当避免使用它作为变量名.
>>> eng2sp = dict()
>>> eng2sp
{}这里的花括号{}表示一个空的字典.
想要给字典添加新项, 可以使用方括号操作符:
>>> eng2sp['one'] = 'uno'这一行代码创建一个新项, 将键'one'隐射到值'uno'上.
如果我们再次打印这个字典, 可以看到一个键值对, 以冒号为分隔:
>>> eng2sp
{'one': 'uno'}这种输出格式也同样是出入的格式.
例如, 可以创建一个包含3个项的新字典:
>>> eng2sp = {'one': 'uno', 'two': 'dos', 'three': 'tres'}但如果你打印eng2sp, 可能会感觉奇怪:
>>> eng2sp
{'three': 'tres', 'two': 'dos', 'one': 'uno'}字典中键值对的顺序可能并不相同.
如果你在自己的电脑上输入相同的示例, 可能会得到另一个不同的结果.
总之, 字典中各项的顺序是不可预料的.
* 从Python3.6开始, Python中内置的字典是有序的, 这里的有序是指输出有序,是按照插入的顺序输出的, 而不是指按照key的字母数字顺序.
但这并不是问题, 因为字典的元素从来不使用整数下标进行查找.
相对地, 它使用键来查找对应的值:
>>> eng2sp['two']
'dos'如果键'two'总是映射到值'dos'是, 那么各项的顺序其实并不重要.
如果一个键并不在字典之中, 会得到一个异常:
>>> eng2sp['four']
Traceback (most recent call last):File "<stdin>", line 1, in <module>
KeyError: 'four'len函数可以用在字典上, 它返回键值对的数量:
>>> len(eng2sp)
3in操作符也可以用在字典上, 它告诉你一个值是不是字典中的键(是字典中的值则不算, 意思是只对键进行检查).
>>> 'one' in eng2sp
True
>>> 'uno' in eng2sp
False若要查看一个值是不是出现在字典的值中, 可以使用方法value, 它会返回一个值的集合,
并可以应用in操作符:
>>> vals = eng2sp.values()
>>> 'nuo' in vals
Truein操作符对列表和字典使用不同的算法实现.
对于列表, 它安顺搜索列表的元素, 如8.6节所示. 当列表变长时, 搜索时间会随之变长.
而对于字典, Python使用一个称为散列表(hashtable)的算法.
它有一个值得注意的特点: 不管字典中有多少项, in操作符花费的时间都差不对.
我会再21.4节中解释其中的原因, 但最好再多都几章, 这样才可能看懂解释的内容.
11.2 使用字典作为计算器集合
假设给点一个字符串, 你想要计算每个字母出现的次数.
有几种可能的实现方法:
* 1. 你可以创建26个变量, 每个变量对应字符表上的一个字母.接着遍历字符串, 对每一个字符, 增加对应的计数器. 你可能需要使用一个链式条件判断.
* 2. 你可以创建一个包含26个元素的列表, 接着可以将每个字符串转为一个数字(使用内置函数ord).使用这个数字作为列表的下标, 并增加对应的计数器.
* 3. 你可以建立一个字典, 以字符作为键, 以计数器作为相应的值.第一次遇到某个字符时, 在字典中添加对应的项. 之后可以增加一个已存在的项的值.
# 第二种实现方式
str1 = 'asdnasdgaofnodsajfasasfaipsdghfpoqwroeiwtuerigpofjsdasdasdafdgsjclkzxvnmxcbnsg'# 空间必须先创建好.
count_list = [0] * 26for i in str1:# 判断字符是否为字母.if i.isalpha():# 1. 将字母转为小写字母 2.将字母转为10进制 3. 向左位移97位.index = ord(i.lower()) - 97count_list[index] += 1# [10, 1, 2, 8, 2, 6, 5, 1, 3, 3, 1, 1, 1, 4, 5, 3, 1, 2, 11, 1, 1, 1, 2, 2, 0, 1]
print(count_list)for i in range(26):print(chr(i + 97) + ' 有', count_list[i], '个')实现(implementation)是进行某种计算的一个具体方式, 有的现实比其他的更好.
例如, 字典实现的优势之一是我们并不需要预先知道字符串中可能出现哪些字母.
因而只需为真正出现过的字母分配空间.
下面是这个实现的代码:
def histogram(s):d = dict()for c in s:if c not in d:d[c] = 1else:d[c] += 1return d这个函数的名称是直方图(histogram), 它是一个统计学术与, 表示一个计数器(或者说频率)的集合.
函数的第一行创建一个空的字典.
for循环遍历字符串. 每次跌代中, 如果字符c不在字典, 我们就创建一个新项, 其键是c, 其值初始化为1
(因为我们已经见到这个字符串一次了). 如果c已经在字典之中, 我们增加d[c].
下面是这个函数的使用方式:
>>> h = histogram('brontosaurus')
>>> h
{'b': 1, 'r': 2, 'o': 2, 'n': 1, 't': 1, 's': 2, 'a': 1, 'u': 2}这个直方图显示, 字母'a'和'b'出现了1次, 'o'出现了两次, 以此类推.
字典中有一个方法get, 接收一个键以及一个默认值.
如果键出现在字典中, get返回对应的值. 否则它返回默认值. 例如:
>>> h = histogram('a')
>>> h
{'a': 1}
>>> h.get('a')
1
# 字典中没有'b'这个键, 返回默认值0.
>>> h.get('b', 0)作为练习, 使用get将histogram写得更紧凑一些. 你应当可以消除掉if语句.
def histogram(s):d = dict()for c in s:# 存在这得到值, 不存在则返回0, 每次都加1.d[c] = d.get(c, 0) + 1return dprint(histogram('brontosaurus'))
# {'b': 1, 'r': 2, 'o': 2, 'n': 1, 't': 1, 's': 2, 'a': 1, 'u': 2}11.3 循环和字典
如果在for循环中使用字典, 会遍历字典的键.
例如, print_hist函数打印字典的每一个键以及对应的值:
def print_hist(h):for c in h:print(c, h[c])下面是这个函数输出的样子:
>>> h = histogram('parrot')
>>> print_hist(h)
a 1
p 1
r 2
t 1
o 1同样地, 键的出现没有特定的顺序. 要按顺序遍历所有键, 可以使用内置函数sorted(按字母顺序排序):
>>> for key in sorted(h)
... print(key, h[key])
...
a 1
o 1
p 1
r 2
t 111.4 反向查找
给定一个字典d和键k, 找到对应的值v=d[k]非常容易. 这个操作成为查找(lookup).
但是如果有v, 而想找到k时怎么办?
这里有两个问题: 首先, 可能存在多个键映射到同一个值v上.
随不同的应用场景, 也许可以挑其中一个, 或者也许需要建立一个列表来保存所有的键.
其次, 并没有可以进行反向查找的简单语法, 你需要使用搜索.下面是一个函数, 接收一个值, 并返回映射该值的第一个键:
def reverse_lookup(d, v):for k in d:if d[k] == v:return kraise LookupError()这个函数是搜索模式的有一个示例.
但它使用了一个我们没有见过的语言特性, raise语句.
raise语句会生成一个异常, 在这个例子里它生成一个LookupError, 这是一个内置异常.
下面的例子展示了一个成功的方向查找:
>>> h = histogram('parrot')
>>> k = reverse_lookup(h, 2)
>>> k
'r'以及一个不成功的反向查找:
>>> k =reverse_lookup(h, 3)
Traceback (most recent call last):File "<stdin>", line 1, in <module>File "<stdin>", line 5, in reverse_lookup
LookupError当你自己抛出异常时, 效果和Python抛出异常时一样的: 它会打印出一个回溯和一个错误信息.
raise语句也可以接受一个可选的参数用来详细描述错误. 例如:
>>> raise LookupError('value does not appear in the dictionary')
Traceback (most recent call last):File "<stdin>", line 1, in <module>
LookupError: value does not appear in the dictionary反向查找远远慢于正向查找; 如果频繁这么做, 或者字典非常大, 会对程序的性能有很大的影响.
11.5 字典和列表
列表可以在字典中以值的形式出现.
例如, 如果你遇到一个将字母映射到频率的字典, 可能会想要反转它.
就是说, 建立一个字典, 将频率映射到字母上.
因为可能出现多个字母频率相同的情况, 在反正的字典中, 每项的值应当时字母的列表.
(意思是: 数字出现的频率作为键, 值则是一个列表, 相同频率的字母作为这个列表的元素.)
这里是一个反转字典的函数:
def invert_dict(d):inverse = dict()# 遍历字典for key in d:# 通过键取值val = d[key]# 值不是字典的键, 则将值作为键, 键作为值存入到新字典中.if val not in inverse:inverse[val] = [key]# 值已经存在, 则将字母添加到列表中.else:inverse[val].append(key)return inverse每次循环中, key从d中获得一个键, 而val获得相应的值.
如果val不在inverse字典中, 意味着我们还没有见到过它,
所以新建一个项, 并将它初始化为一个单件(singleton, 即只包含一个元素的列表).
否则我们已经见过这个值了, 因此将相应的键附加到列表末尾.
下面是一个示例:
>>> hist = histogram('parrot')
>>> hist
{'p': 1, 'a': 1, 'r': 2, 'o': 1, 't': 1}
>>> inverse = invert_dict(hist)
>>> inverse
{1: ['p', 'a', 'o', 't'], 2: ['r']}
下图↓是显示hist和inverse的状态图.
字典使用一个上方标明dict的图框表示, 内部包含键值对.
如果值是整数, 浮点数或字符串, 我会把他们画到图框内,
但我常常会将列表画在图框之外, 以保证状态图的简洁.
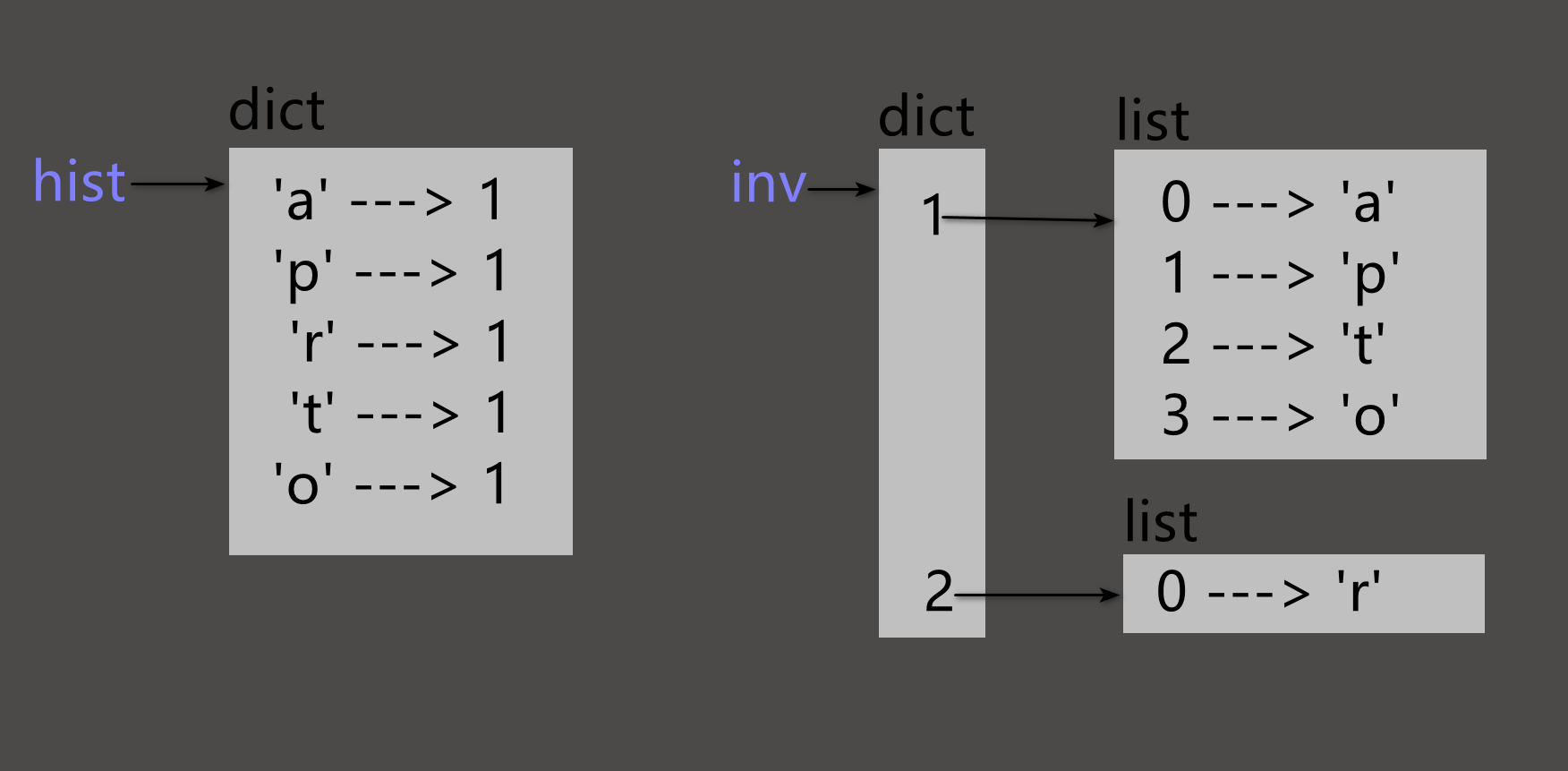
如本例子所示, 列表可以用作字典的值, 但它们不能作为键. 如果尝试的话, 会得到如下的结果:
>>> t = [1, 2, 3]
>>> d = dict()
>>> d[t] = 'oops'
Traceback (most recent call last):File "<stdin>", line 1, in <module>
TypeError: unhashable type: 'list'
类型错误:不可处理的类型: 'list'
之前我们提到过字典是通过散列表的方式实现的, 这意味着键必须是可散列(hashable)的.
散列是一个函数, 接收(任意类型)的值并返回一个整数.
字典使用这些被称为散列值的整数来保存和查找键值对.这套系统但键不可变是, 可以正确工作.
但如果像列表这样, 键是可变的话, 则会有不好的事情发生.
例如, 新建一个键值对时, Python将键进行散列并存储到对应的地方.
如果修改了键并再次散列, 它会指向一个不同的地方.
在那种情况下, 会导致同一个键有两个条目, 或者可能找不到某个键.
不论如何, 字典将无法正常工作.因此键必须是了散列的, 而类似列表这样的可变类型是不可散列的.
绕过这种限制最简单的办法是使用元组, 下一章会有详细介绍.
因为字典是可变的, 它不能用作键, 但它可以用作字典的值.
这段话讨论了Python中字典数据类型的一个重要特性: 字典的键必须是不可变的.
这意味着只有像字符串, 数字和元组这样的不可变类型才能用作字典的键.如果你尝试使用可变类型(如列表)作为字典的键, 那么当你修改了键的值时,它将会指向一个新的内存地址.
这会导致字典中可能会出现两个相同的键, 其中一个指向旧值, 另一个指向新值.
这样就会导致字典无法正常工作, 因为它无法确定应该使用哪个键对应的值.具体地说, 当你向字典中添加一个新键值对时, Python会对键进行散列(也称哈希),
以便快速查找该键对应的值所在的内存地址.
但是, 如果你更改了键的值, 它的哈希值也会发生变化.
这会导致字典无法正确地查找该键对应的值, 或者在字典中出现冗余的键值对.因此, 为了确保字典能够正确工作, Python要求字典的键必须是不可变的.
如果你需要使用可变类型作为键, 你可以考虑使用元组或自定义不可变类型来代替.
11.6 备忘
如果你尝试过6.7节中的fibonacci函数,
可能会注意到, 提供的参数越大, 函数运行的时间越长, 并且运行时间增长很快.为了明白为什么会这样, 考虑下图, 它展示了fibonocci函数n=4时的调用图.
调用图显示了一组函数帧, 并用箭头将函数的帧和它调用的函数帧连接起来.
在图的顶端, n=4的fibonacci调用了n=3和n=2的fibonacci.
同样地, n=3的fibonacci调用了n=2和n=1的fibonacci. 以此类推.数一下fibonacci(0)和fibonacci(1)被调用了多次.
这是本问题的一个很低效的解决方案, 而且但参数变大时, 事情会变得更糟.一个解决办法是记录已经计算过的值, 并将它们保存在一个字典中.
将之前计算的值保存起来以便后面使用的方法称为备忘(memo).
下面是一个使用了备忘的fibonacci版本:
# 原始版本
def fibonacci(n):if n == 0:return 0elif n == 1:return 1else:return fibonacci(n - 1) + fibonacci(n - 2)# 对应了n为0返回0, n为1返回1
known = {0: 0, 1: 1}def fibonacci(n):# n是数字, (0-1-2-3-n)if n in known:# n存在则, 返回值斐波那契数列的值.return known[n]# n不存在则进行计算, 将计算的结果保存到字典中.res = fibonacci(n - 1) + fibonacci(n - 2)known[n] = resreturn res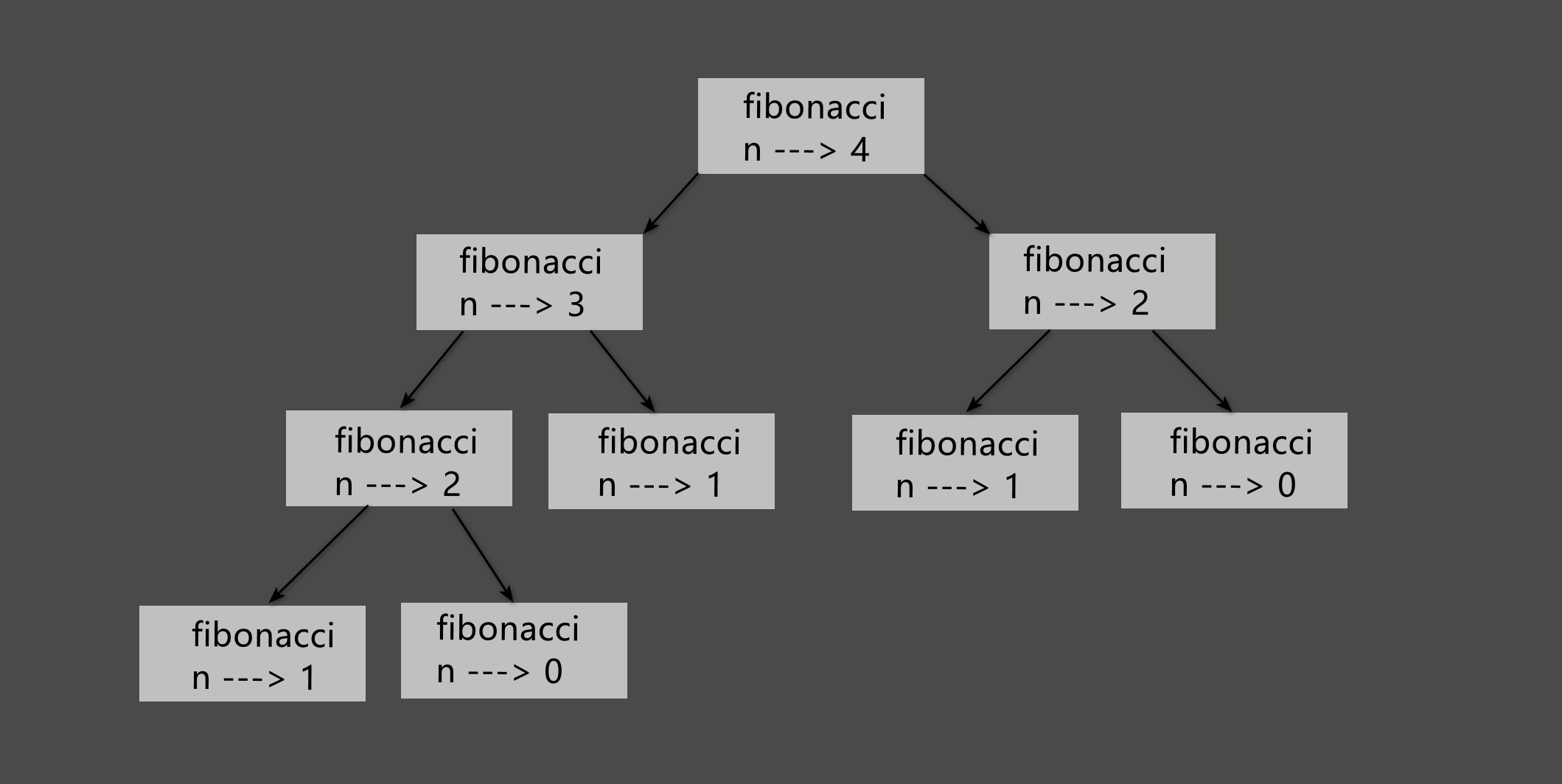
known是一个用来记录我们已知的Fibonacci(斐波那契)数的的字典.
开始时它有两个项: 0映射到0, 1映射到1.每当fibonacci被调用时, 它会先检查known. 如果结果已经存在, 则可以立即放回.
如果不存在, 它需要计算这个新值, 将其添加到字典, 并返回.
你过你运行fibonacci的这个版本, 并将其与原始版本进行比较, 你会发现, 这个版本快得多.
第一个程序每次递归调用都需要重新计算前面的斐波那契数列,
而第二个程序使用了一个字典(known)来存储之前计算过的斐波那契数列, 从而避免了重复计算, 提高了效率.
11.7 全局变量
在前一个例子中, known是在函数之外创建的, 所以它属于__main__的特殊帧.
__main__之中的变量有时被称为全局变量, 因为它们可以在任意函数中访问.
和局部变量在函数结束时就消失不同, 全部变量可以在不同函数的调用之间持久存在.
全局变量常常用作标志(flag), 它是一种布尔变量, 可以标志一个条件是否为真.
例如, 有的函数使用一个叫verbose的标志来控制输出的详细程度:
verbose = Truedef example1():if verbose:print('Running example1')example1() # Running example1如果你尝试给全局变量重新赋值, 可能会感到惊讶,. 下面例子的本意是想记录函数是否被调用过:
been_called =False
def example2():been_called = True # 错但当你运行它时, 会发现been_called的值并不会变化.
问题在于函数example2会新建一个局部变量been_called.
局部变量在函数结束时就会消失, 并且对全局变量没有任何影响.要想在函数中给全局变量重新赋值, 你需要在使用它之前声明这个全局变量:
been_called = Falsedef example2():global been_calledbeen_called = Trueprint(been_called) # False
example2()
print(been_called) # Trueglobal语句告诉编译器, '在这个函数里, 当我说been_called时, 我指定的全局变量; 不要新建一个局部变量'.
下面是一个尝试更新全局变量的例子:
count = 0
def example3():count = count + 1 # 错如果运行它, 会得到:
Traceback (most recent call last):File "C:\Users\13600\PycharmProjects\test\tese.py", line 6, in <module>example3()File "C:\Users\13600\PycharmProjects\test\tese.py", line 3, in example3count = count + 1 # 错
UnboundLocalError: local variable 'count' referenced before assignment
取消绑定本地错误: 在赋值之前引用了本地变量'count'
Python会假设count是局部的, 在这种假设下你在写入它之前先读取了 (好没有定义就使用它)..
解决方案也是声明count为全局变量.
def example3():global countcount += 1如果全局变量指向的是可变的值, 可以不用声明该变量就可以修改该值:
known = {0: 0, 1: 1}
def example4():known[2] = 1所有你可以添加, 删除, 和替换一个全局的列表或字典的元素,
但如果想要给全局变量重新赋值, 则需要声明它:
def example5():global knownknown = dict()全局变量很有用, 但是如果使用太多, 并且频繁修改, 可能会让代码比较难调试.
11.8 调式
在使用更大的数据集时, 通过打印和手动检查输出的方式来调试已经变得很笨拙.
下面是一些调试大数据集的建议.
* 1. 缩小输入: 如果可能, 减小数据集的尺寸. 例如, 程序如果读入文本文件, 可以从开头10行开始, 或者使用你能找到的最小样本.你可以编辑文件本身, 或者(更好地)修改程序让它只读前n行.如果出现了错误, 可以调小n, 小到足够展现出错误的最小程度, 并在修改之后逐渐增大n.(读取少量的数据对程序进行测试.)* 2. 检查概要信息和类型. 与其打印和检查整个数据集, 可以考虑打印出数据的概要信息.例如, 字典中条目的数量, 或者一个列表中数的和,运行时错误的一个常见原因是某个值的类型不对. 调试这种错误时, 常常只需要打印出值的类型就足够了.* 3. 编写自检查逻辑. 有时候可以写代码自动检查错误.例如, 如果你要计算一系列数的平均值, 可以检查结果是否比列表中最大的数小, 或者比最小的数大.这种检查称为'健全检查'(sanity check), 因为它会发现哪些'发疯'的结果.另一种检查可以对比两种不同的计算的结果, 查看它们是否一致. 这样的检查称为'一致性检查'.例如, 对一个列表中的元素进行排序, 使用两种算法排序, 检查它们的结果是否一致.* 4. 格式化输出. 格式化调试输出, 可以更容易发现错误.我们在6.9节中已经看过一个例子. pprint模块提供了一个pprint函数(pprint代表, 'pretty [rint]'),可以将内置类型的值以更加人性化的可读的格式打印出现. 另外, 再提醒一次, 花费时间构建脚手架代码, 可以减少未来进行调试的时间.
11.9 术语表
映射(mapping): 一个集合中每个元素与另一个集合中的元素所产生的关联.字典(dictoinary): 从键到对应的值的映射.键值对(key-value pair): 键到值的映射的展示.项(item): 字典中, 键值对的另一个名称.键(key): 字典中出现在键值对的前一部分的对象.值(value): 字典中出现在键值对的后一部分的对象. 这比我们之前提到的'值'更加具体.实现(implementation): 进行计算的一个具体方式.散列表(hashtable): Python字典的实现用的算法.散列函数(hash function): 散列表中用来计算一个键的位置的函数.可散列(hashable): 拥有散列函数的类型. 不可变类型, 诸如整数, 浮点数和字符串都是可散列的.可变类型, 诸如列表和字典, 都是不可散列的.查找(loopup): 字典的一个操作, 接收一个键, 并找到它对应的值.反向查找(reverse lookup): 字典的一个操作, 通过一个值来找到它对应的一个或多个键.raise语句(raise statement): 一个(故意)抛出异常的语句.单件(singleton): 只包含一个元素的列表(或其他序列).调用图(call graph): 一个用来展示程序运行中创建的每一帧的关系的图. 使用箭头连接每个调用者和被调用者.备忘(memo): 将计算的结果存储起来, 以避免将来进行不必要的计算.全局变量(global statement): 声明变量名为全局的语句.标志(flag): 用于标志一个条件是否为真的布尔变量.声明(declaration): 类似于global这样的用于通知解释器关于一个变量的信息的语句.11.10 练习
1. 练习1
编写一个函数, 读入words.txt中的单词, 并将其作为键保存到一个字典中. 字典的值是什么不重要.
然后你就可以使用in操作符快速检查一个字符串是否在这个字典中.如果你做过了第十章的练习10, 可以将这个实现与列表的in操作符以及二分查找进行速度的对比(大概一样快把).
import timedef make_dict():fin = open(r'C:\Users\13600\Desktop\words.txt')# 创建一个空字典tem_words_dict = dict()# 遍历文件对象for line in fin:# 移除'\n'word = line.strip()# 值是什么不所谓..tem_words_dict[word] = word# 将字典返回return tem_words_dictdef make_list():fin = open(r'C:\Users\13600\Desktop\words.txt')# 创建一个空字典tem_words_list = list()# 遍历文件对象for line in fin:# 移除'\n'word = line.strip()tem_words_list.append(word)# 将字典返回return tem_words_list# 二分法
def my_bisect(word_list, target):# 设置低位low = 0# 设置高为high = len(word_list) - 1while high >= low:# 求中间值middle = (low + high) // 2# 判断目标值是否等于中间值的if target == word_list[middle]:return True# 判断目标值是否比中间值的大elif target > word_list[middle]:# 修改低位low = middle + 1else:# 修改高位high = middle - 1return False# 统计时间
def count_time(s):start_time = time.time()# 查询单词是否存在eval(s)end_time = time.time()print('花费时间:', end_time - start_time) # 花费时间: 0.0# 返回单词字典.
words_dict = make_dict()# 返回单词列表.
words_list = make_list()count_time("print('zoos' in words_dict, end=' ')") # True 花费时间: 0.0
count_time("print(my_bisect(words_list, 'zoos'), end=' ')") # True 花费时间: 0.0
count_time("print('zoos' in words_list, end=' ')") # True 花费时间: 0.00101518630981445312. 练习2
阅读字典方法setdefault的文档, 并使用它来写一个更简洁的invert_dict.
default方法: 键不存在时, 设置的默认键值.
解答: https://raw.githubusercontent.com/AllenDowney/ThinkPython2/master/code/invert_dict.py
d = {'p': 1, 'a': 1, 'r': 2, 'o': 1, 't': 1}def invert_dict(tem_d):inverse = dict()# 遍历键for k in tem_d:# 设置键的值为一个列表, 在往列表中添加数据...val = tem_d[k]inverse.setdefault(val, []).append(k)return inversedict1 = invert_dict(d)
print(dict1) # {1: ['p', 'p', 'a', 'o', 't'], 2: ['r', 'r']}3. 练习3
将练习6-2中的Ackermann函数改为备忘化的版本, 并查看备忘化之后是否让它运行更大的参数. 提示: 不能.
解答: https://raw.githubusercontent.com/AllenDowney/ThinkPython2/master/code/ackermann_memo.py
def ackermann(m, n):"""计算阿克曼函数 A(m, n)See http://en.wikipedia.org/wiki/Ackermann_functionn, m: 非负整数"""print(m, n)if m == 0:return n + 1if n == 0:return ackermann(m - 1, 1)return ackermann(m - 1, ackermann(m, n - 1))print(ackermann(3, 4))notes = {}def ackermann(m, n):if m == 0:return n + 1if n == 0:return ackermann(m - 1, 1)# 有两个参数, 合并在一个.(目前值学了字符串, 后续使用元组更加合理)key = str(m) + str(n)if key in notes:return notes[key]# 将原本的语句拆分了, 看的清楚点.res1 = ackermann(m, n - 1)res2 = ackermann(m - 1, res1)notes[key] = res2return res2print(ackermann(3, 4)) # 125
print(ackermann(3, 6)) # 509
print(notes)4. 练习4
如果你做过练习10-7, 则已经有一个接受了列表最为形参的函数has_duplicates.
当列表中有任意元素出现多于1次时返回True.
使用字典编写一个更快, 更简单的has_duplicates.
解答: (之前使用in操作符判断值在不在新列表中, 或先排序在比较相邻两个值是否相同.)
https://raw.githubusercontent.com/AllenDowney/ThinkPython2/master/code/has_duplicates.py
# (修改列表为字典, in操作符字典比 in列表快n倍.)
def has_duplicates(list1):# 新建一个字典tem_dict = dict()# 遍历列表for i in list1:# i不在字典, 则添加. if i not in tem_dict:tem_dict[i] = 0else:return Truereturn Falseprint(has_duplicates([1, 1, 2, 3, 4, 5, 5, 6])) # True
print(has_duplicates([1, 2, 3, 4, 5, 6])) # False5. 练习5
两个单词, 如果可以是转轮操作将一个转为另一个, 则称为转轮对. (参见练习8-5的rotate_word函数.)
编写一个程序, 读入一个单词表, 并找到所有的转轮对.
(提示: 转轮后一个单词, 轮转后的这个单词去单词表中匹配.)
解答: https://raw.githubusercontent.com/AllenDowney/ThinkPython2/master/code/rotate_pairs.py
# 单词字典
def make_word_dict():fin = open(r'C:\Users\13600\Desktop\words.txt')# 新建字典word_dict = dict()for line in fin:word = line.strip()# 将所有的列表元素作为字典的键.word_dict.setdefault(word, None)return word_dict# 轮转单词
def rotate_words(tem_word, digit):# a - z 对应 97 - 123# 新建列表word_list = []for i in tem_word:letter = chr((ord(i) - 97 + digit) % 26 + 97)word_list.append(letter)res_word = ''.join(word_list)return res_word# 查找轮转对
def check_wheelset():word_dict = make_word_dict()for word in word_dict:for i in range(1, 26):# 返回轮转后的单词rotation = rotate_words(word, i)# 判断轮转后的单词是否存在if rotation in word_dict:print('单词: ' + word + ' 轮转' + str(i) + '次后为 ' + rotation)check_wheelset()# 运行终端显示:
单词: aah 轮转4次后为 eel
单词: aba 轮转19次后为 tut
单词: abet 轮转7次后为 hila
单词: abjurer 轮转13次后为 nowhere
单词: abo 轮转4次后为 efs
单词: abo 轮转13次后为 nob
单词: aby 轮转3次后为 deb
单词: aby 轮转25次后为 zax
单词: ache 轮转6次后为 gink
单词: act 轮转24次后为 yar
6. 练习6
下面是<<车迷天下>>节目中的另一个谜题(http://www.cartalk.com/content/puzzlers).
这个谜题是一个叫作Dan O' Leary的伙计寄过来的.
他曾经遇到一个单音节, 5字母的常用单词, 有如下所述的特殊属性.
当你删除第一个字母时, 剩下的字母组成原单词的一个同音词, 即发音完全相同的词,
将第一个字母放回去, 并删除第二个字母, 结果也是原单词的另一个同音词,
问题是, 这个单词是什么?接下来我给你一个示例, 但它并不能完全符合条件.
我们看这5个字母单词'wrack', W-R-A-C-K, 也就是'weack with pain(带来伤害)'里的那个词.
如果我删除掉第一个字母, 会剩下一个4个字母的单词, 'R-A-C-K'.
也就是, 'Holy cow, did you sess the rack on that buck! It must have a nine-pointer!'
(天哪! 你看到哪匹雄鹿的鹿角了吗! 一定有9个犄角!) 中的那个单词. 它是一个完美的同音词.
但如果你把'w'放回去, 并删除掉'r'会得到单词'wack'也是一个真实的单词, 但它的读音和其他两个不一样.
但就Dam个我所知, 至少有一个单词能够通过删除前两个字母得到两个同音词. 问题是, 这个单词是什么?
你可以使用11-1中的字典来检测一个字符串是否出现在单词表中.
要检查两个单词是不是同音词, 你可以使用CMU发音词典.
你可以从下面的地址下载它:
http:www.speech.cs.cum.edu/cgi-bin/cmudict
https://raw.githubusercontent.com/AllenDowney/ThinkPython2/master/code/c06d
下面脚本提供了一个叫作read_dictionary的函数来读入发音词典并返回一个Python字典,
将每个单词映射到表示其只要发音的字符串上.
https://raw.githubusercontent.com/AllenDowney/ThinkPython2/master/code/pronounce.py编写一个程序, 列出所有可以解答这个谜题的单词.
解答: https://raw.githubusercontent.com/AllenDowney/ThinkPython2/master/code/homophone.py
def make_dict():fin = open(r'C:\Users\13600\Desktop\words.txt')# 创建一个空字典tem_words_dict = dict()# 遍历文件对象for line in fin:# 移除'\n'word = line.strip()# 值是什么不所谓..tem_words_dict[word] = word# 将字典返回return tem_words_dictdef read_dictionary(filename='c06d'):# 新建空字典d = dict()# 读取文件fin = open(filename)# 遍历文件for line in fin:# 跳过评论, 文件中很有很多#开头的段落.if line[0] == '#':continue# 去除\nt = line.split()# 将单词的第一个单词转为小写, 赋值给word, SCHLARB --> schlarbword = t[0].lower()# 使用空格拼接, SH L AA1 R Bpron = ' '.join(t[1:])# schlarb = SH L AA1 R Bd[word] = pronreturn d# 发音单词字典
phonetic = read_dictionary()
# 单词字典
words_dict = make_dict()# 遍历单词
for word in words_dict:# 第一个单词, 去除首字母word1 = word[1:]# 第二个单词, 去除第二个字母word2 = word[:1] + word[2:]# 这两个单词在字典中.if word1 in words_dict and word2 in words_dict:# 三个单词都在phonetic中if word1 in phonetic and word2 in phonetic and word in phonetic:# 单词1, 单词2, 与单词的值一样.if phonetic[word1] == phonetic[word2] == phonetic[word]:print(word, word1, word2)这篇关于11.第十一章 字典的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!

![python 字典d[k]中key不存在的解决方案](/front/images/it_default.jpg)

