本文主要是介绍Java最新面试题(全网最全、最细、附答案),希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
一、Java基础
1、基础概念与常识Java 语言有哪些特点?
- 简单易学(语法简单,上手容易);
- 面向对象(封装,继承,多态);
- 平台无关性( Java 虚拟机实现平台无关性);
- 支持多线程( C++ 语言没有内置的多线程机制,因此必须调用操作系统的多线程功能来进行多线程程序设计,而 Java 语言却提供了多线程支持);
- 可靠性(具备异常处理和自动内存管理机制);
- 安全性(Java 语言本身的设计就提供了多重安全防护机制如访问权限修饰符、限制程序直接访问操作系统资源);
- 高效性(通过 Just In Time 编译器等技术的优化,Java 语言的运行效率还是非常不错的);
- 支持网络编程并且很方便;
- 编译与解释并存;
🌈 拓展一下:
“Write Once, Run Anywhere(一次编写,随处运行)”这句宣传口号,真心经典,流传了好多年!以至于,直到今天,依然有很多人觉得跨平台是 Java 语言最大的优势。实际上,跨平台已经不是 Java 最大的卖点了,各种 JDK 新特性也不是。目前市面上虚拟化技术已经非常成熟,比如你通过 Docker 就很容易实现跨平台了。在我看来,Java 强大的生态才是!
1.1、Java SE vs Java EE
- Java SE(Java Platform,Standard Edition): Java 平台标准版,Java 编程语言的基础,它包含了支持 Java 应用程序开发和运行的核心类库以及虚拟机等核心组件。Java SE 可以用于构建桌面应用程序或简单的服务器应用程序。
- Java EE(Java Platform, Enterprise Edition ):Java 平台企业版,建立在 Java SE 的基础上,包含了支持企业级应用程序开发和部署的标准和规范(比如 Servlet、JSP、EJB、JDBC、JPA、JTA、JavaMail、JMS)。 Java EE 可以用于构建分布式、可移植、健壮、可伸缩和安全的服务端 Java 应用程序,例如 Web 应用程序。
简单来说,Java SE 是 Java 的基础版本,Java EE 是 Java 的高级版本。Java SE 更适合开发桌面应用程序或简单的服务器应用程序,Java EE 更适合开发复杂的企业级应用程序或 Web 应用程序。除了 Java SE 和 Java EE,还有一个 Java ME(Java Platform,Micro Edition)。Java ME 是 Java 的微型版本,主要用于开发嵌入式消费电子设备的应用程序,例如手机、PDA、机顶盒、冰箱、空调等。Java ME 无需重点关注,知道有这个东西就好了,现在已经用不上了。
1.2、JVM vs JDK vs JRE
JVM
Java 虚拟机(Java Virtual Machine, JVM)是运行 Java 字节码的虚拟机。JVM 有针对不同系统的特定实现(Windows,Linux,macOS),目的是使用相同的字节码,它们都会给出相同的结果。字节码和不同系统的 JVM 实现是 Java 语言“一次编译,随处可以运行”的关键所在。
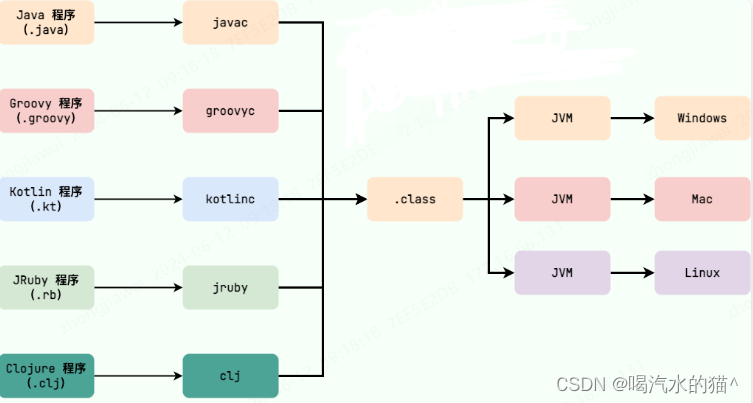
运行在 Java 虚拟机之上的编程语言JVM 并不是只有一种!只要满足 JVM 规范,每个公司、组织或者个人都可以开发自己的专属 JVM。 也就是说我们平时接触到的 HotSpot VM 仅仅是是 JVM 规范的一种实现而已。除了我们平时最常用的 HotSpot VM 外,还有 J9 VM、Zing VM、JRockit VM 等 JVM 。维基百科上就有常见 JVM 的对比:Comparison of Java virtual machinesopen in new window ,感兴趣的可以去看看。并且,你可以在 Java SE Specificationsopen in new window 上找到各个版本的 JDK 对应的 JVM 规范。
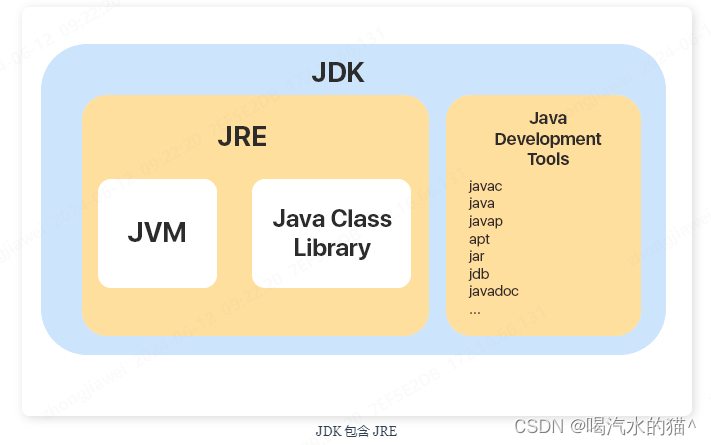
JDK 和 JRE
JDK(Java Development Kit),它是功能齐全的 Java SDK,是提供给开发者使用,能够创建和编译 Java 程序的开发套件。它包含了 JRE,同时还包含了编译 java 源码的编译器 javac 以及一些其他工具比如 javadoc(文档注释工具)、jdb(调试器)、jconsole(基于 JMX 的可视化监控⼯具)、javap(反编译工具)等等。
JRE(Java Runtime Environment) 是 Java 运行时环境。它是运行已编译 Java 程序所需的所有内容的集合,主要包括 Java 虚拟机(JVM)、Java 基础类库(Class Library)。
也就是说,JRE 是 Java 运行时环境,仅包含 Java 应用程序的运行时环境和必要的类库。而 JDK 则包含了 JRE,同时还包括了 javac、javadoc、jdb、jconsole、javap 等工具,可以用于 Java 应用程序的开发和调试。如果需要进行 Java 编程工作,比如编写和编译 Java 程序、使用 Java API 文档等,就需要安装 JDK。而对于某些需要使用 Java 特性的应用程序,如 JSP 转换为 Java Servlet、使用反射等,也需要 JDK 来编译和运行 Java 代码。因此,即使不打算进行 Java 应用程序的开发工作,也有可能需要安装 JDK。
不过,从 JDK 9 开始,就不需要区分 JDK 和 JRE 的关系了,取而代之的是模块系统(JDK 被重新组织成 94 个模块)+ jlinkopen in new window 工具 (随 Java 9 一起发布的新命令行工具,用于生成自定义 Java 运行时映像,该映像仅包含给定应用程序所需的模块) 。并且,从 JDK 11 开始,Oracle 不再提供单独的 JRE 下载。
在 Java 9 新特性概览open in new window这篇文章中,我在介绍模块化系统的时候提到:
在引入了模块系统之后,JDK 被重新组织成 94 个模块。Java 应用可以通过新增的 jlink 工具,创建出只包含所依赖的 JDK 模块的自定义运行时镜像。这样可以极大的减少 Java 运行时环境的大小。
也就是说,可以用 jlink 根据自己的需求,创建一个更小的 runtime(运行时),而不是不管什么应用,都是同样的 JRE。
定制的、模块化的 Java 运行时映像有助于简化 Java 应用的部署和节省内存并增强安全性和可维护性。这对于满足现代应用程序架构的需求,如虚拟化、容器化、微服务和云原生开发,是非常重要的。
1.3、什么是字节码?采用字节码的好处是什么?
在 Java 中,JVM 可以理解的代码就叫做字节码(即扩展名为 .class 的文件),它不面向任何特定的处理器,只面向虚拟机。Java 语言通过字节码的方式,在一定程度上解决了传统解释型语言执行效率低的问题,同时又保留了解释型语言可移植的特点。所以, Java 程序运行时相对来说还是高效的(不过,和 C、 C++,Rust,Go 等语言还是有一定差距的),而且,由于字节码并不针对一种特定的机器,因此,Java 程序无须重新编译便可在多种不同操作系统的计算机上运行。
Java 程序从源代码到运行的过程如下图所示:
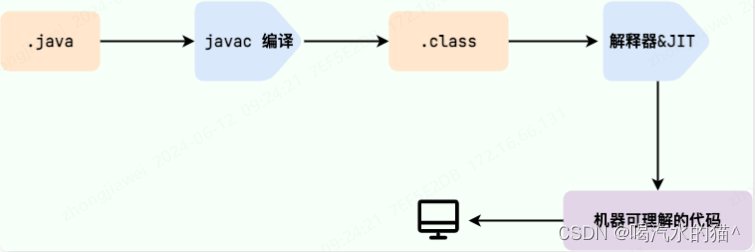
我们需要格外注意的是 .class->机器码 这一步。在这一步 JVM 类加载器首先加载字节码文件,然后通过解释器逐行解释执行,这种方式的执行速度会相对比较慢。而且,有些方法和代码块是经常需要被调用的(也就是所谓的热点代码),所以后面引进了 JIT(Just in Time Compilation) 编译器,而 JIT 属于运行时编译。当 JIT 编译器完成第一次编译后,其会将字节码对应的机器码保存下来,下次可以直接使用。而我们知道,机器码的运行效率肯定是高于 Java 解释器的。这也解释了我们为什么经常会说 Java 是编译与解释共存的语言 。
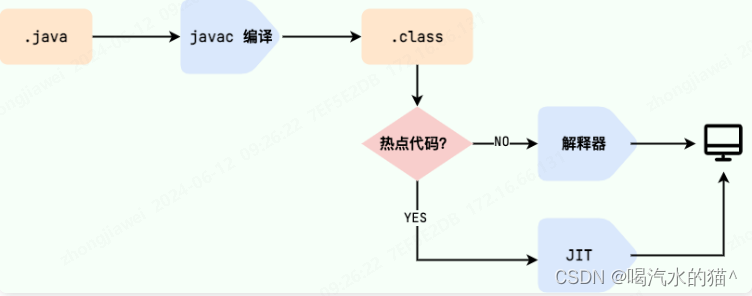
1.4、为什么说 Java 语言“编译与解释并存”?
其实这个问题我们讲字节码的时候已经提到过,因为比较重要,所以我们这里再提一下。
我们可以将高级编程语言按照程序的执行方式分为两种:
-
编译型:编译型语言open in new window 会通过编译器open in new window将源代码一次性翻译成可被该平台执行的机器码。一般情况下,编译语言的执行速度比较快,开发效率比较低。常见的编译性语言有 C、C++、Go、Rust 等等。
-
解释型:解释型语言open in new window会通过解释器open in new window一句一句的将代码解释(interpret)为机器代码后再执行。解释型语言开发效率比较快,执行速度比较慢。常见的解释性语言有 Python、JavaScript、PHP 等等。
为什么说 Java 语言“编译与解释并存”?
这是因为 Java 语言既具有编译型语言的特征,也具有解释型语言的特征。因为 Java 程序要经过先编译,后解释两个步骤,由 Java 编写的程序需要先经过编译步骤,生成字节码(.class 文件),这种字节码必须由 Java 解释器来解释执行。
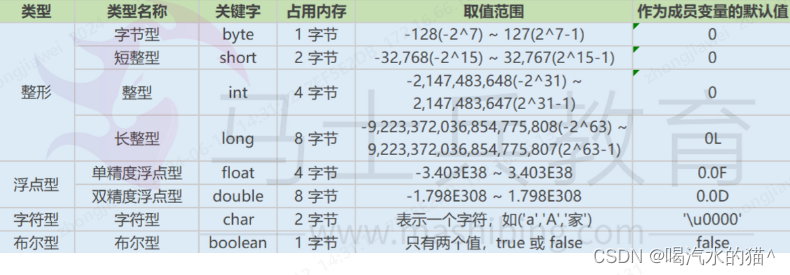
2、Java有哪些数据类型
定义:Java语言是强类型语言,对于每一种数据都定义了明确的具体的数据类 型,在内存中分配了不同大小的内存空间。
分类:
基本数据类型
- 数值型
整数类型(byte,short,int,long)
浮点类型(float,double) - 字符型(char)
- 布尔型(boolean)
引用数据类型
- 类(class)
- 接口(interface)
- 数组([])
Java基本数据类型图
3、java三大特性
封装: 使用private关键字,让对象私有,防止无关的程序去使用。
继承: 继承某个类,使子类可以使用父类的属性和方法。
多态: 同一个行为,不同的子类具有不同的表现形式。
4、重载和重写的区别
1.重写(Override)
从字面上看,重写就是 重新写一遍的意思。其实就是在子类中把父类本身有的方法重新写一遍。子类继承了父类原有的方法,但有时子类并不想原封不动的继承父类中的某个方法,所以在方法名,参数列表,返回类型(除过子类中方法的返回值是父类中方法返回值的子类时)都相同的情况下, 对方法体进行修改或重写,这就是重写。但要注意子类函数的访问修饰权限不能少于父类的。
例如:
public class Father {public static void main(String[] args) {// TODO Auto-generated method stubSon s = new Son();s.sayHello();}public void sayHello() {System.out.println("Hello");}
}class Son extends Father{@Overridepublic void sayHello() {// TODO Auto-generated method stubSystem.out.println("hello by ");}}
重写 总结:
- 发生在父类与子类之间
- 方法名,参数列表,返回类型(除过子类中方法的返回类型是父类中返回类型的子类)必须相同
- 访问修饰符的限制一定要大于被重写方法的访问修饰符(public>protected>default>private)
- 重写方法一定不能抛出新的检查异常或者比被重写方法申明更加宽泛的检查型异常
2.重载(Overload)
在一个类中,同名的方法如果有不同的参数列表(参数类型不同、参数个数不同甚至是参数顺序不同)则视为重载。同时,重载对返回类型没有要求,可以相同也可以不同,但不能通过返回类型是否相同来判断重载。
例如:
public class Father {public static void main(String[] args) {// TODO Auto-generated method stubFather s = new Father();s.sayHello();s.sayHello("wintershii");}public void sayHello() {System.out.println("Hello");}public void sayHello(String name) {System.out.println("Hello" + " " + name);}
}
重载 总结:
- 重载Overload是一个类中多态性的一种表现
- 重载要求同名方法的参数列表不同(参数类型,参数个数甚至是参数顺序)
- 重载的时候,返回值类型可以相同也可以不相同。无法以返回型别作为重载函数的区分标准
面试时,问:重载(Overload)和重写(Override)的区别?
答:方法的重载和重写都是实现多态的方式,区别在于前者实现的是编译时的多态性,而后者实现的是运行时的多态性。重载发生在一个类中,同名的方法如果有不同的参数列表(参数类型不同、参数个数不同或者二者都不同)则视为重载;重写发生在子类与父类之间,重写要求子类被重写方法与父类被重写方法有相同的参数列表,有兼容的返回类型,比父类被重写方法更好访问,不能比父类被重写方法声明更多的异常(里氏代换原则)。重载对返回类型没有特殊的要求,不能根据返回类型进行区分。
5、访问修饰符 public,private,protected,以及不写(默认)时的 区别
定义:Java中,可以使用访问修饰符来保护对类、变量、方法和构造方法的访 问。Java 支持 4 种不同的访问权限。
分类:
- private : 在同一类内可见。使用对象:变量、方法。 注意:不能修饰类(外部 类)
- default (即缺省,什么也不写,不使用任何关键字): 在同一包内可见,不使用 任何修饰符。使用对象:类、接口、变量、方法。
- protected : 对同一包内的类和所有子类可见。使用对象:变量、方法。 注意: 不能修饰类(外部类)。
- public : 对所有类可见。使用对象:类、接口、变量、方法
访问修饰符图

6、==和equals的区别
== 对于基本类型和引用类型的作用效果是不同的:
- 对于基本数据类型来说,== 比较的是值。
- 对于引用数据类型来说,== 比较的是对象的内存地址。
因为 Java 只有值传递,所以,对于 == 来说,不管是比较基本数据类型,还是引用数据类型的变量,其本质比较的都是值,只是引用类型变量存的值是对象的地址。
equals() 不能用于判断基本数据类型的变量,只能用来判断两个对象是否相等。equals()方法存在于Object类中,而Object类是所有类的直接或间接父类,因此所有的类都有equals()方法。
Object 类 equals() 方法:
public boolean equals(Object obj) {return (this == obj);
}
equals() 方法存在两种使用情况:
-
类没有重写 equals()方法:通过equals()比较该类的两个对象时,等价于通过“==”比较这两个对象,使用的默认是 Object类equals()方法。
-
类重写了 equals()方法:一般我们都重写 equals()方法来比较两个对象中的属性是否相等;若它们的属性相等,则返回 true(即,认为这两个对象相等)。
举个例子(这里只是为了举例。实际上,你按照下面这种写法的话,像 IDEA 这种比较智能的 IDE 都会提示你将 == 换成 equals() ):
String a = new String("ab"); // a 为一个引用
String b = new String("ab"); // b为另一个引用,对象的内容一样
String aa = "ab"; // 放在常量池中
String bb = "ab"; // 从常量池中查找
System.out.println(aa == bb);// true
System.out.println(a == b);// false
System.out.println(a.equals(b));// true
System.out.println(42 == 42.0);// trueString 中的 equals 方法是被重写过的,因为 Object 的 equals 方法是比较的对象的内存地址,而 String 的 equals 方法比较的是对象的值。
当创建 String 类型的对象时,虚拟机会在常量池中查找有没有已经存在的值和要创建的值相同的对象,如果有就把它赋给当前引用。如果没有就在常量池中重新创建一个 String 对象。
String类equals()方法:
public boolean equals(Object anObject) {if (this == anObject) {return true;}if (anObject instanceof String) {String anotherString = (String)anObject;int n = value.length;if (n == anotherString.value.length) {char v1[] = value;char v2[] = anotherString.value;int i = 0;while (n-- != 0) {if (v1[i] != v2[i])return false;i++;}return true;}}return false;
}hashCode() 有什么用?
hashCode() 的作用是获取哈希码(int 整数),也称为散列码。这个哈希码的作用是确定该对象在哈希表中的索引位置。

hashCode() 方法hashCode() 定义在 JDK 的 Object 类中,这就意味着 Java 中的任何类都包含有 hashCode() 函数。另外需要注意的是:Object 的 hashCode() 方法是本地方法,也就是用 C 语言或 C++ 实现的。
散列表存储的是键值对(key-value),它的特点是:能根据“键”快速的检索出对应的“值”。这其中就利用到了散列码!(可以快速找到所需要的对象)
为什么要有 hashCode?
我们以“HashSet 如何检查重复”为例子来说明为什么要有 hashCode?
下面这段内容摘自我的 Java 启蒙书《Head First Java》:
当你把对象加入 HashSet 时,HashSet 会先计算对象的 hashCode 值来判断对象加入的位置,同时也会与其他已经加入的对象的hashCode 值作比较,如果没有相符的 hashCode,HashSet 会假设对象没有重复出现。但是如果发现有相同 hashCode 值的对象,这时会调用 equals() 方法来检查 hashCode 相等的对象是否真的相同。如果两者相同,HashSet 就不会让其加入操作成功。如果不同的话,就会重新散列到其他位置。这样我们就大大减少了 equals 的次数,相应就大大提高了执行速度。其实, hashCode() 和 equals()都是用于比较两个对象是否相等。
其实, hashCode() 和 equals()都是用于比较两个对象是否相等。
那为什么 JDK 还要同时提供这两个方法呢?
-
这是因为在一些容器(比如 HashMap、HashSet)中,有了 hashCode() 之后,判断元素是否在对应容器中的效率会更高(参考添加元素进HashSet的过程)!
-
我们在前面也提到了添加元素进HashSet的过程,如果 HashSet 在对比的时候,同样的 hashCode 有多个对象,它会继续使用 equals() 来判断是否真的相同。也就是说 hashCode 帮助我们大大缩小了查找成本。
那为什么不只提供 hashCode() 方法呢?
- 这是因为两个对象的hashCode 值相等并不代表两个对象就相等。
那为什么两个对象有相同的 hashCode 值,它们也不一定是相等的?
因为 hashCode() 所使用的哈希算法也许刚好会让多个对象传回相同的哈希值。越糟糕的哈希算法越容易碰撞,但这也与数据值域分布的特性有关(所谓哈希碰撞也就是指的是不同的对象得到相同的 hashCode )。
总结下来就是:
- 如果两个对象的hashCode 值相等,那这两个对象不一定相等(哈希碰撞)。
- 如果两个对象的hashCode 值相等并且equals()方法也返回 true,我们才认为这两个对象相等。
- 如果两个对象的hashCode 值不相等,我们就可以直接认为这两个对象不相等。
相信大家看了我前面对 hashCode() 和 equals() 的介绍之后,下面这个问题已经难不倒你们了。
为什么重写 equals() 时必须重写 hashCode() 方法?
因为两个相等的对象的 hashCode 值必须是相等。也就是说如果 equals 方法判断两个对象是相等的,那这两个对象的 hashCode 值也要相等。
如果重写 equals() 时没有重写 hashCode() 方法的话就可能会导致 equals 方法判断是相等的两个对象,hashCode 值却不相等。
思考:重写 equals() 时没有重写 hashCode() 方法的话,使用 HashMap 可能会出现什么问题。
总结:
- equals 方法判断两个对象是相等的,那这两个对象的 hashCode 值也要相等。
- 两个对象有相同的 hashCode 值,他们也不一定是相等的(哈希碰撞)。
7、&和&&的区别
用法: &&和&都是表示 与
区别是:&&若第一个条件不满足,后面条件就不再判断。而&要对所有的条件都进行判断
返回值:true/false
8、 | 和 || 的区别
用法:|| 和 | 都是表示 或
区别: || 若第一个条件满足,后面条件就不再判断。而 | 要对所有的条件都进行判断
返回值:true/false
9、String、StringBuffer、StringBuilder的区别
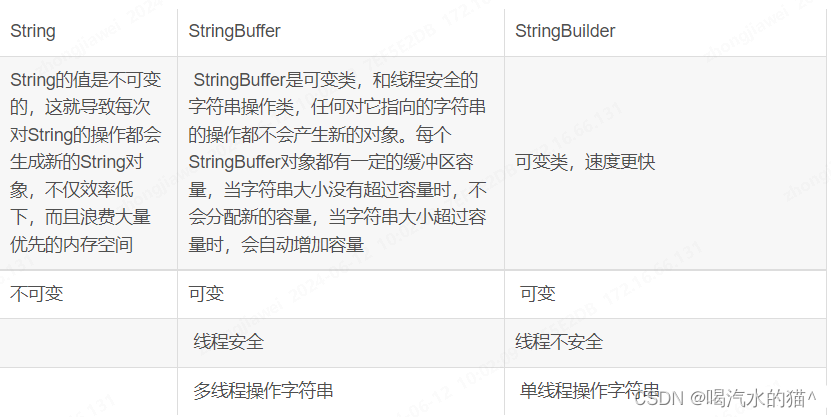
1、String
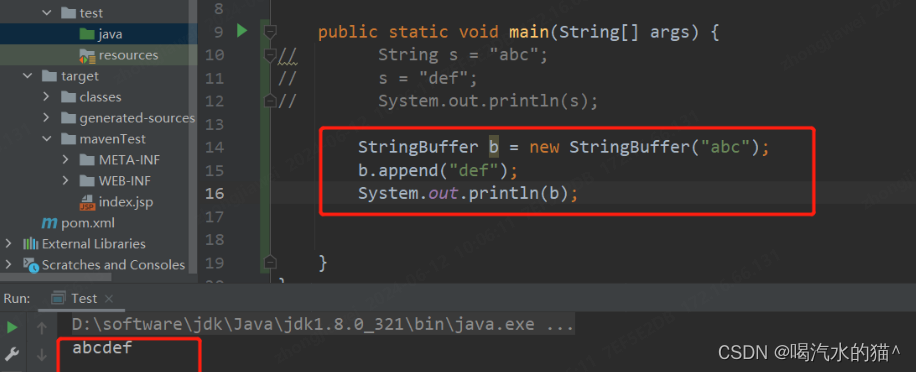
String是不可变的,即一旦一个String对象被创建以后,包含在这个对象中的字符序列是不可改变的,直至这个对象被销毁。
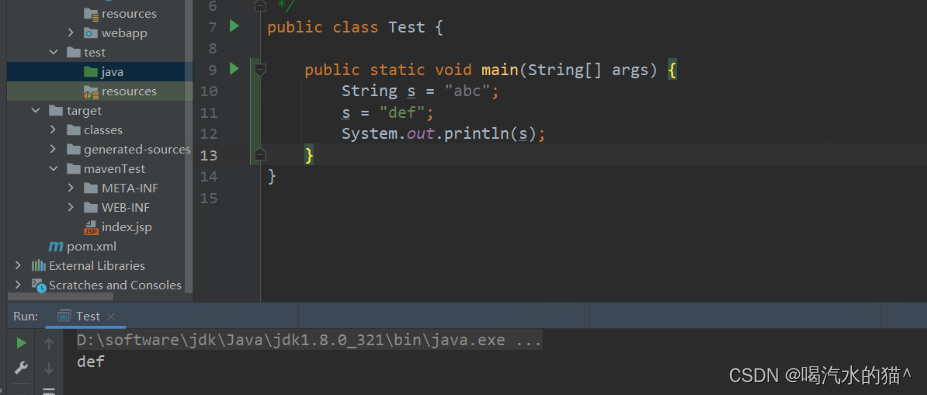
可以看出来,再次给s赋值时,并不是对原来堆中实例对象进行重新赋值,而是生成一个新的实例对象,并且指向“def”这个字符串,s则指向最新生成的实例对象,之前的实例对象仍然存在,如果没有被再次引用,则会被垃圾回收。
2、StringBuffer
StringBuffer对象则代表一个字符序列可变的字符串,当一个StringBuffer被创建以后,通过StringBuffer提供的append()、insert()、reverse()、setCharAt()、setLength()等方法可以改变这个字符串对象的字符序列。一旦通过StringBuffer生成了最终想要的字符串,就可以调用它的toString()方法将其转换为一个String对象。StringBuffer对象是一个字符序列可变的字符串,它没有重新生成一个对象,而且在原来的对象中可以连接新的字符串。
3、StringBuilder
StringBuilder类也代表可变字符串对象。实际上,StringBuilder和StringBuffer基本相似,两个类的构造器和方法也基本相同。不同的是:StringBuffer是线程安全的,而StringBuilder则没有实现线程安全功能,所以性能略高。
4、StringBuffer类中实现的方法,StringBuffer是如何实现线程安全的呢?

StringBuffer类中的方法都添加了synchronized关键字,也就是给这个方法添加了一个锁,用来保证线程安全。
5、StringBuilder类中实现的方法。
6、String、StringBuffer、StringBuilder比较。
三者共同之处:都是final类,不允许被继承,主要是从性能和安全性上考虑的,因为这几个类都是经常被使用着,且考虑到防止其中的参数被参数修改影响到其他的应用。
- StringBuffer是线程安全,可以不需要额外的同步用于多线程中;
- StringBuilder是非同步,运行于多线程中就需要使用着单独同步处理,但是速度就比StringBuffer快多了;
- StringBuffer与StringBuilder两者共同之处:可以通过append、indert进行字符串的操作。
- String实现了三个接口:Serializable、Comparable、CarSequence
- StringBuilder只实现了两个接口Serializable、CharSequence,相比之下String的实例可以通过compareTo方法进行比较,其他两个不可以。
7、运行速度
执行速度由快到慢:StringBuilder > StringBuffer > String
8、小结:
- 如果要操作少量的数据用 String;
- 多线程操作字符串缓冲区下操作大量数据 StringBuffer;
- 单线程操作字符串缓冲区下操作大量数据 StringBuilder。
10、反射
在运行过程中,对于任何一个类都能获取它的属性和方法,任何一个对象都能调用其方法,动态获取信息和动态调用,就是反射。
Java获取反射的三种方法:
1.通过new对象实现反射机制
2.通过路径实现反射机制
3.通过类名实现反射机制
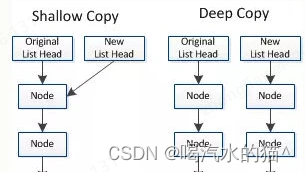
11、浅拷贝和深拷贝的区别
浅拷贝: 基础数据类型复制值,引用类型复制引用地址,修改一个对象的值,另一个对象也随之改变。
深拷贝: 基础数据类型复制值,引用类型在新的内存空间复制值,新老对象不共享内存,修改一个值,不影响另一个。
深拷贝和浅拷贝的示意图大致如下:
12、抽象类和接口的区别
- 象类只能单继承,接口可以实现多个。
- 抽象类有构造方法,接口没有构造方法。
- 抽象类可以有实例变量,接口中没有实例变量,有常量。
- 抽象类可以包含非抽象方法,接口在java7之前所有方法都是抽象的,java8之后可以包含非抽象方法。
- 抽象类中方法可以是任意修饰符,接口中java8之前都是public,java9支持private。
扩展:普通类是亲爹,手把手教你怎么学,抽象类(多个类具有相同的东西,拿出来放抽象类)是师傅,教你一部分秘籍,然后告诉你怎么学。接口(规范了某些行为)是干爹,只给你秘籍,怎么学全靠你。
13、Error和Exception有什么区别
Error: 程序无法处理,比较严重的问题,程序会立即崩溃,jvm停止运行。
Exception: 程序本身可以处理(向上抛出或者捕获)。编译时异常和运行时异常
14、final关键字有哪些用法?
- 修饰类: 不能被继承。
- 修饰方法: 不能被重写。
- 修饰变量: 声明时给定初始值,只能读取不能修改。如果是对象引用不能改,但是对象的属性可以修改。
15、jdk1.8的新特性
1、lambda 表达式
Lambda是一个匿名函数,我们可以将Lambda表达式理解为一段可以传递的代码(将代码像数据一样传递)。使用它可以写出简洁、灵活的代码。作为一种更紧凑的代码风格,使java语言表达能力得到提升。
2、方法引用
当要传递给Lambda体的操作已经有实现方法,可以直接使用方法引用(实现抽象方法的列表,必须要和方法引用的方法参数列表一致)
方法引用:使用操作符“::”将方法名和(类或者对象)分割开来。
有下列三种情况:
- 对象::实例方法
- 类::实例方法
- 类::静态方法
3、函数式接口
函数式接口:只包含一个抽象方法的接口,称为函数式接口,并且可以使用lambda表达式来创建该接口的对象,可以在任意函数式接口上使用@FunctionalInterface注解,来检测它是否是符合函数式接口。同时javac也会包含一条声明,说明这个接口是否符合函数式接口。
4、Optional类
optional类是一个容器,代表一个值存在或者不存在,原来使用null表示一个值存不存在,现在使用optional可以更好的表达这个概念,并且可以避免空指针异常。
Optional常用的方法:
Optional.of(T t) : 创建一个Optional实例;
Optional.empty() : 创建一个空的Optional实例;
Optional.ofNullable(T t) :若t不为空创建一个Optional实例否则创建一个空实例;
isPresent() : 判断是否包含值;
orElse(T t) :如果调用对象包含值,返回该值,否则返回t;
orElseGet(Supplier s) : 如果调用对象包含值,返回该值,否则返回s获取的值;
map(Function f) : 如果有值对其处理,并返回处理后的Optional,否则返回Optional.empty();
flatMap(Function mapper) : 与map类似,要求返回值必须是Optional。
其他等等
16、Java和C++的区别
我知道很多人没学过C++,但是面试官就是没事喜欢拿咱们Java和C++比呀! 没办法!!!就算没学过C++,也要记下来!
- 都是面向对象的语言,都支持封装、继承和多态
- Java不提供指针来直接访问内存,程序内存更加安全
- Java的类是单继承的,C++支持多重继承;虽然Java的类不可以多继承,但是 接口可以多继承。
- Java有自动内存管理机制,不需要程序员手动释放无用内存
17、Oracle JDK 和 OpenJDK 的对比
- Oracle JDK版本将每三年发布一次,而OpenJDK版本每三个月发布一 次;
- OpenJDK 是一个参考模型并且是完全开源的,而Oracle JDK是 OpenJDK的一个实现,并不是完全开源的;
- Oracle JDK 比 OpenJDK 更稳定。OpenJDK和Oracle JDK的代码几乎 相同,但Oracle JDK有更多的类和一些错误修复。因此,如果您想开发企 业/商业软件,我建议您选择Oracle JDK,因为它经过了彻底的测试和稳 定。某些情况下,有些人提到在使用OpenJDK 可能会遇到了许多应用程 序崩溃的问题,但是,只需切换到Oracle JDK就可以解决问题;
- 在响应性和JVM性能方面,Oracle JDK与OpenJDK相比提供了更好的 性能;
- Oracle JDK不会为即将发布的版本提供长期支持,用户每次都必须通过 更新到最新版本获得支持来获取最新版本;
- Oracle JDK根据二进制代码许可协议获得许可,而OpenJDK根据GPL v2许可获得许可。
18、 用最有效率的方法计算 2 乘以 8
2 << 3(左移 3 位相当于乘以 2 的 3 次方,右移 3 位相当于除以 2 的 3 次 方)。
19、 loat f=3.4;是否正确
不正确。3.4 是双精度数,将双精度型(double)赋值给浮点型(float)属于 下转型(down-casting,也称为窄化)会造成精度损失,因此需要强制类型转 换float f =(float)3.4; 或者写成 float f =3.4F;。
20、Java语言采用何种编码方案?有何特点?
Java语言采用Unicode编码标准,Unicode(标准码),它为每个字符制订了一 个唯一的数值,因此在任何的语言,平台,程序都可以放心的使用。
21、 final、finally、finalize区别
- final可以修饰类、变量、方法,修饰类表示该类不能被继承、修饰方法表示该方法不能被重写、修饰变量表示该变量是一个常量不能被重新赋值。
- finally一般作用在try-catch代码块中,在处理异常的时候,通常我们将一定要执行的代码方法finally代码块中,表示不管是否出现异常,该代码块都会执行,一般用来存放一些关闭资源的代码。
- finalize是一个方法,属于Object类的一个方法,而Object类是所有类的父类,该方法一般由垃圾回收器来调用,当我们调用System.gc() 方法的时候,由垃圾回收器调用finalize(),回收垃圾,一个对象是否可回收的最后判断。
22、this关键字的用法
this是自身的一个对象,代表对象本身,可以理解为:指向对象本身的一个指
针。
this的用法在java中大体可以分为3种:
- 普通的直接引用,this相当于是指向当前对象本身。
- 形参与成员名字重名,用this来区分:
- 引用本类的构造函数
23、 super关键字的用法
super可以理解为是指向自己超(父)类对象的一个指针,而这个超类指的是离
自己最近的一个父类。
super也有三种用法:
1.普通的直接引用与this类似,super相当于是指向当前对象的父类的引用,这样就可以用
super.xxx来引用父类的成员。
2.子类中的成员变量或方法与父类中的成员变量或方法同名时,用super进行区
分
3.引用父类构造函数
-
super(参数):调用父类中的某一个构造函数(应该为构造函数中的第一条语句)。
-
this(参数):调用本类中另一种形式的构造函数(应该为构造函数中的第一条语句)。
24、break ,continue ,return 的区别及作用
break 跳出总上一层循环,不再执行循环(结束当前的循环体)continue 跳出本次循环,继续执行下次循环(结束正在执行的循环 进入下一个循环条件)
return 程序返回,不再执行下面的代码(结束当前的方法 直接返回)
25、在 Java 中,如何跳出当前的多重嵌套循环
在Java中,要想跳出多重循环,可以在外面的循环语句前定义一个标号,然后在里层循环体的代码中使用带有标号的break 语句,即可跳出外层循环。例如:
1 public static void main(String[] args) {
2 ok:
3 for (int i = 0; i < 10; i++) {
4 for (int j = 0; j < 10; j++) {
5 System.out.println("i=" + i + ",j=" + j);
6 if (j == 5) {
7 break ok;
8 }
10 }
11 }
12 }
26、面向对象三大特性
1、 面向对象的特征有哪些方面
面向对象的特征主要有以下几个方面:
-
抽象:抽象是将一类对象的共同特征总结出来构造类的过程,包括数据抽象和行 为抽象两方面。抽象只关注对象有哪些属性和行为,并不关注这些行为的细节是 什么。
-
封装 : 封装把一个对象的属性私有化,同时提供一些可以被外界访问的属性的方法,如 果属性不想被外界访问,我们大可不必提供方法给外界访问。但是如果一个类没 有提供给外界访问的方法,那么这个类也没有什么意义了。
-
继承 : 继承是使用已存在的类的定义作为基础建立新类的技术,新类的定义可以增加新 的数据或新的功能,也可以用父类的功能,但不能选择性地继承父类。通过使用 继承我们能够非常方便地复用以前的代码。
关于继承如下 3 点请记住:
1.子类拥有父类非 private 的属性和方法。
2.子类可以拥有自己属性和方法,即子类可以对父类进行扩展。
3.子类可以用自己的方式实现父类的方法。
多态 : 所谓多态就是指程序中定义的引用变量所指向的具体类型和通过该引用变量发出 的方法调用在编程时并不确定,而是在程序运行期间才确定,即一个引用变量到 底会指向哪个类的实例对象,该引用变量发出的方法调用到底是哪个类中实现的 方法,必须在由程序运行期间才能决定。
在Java中有两种形式可以实现多态:继承(多个子类对同一方法的重写)和接口 (实现接口并覆盖接口中同一方法)。
其中Java 面向对象编程三大特性:封装 继承 多态
封装:隐藏对象的属性和实现细节,仅对外提供公共访问方式,将变化隔离,便 于使用,提高复用性和安全性。
继承:继承是使用已存在的类的定义作为基础建立新类的技术,新类的定义可以 增加新的数据或新的功能,也可以用父类的功能,但不能选择性地继承父类。通 过使用继承可以提高代码复用性。继承是多态的前提。
关于继承如下 3 点请记住:
- 子类拥有父类非 private 的属性和方法。
- 子类可以拥有自己属性和方法,即子类可以对父类进行扩展。
- 子类可以用自己的方式实现父类的方法。
多态性:父类或接口定义的引用变量可以指向子类或具体实现类的实例对象。提 高了程序的拓展性。
在Java中有两种形式可以实现多态:继承(多个子类对同一方法的重写)和接口 (实现接口并覆盖接口中同一方法)。
方法重载(overload)实现的是编译时的多态性(也称为前绑定),而方法重 写(override)实现的是运行时的多态性(也称为后绑定)。
一个引用变量到底会指向哪个类的实例对象,该引用变量发出的方法调用到底是 哪个类中实现的方法,必须在由程序运行期间才能决定。运行时的多态是面向对 象精髓的东西,要实现多态需要做两件事:
- 方法重写(子类继承父类并重写父类中已有的或抽象的方法);
- 对象造型(用父类型引用子类型对象,这样同样的引用调用同样的方法就会根据 子类对象的不同而表现出不同的行为)。
2、 什么是多态机制?Java语言是如何实现多态的?
所谓多态就是指程序中定义的引用变量所指向的具体类型和通过该引用变量发出 的方法调用在编程时并不确定,而是在程序运行期间才确定,即一个引用变量倒 底会指向哪个类的实例对象,该引用变量发出的方法调用到底是哪个类中实现的 方法,必须在由程序运行期间才能决定。因为在程序运行时才确定具体的类,这 样,不用修改源程序代码,就可以让引用变量绑定到各种不同的类实现上,从而 导致该引用调用的具体方法随之改变,即不修改程序代码就可以改变程序运行时 所绑定的具体代码,让程序可以选择多个运行状态,这就是多态性。
多态分为编译时多态和运行时多态。其中编辑时多态是静态的,主要是指方法的 重载,它是根据参数列表的不同来区分不同的函数,通过编辑之后会变成两个不 同的函数,在运行时谈不上多态。而运行时多态是动态的,它是通过动态绑定来 实现的,也就是我们所说的多态性
3、多态的实现
Java实现多态有三个必要条件:继承、重写、向上转型。
继承:在多态中必须存在有继承关系的子类和父类。
重写:子类对父类中某些方法进行重新定义,在调用这些方法时就会调用子类的 方法。
向上转型:在多态中需要将子类的引用赋给父类对象,只有这样该引用才能够具 备技能调用父类的方法和子类的方法。
只有满足了上述三个条件,我们才能够在同一个继承结构中使用统一的逻辑实现 代码处理不同的对象,从而达到执行不同的行为。
对于Java而言,它多态的实现机制遵循一个原则:当超类对象引用变量引用子类 对象时,被引用对象的类型而不是引用变量的类型决定了调用谁的成员方法,但 是这个被调用的方法必须是在超类中定义过的,也就是说被子类覆盖的方法。
4、 面向对象五大基本原则是什么(可选)
-
单一职责原则SRP(Single Responsibility Principle)类的功能要单一,不能包罗万象,跟杂货铺似的。
-
开放封闭原则OCP(Open-Close Principle)一个模块对于拓展是开放的,对于修改是封闭的,想要增加功能热烈欢迎,想要修改,哼,一万个不乐意。
-
里式替换原则LSP(the Liskov Substitution Principle LSP)子类可以替换父类出现在父类能够出现的任何地方。比如你能代表你爸去你姥姥家干活。哈哈~~
-
依赖倒置原则DIP(the Dependency Inversion Principle DIP)高层次的模块不应该依赖于低层次的模块,他们都应该依赖于抽象。抽象不应该依赖于具体实现,具体实现应该依赖于抽象。就是你出国要说你是中国人,而不能说你是哪个村子的。比如说中国人是抽象的,下面有具体的xx省,xx市,xx县。你要依赖的抽象是中国人,而不是你是xx村的。
-
接口分离原则ISP(the Interface Segregation Principle ISP)
设计时采用多个与特定客户类有关的接口比采用一个通用的接口要好。就比如一个手机拥有
打电话,看视频,玩游戏等功能,把这几个功能拆分成不同的接口,比在一个接口里要好的
多。
27、静态变量和实例变量区别
静态变量: 静态变量由于不属于任何实例对象,属于类的,所以在内存中只会 有一份,在类的加载过程中,JVM只为静态变量分配一次内存空间。
实例变量: 每次创建对象,都会为每个对象分配成员变量内存空间,实例变量 是属于实例对象的,在内存中,创建几次对象,就有几份成员变量。
28、## 什么是内部类?
在Java中,可以将一个类的定义放在另外一个类的定义内部,这就是内部类。内 部类本身就是类的一个属性,与其他属性定义方式一致。
29、 内部类的分类有哪些
在Java中,可以将一个类的定义放在另外一个类的定义内部,这就是内部类。内 部类本身就是类的一个属性,与其他属性定义方式一致。
内部类可以分为四种:成员内部类、局部内部类、匿名内部类和静态内部类。
30、IO流
1、 java 中 IO 流分为几种?
按照流的流向分,可以分为输入流和输出流; 按照操作单元划分,可以划分为字节流和字符流; 按照流的角色划分为节点流和处理流。 Java Io流共涉及40多个类,这些类看上去很杂乱,但实际上很有规则,而且彼 此之间存在非常紧密的联系, Java I0流的40多个类都是从如下4个抽象类基类 中派生出来的。
- InputStream/Reader: 所有的输入流的基类,前者是字节输入流,后者是字符 输入流。
- OutputStream/Writer: 所有输出流的基类,前者是字节输出流,后者是字符输 出流。
2、 BIO,NIO,AIO 有什么区别?
简答
-
BIO:Block IO 同步阻塞式 IO,就是我们平常使用的传统 IO,它的特点是模式简单使用方便,并发处理能力低。
-
NIO:Non IO 同步非阻塞 IO,是传统 IO 的升级,客户端和服务器端通过
Channel(通道)通讯,实现了多路复用。 -
AIO:Asynchronous IO 是 NIO 的升级,也叫 NIO2,实现了异步非堵塞 IO
,异步 IO 的操作基于事件和回调机制。
详细回答
-
BIO (Blocking I/O): 同步阻塞I/O模式,数据的读取写入必须阻塞在一个线程内等待其完成。在活动连接数不是特别高(小于单机1000)的情况下,这种模型是比较不错的,可以让每一个连接专注于自己的 I/O 并且编程模型简单,也不用过多考虑系统的过载、限流等问题。线程池本身就是一个天然的漏斗,可以缓冲一些系统处理不了的连接或请求。但是,当面对十万甚至百万级连接的时候,传统的 BIO 模型是无能为力的。因此,我们需要一种更高效的 I/O 处理模型来应对更高的并发量。
-
NIO (New I/O): NIO是一种同步非阻塞的I/O模型,在Java 1.4 中引入了NIO框架,对应 java.nio 包,提供了 Channel , Selector,Buffer等抽象。NIO中的 N可以理解为Non-blocking,不单纯是New。它支持面向缓冲的,基于通道的I/O操作方法。 NIO提供了与传统BIO模型中的 Socket 和 ServerSocket 相对应的 SocketChannel 和 ServerSocketChannel 两种不同的套接字通道实现,两种通道都支持阻塞和非阻塞两种模式。阻塞模式使用就像传统中的支持一样,比较简单,但是性能和可靠性都不好;非阻塞模式正好与之相反。对于低负载、低并发的应用程序,可以使用同步阻塞I/O来提升开发速率和更好的维护性;对于高负载、高并发的(网络)应用,应使用 NIO 的非阻塞模式来开发
-
AIO (Asynchronous I/O): AIO 也就是 NIO 2。在 Java 7 中引入了 NIO 的改进版 NIO 2,它是异步非阻塞的IO模型。异步 IO 是基于事件和回调机制实现的,也就是应用操作之后会直接返回,不会堵塞在那里,当后台处理完成,操作系统会通知相应的线程进行后续的操作。AIO 是异步IO的缩写,虽然 NIO 在网络操作中,提供了非阻塞的方法,但是 NIO 的 IO 行为还是同步的。对于 NIO 来说,我们的业务线程是在 IO 操作准备好时,得到通知,接着就由这个线程自行进行 IO 操作,IO操作本身是同步的。查阅网上相关资料,我发现就目前来说 AIO 的应用还不是很广泛,Netty 之前也尝试使用过 AIO,不过又放弃了。
31、 Files的常用方法都有哪些?
- Files. exists():检测文件路径是否存在。
- Files. createFile():创建文件。
- Files. createDirectory():创建文件夹。
- Files. delete():删除一个文件或目录。
- Files. copy():复制文件。
- Files. move():移动文件。
- Files. size():查看文件个数。
- Files. read():读取文件。
- Files. write():写入文件。
32、 在使用 HashMap 的时候,用 String 做 key 有什么好处?
HashMap 内部实现是通过 key 的 hashcode 来确定 value 的存储位置,因为字符串是不可变的,所以当创建字符串时,它的 hashcode 被缓存下来,不需要再次计算,所以相比于其他对象更快。
二、集合
1、 什么是集合 ?
集合框架: 用于存储数据的容器。
集合框架是为表示和操作集合而规定的一种统一的标准的体系结构。 任何集合框架都包含三大块内容:对外的接口、接口的实现和对集合运算的算 法。
接口:表示集合的抽象数据类型。接口允许我们操作集合时不必关注具体实现, 从而达到“多态”。在面向对象编程语言中,接口通常用来形成规范。
实现:集合接口的具体实现,是重用性很高的数据结构。
算法:在一个实现了某个集合框架中的接口的对象身上完成某种有用的计算的方 法,例如查找、排序等。这些算法通常是多态的,因为相同的方法可以在同一个 接口被多个类实现时有不同的表现。事实上,算法是可复用的函数。 它减少了程序设计的辛劳。
集合框架通过提供有用的数据结构和算法使你能集中注意力于你的程序的重要部 分上,而不是为了让程序能正常运转而将注意力于底层设计上。
通过这些在无关API之间的简易的互用性,使你免除了为改编对象或转换代码以 便联合这些API而去写大量的代码。 它提高了程序速度和质量。
集合的特点
集合的特点主要有如下两点:
- 对象封装数据,对象多了也需要存储。集合用于存储对象。
- 对象的个数确定可以使用数组,对象的个数不确定的可以用集合。因 为集合是可变长度的。
集合和数组的区别
- 数组是固定长度的;集合可变长度的。
- 数组可以存储基本数据类型,也可以存储引用数据类型;集合只能存 储引用数据类型。
- 数组存储的元素必须是同一个数据类型;集合存储的对象可以是不同 数据类型。
数据结构:就是容器中存储数据的方式。
对于集合容器,有很多种。因为每一个容器的自身特点不同,其实原理在于每个 容器的内部数据结构不同。
集合容器在不断向上抽取过程中,出现了集合体系。在使用一个体系的原则:参 阅顶层内容。建立底层对象。
使用集合框架的好处
- 容量自增长;
- 提供了高性能的数据结构和算法,使编码更轻松,提高了程序速度和质 量; 3
- 允许不同 API 之间的互操作,API之间可以来回传递集合;
- 可以方便地扩展或改写集合,提高代码复用性和可操作性。
- 通过使用JDK自带的集合类,可以降低代码维护和学习新API成本。
2、常用的集合类有哪些?
Map接口和Collection接口是所有集合框架的父接口:
- Collection接口的子接口包括:Set接口和List接口
- Map接口的实现类主要有:HashMap、TreeMap、Hashtable、 ConcurrentHashMap以及Properties等
- Set接口的实现类主要有:HashSet、TreeSet、LinkedHashSet等
- List接口的实现类主要有:ArrayList、LinkedList、Stack以及Vector等
3、List,Set,Map三者的区别?List、Set、Map 是否继 承自 Collection 接口?List、Map、Set 三个接口存取 元素时,各有什么特点?
Java 容器分为 Collection 和 Map 两大类,Collection集合的子接口有Set、 List、Queue三种子接口。我们比较常用的是Set、List,Map接口不是 collection的子接口。
Collection集合主要有List和Set两大接口
- List:一个有序(元素存入集合的顺序和取出的顺序一致)容器,元素可以重 复,可以插入多个null元素,元素都有索引。常用的实现类有 ArrayList、LinkedList 和 Vector。
- Set:一个无序(存入和取出顺序有可能不一致)容器,不可以存储重复元素, 只允许存入一个null元素,必须保证元素唯一性。Set 接口常用实现类是 HashSet、 LinkedHashSet 以及 TreeSet。
Map是一个键值对集合,存储键、值和之间的映射。 Key无序,唯一;value 不 要求有序,允许重复。Map没有继承于Collection接口,从Map集合中检索元 素时,只要给出键对象,就会返回对应的值对象。
Map 的常用实现类:HashMap、TreeMap、HashTable、LinkedHashMap、 ConcurrentHashMap
4、集合框架底层数据结构
List
- Arraylist: Object数组
- Vector: Object数组
- LinkedList: 双向循环链表
Set
- HashSet(无序,唯一):基于 HashMap 实现的,底层采用 HashMap 来保存元素
- LinkedHashSet: LinkedHashSet 继承与 HashSet,并且其内部是通过 LinkedHashMap 来实现的。有点类似于我们之前说的LinkedHashMap 其内部是基 于 Hashmap 实现一样,不过还是有一点点区别的。
- TreeSet(有序,唯一): 红黑树(自平衡的排序二叉树。) Map
- HashMap: JDK1.8之前HashMap由数组+链表组成的,数组是HashMap的主 体,链表则是主要为了解决哈希冲突而存在的(“拉链法”解决冲突).JDK1.8以后
在解决哈希冲突时有了较大的变化,当链表长度大于阈值(默认为8)时,将链表转 化为红黑树,以减少搜索时间 - LinkedHashMap:LinkedHashMap 继承自 HashMap,所以它的底层仍然是 基于拉链式散列结构即由数组和链表或红黑树组成。另外,LinkedHashMap 在上面 结构的基础上,增加了一条双向链表,使得上面的结构可以保持键值对的插入顺序。 同时通过对链表进行相应的操作,实现了访问顺序相关逻辑。
- HashTable: 数组+链表组成的,数组是 HashMap 的主体,链表则是主要为 了解决哈希冲突而存在的
- TreeMap: 红黑树(自平衡的排序二叉树)
5、哪些集合类是线程安全的?
- vector:就比arraylist多了个同步化机制(线程安全),因为效率较低,现在已 经不太建议使用。在web应用中,特别是前台页面,往往效率(页面响应速度)是优 先考虑的。
- statck:堆栈类,先进后出。
- hashtable:就比hashmap多了个线程安全。
- enumeration:枚举,相当于迭代器。
6、Java集合的快速失败机制 “fail-fast”?
是java集合的一种错误检测机制,当多个线程对集合进行结构上的改变的操作 时,有可能会产生 fail-fast 机制。
例如:假设存在两个线程(线程1、线程2),线程1通过Iterator在遍历集合A中 的元素,在某个时候线程2修改了集合A的结构(是结构上面的修改,而不是简 单的修改集合元素的内容),那么这个时候程序就会抛出ConcurrentModificationException 异常,从而产生fail-fast机制。
原因:迭代器在遍历时直接访问集合中的内容,并且在遍历过程中使用一个 modCount 变量。集合在被遍历期间如果内容发生变化,就会改变modCount 的值。每当迭代器使用hashNext()/next()遍历下一个元素之前,都会检测 modCount变量是否为expectedmodCount值,是的话就返回遍历;否则抛出 异常,终止遍历。
解决办法:
- 在遍历过程中,所有涉及到改变modCount值得地方全部加上 synchronized。
- 使用CopyOnWriteArrayList来替换ArrayList
7、 怎么确保一个集合不能被修改?
可以使用 Collections. unmodifiableCollection(Collection c) 方法来创建一个 只读集合,这样改变集合的任何操作都会抛出 Java. lang. UnsupportedOperationException 异常。 示例代码如下:
List<String> list = new ArrayList<>(); list. add("x"); Collection<String> clist = Collections. unmodifiableCollection(list); clist. add("y"); // 运行时此行报错 System. out. println(list. size());
8、 说一下 ArrayList 的优缺点
ArrayList的优点如下:
- ArrayList 底层以数组实现,是一种随机访问模式。ArrayList 实现了 RandomAccess 接口,因此查找的时候非常快。
- ArrayList 在顺序添加一个元素的时候非常方便。
ArrayList 的缺点如下:
- 删除元素的时候,需要做一次元素复制操作。如果要复制的元素很多,那么就会比较耗费性能。
- 插入元素的时候,也需要做一次元素复制操作,缺点同上。
ArrayList 比较适合顺序添加、随机访问的场景。
9、 ArrayList 和 LinkedList 的区别是什么?
- 数据结构实现:ArrayList 是动态数组的数据结构实现,而 LinkedList 是双向链表的数据结构实现。
- 随机访问效率:ArrayList 比 LinkedList 在随机访问的时候效率要高,因为 LinkedList 是线性的数据存储方式,所以需要移动指针从前往后依次查找。
- 增加和删除效率:在非首尾的增加和删除操作,LinkedList 要比 ArrayList 效率要高,因为 ArrayList 增删操作要影响数组内的其他数据的下标。
- 内存空间占用:LinkedList 比 ArrayList 更占内存,因为 LinkedList 的节点除了存储数据,还存储了两个引用,一个指向前一个元素,一个指向后一个元素。
- 线程安全:ArrayList 和 LinkedList 都是不同步的,也就是不保证线程安全;
综合来说,在需要频繁读取集合中的元素时,更推荐使用 ArrayList,而在插入和删除操作较多时,更推荐使用 LinkedList。
补充:数据结构基础之双向链表
双向链表也叫双链表,是链表的一种,它的每个数据结点中都有两个指针,分别指向直接后继和直接前驱。所以,从双向链表中的任意一个结点开始,都可以很方便地访问它的前驱结点和后继结点。
10、 ArrayList 和 Vector 的区别是什么?
- 这两个类都实现了 List 接口(List 接口继承了 Collection 接口),他们都是有序集合
- 线程安全:Vector 使用了 Synchronized 来实现线程同步,是线程安全的,而ArrayList 是非线程安全的。
- 性能:ArrayList 在性能方面要优于 Vector
- 扩容:ArrayList 和 Vector 都会根据实际的需要动态的调整容量,只不过在 Vector 扩容每次会增加 1 倍,而 ArrayList 只会增加 50%。
- Vector类的所有方法都是同步的。可以由两个线程安全地访问一个Vector对象、但是一个线程访问Vector的话代码要在同步操作上耗费大量的时间。
- Arraylist不是同步的,所以在不需要保证线程安全时时建议使用Arraylist。
11、 插入数据时,ArrayList、LinkedList、Vector谁速度较快?阐述 ArrayList、Vector、LinkedList 的存储性能和特性?
- ArrayList、LinkedList、Vector底层的实现都是使用数组方式存储数据。数组元素数大于实际存储的数据以便增加和插入元素,它们都允许直接按序号索引元素,但是插入元素要涉及数组元素移动等内存操作,所以索引数据快而插入数据慢。
- Vector 中的方法由于加了 synchronized 修饰,因此 Vector是线程安全容器,但性能上较ArrayList差。
- LinkedList 使用双向链表实现存储,按序号索引数据需要进行前向或后向遍历,但插入数据时只需要记录当前项的前后项即可,所以LinkedList插入速度较快。
12、 多线程场景下如何使用 ArrayList?
ArrayList 不是线程安全的,如果遇到多线程场景,可以通过 Collections 的 synchronizedList 方法将其转换成线程安全的容器后再使用。例如像下面这样:
1 List<String> synchronizedList = Collections.synchronizedList(list);
2 synchronizedList.add("aaa");
3 synchronizedList.add("bbb");
4
5 for (int i = 0; i < synchronizedList.size(); i++) {
6 System.out.println(synchronizedList.get(i));
7 }
13、 List 和 Set 的区别
- List , Set 都是继承自Collection 接口
- List 特点:一个有序(元素存入集合的顺序和取出的顺序一致)容器,元素可以重复,可以插入多个null元素,元素都有索引。常用的实现类有ArrayList、LinkedList 和 Vector。
- Set 特点:一个无序(存入和取出顺序有可能不一致)容器,不可以存储重复元素,只允许存入一个null元素,必须保证元素唯一性。Set 接口常用实现类是HashSet、LinkedHashSet 以及 TreeSet。
另外 List 支持for循环,也就是通过下标来遍历,也可以用迭代器,但是set只能用迭代,因为他无序,无法用下标来取得想要的值。
Set和List对比
Set:检索元素效率低下,删除和插入效率高,插入和删除不会引起元素位置改变。
List:和数组类似,List可以动态增长,查找元素效率高,插入删除元素效率低,因为会引起其他元素位置改变
14、说一下 HashSet 的实现原理?
-
HashSet 是基于 HashMap 实现的,HashSet的值存放于HashMap的key上,HashMap的value统一为PRESENT,因此 HashSet 的实现比较简单,相关 HashSet 的操作,基本上都是直接调用底层 HashMap 的相关方法来完成。
-
HashSet 不允许重复的值。
15、 HashSet如何检查重复?HashSet是如何保证数据不可重复的?
- 向HashSet 中add ()元素时,判断元素是否存在的依据,不仅要比较hash值,同时还要结合equles 方法比较。HashSet 中的add ()方法会使用HashMap 的put()方法。
- HashMap 的 key 是唯一的,由源码可以看出 HashSet 添加进去的值就是作为 HashMap 的key,并且在HashMap中如果K/V相同时,会用新的V覆盖掉旧的V,然后返回旧的V。所以不会重复( HashMap 比较key是否相等是先比较 hashcode 再比较equals )。
16、 BlockingQueue是什么?
Java.util.concurrent.BlockingQueue是一个队列,在进行检索或移除一个元素的时候,它会等待队列变为非空;当在添加一个元素时,它会等待队列中的可用空间。BlockingQueue接口是Java集合框架的一部分,主要用于实现生产者-消费者模式。我们不需要担心等待生产者有可用的空间,或消费者有可用的对象,因为它都在BlockingQueue的实现类中被处理了。Java提供了集中 BlockingQueue的实现,比如ArrayBlockingQueue、LinkedBlockingQueue、PriorityBlockingQueue、SynchronousQueue等。
在 Queue 中 poll()和 remove()有什么区别?
- 相同点:都是返回第一个元素,并在队列中删除返回的对象。
- 不同点:如果没有元素 poll()会返回 null,而 remove()会直接抛出 NoSuchElementException 异常。
17、 Map接口
1、说一下 HashMap 的实现原理?
HashMap概述: HashMap是基于哈希表的Map接口的非同步实现。此实现提供所有可选的映射操作,并允许使用null值和null键。此类不保证映射的顺序,特别是它不保证该顺序恒久不变。
HashMap的数据结构: 在Java编程语言中, 基本的结构就是两种,一个是数组,另外一个是模拟指针(引用),所有的数据结构都可以用这两个基本结构来构造的,HashMap也不例外。HashMap实际上是一个“链表散列”的数据结构,即数组和链表的结合体。
HashMap 基于 Hash 算法实现的:
-
当我们往Hashmap中put元素时,利用key的hashCode重新hash计算出当前对象的元素在数组中的下标
-
存储时,如果出现hash值相同的key,此时有两种情况。(1)如果key相
同,则覆盖原始值;(2)如果key不同(出现冲突),则将当前的key-value 放入链表中
-
获取时,直接找到hash值对应的下标,在进一步判断key是否相同,从而找到对应值。
-
理解了以上过程就不难明白HashMap是如何解决hash冲突的问题,核心就是使用了数组的存储方式,然后将冲突的key的对象放入链表中,一旦发现冲突就在链表中做进一步的对比。
需要注意Jdk 1.8中对HashMap的实现做了优化,当链表中的节点数据超过八个之后,该链表会转为红黑树来提高查询效率,从原来的O(n)到O(logn)
2、HashMap在JDK1.7和JDK1.8中有哪些不同? HashMap的底层实现
在Java中,保存数据有两种比较简单的数据结构:数组和链表。数组的特点是:寻址容易,插入和删除困难;链表的特点是:寻址困难,但插入和删除容易;所以我们将数组和链表结合在一起,发挥两者各自的优势,使用一种叫做拉链法的方式可以解决哈希冲突。
JDK1.8之前
JDK1.8之前采用的是拉链法。拉链法:将链表和数组相结合。也就是说创建一个链表数组,数组中每一格就是一个链表。若遇到哈希冲突,则将冲突的值加到链表中即可。
JDK1.8之后
相比于之前的版本,jdk1.8在解决哈希冲突时有了较大的变化,当链表长度大于阈值(默认为8)时,将链表转化为红黑树,以减少搜索时间。
JDK1.7 VS JDK1.8 比较
JDK1.8主要解决或优化了一下问题:
-
resize 扩容优化
-
引入了红黑树,目的是避免单条链表过长而影响查询效率,红黑树算法请参考
-
解决了多线程死循环问题,但仍是非线程安全的,多线程时可能会造成数据丢失问题。

3、 HashMap的put方法的具体流程?
①.判断键值对数组table[i]是否为空或为null,否则执行resize()进行扩容;
②.根据键值key计算hash值得到插入的数组索引i,如果table[i]==null,直接新建节点添加,转向⑥,如果table[i]不为空,转向③;
③.判断table[i]的首个元素是否和key一样,如果相同直接覆盖value,否则转向
④,这里的相同指的是hashCode以及equals;
④.判断table[i] 是否为treeNode,即table[i] 是否是红黑树,如果是红黑树,则直接在树中插入键值对,否则转向⑤;
⑤.遍历table[i],判断链表长度是否大于8,大于8的话把链表转换为红黑树,在红黑树中执行插入操作,否则进行链表的插入操作;遍历过程中若发现key已经存在直接覆盖value即可;
⑥.插入成功后,判断实际存在的键值对数量size是否超多了 大容量threshold,如果超过,进行扩容。
4、 HashMap是怎么解决哈希冲突的?
答:在解决这个问题之前,我们首先需要知道什么是哈希冲突,而在了解哈希冲突之前我们还要知道什么是哈希才行;什么是哈希?
Hash,一般翻译为“散列”,也有直接音译为“哈希”的,这就是把任意长度的输入通过散列算法,变换成固定长度的输出,该输出就是散列值(哈希值);这种转换是一种压缩映射,也就是,散列值的空间通常远小于输入的空间,不同的输入可能会散列成相同的输出,所以不可能从散列值来唯一的确定输入值。简单的说就是一种将任意长度的消息压缩到某一固定长度的消息摘要的函数。
所有散列函数都有如下一个基本特性**:根据同一散列函数计算出的散列值如果不同,那么输入值肯定也不同。但是,根据同一散列函数计算出的散列值如果相同,输入值不一定相同**。
什么是哈希冲突?
当两个不同的输入值,根据同一散列函数计算出相同的散列值的现象,我们就把它叫做碰撞(哈希碰撞)。
HashMap的数据结构
在Java中,保存数据有两种比较简单的数据结构:数组和链表。数组的特点是:寻址容易,插入和删除困难;链表的特点是:寻址困难,但插入和删除容易;所以我们将数组和链表结合在一起,发挥两者各自的优势,使用一种叫做链地址法的方式可以解决哈希冲突:
这样我们就可以将拥有相同哈希值的对象(img)组织成一个链表放在hash值所对应的 bucket下,但相比于hashCode返回的int类型,我们HashMap初始的容量大小DEFAULT_INITIAL_CAPACITY = 1 << 4(即2的四次方16)要远小于int类型的范围,所以我们如果只是单纯的用hashCode取余来获取对应的bucket这将会大大增加哈希碰撞的概率,并且最坏情况下还会将HashMap变成一个单链表,所以我们还需要对hashCode作一定的优化 hash()函数。
上面提到的问题,主要是因为如果使用hashCode取余,那么相当于参与运算的只有hashCode的低位,高位是没有起到任何作用的,所以我们的思路就是让 hashCode取值出的高位也参与运算,进一步降低hash碰撞的概率,使得数据分布更平均,我们把这样的操作称为扰动,在JDK 1.8中的hash()函数如下:
1 static final int hash(Object key) {
2 int h;
3 return (key == null) ? 0 : (h = key.hashCode()) ^ (h >>> 16);// 与自己右移16位进行异或运算(高低位异或)
4 }
这比在JDK 1.7中,更为简洁,相比在1.7中的4次位运算,5次异或运算(9次扰动),在1.8中,只进行了1次位运算和1次异或运算(2次扰动);
5、 HashMap 的长度为什么是2的幂次方?
为了能让 HashMap 存取高效,尽量较少碰撞,也就是要尽量把数据分配均匀,每个链表/红黑树长度大致相同。这个实现就是把数据存到哪个链表/红黑树中的算法。
这个算法应该如何设计呢?我们首先可能会想到采用%取余的操作来实现。但是,重点来了:“取余(%)操作中如果除数是2的幂次则等价于与其除数减一的与(&)操作(也就是说 hash%length==hash&(length-1)的前提是 length 是2的 n 次方;)。” 并且 采用二进制位操作 &,相对于%能够提高运算效率,这就解释了 HashMap 的长度为什么是2的幂次方。
那为什么是两次扰动呢?
答:这样就是加大哈希值低位的随机性,使得分布更均匀,从而提高对应数组存储下标位置的随机性&均匀性, 终减少Hash冲突,两次就够了,已经达到了高位低位同时参与运算的目的。
6、 HashMap 与 HashTable 有什么区别?
- 线程安全: HashMap 是非线程安全的,HashTable 是线程安全的;
HashTable 内部的方法基本都经过 synchronized 修饰。(如果你要保证线程安全的话就使用 ConcurrentHashMap 吧!);
-
效率: 因为线程安全的问题,HashMap 要比 HashTable 效率高一点。另外,HashTable 基本被淘汰,不要在代码中使用它;
-
对Null key 和Null value的支持: HashMap 中,null 可以作为键,这样的键只有一个,可以有一个或多个键所对应的值为 null。但是在 HashTable 中 put 进的键值只要有一个 null,直接抛NullPointerException。
-
初始容量大小和每次扩充容量大小的不同 : ①创建时如果不指定容量初始值,Hashtable 默认的初始大小为11,之后每次扩充,容量变为原来的2n+1。HashMap 默认的初始化大小为16。之后每次扩充,容量变为原来的2倍。②创建时如果给定了容量初始值,那么 Hashtable 会直接使用你给定的大小,而 HashMap 会将其扩充为2的幂次方大小。也就是说 HashMap 总是使用2的幂作为哈希表的大小,后面会介绍到为什么是2 的幂次方。
-
底层数据结构: JDK1.8 以后的 HashMap 在解决哈希冲突时有了较大的变化,当链表长度大于阈值(默认为8)时,将链表转化为红黑树,以减少搜索时间。Hashtable 没有这样的机制。
-
推荐使用:在 Hashtable 的类注释可以看到,Hashtable 是保留类不建议使用,推荐在单线程环境下使用 HashMap 替代,如果需要多线程使用则用 ConcurrentHashMap 替代。
7、如何决定使用 HashMap 还是TreeMap?
对于在Map中插入、删除和定位元素这类操作,HashMap是 好的选择。然
而,假如你需要对一个有序的key集合进行遍历,TreeMap是更好的选择。基于你的collection的大小,也许向HashMap中添加元素会更快,将map换为TreeMap进行有序key的遍历
8、 HashMap 和 ConcurrentHashMap 的区别
-
ConcurrentHashMap对整个桶数组进行了分割分段(Segment),然后在每一个分段上都用lock锁进行保护,相对于HashTable的synchronized 锁的粒度更精细了一些,并发性能更好,而HashMap没有锁机制,不是线程安全的。(JDK1.8之后ConcurrentHashMap启了一种全新的方式实现,利用CAS算法。)
-
HashMap的键值对允许有null,但是ConCurrentHashMap都不允许。
三、并发编程
1、并发编程的优缺点为什么要使用并发编程(并发编程的优点)
- 充分利用多核CPU的计算能力:通过并发编程的形式可以将多核CPU 的计算能力发挥到极致,性能得到提升
- 方便进行业务拆分,提升系统并发能力和性能:在特殊的业务场景下,先天的就适合于并发编程。现在的系统动不动就要求百万级甚至千万级的并发量,而多线程并发编程正是开发高并发系统的基础,利用好多线程机制可以大大提高系统整体的并发能力以及性能。面对复杂业务模型,并行程序会比串行程序更适应业务需求,而并发编程更能吻合这种业务拆分 。
2、并发编程有什么缺点
并发编程的目的就是为了能提高程序的执行效率,提高程序运行速度,但是并发编程并不总是能提高程序运行速度的,而且并发编程可能会遇到很多问题,
比如:内存泄漏、上下文切换、线程安全、死锁**等问题。
3、并发编程三要素是什么?在 Java 程序中怎么保证多线程的运行安全?
并发编程三要素(线程的安全性问题体现在):
- 原子性:原子,即一个不可再被分割的颗粒。原子性指的是一个或多个操作要么 全部执行成功要么全部执行失败。
- 可见性:一个线程对共享变量的修改,另一个线程能够立刻看到。 (synchronized,volatile)
- 有序性:程序执行的顺序按照代码的先后顺序执行。(处理器可能会对指令进行 重排序)
出现线程安全问题的原因:
- 线程切换带来的原子性问题
- 缓存导致的可见性问题
- 编译优化带来的有序性问题
解决办法:
- JDK Atomic开头的原子类、synchronized、LOCK,可以解决原子性问题
- synchronized、volatile、LOCK,可以解决可见性问题
- Happens-Before 规则可以解决有序性问题
4、并行和并发有什么区别?
- 并发:多个任务在同一个 CPU 核上,按细分的时间片轮流(交替)执行,从逻辑 上来看那些任务是同时执行。
- 并行:单位时间内,多个处理器或多核处理器同时处理多个任务,是真正意义上 的“同时进行”。
- 串行:有n个任务,由一个线程按顺序执行。由于任务、方法都在一个线程执行 所以不存在线程不安全情况,也就不存在临界区的问题。
做一个形象的比喻:
并发 = 两个队列和一台咖啡机。
并行 = 两个队列和两台咖啡机。
串行 = 一个队列和一台咖啡机。
5、什么是多线程,多线程的优劣?
多线程:多线程是指程序中包含多个执行流,即在一个程序中可以同时运行多个 不同的线程来执行不同的任务。
多线程的好处: 可以提高 CPU 的利用率。在多线程程序中,一个线程必须等待的时候,CPU 可 以运行其它的线程而不是等待,这样就大大提高了程序的效率。也就是说允许单 个程序创建多个并行执行的线程来完成各自的任务。
多线程的劣势:
- 线程也是程序,所以线程需要占用内存,线程越多占用内存也越多;
- 多线程需要协调和管理,所以需要 CPU 时间跟踪线程;
- 线程之间对共享资源的访问会相互影响,必须解决竞用共享资源的问 题。
6、线程和进程区别 什么是线程和进程?
进程 :
一个在内存中运行的应用程序。每个进程都有自己独立的一块内存空间,一个进 程可以有多个线程,比如在Windows系统中,一个运行的xx.exe就是一个进 程。
线程:
进程中的一个执行任务(控制单元),负责当前进程中程序的执行。一个进程至 少有一个线程,一个进程可以运行多个线程,多个线程可共享数据。
进程与线程的区别 :
线程具有许多传统进程所具有的特征,故又称为轻型进程(Light—Weight Process)或进程元;而把传统的进程称为重型进程(Heavy—Weight Process), 它相当于只有一个线程的任务。在引入了线程的操作系统中,通常一个进程都有 若干个线程,至少包含一个线程。
根本区别:进程是操作系统资源分配的基本单位,而线程是处理器任务调度和执 行的基本单位
资源开销:每个进程都有独立的代码和数据空间(程序上下文),程序之间的切 换会有较大的开销;线程可以看做轻量级的进程,同一类线程共享代码和数据空 间,每个线程都有自己独立的运行栈和程序计数器(PC),线程之间切换的开 销小。
包含关系:如果一个进程内有多个线程,则执行过程不是一条线的,而是多条线 (线程)共同完成的;线程是进程的一部分,所以线程也被称为轻权进程或者轻 量级进程。
内存分配:同一进程的线程共享本进程的地址空间和资源,而进程之间的地址空 间和资源是相互独立的
影响关系:一个进程崩溃后,在保护模式下不会对其他进程产生影响,但是一个 线程崩溃整个进程都死掉。所以多进程要比多线程健壮。
执行过程:每个独立的进程有程序运行的入口、顺序执行序列和程序出口。但是 线程不能独立执行,必须依存在应用程序中,由应用程序提供多个线程执行控 制,两者均可并发执行
7、什么是上下文切换?
多线程编程中一般线程的个数都大于 CPU 核心的个数,而一个 CPU 核心在任 意时刻只能被一个线程使用,为了让这些线程都能得到有效执行,CPU 采取的 策略是为每个线程分配时间片并轮转的形式。当一个线程的时间片用完的时候就 会重新处于就绪状态让给其他线程使用,这个过程就属于一次上下文切换。
概括来说就是:当前任务在执行完 CPU 时间片切换到另一个任务之前会先保存 自己的状态,以便下次再切换回这个任务时,可以再加载这个任务的状态。任务从保存到再加载的过程就是一次上下文切换。
上下文切换通常是计算密集型的。也就是说,它需要相当可观的处理器时间,在 每秒几十上百次的切换中,每次切换都需要纳秒量级的时间。所以,上下文切换 对系统来说意味着消耗大量的 CPU 时间,事实上,可能是操作系统中时间消耗最大的操作。
Linux 相比与其他操作系统(包括其他类 Unix 系统)有很多的优点,其中有一 项就是,其上下文切换和模式切换的时间消耗非常少。
8、守护线程和用户线程有什么区别呢?
守护线程和用户线程
- 用户 (User) 线程:运行在前台,执行具体的任务,如程序的主线程、连接网 络的子线程等都是用户线程
- 守护 (Daemon) 线程:运行在后台,为其他前台线程服务。也可以说守护 线程是 JVM 中非守护线程的 “佣人”。一旦所有用户线程都结束运行,守护线程 会随 JVM 一起结束工作
main 函数所在的线程就是一个用户线程啊,main 函数启动的同时在 JVM 内部 同时还启动了好多守护线程,比如垃圾回收线程。 比较明显的区别之一是用户线程结束,JVM 退出,不管这个时候有没有守护线 程运行。而守护线程不会影响 JVM 的退出。
注意事项:
- setDaemon(true)必须在start()方法前执行,否则会抛出 IllegalThreadStateException 异常
- 在守护线程中产生的新线程也是守护线程
- 不是所有的任务都可以分配给守护线程来执行,比如读写操作或者计算 逻辑
- 守护 (Daemon) 线程中不能依靠 finally 块的内容来确保执行关闭或清 理资源的逻辑。因为我们上面也说过了一旦所有用户线程都结束运行,守 护线程会随 JVM 一起结束工作,所以守护 (Daemon) 线程中的 finally 语 句块可能无法被执行。
9、如何在 Windows 和 Linux 上查找哪个线程cpu利用率最高?
windows上面用任务管理器看,linux下可以用 top 这个工具看。
- 找出cpu耗用厉害的进程pid, 终端执行top命令,然后按下shift+p 查 找出cpu利用厉害的pid号
- 根据上面第一步拿到的pid号,top -H -p pid 。然后按下shift+p,查 找出cpu利用率厉害的线程号,比如top -H -p 1328
- 将获取到的线程号转换成16进制,去百度转换一下就行
- 使用jstack工具将进程信息打印输出,jstack pid号 > /tmp/t.dat,比 如jstack 31365 > /tmp/t.dat
- 编辑/tmp/t.dat文件,查找线程号对应的信息
10、 什么是线程死锁 ?
百度百科:死锁是指两个或两个以上的进程(线程)在执行过程中,由于竞争资 源或者由于彼此通信而造成的一种阻塞的现象,若无外力作用,它们都将无法推 进下去。此时称系统处于死锁状态或系统产生了死锁,这些永远在互相等待的进 程(线程)称为死锁进程(线程)。
多个线程同时被阻塞,它们中的一个或者全部都在等待某个资源被释放。由于线 程被无限期地阻塞,因此程序不可能正常终止。
线程 A 持有资源 2,线程 B 持有资源 1,他们同时都想申请对方 的资源,所以这两个线程就会互相等待而进入死锁状态。
形成死锁的四个必要条件是什么
- 互斥条件:线程(进程)对于所分配到的资源具有排它性,即一个资源只 能被一个线程(进程)占用,直到被该线程(进程)释放
- 请求与保持条件:一个线程(进程)因请求被占用资源而发生阻塞时,对 已获得的资源保持不放。
- 不剥夺条件:线程(进程)已获得的资源在末使用完之前不能被其他线程 强行剥夺,只有自己使用完毕后才释放资源。
- 循环等待条件:当发生死锁时,所等待的线程(进程)必定会形成一个环 路(类似于死循环),造成永久阻塞
如何避免线程死锁
我们只要破坏产生死锁的四个条件中的其中一个就可以了。
破坏互斥条件
这个条件我们没有办法破坏,因为我们用锁本来就是想让他们互斥的(临界资源 需要互斥访问)。
破坏请求与保持条件
一次性申请所有的资源。
破坏不剥夺条件
占用部分资源的线程进一步申请其他资源时,如果申请不到,可以主动释放它占 有的资源。
破坏循环等待条件
靠按序申请资源来预防。按某一顺序申请资源,释放资源则反序释放。破坏循环 等待条件。
11、 创建线程有哪几种方式?
创建线程有四种方式:
- 继承 Thread 类;
- 实现 Runnable 接口;
- 实现 Callable 接口;
- 使用 Executors 工具类创建线程池继承 Thread 类
12、 线程的 run()和 start()有什么区别?
每个线程都是通过某个特定Thread对象所对应的方法run()来完成其操作的, run()方法称为线程体。通过调用Thread类的start()方法来启动一个线程。 start() 方法用于启动线程,run() 方法用于执行线程的运行时代码。run() 可以重复调用,而 start() 只能调用一次。 start()方法来启动一个线程,真正实现了多线程运行。调用start()方法无需等待 run方法体代码执行完毕,可以直接继续执行其他的代码; 此时线程是处于就绪状态,并没有运行。 然后通过此Thread类调用方法run()来完成其运行状态, run()方法运行结束, 此线程终止。然后CPU再调度其它线程。
run()方法是在本线程里的,只是线程里的一个函数,而不是多线程的。 如果直接调用run(),其实就相当于是调用了一个普通函数而已,直接待用run()方法必须等待run()方法执行完毕才能执行下面的代码,所以执行路径还是只有一条,根本就没有线程的特征,所以在多线程执行时要使用start()方法而不是run()方法。
13、 为什么我们调用 start() 方法时会执行 run() 方法,为什么我们不能直接调用 run() 方法?
这是另一个非常经典的 java 多线程面试问题,而且在面试中会经常被问到。很简单,但是很多人都会答不上来!
new 一个 Thread,线程进入了新建状态。调用 start() 方法,会启动一个线程并使线程进入了就绪状态,当分配到时间片后就可以开始运行了。 start() 会执行线程的相应准备工作,然后自动执行 run() 方法的内容,这是真正的多线程工作。
而直接执行 run() 方法,会把 run 方法当成一个 main 线程下的普通方法去执行,并不会在某个线程中执行它,所以这并不是多线程工作。
总结: 调用 start 方法方可启动线程并使线程进入就绪状态,而 run 方法只是 thread 的一个普通方法调用,还是在主线程里执行。
14、 什么是 Callable 和 Future?
Callable 接口类似于 Runnable,从名字就可以看出来了,但是 Runnable 不会返回结果,并且无法抛出返回结果的异常,而 Callable 功能更强大一些,被线程执行后,可以返回值,这个返回值可以被 Future 拿到,也就是说,Future 可以拿到异步执行任务的返回值。
Future 接口表示异步任务,是一个可能还没有完成的异步任务的结果。所以说Callable用于产生结果,Future 用于获取结果。
15、什么是 FutureTask?
FutureTask 表示一个异步运算的任务。FutureTask 里面可以传入一个 Callable 的具体实现类,可以对这个异步运算的任务的结果进行等待获取、判断是否已经完成、取消任务等操作。只有当运算完成的时候结果才能取回,如果运算尚未完成 get 方法将会阻塞。一个 FutureTask 对象可以对调用了Callable 和 Runnable 的对象进行包装,由于 FutureTask 也是Runnable 接口的实现类,所以 FutureTask 也可以放入线程池中。
16、说说线程的生命周期及五种基本状态?
网上对线程状态的描述很多,有5种,6种,7种,都可以接受。
5中状态一般是针对传统的线程状态来说(操作系统层面):
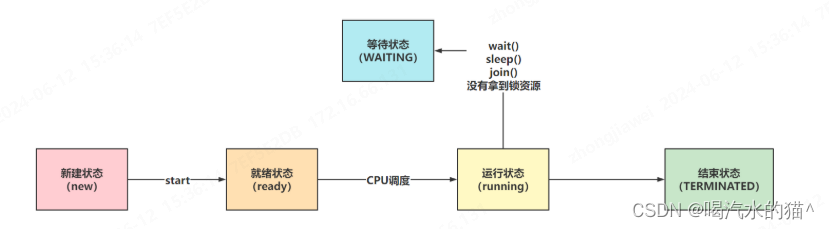
Java中给线程准备的6种状态:
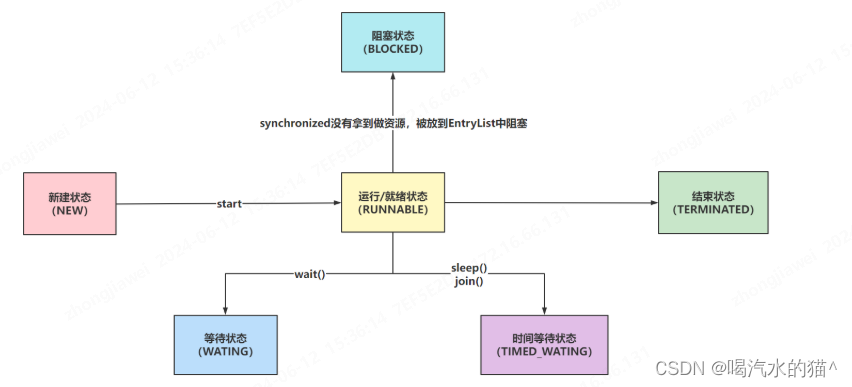
- NEW:Thread对象被创建出来了,但是还没有执行start方法。
- RUNNABLE:Thread对象调用了start方法,就为RUNNABLE状态(CPU调度/没有调度)
- BLOCKED、WAITING、TIME_WAITING:都可以理解为是阻塞、等待状态,因为处在这三种状态下,CPU不会调度当前线程
- BLOCKED:synchronized没有拿到同步锁,被阻塞的情况
- WAITING:调用wait方法就会处于WAITING状态,需要被手动唤醒
- TIME_WAITING:调用sleep方法或者join方法,会被自动唤醒,无需手动唤醒
- TERMINATED:run方法执行完毕,线程生命周期到头了
在Java代码中验证一下效果
NEW:
public static void main(String[] args) throws InterruptedException {Thread t1 = new Thread(() -> {});System.out.println(t1.getState());
}
RUNNABLE:
public static void main(String[] args) throws InterruptedException {Thread t1 = new Thread(() -> {while(true){}});t1.start();Thread.sleep(500);System.out.println(t1.getState());
}
BLOCKED:
public static void main(String[] args) throws InterruptedException {Object obj = new Object();Thread t1 = new Thread(() -> {// t1线程拿不到锁资源,导致变为BLOCKED状态synchronized (obj){}});// main线程拿到obj的锁资源synchronized (obj) {t1.start();Thread.sleep(500);System.out.println(t1.getState());}
}
WAITING:
public static void main(String[] args) throws InterruptedException {Object obj = new Object();Thread t1 = new Thread(() -> {synchronized (obj){try {obj.wait();} catch (InterruptedException e) {e.printStackTrace();}}});t1.start();Thread.sleep(500);System.out.println(t1.getState());
}
TIMED_WAITING:
public static void main(String[] args) throws InterruptedException {Thread t1 = new Thread(() -> {try {Thread.sleep(1000);} catch (InterruptedException e) {e.printStackTrace();}});t1.start();Thread.sleep(500);System.out.println(t1.getState());
}
TERMINATED:
public static void main(String[] args) throws InterruptedException {Thread t1 = new Thread(() -> {try {Thread.sleep(500);} catch (InterruptedException e) {e.printStackTrace();}});t1.start();Thread.sleep(1000);System.out.println(t1.getState());
}
17、 sleep() 和 wait() 有什么区别?
两者都可以暂停线程的执行
- 类的不同:sleep() 是 Thread线程类的静态方法,wait() 是 Object类的方法。
- 是否释放锁:sleep() 不释放锁;wait() 释放锁。
- 用途不同:Wait 通常被用于线程间交互/通信,sleep 通常被用于暂停执行。
- 用法不同:wait() 方法被调用后,线程不会自动苏醒,需要别的线程调用同一个对象上的 notify() 或者 notifyAll() 方法。sleep() 方法执行完成后,线程会自动苏醒。或者可以使用wait(long timeout)超时后线程会自动苏醒。
18、 如何停止一个正在运行的线程?
在java中有以下3种方法可以终止正在运行的线程:
- 使用退出标志,使线程正常退出,也就是当run方法完成后线程终止。
- 使用stop方法强行终止,但是不推荐这个方法,因为stop和suspend及 resume一样都是过期作废的方法。
- 使用interrupt方法中断线程。
19、 Java 中 interrupted 和 isInterrupted 方法的区别?
interrupt:用于中断线程。调用该方法的线程的状态为将被置为”中断”状态。注意:线程中断仅仅是置线程的中断状态位,不会停止线程。需要用户自己去监视线程的状态为并做处理。支持线程中断的方法(也就是线程中断后会抛出interruptedException 的方法)就是在监视线程的中断状态,一旦线程的中断状态被置为“中断状态”,就会抛出中断异常。
interrupted:是静态方法,查看当前中断信号是true还是false并且清除中断信号。如果一个线程被中断了,第一次调用 interrupted 则返回 true,第二次和后面的就返回 false 了。
isInterrupted:查看当前中断信号是true还是false
20、 notify() 和 notifyAll() 有什么区别?
如果线程调用了对象的 wait()方法,那么线程便会处于该对象的等待池中,等待池中的线程不会去竞争该对象的锁。
notifyAll() 会唤醒所有的线程,notify() 只会唤醒一个线程。
notifyAll() 调用后,会将全部线程由等待池移到锁池,然后参与锁的竞争,竞争成功则继续执行,如果不成功则留在锁池等待锁被释放后再次参与竞争。而 notify()只会唤醒一个线程,具体唤醒哪一个线程由虚拟机控制。如何在两个线程间共享数据?在两个线程间共享变量即可实现共享。
21、 Java 线程数过多会造成什么异常?
-
线程的生命周期开销非常高消耗过多的
-
CPU资源如果可运行的线程数量多于可用处理器的数量,那么有线程将会被闲置。大量空闲的线程会占用许多内存,给垃圾回收器带来压力,而且大量的线程在竞争CPU资源时还将产生其他性能的开销。
-
降低稳定性JVM 在可创建线程的数量上存在一个限制,这个限制值将随着平台的不同而不同,并且承受着多个因素制约,包括 JVM 的启动参数、Thread 构造函数中请求栈的大小,以及底层操作系统对线程的限制等。如果破坏了这些限制,那么可能抛出OutOfMemoryError 异常。
22、synchronized 的作用?
synchronized 可以修饰类、方法、变量。
在 Java 中,synchronized 关键字是用来控制线程同步的,就是在多线程的环境下,控制 synchronized 代码段不被多个线程同时执行。
另外,在 Java 早期版本中,synchronized属于重量级锁,效率低下,因为监视器锁(monitor)是依赖于底层的操作系统的 Mutex Lock 来实现的,Java 的线程是映射到操作系统的原生线程之上的。如果要挂起或者唤醒一个线程,都需要操作系统帮忙完成,而操作系统实现线程之间的切换时需要从用户态转换到内核态,这个状态之间的转换需要相对比较长的时间,时间成本相对较高,这也是为什么早期的 synchronized 效率低的原因。
庆幸的是在 Java 6 之后 Java 官方对从 JVM 层面对synchronized 较大优化,所以现在的synchronized 锁效率也优化得很不错了。JDK1.6对锁的实现引入了大量的优化,如自旋锁、适应性自旋锁、锁消除、锁粗化、偏向锁、轻量级锁等技术来减少锁操作的开销。
23、 synchronized、volatile、CAS 比较?
(1)synchronized 是悲观锁,属于抢占式,会引起其他线程阻塞。
(2)volatile 提供多线程共享变量可见性和禁止指令重排序优化。
(3)CAS 是基于冲突检测的乐观锁(非阻塞)
24、synchronized 和 Lock 有什么区别?
- 首先synchronized是Java内置关键字,在JVM层面,Lock是个Java类;
- synchronized 可以给类、方法、代码块加锁;而 lock 只能给代码块加锁。
- synchronized 不需要手动获取锁和释放锁,使用简单,发生异常会自动释放锁,不会造成死锁;而 lock 需要自己加锁和释放锁,如果使用不当没有 unLock()去释放锁就会造成死锁。
- 通过 Lock 可以知道有没有成功获取锁,而 synchronized 却无法办到。
25、 synchronized 和 ReentrantLock 区别是什么?
synchronized 是和 if、else、for、while 一样的关键字,ReentrantLock 是类,这是二者的本质区别。既然 ReentrantLock 是类,那么它就提供了比synchronized 更多更灵活的特性,可以被继承、可以有方法、可以有各种各样的类变量synchronized 早期的实现比较低效,对比 ReentrantLock,大多数场景性能都相差较大,但是在 Java 6 中对 synchronized 进行了非常多的改进。
相同点:
两者都是可重入锁两者都是可重入锁。“可重入锁”概念是:自己可以再次获取自己的内部锁。比如一个线程获得了某个对象的锁,此时这个对象锁还没有释放,当其再次想要获取这个对象的锁的时候还是可以获取的,如果不可锁重入的话,就会造成死锁。
同一个线程每次获取锁,锁的计数器都自增1,所以要等到锁的计数器下降为0 时才能释放锁。主要区别如下:
- ReentrantLock 使用起来比较灵活,但是必须有释放锁的配合动作;
- ReentrantLock 必须手动获取与释放锁,而 synchronized 不需要手动释放和开启锁;
- ReentrantLock 只适用于代码块锁,而 synchronized 可以修饰类、方法、变量等。
- 二者的锁机制其实也是不一样的。ReentrantLock 底层调用的是 Unsafe 的 park 方法加锁,synchronized 操作的应该是对象头中 mark word
- Java中每一个对象都可以作为锁,这是synchronized实现同步的基础: 普通同步方法,锁是当前实例对象
- 静态同步方法,锁是当前类的class对象
- 同步方法块,锁是括号里面的对象
26、 volatile 关键字的作用
- 对于可见性,Java 提供了 volatile 关键字来保证可见性和禁止指令重排。
- volatile 提供 happens-before 的保证,确保一个线程的修改能对其他线程是可见的。当一个共享变量被 volatile 修饰时,它会保证修改的值会立即被更新到主存,当有其他线程需要读取时,它会去内存中读取新值。
- volatile 常用于多线程环境下的单次操作(单次读或者单次写)。
27、什么是AQS?
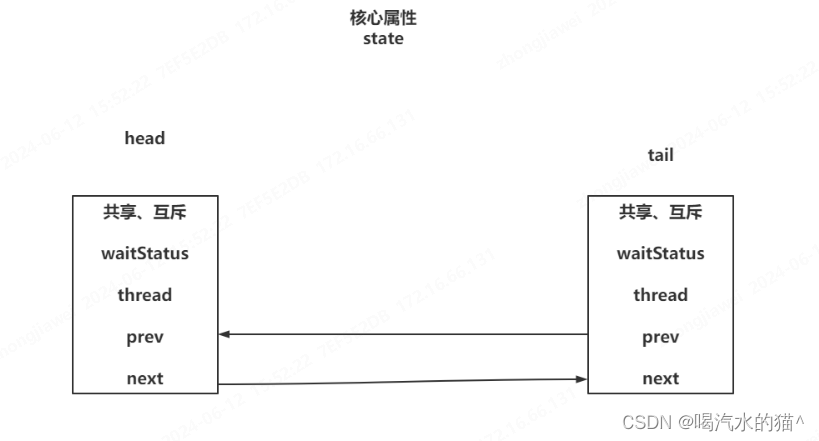
AQS就是AbstractQueuedSynchronizer抽象类,AQS其实就是JUC包下的一个基类,JUC下的很多内容都是基于AQS实现了部分功能,比如ReentrantLock,ThreadPoolExecutor,阻塞队列,CountDownLatch,Semaphore,CyclicBarrier等等都是基于AQS实现。
首先AQS中提供了一个由volatile修饰,并且采用CAS方式修改的int类型的state变量。
其次AQS中维护了一个双向链表,有head,有tail,并且每个节点都是Node对象。
AQS内部结构和属性:
28、ThreadLocal 是什么?有哪些使用场景?
hreadLocal 是一个本地线程副本变量工具类,在每个线程中都创建了一个ThreadLocalMap 对象,简单说 ThreadLocal 就是一种以空间换时间的做法,每个线程可以访问自己内部 ThreadLocalMap 对象内的 value。通过这种方式,避免资源在多线程间共享。
原理:线程局部变量是局限于线程内部的变量,属于线程自身所有,不在多个线程间共享。Java提供ThreadLocal类来支持线程局部变量,是一种实现线程安全的方式。但是在管理环境下(如 web 服务器)使用线程局部变量的时候要特别小心,在这种情况下,工作线程的生命周期比任何应用变量的生命周期都要长。
任何线程局部变量一旦在工作完成后没有释放,Java 应用就存在内存泄露的风险。
经典的使用场景是为每个线程分配一个 JDBC 连接 Connection。这样就可以保证每个线程的都在各自的 Connection 上进行数据库的操作,不会出现 A 线程关了 B线程正在使用的 Connection; 还有 Session 管理 等问题。
29、 ThreadLocal造成内存泄漏的原因?
ThreadLocalMap 中使用的 key 为 ThreadLocal 的弱引用,而 value 是强引用。所以,如果 ThreadLocal 没有被外部强引用的情况下,在垃圾回收的时候,key 会被清理掉,而 value 不会被清理掉。这样一来,ThreadLocalMap 中就会出现key 为null的Entry。假如我们不做任何措施的话,value 永远无法被GC 回收,这个时候就可能会产生内存泄露。ThreadLocalMap实现中已经考虑了这种情况,在调用 set()、get()、remove() 方法的时候,会清理掉 key 为 null 的记录。使用完ThreadLocal方法后手动调用remove()方法。
ThreadLocal内存泄漏解决方案?
- 每次使用完ThreadLocal,都调用它的remove()方法,清除数据。
- 在使用线程池的情况下,没有及时清理ThreadLocal,不仅是内存泄漏的问题,更严重的是可能导致业务逻辑出现问题。所以,使用ThreadLocal就跟加锁完要解锁一样,用完就清理。
30、 线程池有什么优点?
- 降低资源消耗:重用存在的线程,减少对象创建销毁的开销。
- 提高响应速度。可有效的控制 大并发线程数,提高系统资源的使用率,同时避免过多资源竞争,避免堵塞。当任务到达时,任务可以不需要的等到线程创建就能立即执行。
- 提高线程的可管理性。线程是稀缺资源,如果无限制的创建,不仅会消耗系统资源,还会降低系统的稳定性,使用线程池可以进行统一的分配,调优和监控。
- 附加功能:提供定时执行、定期执行、单线程、并发数控制等功能。综上所述使用线程池框架 Executor 能更好的管理线程、提供系统资源使用率。
31、 线程池都有哪些状态?
- RUNNING:这是 正常的状态,接受新的任务,处理等待队列中的任务。 SHUTDOWN:不接受新的任务提交,但是会继续处理等待队列中的任务。
- STOP:不接受新的任务提交,不再处理等待队列中的任务,中断正在执行任务的线程。
- TIDYING:所有的任务都销毁了,workCount 为 0,线程池的状态在转换为
- TIDYING 状态时,会执行钩子方法 terminated()。
- TERMINATED:terminated()方法结束后,线程池的状态就会变成这个。
32、 Executors和ThreaPoolExecutor创建线程池的区别
《阿里巴巴Java开发手册》中强制线程池不允许使用 Executors 去创建,而是通过ThreadPoolExecutor 的方式,这样的处理方式让写的同学更加明确线程池的运行规则,规避资源耗尽的风险
Executors 各个方法的弊端:
- newFixedThreadPool 和 newSingleThreadExecutor:
主要问题是堆积的请求处理队列可能会耗费非常大的内存,甚至 OOM。 - newCachedThreadPool 和 newScheduledThreadPool:
主要问题是线程数 大数是 Integer.MAX_VALUE,可能会创建数量非常多的线程,甚至 OOM。
ThreaPoolExecutor创建线程池方式只有一种,就是走它的构造函数,参数自己指定。
33、ThreadPoolExecutor参数说明?
1、corePoolSize:核心线程数* 核心线程会一直存活,及时没有任务需要执行* 当线程数小于核心线程数时,即使有线程空闲,线程池也会优先创建新线程处理* 设置allowCoreThreadTimeout=true(默认false)时,核心线程会超时关闭2、queueCapacity:任务队列容量(阻塞队列)* 当核心线程数达到最大时,新任务会放在队列中排队等待执行3、maxPoolSize:最大线程数* 当线程数>=corePoolSize,且任务队列已满时。线程池会创建新线程来处理任务* 当线程数=maxPoolSize,且任务队列已满时,线程池会拒绝处理任务而抛出异常4、 keepAliveTime:线程空闲时间* 当线程空闲时间达到keepAliveTime时,线程会退出,直到线程数量=corePoolSize* 如果allowCoreThreadTimeout=true,则会直到线程数量=05、allowCoreThreadTimeout:允许核心线程超时
6、rejectedExecutionHandler:任务拒绝处理器* 两种情况会拒绝处理任务:- 当线程数已经达到maxPoolSize,切队列已满,会拒绝新任务- 当线程池被调用shutdown()后,会等待线程池里的任务执行完毕,再shutdown。如果在调用shutdown()和线程池真正shutdown之间提交任务,会拒绝新任务* 线程池会调用rejectedExecutionHandler来处理这个任务。如果没有设置默认是AbortPolicy,会抛出异常* ThreadPoolExecutor类有几个内部实现类来处理这类情况:- AbortPolicy 丢弃任务,抛运行时异常- CallerRunsPolicy 执行任务- DiscardPolicy 忽视,什么都不会发生- DiscardOldestPolicy 从队列中踢出最先进入队列(最后一个执行)的任务* 实现RejectedExecutionHandler接口,可自定义处理器
34、 ThreadPoolExecutor执行顺序
线程池按以下行为执行任务
1. 当线程数小于核心线程数时,创建线程。
2. 当线程数大于等于核心线程数,且任务队列未满时,将任务放入任务队列。
3. 当线程数大于等于核心线程数,且任务队列已满-1 若线程数小于最大线程数,创建线程-2 若线程数等于最大线程数,抛出异常,拒绝任务
35、 并发工具
1、CycliBarriar 和 CountdownLatch 有什么区别?
CountDownLatch与CyclicBarrier都是用于控制并发的工具类,都可以理解成维护的就是一个计数器,但是这两者还是各有不同侧重点的:
- CountDownLatch一般用于某个线程A等待若干个其他线程执行完任务之后,它才执行;而CyclicBarrier一般用于一组线程互相等待至某个状态,然后这一组线程再同时执行;CountDownLatch强调一个线程等多个线程完成某件事情。CyclicBarrier是多个线程互等,等大家都完成,再携手共进。
- 调用CountDownLatch的countDown方法后,当前线程并不会阻塞,会继续往下执行;而调用CyclicBarrier的await方法,会阻塞当前线程,直到CyclicBarrier指定的线程全部都到达了指定点的时候,才能继续往下执行;
- CountDownLatch方法比较少,操作比较简单,而CyclicBarrier提供的方法更多,比如能够通过getNumberWaiting(),isBroken()这些方法获取当前多个线程的状态,并且CyclicBarrier的构造方法可以传入 barrierAction,指定当所有线程都到达时执行的业务功能;
- CountDownLatch是不能复用的,而CyclicLatch是可以复用的。
2、 Semaphore
Semaphore 就是一个信号量,它的作用是限制某段代码块的并发数。
Semaphore有一个构造函数,可以传入一个 int 型整数 n,表示某段代码 多只有 n 个线程可以访问,如果超出了 n,那么请等待,等到某个线程执行完毕这段代码块,下一个线程再进入。由此可以看出如果 Semaphore 构造函数中传入的 int 型整数 n=1,相当于变成了一个 synchronized 了。
Semaphore(信号量)-允许多个线程同时访问: synchronized 和
ReentrantLock 都是一次只允许一个线程访问某个资源,Semaphore(信号量) 可以指定多个线程同时访问某个资源。
3、 Exchanger
Exchanger是一个用于线程间协作的工具类,用于两个线程间交换数据。它提供了一个交换的同步点,在这个同步点两个线程能够交换数据。交换数据是通过 exchange方法来实现的,如果一个线程先执行exchange方法,那么它会同步等待另一个线程也执行exchange方法,这个时候两个线程就都达到了同步点,两个线程就可以交换数据。
36、常用的并发工具类有哪些?
- Semaphore(信号量)-允许多个线程同时访问: synchronized 和ReentrantLock 都是一次只允许一个线程访问某个资源,Semaphore(信号量)可以指定多个线程同时访问某个资源。
- CountDownLatch(倒计时器): CountDownLatch是一个同步工具类,用来协调多个线程之间的同步。这个工具通常用来控制线程等待,它可以让某一个线程等待直到倒计时结束,再开始执行。
- CyclicBarrier(循环栅栏): CyclicBarrier 和 CountDownLatch 非常类似,它也可以实现线程间的技术等待,但是它的功能比 CountDownLatch 更加复杂和强大。主要应用场景和 CountDownLatch 类似。CyclicBarrier 的字面意思是可循环使用(Cyclic)的屏障(Barrier)。它要做的事情是,让一组线程到达一个屏障(也可以叫同步点)时被阻塞,直到 后一个线程到达屏障时,屏障才会开门,所有被屏障拦截的线程才会继续干活。CyclicBarrier默认的构造方法是 CyclicBarrier(int parties),其参数表示屏障拦截的线程数量,每个线程调用await()方法告诉
- CyclicBarrier 我已经到达了屏障,然后当前线程被阻塞。
四、Spinrg
1、什么是spring?
Spring是一个轻量级Java开发框架,最早由Rod Johnson创建,目的是为了解 决企业级应用开发的业务逻辑层和其他各层的耦合问题。它是一个分层的 JavaSE/JavaEE full-stack(一站式)轻量级开源框架,为开发Java应用程序提 供全面的基础架构支持。Spring负责基础架构,因此Java开发者可以专注于应 用程序的开发。 Spring最根本的使命是解决企业级应用开发的复杂性,即简化Java开发。
Spring可以做很多事情,它为企业级开发提供给了丰富的功能,但是这些功能 的底层都依赖于它的两个核心特性,也就是依赖注入(dependency injection,DI)和面向切面编程(aspect-oriented programming, AOP)。
为了降低Java开发的复杂性,Spring采取了以下4种关键策略:
- 基于POJO的轻量级和最小侵入性编程;
- 通过依赖注入和面向接口实现松耦合;
- 基于切面和惯例进行声明式编程;
- 通过切面和模板减少样板式代码。
2、Spring框架的设计目标,设计理念,和核心是什么 ?
Spring设计目标:Spring为开发者提供一个一站式轻量级应用开发平台;
Spring设计理念:在JavaEE开发中,支持POJO和JavaBean开发方式,使应用 面向接口开发,充分支持OO(面向对象)设计方法;Spring通过IoC容器实现 对象耦合关系的管理,并实现依赖反转,将对象之间的依赖关系交给IoC容器, 实现解耦;
Spring框架的核心:IoC容器和AOP模块。通过IoC容器管理POJO对象以及他 们之间的耦合关系;通过AOP以动态非侵入的方式增强服务。 IoC让相互协作的组件保持松散的耦合,而AOP编程允许你把遍布于应用各层的 功能分离出来形成可重用的功能组件。
3、Spring的优缺点是什么?
优点
- 方便解耦,简化开发
Spring就是一个大工厂,可以将所有对象的创建和依赖关系的维护,交给 Spring管理。 - AOP编程的支持
Spring提供面向切面编程,可以方便的实现对程序进行权限拦截、运行监控等 功能。 - 声明式事务的支持
只需要通过配置就可以完成对事务的管理,而无需手动编程。 - 方便程序的测试
Spring对Junit4支持,可以通过注解方便的测试Spring程序。 - 方便集成各种优秀框架
Spring不排斥各种优秀的开源框架,其内部提供了对各种优秀框架的直接支持 (如:Struts、Hibernate、MyBatis等)。 - 降低JavaEE API的使用难度
Spring对JavaEE开发中非常难用的一些API(JDBC、JavaMail、远程调用 等),都提供了封装,使这些API应用难度大大降低。
缺点
- Spring明明一个很轻量级的框架,却给人感觉大而全
- Spring依赖反射,反射影响性能
- 使用门槛升高,入门Spring需要较长时间
4、Spring有哪些应用场景?
应用场景:JavaEE企业应用开发,包括SSH、SSM等
Spring价值:
- Spring是非侵入式的框架,目标是使应用程序代码对框架依赖最小化;
- Spring提供一个一致的编程模型,使应用直接使用POJO开发,与运行环境隔离 开来;
- Spring推动应用设计风格向面向对象和面向接口开发转变,提高了代码的重用性 和可测试性;
5、Spring由哪些模块组成?
Spring 总共大约有 20 个模块, 由 1300 多个不同的文件构成。 而这些组件被 分别整合在核心容器(Core Container) 、 AOP(Aspect Oriented Programming) 和设备支持(Instrmentation) 、数据访问与集成(Data Access/Integeration) 、 Web、 消息(Messaging) 、 Test等 6 个模块中。
- spring core:提供了框架的基本组成部分,包括控制反转(Inversion of Control,IOC)和依赖注入(Dependency Injection,DI)功能。
- spring beans:提供了BeanFactory,是工厂模式的一个经典实现,Spring将管 理对象称为Bean。
- spring context:构建于 core 封装包基础上的 context 封装包,提供了一种框 架式的对象访问方法。
- spring jdbc:提供了一个JDBC的抽象层,消除了烦琐的JDBC编码和数据库厂 商特有的错误代码解析, 用于简化JDBC。
- spring aop:提供了面向切面的编程实现,让你可以自定义拦截器、切点等。
- spring Web:提供了针对 Web 开发的集成特性,例如文件上传,利用 servlet listeners 进行 ioc 容器初始化和针对 Web 的 ApplicationContext。
- spring test:主要为测试提供支持的,支持使用JUnit或TestNG对Spring组件进 行单元测试和集成测试。
6、Spring 框架中都用到了哪些设计模式?
- 工厂模式:BeanFactory就是简单工厂模式的体现,用来创建对象的实 例;
- 单例模式:Bean默认为单例模式。
- 代理模式:Spring的AOP功能用到了JDK的动态代理和CGLIB字节码生 成技术;
- 模板方法:用来解决代码重复的问题。比如. RestTemplate, JmsTemplate, JpaTemplate。
- 观察者模式:定义对象键一种一对多的依赖关系,当一个对象的状态发 生改变时,所有依赖于它的对象都会得到通知被制动更新,如Spring中 listener的实现–ApplicationListener。
7、什么是Spring IOC ?
控制反转即IoC (Inversion of Control),它把传统上由程序代码直接操控的对象的调用权交给容器,通过容器来实现对象组件的装配和管理。所谓的“控制反转”概念就是对组件对象控制权的转移,从程序代码本身转移到了外部容器。
Spring IOC 负责创建对象,管理对象(通过依赖注入(DI),装配对象,配置对象,并且管理这些对象的整个生命周期。
8、什么是Spring AOP?
面向切面编程(AOP)就是纵向的编程。比如业务A和业务B现在需要一个相同的操作,传统方法我们可能需要在A、B中都加入相关操作代码,而应用AOP就可以只写一遍代码,A、B共用这段代码。并且,当A、B需要增加新的操作时,可以在不改动原代码的情况下,灵活添加新的业务逻辑实现。
在实际开发中,比如商品查询、促销查询等业务,都需要记录日志、异常处理等操作,AOP把所有共用代码都剥离出来,单独放置到某个类中进行集中管理,在具体运行时,由容器进行动态织入这些公共代码。
AOP主要一般应用于签名验签、参数校验、日志记录、事务控制、权限控制、性能统计、异常处理等。
9、Spring常用注解?
1、@Controller:用于标注控制器层组件
2、@Service:用于标注业务层组件
3、@Component : 用于标注这是一个受 Spring 管理的组件,组件引用名称是类名,第一个字母小写。可以使用@Component(“beanID”) 指定组件的名称
4、@Repository:用于标注数据访问组件,即DAO组件
5、@Bean:方法级别的注解,主要用在@Configuration和@Component注解的类里,@Bean注解的方法会产生一个Bean对象,该对象由Spring管理并放到IoC容器中。引用名称是方法名,也可以用@Bean(name = “beanID”)指定组件名
6、@Scope(“prototype”):将组件的范围设置为原型的(即多例)。保证每一个请求有一个单独的action来处理,避免action的线程问题。
由于Spring默认是单例的,只会创建一个action对象,每次访问都是同一个对象,容易产生并发问题,数据不安全。
7、@Autowired:默认按类型进行自动装配。在容器查找匹配的Bean,当有且仅有一个匹配的Bean时,Spring将其注入@Autowired标注的变量中。
8、@Resource:默认按名称进行自动装配,当找不到与名称匹配的Bean时会按类型装配。
10、 @Autowired和@Resource之间的区别?
@Autowired可用于:构造函数、成员变量、Setter方法
@Autowired和@Resource之间的区别
@Autowired默认是按照类型装配注入的,默认情况下它要求依赖对象必须存在(可以设置它required属性为false)。
@Resource默认是按照名称来装配注入的,只有当找不到与名称匹配的bean才会按照类型来装配注入。
11、@Qualifier 注解有什么作用
当您创建多个相同类型的 bean 并希望仅使用属性装配其中一个 bean 时,您可以使用@Qualifier 注解和 @Autowired 通过指定应该装配哪个确切的 bean 来消除歧义。
12、说一下Spring的事务传播行为?
spring事务的传播行为说的是,当多个事务同时存在的时候,spring如何处理这些事务的行为。
① PROPAGATION_REQUIRED:如果当前没有事务,就创建一个新事务,如果当前存在事务,就加入该事务,该设置是最常用的设置。
② PROPAGATION_SUPPORTS:支持当前事务,如果当前存在事务,就加入该事务,如果当前不存在事务,就以非事务执行。
③ PROPAGATION_MANDATORY:支持当前事务,如果当前存在事务,就加入该事务,如果当前不存在事务,就抛出异常。
④ PROPAGATION_REQUIRES_NEW:创建新事务,无论当前存不存在事务,都创建新事务。
⑤ PROPAGATION_NOT_SUPPORTED:以非事务方式执行操作,如果当前存在事务,就把当前事务挂起。
⑥ PROPAGATION_NEVER:以非事务方式执行,如果当前存在事务,则抛出异常。
⑦ PROPAGATION_NESTED:如果当前存在事务,则在嵌套事务内执行。如果当前没有事务,则按REQUIRED属性执行。
13、 说一下 spring 的事务隔离?
spring 有五大隔离级别,默认值为 ISOLATION_DEFAULT(使用数据库的设置),其他四个隔离级别和数据库的隔离级别一致:
-
ISOLATION_DEFAULT:用底层数据库的设置隔离级别,数据库设置的是什么我就用什么;
-
ISOLATION_READ_UNCOMMITTED:未提交读,最低隔离级别、事务未提交前,就可被其他事务读取(会出现幻读、脏读、不可重复读);
-
ISOLATION_READ_COMMITTED:提交读,一个事务提交后才能被其他事务读取到(会造成幻读、不可重复读),SQL server 的默认级别;
-
ISOLATION_REPEATABLE_READ:可重复读,保证多次读取同一个数据时,其值都和事务开始时候的内容是一致,禁止读取到别的事务未提交的数据(会造成幻读),MySQL 的默认级别;
-
ISOLATION_SERIALIZABLE:序列化,代价最高最可靠的隔离级别,该隔离级别能防止脏读、不可重复读、幻读。
脏读 :表示一个事务能够读取另一个事务中还未提交的数据。比如,某个事务尝试插入记录 A,此时该事务还未提交,然后另一个事务尝试读取到了记录 A。
不可重复读 :是指在一个事务内,多次读同一数据。
幻读 :指同一个事务内多次查询返回的结果集不一样。比如同一个事务 A 第一次查询时候有 n 条记录,但是第二次同等条件下查询却有 n+1 条记录,这就好像产生了幻觉。发生幻读的原因也是另外一个事务新增或者删除或者修改了第一个事务结果集里面的数据,同一个记录的数据内容被修改了,所有数据行的记录就变多或者变少了。
五、Spring MVC
1、什么是Spring MVC?简单介绍下你对Spring MVC的理解?
Spring MVC是一个基于Java的实现了MVC设计模式的请求驱动类型的轻量级 Web框架,通过把模型-视图-控制器分离,将web层进行职责解耦,把复杂的 web应用分成逻辑清晰的几部分,简化开发,减少出错,方便组内开发人员之间 的配合。
2、Spring MVC的优点
(1)可以支持各种视图技术,而不仅仅局限于JSP;
(2)与Spring框架集成(如IoC容器、AOP等);
(3)清晰的角色分配:前端控制器(dispatcherServlet) , 请求到处理器映射 (handlerMapping), 处理器适配器(HandlerAdapter), 视图解析器 (ViewResolver)。
(4) 支持各种请求资源的映射策略。
3、Spring MVC的主要组件?
(1)前端控制器 DispatcherServlet(不需要程序员开发)
作用:接收请求、响应结果,相当于转发器,有了DispatcherServlet 就减少了 其它组件之间的耦合度。
(2)处理器映射器HandlerMapping(不需要程序员开发)
作用:根据请求的URL来查找Handler
(3)处理器适配器HandlerAdapter
注意:在编写Handler的时候要按照HandlerAdapter要求的规则去编写,这样适配器HandlerAdapter才可以正确的去执行Handler。
(4)处理器Handler(需要程序员开发)
(5)视图解析器 ViewResolver(不需要程序员开发)
作用:进行视图的解析,根据视图逻辑名解析成真正的视图(view)
(6)视图View(需要程序员开发jsp)
View是一个接口, 它的实现类支持不同的视图类型(jsp,freemarker,pdf等 等)
4、什么是DispatcherServlet
Spring的MVC框架是围绕DispatcherServlet来设计的,它用来处理所有的 HTTP请求和响应。
5、什么是Spring MVC框架的控制器?
控制器提供一个访问应用程序的行为,此行为通常通过服务接口实现。控制器解 析用户输入并将其转换为一个由视图呈现给用户的模型。Spring用一个非常抽 象的方式实现了一个控制层,允许用户创建多种用途的控制器。
6、Spring MVC的控制器是不是单例模式,如果是,有什么问题,怎么解决?
答:是单例模式,所以在多线程访问的时候有线程安全问题,不要用同步,会影响性 能的,解决方案是在控制器里面不能写字段。
7、请描述Spring MVC的工作流程?描述一下 DispatcherServlet 的工作流程?
(1)用户发送请求至前端控制器DispatcherServlet;
(2) DispatcherServlet收到请求后,调用HandlerMapping处理器映射器, 请求获取Handle;
(3)处理器映射器根据请求url找到具体的处理器,生成处理器对象及处理器拦 截器(如果有则生成)一并返回给DispatcherServlet;
(4)DispatcherServlet 调用 HandlerAdapter处理器适配器;
(5)HandlerAdapter 经过适配调用 具体处理器(Handler,也叫后端控制 器);
(6)Handler执行完成返回ModelAndView;
(7)HandlerAdapter将Handler执行结果ModelAndView返回给 DispatcherServlet;
(8)DispatcherServlet将ModelAndView传给ViewResolver视图解析器进行 解析;
(9)ViewResolver解析后返回具体View;
(10)DispatcherServlet对View进行渲染视图(即将模型数据填充至视图中)
(11)DispatcherServlet响应用户。
8、MVC是什么?MVC设计模式的好处有哪些
mvc是一种设计模式(设计模式就是日常开发中编写代码的一种好的方法和经验 的总结)。模型(model)-视图(view)-控制器(controller),三层架构的 设计模式。用于实现前端页面的展现与后端业务数据处理的分离。
mvc设计模式的好处
1.分层设计,实现了业务系统各个组件之间的解耦,有利于业务系统的可扩展 性,可维护性。
2.有利于系统的并行开发,提升开发效率。
9、 Spring MVC常用的注解有哪些?
@RequestMapping:用于处理请求 url 映射的注解,可用于类或方法上。用 于类上,则表示类中的所有响应请求的方法都是以该地址作为父路径。
@RequestBody:注解实现接收http请求的json数据,将json转换为java对 象。
@ResponseBody:注解实现将conreoller方法返回对象转化为json对象响应给 客户。
10、 @Controller注解的作用
在Spring MVC 中,控制器Controller 负责处理由DispatcherServlet 分发的请求,它把用户请求的数据经过业务处理层处理之后封装成一个Model ,然后再把该Model 返回给对应的View 进行展示。
在Spring MVC 中提供了一个非常简便的定义Controller 的方法,你无需继承特定的类或实现特定的接口,只需使用@Controller 标记一个类是Controller ,然后使用@RequestMapping 和 @RequestParam 等一些注解用以定义URL 请求和Controller 方法之间的映射,这样的Controller 就能被外界访问到。
此外Controller 不会直接依赖于HttpServletRequest 和HttpServletResponse 等HttpServlet 对象,它们可以通过Controller 的方法参数灵活的获取到。
@Controller 用于标记在一个类上,使用它标记的类就是一个Spring MVC
Controller 对象。分发处理器将会扫描使用了该注解的类的方法,并检测该方法是否使用了@RequestMapping 注解。@Controller 只是定义了一个控制器类,而使用@RequestMapping 注解的方法才是真正处理请求的处理器。单单使用@Controller 标记在一个类上还不能真正意义上的说它就是Spring MVC 的一个控制器类,因为这个时候Spring 还不认识它。那么要如何做Spring 才能认识它呢?
这个时候就需要我们把这个控制器类交给Spring 来管理。有两种方式:
- 在Spring MVC 的配置文件中定义MyController 的bean 对象。
- 在Spring MVC 的配置文件中告诉Spring 该到哪里去找标记为@Controller 的Controller 控制器。
11、@RequestMapping注解的作用
RequestMapping是一个用来处理请求地址映射的注解,可用于类或方法上。
用于类上,表示类中的所有响应请求的方法都是以该地址作为父路径。
RequestMapping注解有六个属性,下面我们把她分成三类进行说明(下面有相应示例)。
- value: 指定请求的实际地址,指定的地址可以是URI Template 模式(后面将会说明);
- method: 指定请求的method类型, GET、POST、PUT、DELETE等; consumes,produces
- consumes: 指定处理请求的提交内容类型(Content-Type),例如 application/json, text/html;
- produces: 指定返回的内容类型,仅当request请求头中的(Accept)类型中包含该指定类型才返回;
- params: 指定request中必须包含某些参数值是,才让该方法处理。
- headers: 指定request中必须包含某些指定的header值,才能让该方法处理请求。
12、@ResponseBody注解的作用
作用: 该注解用于将Controller的方法返回的对象,通过适当的HttpMessageConverter转换为指定格式后,写入到Response对象的body数据区。
使用时机:返回的数据不是html标签的页面,而是其他某种格式的数据时(如json、xml等)使用;
13、@PathVariable和@RequestParam的区别
请求路径上有个id的变量值,可以通过@PathVariable来获取
@RequestMapping(value = “/page/{id}”, method = RequestMethod.GET)
@RequestParam用来获得静态的URL请求入参 spring注解时action里用到。
六、MyBatis
1. MyBatis是什么?
MyBatis 是一款优秀的持久层框架,一个半 ORM(对象关系映射)框架,它支持定制化 SQL、存储过程以及高级映射。MyBatis 避免了几乎所有的 JDBC 代码和手动设置参数以及 获取结果集。MyBatis 可以使用简单的 XML 或注解来配置和映射原生类型、接口和 Java 的 POJO(Plain Old Java Objects,普通老式 Java 对象)为数据库中的记录。
2. ORM是什么
ORM(Object Relational Mapping),对象关系映射,是一种为了解决关系型数据库数 据与简单Java对象(POJO)的映射关系的技术。简单的说,ORM是通过使用描述对象和 数据库之间映射的元数据,将程序中的对象自动持久化到关系型数据库中。
3. 为什么说Mybatis是半自动ORM映射工具?它与全自动的区别在哪里?
Hibernate属于全自动ORM映射工具,使用Hibernate查询关联对象或者关联集合对象时, 可以根据对象关系模型直接获取,所以它是全自动的。
而Mybatis在查询关联对象或关联集合对象时,需要手动编写sql来完成,所以,称之为半 自动ORM映射工具。
4. 传统JDBC开发存在的问题?
频繁创建数据库连接对象、释放,容易造成系统资源浪费,影响系统性能。可以使用连接池 解决这个问题。但是使用jdbc需要自己实现连接池。
sql语句定义、参数设置、结果集处理存在硬编码。实际项目中sql语句变化的可能性较大, 一旦发生变化,需要修改java代码,系统需要重新编译,重新发布。不好维护。
使用preparedStatement向占有位符号传参数存在硬编码,因为sql语句的where条件不一 定,可能多也可能少,修改sql还要修改代码,系统不易维护。
结果集处理存在重复代码,处理麻烦。如果可以映射成Java对象会比较方便。
5. JDBC编程有哪些不足之处,MyBatis是如何解决这些问题的?
- 数据库链接创建、释放频繁造成系统资源浪费从而影响系统性能,如果使用数据库连接 池可解决此问题。
解决:在mybatis-config.xml中配置数据链接池,使用连接池管理数据库连接。 - Sql语句写在代码中造成代码不易维护,实际应用sql变化的可能较大,sql变动需要改变 java代码。
解决:将Sql语句配置在XXXXmapper.xml文件中与java代码分离。 - 向sql语句传参数麻烦,因为sql语句的where条件不一定,可能多也可能少,占位符需 要和参数一一对应。
解决: Mybatis自动将java对象映射至sql语句。 - 对结果集解析麻烦,sql变化导致解析代码变化,且解析前需要遍历,如果能将数据库记 录封装成pojo对象解析比较方便。
解决:Mybatis自动将sql执行结果映射至java对象。
6. Mybatis优缺点
优点
与传统的数据库访问技术相比,ORM有以下优点:
基于SQL语句编程,相当灵活,不会对应用程序或者数据库的现有设计造成任何影响,SQL 写在XML里,解除sql与程序代码的耦合,便于统一管理;提供XML标签,支持编写动态 SQL语句,并可重用与JDBC相比,减少了50%以上的代码量,消除了JDBC大量冗余的代码,不需要手动开关连接很好的与各种数据库兼容(因为MyBatis使用JDBC来连接数据库,所以只要JDBC支持的数 据库MyBatis都支持)
不同点
能够与Spring很好的集成
缺点
SQL语句的编写工作量较大,尤其当字段多、关联表多时,对开发人员编写SQL语句的功底 有一定要求
SQL语句依赖于数据库,导致数据库移植性差,不能随意更换数据库
7. MyBatis编程步骤是什么样的?
- 创建SqlSessionFactory
- 通过SqlSessionFactory创建SqlSession
- 通过sqlsession执行数据库操作
- 调用session.commit()提交事务
- 调用session.close()关闭会话
8.请说说MyBatis的工作原理 ?
在学习 MyBatis 程序之前,需要了解一下 MyBatis 工作原理,以便于理解程序。MyBatis 的工作原理如下图:
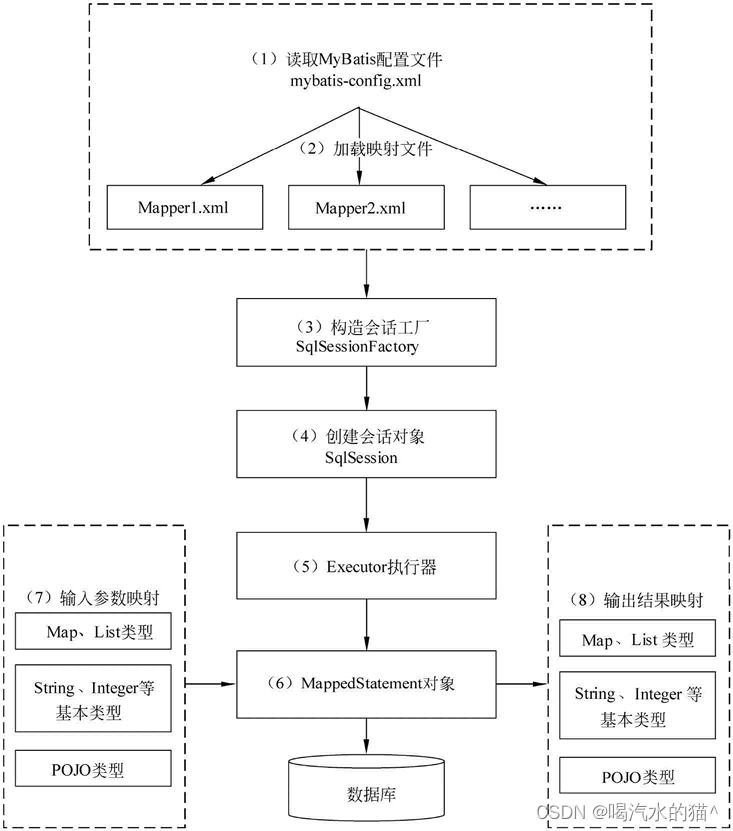
上面中流程就是MyBatis内部核心流程,每一步流程的详细说明如下文所述:
(1)读取MyBatis的配置文件。mybatis-config.xml为MyBatis的全局配置文件,用于配置数据库连接信息。
(2)加载映射文件。映射文件即SQL映射文件,该文件中配置了操作数据库的SQL语句,需要在MyBatis配置文件mybatis-config.xml中加载。mybatis-config.xml 文件可以加载多个映射文件,每个文件对应数据库中的一张表。
(3)构造会话工厂。通过MyBatis的环境配置信息构建会话工厂SqlSessionFactory。
(4)创建会话对象。由会话工厂创建SqlSession对象,该对象中包含了执行SQL语句的所有方法。
(5)Executor执行器。MyBatis底层定义了一个Executor接口来操作数据库,它将根据SqlSession传递的参数动态地生成需要执行的SQL语句,同时负责查询缓存的维护。
(6)MappedStatement对象。在Executor接口的执行方法中有一个MappedStatement类型的参数,该参数是对映射信息的封装,用于存储要映射的SQL语句的id、参数等信息。
(7)输入参数映射。输入参数类型可以是Map、List等集合类型,也可以是基本数据类型和POJO类型。输入参数映射过程类似于JDBC对preparedStatement对象设置参数的过程。
(8)输出结果映射。输出结果类型可以是Map、List等集合类型,也可以是基本数据类型和POJO类型。输出结果映射过程类似于JDBC对结果集的解析过程。
9.MyBatis的功能架构是怎样的?
我们把Mybatis的功能架构分为三层:
API接口层:提供给外部使用的接口API,开发人员通过这些本地API来操纵数据库。接口层 一接收到调用请求就会调用数据处理层来完成具体的数据处理。
数据处理层:负责具体的SQL查找、SQL解析、SQL执行和执行结果映射处理等。它主要的 目的是根据调用的请求完成一次数据库操作。
基础支撑层:负责最基础的功能支撑,包括连接管理、事务管理、配置加载和缓存处理,这 些都是共用的东西,将他们抽取出来作为最基础的组件。为上层的数据处理层提供最基础的 支撑。
10.为什么需要预编译
定义:
SQL 预编译指的是数据库驱动在发送 SQL 语句和参数给 DBMS 之前对 SQL 语句进行编 译,这样 DBMS 执行 SQL 时,就不需要重新编译。
为什么需要预编译
JDBC 中使用对象 PreparedStatement 来抽象预编译语句,使用预编译。预编译阶段可以 优化 SQL 的执行。预编译之后的 SQL 多数情况下可以直接执行,DBMS 不需要再次编译,越复杂的SQL,编译的复杂度将越大,预编译阶段可以合并多次操作为一个操作。同时预编译语句对象可以重复利用。把一个 SQL 预编译后产生的 PreparedStatement 对象缓存下来,下次对于同一个SQL,可以直接使用这个缓存的 PreparedState 对象。Mybatis 默认情况下,将对所有的 SQL 进行预编译。
11.#{}和${}的区别?
#{}是占位符:预编译处理;
${}是拼接符:字符串替换,没有预编译处理。
Mybatis在处理#{}时,#{}传入参数是以字符串传入,会将SQL中的#{}替换为?号,调用PreparedStatement的set方法来赋值。
Mybatis在处理时,是原值传入,就是把 {}时,是原值传入,就是把时,是原值传入,就是 把{}替换成变量的值,相当于JDBC中的Statement编译变量替换后,#{} 对应的变量自动加上单引号 ‘’;变量替换后,${} 对应的变量不会加上 单引号 ‘’
#{} 可以有效的防止SQL注入,提高系统安全性;${} 不能防止SQL 注入。
#{} 的变量替换是在DBMS 中;${} 的变量替换是在 DBMS 外。
12.Mybatis的一级、二级缓存
- 一级缓存: 基于 PerpetualCache 的 HashMap 本地缓存,其存储作用域为 Session, 当 Session flush 或 close 之后,该 Session 中的所有 Cache 就将清空,默认打开一级缓 存。
- 二级缓存与一级缓存其机制相同,默认也是采用 PerpetualCache,HashMap 存储, 不同在于其存储作用域为 Mapper(Namespace),并且可自定义存储源,如 Ehcache。默 认不打开二级缓存,要开启二级缓存,使用二级缓存属性类需要实现Serializable序列化接 口(可用来保存对象的状态),可在它的映射文件中配置 ;
- 对于缓存数据更新机制,当某一个作用域(一级缓存 Session/二级缓存Namespaces)的 进行了C/U/D 操作后,默认该作用域下所有 select 中的缓存将被 clear。
七、JVM
1. 内存模型以及分区,需要详细到每个区放什么。
· 方法区:主要是存储类信息,常量池(static 常量和 static 变量),编译后的代码(字
节码)等数据
· 堆:初始化的对象,成员变量 (那种非 static 的变量),所有的对象实例和数组都要
在堆上分配
· 栈:栈的结构是栈帧组成的,调用一个方法就压入一帧,帧上面存储局部变量表,操
作数栈,方法出口等信息,局部变量表存放的是 8 大基础类型加上一个应用类型,所以还是一个指向地址的指针
· 本地方法栈:主要为 Native 方法服务
· 程序计数器:记录当前线程执行的行号
2. 堆里面的分区:Eden,survival (from+ to),老年代,各自的特点
堆里面分为新生代和老生代(java8 取消了永久代,采用了 Metaspace),新生代包含Eden+Survivor 区,survivor 区里面分为 from 和 to 区,内存回收时,如果用的是复制算法,从 from 复制到 to,当经过一次或者多次 GC 之后,存活下来的对象会被移动到老年区,当 JVM 内存不够用的时候,会触发 Full GC,清理 JVM 老年区当新生区满了之后会触发 YGC,先把存活的对象放到其中一个 Survice区,然后进行垃圾清理。因为如果仅仅清理需要删除的对象,这样会导致内存碎片,因此一般会把 Eden 进行完全的清理,然后整理内存。那么下次 GC 的时候,就会使用下一个 Survive,这样循环使用。如果有特别大的对象,新生代放不下,就会使用老年代的担保,直接放到老年代里面。因为 JVM 认为,一般大对象的存活时间一般比较久远。
3.GC 的两种判定方法
引用计数法:指的是如果某个地方引用了这个对象就+1,如果失效了就-1,当为 0 就会回收,但是 JVM 没有用这种方式,因为无法判定相互循环引用(A 引用 B,B 引用 A)的情况。
引用链法: 通过一种 GC ROOT 的对象(方法区中静态变量引用的对象等-static 变量)来判断,如果有一条链能够到达 GC ROOT 就说明,不能到达 GC ROOT 就说明可以回收。
4. SafePoint 是什么
比如 GC 的时候必须要等到 Java 线程都进入到 safepoint 的时候 VMThread 才能开始执行 GC
- 循环的末尾 (防止大循环的时候一直不进入 safepoint,而其他线程在等待它进入safepoint)
- 方法返回前
- 调用方法的 call 之后
- 抛出异常的位置
5.Java New对象分配内存流程
点击这里参见详情
6.常见的垃圾回收器?
点击这里参见详情
7.类加载的几个过程?
java 类加载需要经历一下 7 个过程:
加载:
加载时类加载的第一个过程,在这个阶段,将完成一下三件事情:
-
通过一个类的全限定名获取该类的二进制流。
-
将该二进制流中的静态存储结构转化为方法去运行时数据结构。
-
在内存中生成该类的 Class 对象,作为该类的数据访问入口。
验证:
验证的目的是为了确保 Class 文件的字节流中的信息不回危害到虚拟机.在该阶段主要完成
以下四钟验证:
-
文件格式验证:验证字节流是否符合 Class 文件的规范,如主次版本号是否在当前虚拟机范围内,常量池中的常量是否有不被支持的类型.
-
元数据验证:对字节码描述的信息进行语义分析,如这个类是否有父类,是否集成了不被继承的类等。
-
字节码验证:是整个验证过程中最复杂的一个阶段,通过验证数据流和控制流的分析,确定程序语义是否正确,主要针对方法体的验证。如:方法中的类型转换是否正确,跳转指令是否正确等。
-
符号引用验证:这个动作在后面的解析过程中发生,主要是为了确保解析动作能正确执行。
准备:
准备阶段是为类的静态变量分配内存并将其初始化为默认值,这些内存都将在方法区中进行分配。准备阶段不分配类中的实例变量的内存,实例变量将会在对象实例化时随着对象一起分配在 Java 堆中。
public static int value=123;*//**在准备阶段**value**初始值为**0**。在初始化阶段才会变**为123**。*
解析:
该阶段主要完成符号引用到直接引用的转换动作。解析动作并不一定在初始化动作完成之前,也有可能在初始化之后。
初始化:
初始化时类加载的最后一步,前面的类加载过程,除了在加载阶段用户应用程序可以通过自定义类加载器参与之外,其余动作完全由虚拟机主导和控制。到了初始化阶段,才真正开始执行类中定义的 Java 程序代码。
8.如和判断一个对象是否存活?(或者GC对象的判定方法)
判断一个对象是否存活有两种方法:
- 引用计数法
所谓引用计数法就是给每一个对象设置一个引用计数器,每当有一个地方引用这个对象时,就将计数器加一,引用失效时,计数器就减一。当一个对象的引用计数器为零时,说明此对象没有被引用,也就是“死对象”,将会被垃圾回收.
引用计数法有一个缺陷就是无法解决循环引用问题,也就是说当对象 A 引用对象 B,对象B 又引用者对象 A,那么此时 A,B 对象的引用计数器都不为零,也就造成无法完成垃圾回收,所以主流的虚拟机都没有采用这种算法。
2.可达性算法(引用链法)
该算法的思想是:从一个被称为 GC Roots 的对象开始向下搜索,如果一个对象到 GC Roots 没有任何引用链相连时,则说明此对象不可用。
在 java 中可以作为 GC Roots 的对象有以下几种:
· 虚拟机栈中引用的对象
· 方法区类静态属性引用的对象
· 方法区常量池引用的对象
· 本地方法栈 JNI 引用的对象
虽然这些算法可以判定一个对象是否能被回收,但是当满足上述条件时,一个对象比不一定会被回收。当一个对象不可达 GC Root 时,这个对象并不会立马被回收,而是出于一个死缓的阶段,若要被真正的回收需要经历两次标记。如果对象在可达性分析中没有与 GC Root 的引用链,那么此时就会被第一次标记并且进行一次筛选,筛选的条件是是否有必要执行 finalize()方法。当对象没有覆盖 finalize()方法或者已被虚拟机调用过,那么就认为是没必要的。
如果该对象有必要执行 finalize()方法,那么这个对象将会放在一个称为 F-Queue 的对队列中,虚拟机会触发一个 Finalize()线程去执行,此线程是低优先级的,并且虚拟机不会承诺一直等待它运行完,这是因为如果 finalize()执行缓慢或者发生了死锁,那么就会造成 F- Queue 队列一直等待,造成了内存回收系统的崩溃。GC 对处于 F-Queue 中的对象进行第二次被标记,这时,该对象将被移除”即将回收”集合,等待回收。
9. 什么是类加载器,类加载器有哪些?
实现通过类的权限定名获取该类的二进制字节流的代码块叫做类加载器。
主要有一下四种类加载器:
-
启动类加载器(Bootstrap ClassLoader)用来加载 java 核心类库,无法被 java 程序直接引用。
-
扩展类加载器(extensions class loader):它用来加载 Java 的扩展库。Java 虚拟机的实现会提供一个扩展库目录。该类加载器在此目录里面查找并加载 Java 类。
-
系统类加载器(system class loader):它根据 Java 应用的类路径(CLASSPATH)来加载 Java 类。一般来说,Java 应用的类都是由它来完成加载的。可以通过ClassLoader.getSystemClassLoader()来获取它。
-
用户自定义类加载器,通过继承 java.lang.ClassLoader 类的方式实现。
10.什么是双亲委派机制?
Java虚拟机对于class文件采用的加载策略是按需加载。也就是当需要使用该类时才会将该类的.class文件加载到内存中生成Class对象。并且加载某个类的.class文件时,Java虚拟机采用的是双亲委派模式,即将加载.class文件的的请求优先交由父类进行加载处理,如果父类能够进行正常加载则将其加载到内存中,如果不能加载则再由自己进行加载。这是一种任务委派模式。
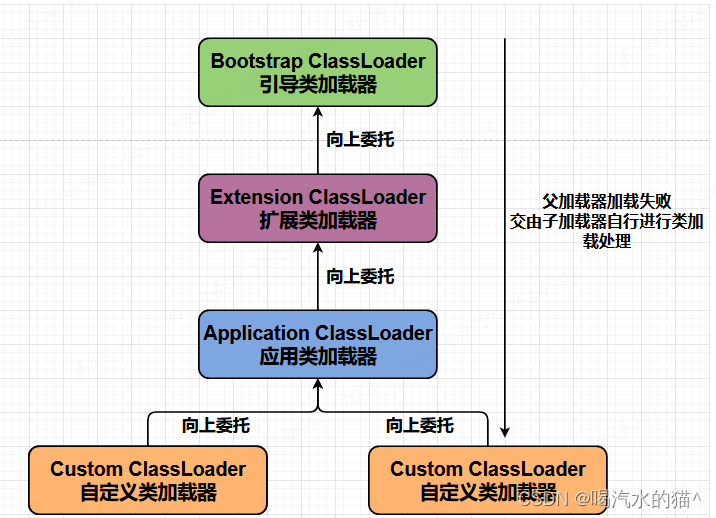
双亲委派机制的工作原理:
如果一个类加载器收到了类加载的请求,它并不会自己先去加载,而是将这个请求委托给父类的加载器去执行。
如果父类加载器还在其父类加载器,则进一步向上委托,依次进行递归,请求最总将到达顶层的引导类加载器。
如果父类加载器可以完成类加载任务,就成功返回,如果父类加载器无法完成类加载任务,子加载器才会尝试自己去加载,这就是双亲委派模式。
八、Mysql
1. 什么是MySQL?
MySQL是一个关系型数据库管理系统,由瑞典MySQLAB公司开发,属于Oracle旗下产品。MySQL是最流行的关系型数据库管理系统之一,在WEB应用方面,MySQL是最好的RDBMS(RelationalDatabaseManagementSystem,关系数据库管理系统)应用软件之一。在Java企业级开发中非常常用,因为MySQL是开源免费的,并且方便扩展。
2.数据库三大范式是什么?
第一范式:每个列都不可以再拆分。
第二范式:在第一范式的基础上,非主键列完全依赖于主键,而不能是依赖于主键的一部分。
第三范式:在第二范式的基础上,非主键列只依赖于主键,不依赖于其他非主键。
在设计数据库结构的时候,要尽量遵守三范式,如果不遵守,必须有足够的理由。比如性能。事实上我们经常会为了性能而妥协数据库的设计。
3.MySQL的binlog有有几种录入格式?分别有什么区别?
有三种格式,statement,row和mixed。
- statement模式下,每一条会修改数据的sql都会记录在binlog中。不需要记录每一行的变化,减少了binlog日志量,节约了IO,提高性能。由于sql的执行是有上下文的,因此在保存的时候需要保存相关的信息,同时还有一些使用了函数之类的语句无法被记录复制。
- row级别下,不记录sql语句上下文相关信息,仅保存哪条记录被修改。记录单元为每一行的改动,基本是可以全部记下来但是由于很多操作,会导致大量行的改动(比如altertable),因此这种模式的文件保存的信息太多,日志量太大。
- mixed,一种折中的方案,普通操作使用statement记录,当无法使用statement的时候使用row。
此外,新版的MySQL中对row级别也做了一些优化,当表结构发生变化的时候,会记录语句而不是逐行记录。
4. MySQL存储引擎MyISAM与InnoDB区别
存储引擎Storageengine:MySQL中的数据、索引以及其他对象是如何存储的,是一套文件系统的实现。
常用的存储引擎有以下:
Innodb引擎:Innodb引擎提供了对数据库ACID事务的支持。并且还提供了行级锁和外键的约束。它的设计的目标就是处理大数据容量的数据库系统。
MyIASM引擎(原本Mysql的默认引擎):不提供事务的支持,也不支持行级锁和外键。
MEMORY引擎:所有的数据都在内存中,数据的处理速度快,但是安全性不高。
MyISAM与InnoDB区别:
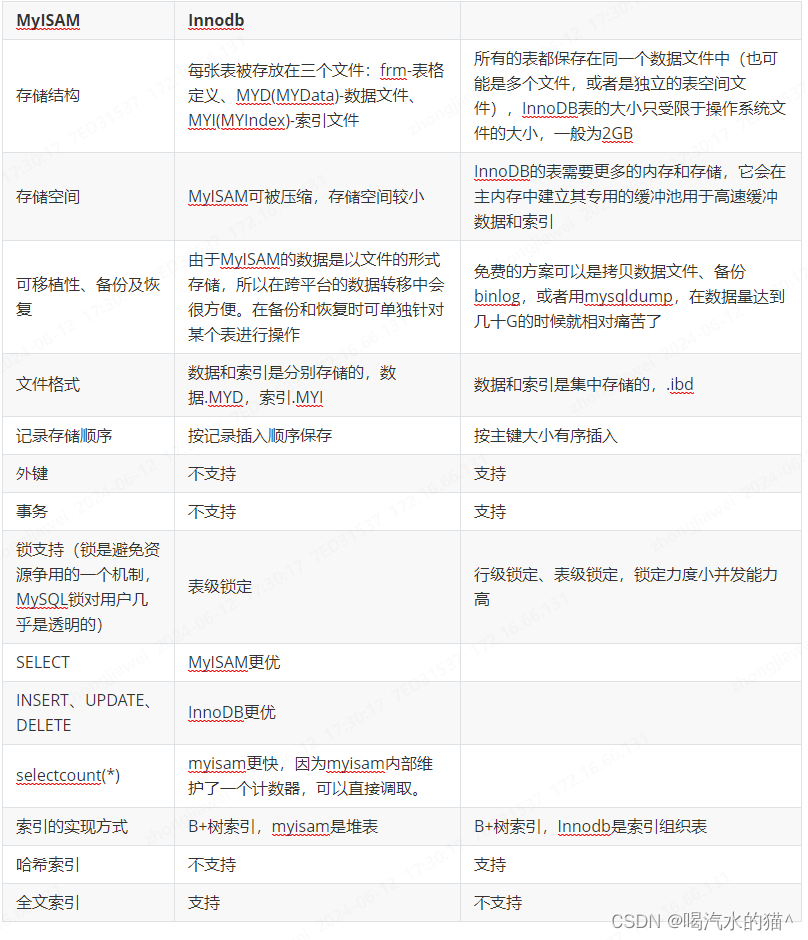
5. MyISAM索引与InnoDB索引的区别?
- InnoDB索引是聚簇索引,MyISAM索引是非聚簇索引。
- InnoDB的主键索引的叶子节点存储着行数据,因此主键索引非常高效。
- MyISAM索引的叶子节点存储的是行数据地址,需要再寻址一次才能得到数据。
- InnoDB非主键索引的叶子节点存储的是主键和其他带索引的列数据,因此查询时做到覆盖索引会非常高效。
6. 存储引擎选择
如果没有特别的需求,使用默认的Innodb即可。
MyISAM:以读写插入为主的应用程序,比如博客系统、新闻门户网站。
Innodb:更新(删除)操作频率也高,或者要保证数据的完整性;并发量高,支持事务和外键。比如OA自动化办公系统。
7. 什么是索引?
索引是一种特殊的文件(InnoDB数据表上的索引是表空间的一个组成部分),它们包含着对数据表里所有记录的引用指针。
索引是一种数据结构。数据库索引,是数据库管理系统中一个排序的数据结构,以协助快速查询、更新数据库表中数据。索引的实现通常使用B树及其变种B+树。更通俗的说,索引就相当于目录。为了方便查找书中的内容,通过对内容建立索引形成目录。索引是一个文件,它是要占据物理空间的。
8. 索引有哪几种类型?
主键索引:数据列不允许重复,不允许为NULL,一个表只能有一个主键。
唯一索引:数据列不允许重复,允许为NULL值,一个表允许多个列
- 可以通过ALTERTABLEtable_nameADDUNIQUE(column);创建唯一索引
- :可以通过ALTERTABLEtable_nameADDUNIQUE(column1,column2); 创建唯一组合索引
普通索引:基本的索引类型,没有唯一性的限制,允许为NULL值。
- 可以通过ALTERTABLEtable_nameADDINDEXindex_name(column);创建普通索引
- 可以通过ALTERTABLEtable_nameADDINDEXindex_name(column1,column2,column3);创建组合索引
全文索引:是目前搜索引擎使用的一种关键技术。
可以通过ALTERTABLEtable_nameADDFULLTEXT(column) 创建全文索引
9.索引的基本原理
索引用来快速地寻找那些具有特定值的记录。如果没有索引,一般来说执行查询时遍历整张表。
索引的原理很简单,就是把无序的数据变成有序的查询:
-
把创建了索引的列的内容进行排序
-
对排序结果生成倒排表
-
在倒排表内容上拼上数据地址链
-
在查询的时候,先拿到倒排表内容,再取出数据地址链,从而拿到具体数据
10. 索引算法有哪些?
索引算法有BTree算法和Hash算法
BTree算法:
BTree是常用的mysql数据库索引算法,也是mysql默认的算法。因为它不仅可以被用在=,>,>=,<,<=和between这些比较操作符上,而且还可以用于like操作符,只要它的查询条件是一个不以通配符开头的常量。
例如:
1 ‐‐只要它的查询条件是一个不以通配符开头的常量
2 select*fromuserwherenamelike'jack%';
3 ‐‐如果一通配符开头,或者没有使用常量,则不会使用索引,例如:
4 select*fromuserwherenamelike'%jack';
Hash算法:
HashHash索引只能用于对等比较,例如=,<=>(相当于=)操作符。由于是一次定位数据,不像BTree索引需要从根节点到枝节点,后才能访问到页节点这样多次IO访问,所以检索效率远高于BTree索引。
11.索引设计的原则?
- 适合索引的列是出现在where子句中的列,或者连接子句中指定的列
- 基数较小的类,索引效果较差,没有必要在此列建立索引
- 使用短索引,如果对长字符串列进行索引,应该指定一个前缀长度,这样能够节省大量索引空间
- 不要过度索引。索引需要额外的磁盘空间,并降低写操作的性能。在修改表内容的时候,索引会进行更新甚至重构,索引列越多,这个时间就会越长。所以只保持需要的索引有利于查询即可。
12.索引虽好,但也不是无限制的使用,好符合一下几个原则
1)左前缀匹配原则,组合索引非常重要的原则,mysql会一直向右匹配直到遇到范围查询(>、<、between、like)就停止匹配,比如a=1andb=2andc>3andd=4如果建立(a,b,c,d)顺序的索引,d是用不到索引的,如果建立(a,b,d,c)的索引则都可以用到,a,b,d的顺序可以任意调整。
2)较频繁作为查询条件的字段才去创建索引
3)更新频繁字段不适合创建索引
4)若是不能有效区分数据的列不适合做索引列(如性别,男女未知,多也就三种,区分度实在太低)
5)尽量的扩展索引,不要新建索引。比如表中已经有a的索引,现在要加(a,b)的索引,那么只需要修改原来的索引即可。
6)定义有外键的数据列一定要建立索引。
7)对于那些查询中很少涉及的列,重复值比较多的列不要建立索引。
8)对于定义为text、image和bit的数据类型的列不要建立索引。创建索引的三种方式,删除索引
13.创建索引时需要注意什么?
- 非空字段:应该指定列为NOTNULL,除非你想存储NULL。在mysql中,含有空值的列很难进行查询优化,因为它们使得索引、索引的统计信息以及比较运算更加复杂。你应该用0、一个特殊的值或者一个空串代替空值;
- 取值离散大的字段:(变量各个取值之间的差异程度)的列放到联合索引的前面,可以通过count()函数查看字段的差异值,返回值越大说明字段的唯一值越多字段的离散程度高;
- 索引字段越小越好:数据库的数据存储以页为单位一页存储的数据越多一次IO操作获取的数据越大效率越高。
14.使用索引查询一定能提高查询的性能吗?为什么?
通常,通过索引查询数据比全表扫描要快。但是我们也必须注意到它的代价。
索引需要空间来存储,也需要定期维护,每当有记录在表中增减或索引列被修改时,索引本身也会被修改。这意味着每条记录的INSERT,DELETE,UPDATE将为此多付出4,5次的磁盘I/O。因为索引需要额外的存储空间和处理,那些不必要的索引反而会使查询反应时间变慢。使用索引查询不一定能提高查询性能,索引范围查询(INDEXRANGESCAN)适用于两种情况:
-
基于一个范围的检索,一般查询返回结果集小于表中记录数的30%
-
基于非唯一性索引的检索
15.什么是最左前缀原则?什么是最左匹配原则?
顾名思义,就是最左优先,在创建多列索引时,要根据业务需求,where子句中使用最频繁的一列放在最左边。
最左前缀匹配原则,非常重要的原则,mysql会一直向右匹配直到遇到范围查询(>、<、between、like)就停止匹配,比如a=1andb=2andc>3andd=4如果建立(a,b,c,d)顺序的索引,d是用不到索引的,如果建立(a,b,d,c)的索引则都可以用到,a,b,d的顺序可以任意调整。
=和in可以乱序,比如a=1andb=2andc=3建立(a,b,c)索引可以任意顺序,mysql的查询优化器会帮你优化成索引可以识别的形式
16. B树和B+树的区别?
在B树中,你可以将键和值存放在内部节点和叶子节点;
但在B+树中,内部节点都是键,没有值,叶子节点同时存放键和值。
B+树的叶子节点有一条链相连,而B树的叶子节点各自独立。
使用B树的好处
B树可以在内部节点同时存储键和值,因此,把频繁访问的数据放在靠近根节点的地方将会大大提高热点数据的查询效率。这种特性使得B树在特定数据重复多次查询的场景中更加高效。
使用B+树的好处
由于B+树的内部节点只存放键,不存放值,因此,一次读取,可以在内存页中获取更多的键,有利于更快地缩小查找范围。B+树的叶节点由一条链相连,因此,当需要进行一次全数据遍历的时候,B+树只需要使用O(logN)时间找到最小的一个节点,然后通过链进行O(N)的顺序遍历即可。而B树则需要对树的每一层进行遍历,这会需要更多的内存置换次数,因此也就需要花费更多的时间
17. 数据库为什么使用B+树而不是B树?
- B树只适合随机检索,而B+树同时支持随机检索和顺序检索;
- B+树空间利用率更高,可减少I/O次数,磁盘读写代价更低。一般来说,索引本身也很大,不可能全部存储在内存中,因此索引往往以索引文件的形式存储的磁盘上。这样的话,索引查找过程中就要产生磁盘I/O消耗。B+树的内部结点并没有指向关键字具体信息的指针,只是作为索引使用,其内部结点比B树小,盘块能容纳的结点中关键字数量更多,一次性读入内存中可以查找的关键字也就越多,相对的,IO读写次数也就降低了。而IO读写次数是影响索引检索效率的最大因素;
- B+树的查询效率更加稳定。B树搜索有可能会在非叶子结点结束,越靠近根节点的记录查找时间越短,只要找到关键字即可确定记录的存在,其性能等价于在关键字全集内做一次二分查找。而在B+树中,顺序检索比较明显,随机检索时,任何关键字的查找都必须走一条从根节点到叶节点的路,所有关键字的查找路径长度相同,导致每一个关键字的查询效率相当。
- B-树在提高了磁盘IO性能的同时并没有解决元素遍历的效率低下的问题。B+树的叶子节点使用指针顺序连接在一起,只要遍历叶子节点就可以实现整棵树的遍历。而且在数据库中基于范围的查询是非常频繁的,而B树不支持这样的操作。
- 增删文件(节点)时,效率更高。因为B+树的叶子节点包含所有关键字,并以有序的链表结构存储,这样可很好提高增删效率。
18. 什么是聚簇索引?何时使用聚簇索引与非聚簇索引
聚簇索引:将数据存储与索引放到了一块,找到索引也就找到了数据
非聚簇索引:将数据存储于索引分开结构,索引结构的叶子节点指向了数据的对应行,myisam通过key_buffer把索引先缓存到内存中,当需要访问数据时(通过索引访问数据),在内存中直接搜索索引,然后通过索引找到磁盘相应数据,这也就是为什么索引不在key buffer命中时,速度慢的原因
澄清一个概念:innodb中,在聚簇索引之上创建的索引称之为辅助索引,辅助索引访问数据总是需要二次查找,非聚簇索引都是辅助索引,像复合索引、前缀索引、唯一索引,辅助索引叶子节点存储的不再是行的物理位置,而是主键值。
19. 非聚簇索引一定会回表查询吗?
不一定,这涉及到查询语句所要求的字段是否全部命中了索引,如果全部命中了索引,那么就不必再进行回表查询
举个简单的例子,假设我们在员工表的年龄上建立了索引,那么当进行select age from employee where age < 20的查询时,在索引的叶子节点上,已经包含了age信息,不会再次进行回表查询。
20.联合索引是什么?为什么需要注意联合索引中的顺序?
MySQL可以使用多个字段同时建立一个索引,叫做联合索引。在联合索引中,如果想要命中索引,需要按照建立索引时的字段顺序挨个使用,否则无法命中索引。
具体原因为:
MySQL使用索引时需要索引有序,假设现在建立了"name,age,school"的联合索引,那么索引的排序为: 先按照name排序,如果name相同,则按照age排序,如果age的值也相等,则按照school进行排序。
当进行查询时,此时索引仅仅按照name严格有序,因此必须首先使用name字段进行等值查询,之后对于匹配到的列而言,其按照age字段严格有序,此时可以使用age字段用做索引查找,以此类推。因此在建立联合索引的时候应该注意索引列的顺序,一般情况下,将查询需求频繁或者字段选择性高的列放在前面。此外可以根据特例的查询或者表结构进行单独的调整。
21. 什么是数据库事务?
事务是一个不可分割的数据库操作序列,也是数据库并发控制的基本单位,其执行的结果必须使数据库从一种一致性状态变到另一种一致性状态。事务是逻辑上的一组操作,要么都执行,要么都不执行。
事务最经典也经常被拿出来说例子就是转账了。
假如小明要给小红转账1000元,这个转账会涉及到两个关键操作就是:将小明的余额减少1000元,将小红的余额增加1000元。万一在这两个操作之间突然出现错误比如银行系统崩溃,导致小明余额减少而小红的余额没有增加,这样就不对了。事务就是保证这两个关键操作要么都成功,要么都要失败。
事物的四大特性(ACID)
关系性数据库需要遵循ACID规则,具体内容如下:
- 原子性: 事务是最小的执行单位,不允许分割。事务的原子性确保动作要么全部完成,要么完全不起作用;
- 一致性: 执行事务前后,数据保持一致,多个事务对同一个数据读取的结果是相同的;
- 隔离性: 并发访问数据库时,一个用户的事务不被其他事务所干扰,各并发事务之间数据库是独立的;
- 持久性: 一个事务被提交之后。它对数据库中数据的改变是持久的,即使数据库发生故障也不应该对其有任何影响。
22.什么是脏读?幻读?不可重复读?
脏读(Drity Read):某个事务已更新一份数据,另一个事务在此时读取了同一份数据,由于某些原因,前一个RollBack了操作,则后一个事务所读取的数据就会是不正确的。
不可重复读(Non-repeatable read):在一个事务的两次查询之中数据不一致,这可能是两次查询过程中间插入了一个事务更新的原有的数据。
幻读(Phantom Read):在一个事务的两次查询中数据笔数不一致,例如有一个事务查询了几列(Row)数据,而另一个事务却在此时插入了新的几列数据,先前的事务在接下来的查询中,就会发现有几列数据是它先前所没有的。
23. 什么是事务的隔离级别?MySQL的默认隔离级别是什么?
为了达到事务的四大特性,数据库定义了4种不同的事务隔离级别,由低到高依次为Read uncommitted、Read committed、Repeatable read、Serializable,这四个级别可以逐个解决脏读、不可重复读、幻读这几类问题。
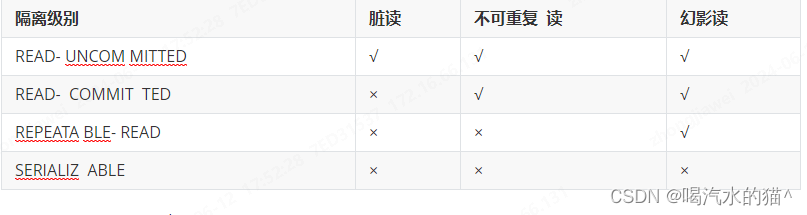
SQL 标准定义了四个隔离级别:
- READ-UNCOMMITTED(读取未提交): 最低的隔离级别,允许读取尚未提交的数据变更,可能会导致脏读、幻读或不可重复读。
- READ-COMMITTED(读取已提交): 允许读取并发事务已经提交的数据,可以阻止脏读,但是幻读或不可重复读仍有可能发生。
- REPEATABLE-READ(可重复读): 对同一字段的多次读取结果都是一致的,除非数据是被本身事务自己所修改,可以阻止脏读和不可重复读,但幻读仍有可能发生。
- SERIALIZABLE(可串行化): 最高的隔离级别,完全服从ACID的隔离级别。所有的事务依次逐个执行,这样事务之间就完全不可能产生干扰,也就是说,该级别可以防止脏读、不可重复读以及幻读。
这里需要注意的是:Mysql 默认采用的 REPEATABLE_READ隔离级别 Oracle默认采用的 READ_COMMITTED隔离级别
事务隔离机制的实现基于锁机制和并发调度。其中并发调度使用的是MVVC(多版本并发控制),通过保存修改的旧版本信息来支持并发一致性读和回滚等特性。
因为隔离级别越低,事务请求的锁越少,所以大部分数据库系统的隔离级别都是READ-COMMITTED(读取提交内容):,但是你要知道的是InnoDB 存储引擎默认使用 REPEATABLE-READ(可重读并不会有任何性能损失。
InnoDB 存储引擎在 分布式事务 的情况下一般会用到 SERIALIZABLE(可串行化) 隔离级别。
24.对MySQL的锁了解吗?
当数据库有并发事务的时候,可能会产生数据的不一致,这时候需要一些机制来保证访问的次序,锁机制就是这样的一个机制。
就像酒店的房间,如果大家随意进出,就会出现多人抢夺同一个房间的情况,而在房间上装上锁,申请到钥匙的人才可以入住并且将房间锁起来,其他人只有等他使用完毕才可以再次使用。
25. 按照锁的粒度分数据库锁有哪些?锁机制与InnoDB锁算法?
在关系型数据库中,可以按照锁的粒度把数据库锁分为行级锁(INNODB引擎)、表级锁(MYISAM引擎)和页级锁(BDB引擎 )。
MyISAM和InnoDB存储引擎使用的锁:
- MyISAM采用表级锁(table-level locking)。
- InnoDB支持行级锁(row-level locking)和表级锁,默认为行级锁
行级锁,表级锁和页级锁对比:
**行级锁:**行级锁是Mysql中锁定粒度最细的一种锁,表示只针对当前操作的行进行加锁。行级锁能大大减少数据库操作的冲突。其加锁粒度最小,但加锁的开销也最大。行级锁分为共享锁 和 排他锁。
特点:开销大,加锁慢;会出现死锁;锁定粒度最小,发生锁冲突的概率最低,并发度也最高。
表级锁 :表级锁是MySQL中锁定粒度最大的一种锁,表示对当前操作的整张表加锁,它实现简单,资源消耗较少,被大部分MySQL引擎支持。最常使用的MYISAM与INNODB都支持表级锁定。表级锁定分为表共享读锁(共享锁)与表独占写锁(排他锁)。
特点:开销小,加锁快;不会出现死锁;锁定粒度大,发出锁冲突的概率最高,并发度最低。
页级锁: 页级锁是MySQL中锁定粒度介于行级锁和表级锁中间的一种锁。表级锁速度快,但冲突多,行级冲突少,但速度慢。所以取了折衷的页级,一次锁定相邻的一组记录。
特点:开销和加锁时间界于表锁和行锁之间;会出现死锁;锁定粒度界于表锁和行锁之间,并发度一般
26.从锁的类别上分MySQL都有哪些锁呢?
从锁的类别上来讲,有共享锁和排他锁。
共享锁: 又叫做读锁。 当用户要进行数据的读取时,对数据加上共享锁。共享锁可以同时加上多个。
排他锁: 又叫做写锁。 当用户要进行数据的写入时,对数据加上排他锁。排他锁只可以加一个,他和其他的排他锁,共享锁都相斥。
用上面的例子来说就是用户的行为有两种,一种是来看房,多个用户一起看房是可以接受的。 一种是真正的入住一晚,在这期间,无论是想入住的还是想看房的都不可以。
锁的粒度取决于具体的存储引擎,InnoDB实现了行级锁,页级锁,表级锁。
他们的加锁开销从大到小,并发能力也是从大到小。
27. MySQL中InnoDB引擎的行锁是怎么实现的?
答:InnoDB是基于索引来完成行锁
例: select * from tab_with_index where id = 1 for update;
for update 可以根据条件来完成行锁锁定,并且 id 是有索引键的列,如果 id不是索引键那么InnoDB将完成表锁,并发将无从谈起
28. 什么是死锁?怎么解决?
死锁是指两个或多个事务在同一资源上相互占用,并请求锁定对方的资源,从而导致恶性循环的现象。
常见的解决死锁的方法:
1、如果不同程序会并发存取多个表,尽量约定以相同的顺序访问表,可以大大降低死锁机会。
2、在同一个事务中,尽可能做到一次锁定所需要的所有资源,减少死锁产生概率;
3、对于非常容易产生死锁的业务部分,可以尝试使用升级锁定颗粒度,通过表级锁定来减少死锁产生的概率;
如果业务处理不好可以用分布式事务锁或者使用乐观锁
29. 为什么要使用视图?什么是视图?
为了提高复杂SQL语句的复用性和表操作的安全性,MySQL数据库管理系统提供了视图特性。所谓视图,本质上是一种虚拟表,在物理上是不存在的,其内容与真实的表相似,包含一系列带有名称的列和行数据。但是,视图并不在数据库中以储存的数据值形式存在。行和列数据来自定义视图的查询所引用基本表,并且在具体引用视图时动态生成。
视图使开发者只关心感兴趣的某些特定数据和所负责的特定任务,只能看到视图中所定义的数据,而不是视图所引用表中的数据,从而提高了数据库中数据的安全性
视图有哪些特点?
- 视图的列可以来自不同的表,是表的抽象和在逻辑意义上建立的新关系。
- 视图是由基本表(实表)产生的表(虚表)。
- 视图的建立和删除不影响基本表。
- 对视图内容的更新(添加,删除和修改)直接影响基本表。
- 当视图来自多个基本表时,不允许添加和删除数据。视图的操作包括创建视图,查看视图,删除视图和修改视图。
视图的使用场景有哪些?
视图根本用途:简化sql查询,提高开发效率。如果说还有另外一个用途那就是兼容老的表结构。
下面是视图的常见使用场景:重用SQL语句;
- 简化复杂的SQL操作。在编写查询后,可以方便的重用它而不必知道它的基本查询细节;使用表的组成部分而不是整个表;
- 保护数据。可以给用户授予表的特定部分的访问权限而不是整个表的访问权限;
- 更改数据格式和表示。视图可返回与底层表的表示和格式不同的数据
视图的优点
-
查询简单化。视图能简化用户的操作
-
数据安全性。视图使用户能以多种角度看待同一数据,能够对机密数据提供安全保护
逻辑数据独立性。视图对重构数据库提供了一定程度的逻辑独立性
视图的缺点
-
性能。数据库必须把视图的查询转化成对基本表的查询,如果这个视图是由一个复杂的多表查询所定义,那么,即使是视图的一个简单查询,数据库也把它变成一个复杂的结合体,需要花费一定的时间。
-
修改限制。当用户试图修改视图的某些行时,数据库必须把它转化为对基本表的某些行的修改。事实上,当从视图中插入或者删除时,情况也是这样。对于简单视图来说,这是很方便的,但是,对于比较复杂的视图,可能是不可修改的这些视图有如下特征:
- 有UNIQUE等集合操作符的视图。
2.有GROUP BY子句的视图。
3.有诸如AVG\SUM\MAX等聚合函数的视图。
4.使用DISTINCT关键字的视图。
5.连接表的视图(其中有些例外)
- 有UNIQUE等集合操作符的视图。
30. 什么是游标?
游标是系统为用户开设的一个数据缓冲区,存放SQL语句的执行结果,每个游标区都有一个名字。用户可以通过游标逐一获取记录并赋给主变量,交由主语言进一步处理
31.什么是存储过程?有哪些优缺点?
存储过程是一个预编译的SQL语句,优点是允许模块化的设计,就是说只需要创建一次,以后在该程序中就可以调用多次。如果某次操作需要执行多次SQL,使用存储过程比单纯SQL语句执行要快。
优点:
- 存储过程是预编译过的,执行效率高。
- 存储过程的代码直接存放于数据库中,通过存储过程名直接调用,减少网络通讯。
- 安全性高,执行存储过程需要有一定权限的用户。
- 存储过程可以重复使用,减少数据库开发人员的工作量。
缺点:
- 调试麻烦,但是用 PL/SQL Developer 调试很方便!弥补这个缺点。
- 移植问题,数据库端代码当然是与数据库相关的。但是如果是做工程型项目,基本不存在移植问题。
- 重新编译问题,因为后端代码是运行前编译的,如果带有引用关系的对象发生改变时,受影响的存储过程、包将需要重新编译(不过也可以设置成运行时刻自动编译)。
- 如果在一个程序系统中大量的使用存储过程,到程序交付使用的时候随着用户需求的增加会导致数据结构的变化,接着就是系统的相关问题了, 后如果用
户想维护该系统可以说是很难很难、而且代价是空前的,维护起来更麻烦。
32.什么是触发器?触发器的使用场景有哪些?
触发器是用户定义在关系表上的一类由事件驱动的特殊的存储过程。触发器是指一段代码,当触发某个事件时,自动执行这些代码。
使用场景
- 可以通过数据库中的相关表实现级联更改。
- 实时监控某张表中的某个字段的更改而需要做出相应的处理。
- 例如可以生成某些业务的编号。
- 注意不要滥用,否则会造成数据库及应用程序的维护困难。
- 大家需要牢记以上基础知识点,重点是理解数据类型CHAR和VARCHAR的差异,表存储引擎InnoDB和MyISAM的区别。
33. SQL语句主要分为哪几类?
数据定义语言DDL(Data Ddefinition Language)CREATE,DROP,ALTER:主要为以上操作 即对逻辑结构等有操作的,其中包括表结构,视图和索引。
数据查询语言DQL(Data Query Language)SELECT: 这个较为好理解 即查询操作,以select关键字。各种简单查询,连接查询等 都属于DQL。
数据操纵语言DML(Data Manipulation Language)INSERT,UPDATE,DELETE :主要为以上操作 即对数据进行操作的,对应上面所说的查询操作 DQL与DML共同构建了多数初级程序员常用的增删改查操作。而查询是较为特殊的一种 被划分到DQL中。
数据控制功能DCL(Data Control Language)GRANT,REVOKE,COMMIT,ROLLBACK:主要为以上操作 即对数据库安全性完整性等有操作的,可以简单的理解为权限控制等
34. 六种关联查询
交叉连接(CROSS JOIN)
内连接(INNER JOIN)
外连接(LEFT JOIN/RIGHT JOIN)
联合查询(UNION与UNION ALL)
全连接(FULL JOIN)
交叉连接(CROSS JOIN)
35.什么是子查询?
- 条件:一条SQL语句的查询结果做为另一条查询语句的条件或查询结果
- 嵌套:多条SQL语句嵌套使用,内部的SQL查询语句称为子查询。
36.mysql中in和exists区别
mysql中的in语句是把外表和内表作hash 连接,而exists语句是对外表作loop循环,每次loop循环再对内表进行查询。一直大家都认为exists比in语句的效率要高,这种说法其实是不准确的。这个是要区分环境的。
-
如果查询的两个表大小相当,那么用in和exists差别不大。
-
如果两个表中一个较小,一个是大表,则子查询表大的用exists,子查询表小的用in。
-
not in 和not exists:如果查询语句使用了not in,那么内外表都进行全表扫描,没有用到索引;而not extsts的子查询依然能用到表上的索引。所以无论那个表大,用not exists都比not in要快。
37. varchar与char的区别?
char的特点:
-
char表示定长字符串,长度是固定的;如果插入数据的长度小于char的固定长度时,则用空格填充,因为长度固定,所以存取速度要比varchar快很多,甚至能快50%,但正因为其长度固定,所以会占据多余的空间,是空间换时间的做法;
-
对于char来说,都能存放的字符个数为255,和编码无关。
varchar的特点:
-
varchar表示可变长字符串,长度是可变的;
-
插入的数据是多长,就按照多长来存储;
-
varchar在存取方面与char相反,它存取慢,因为长度不固定,但正因如此,不占据多余的空间,是时间换空间的做法;
-
对于varchar来说, 多能存放的字符个数为65532 总之,结合性能角度(char更快)和节省磁盘空间角度(varchar更小),具体情况还需具体来设计数据库才是妥当的做法。
38.drop、delete与truncate的区别
| Delete | Truncate | Drop | |
|---|---|---|---|
| 类型 | 属于DML | 属于DDL | 属于DDL |
| 回滚 | 可回滚 | 不可回滚 | 不可回滚 |
| 删除内容 | 表结构还在,删除表的全部或者一部分数据行 | 表结构还在,删除表中的所有数据 | 从数据库中删除表,所有的数据行,索引和权限也会被删除 |
| 删除速度 | 删除速度慢,需要逐行删除 | 删除速度快 | 删除速度快 |
因此,在不再需要一张表的时候,用drop;在想删除部分数据行时候,用 delete;在保留表而删除所有数据的时候用truncate。
39.SQL的生命周期?
-
应用服务器与数据库服务器建立一个连接
-
数据库进程拿到请求sql
-
解析并生成执行计划,执行
-
读取数据到内存并进行逻辑处理
-
通过步骤一的连接,发送结果到客户端
-
关掉连接,释放资源
40. 大表数据查询,怎么优化?
-
优化shema、sql语句+索引;
-
第二加缓存,memcached, redis;
-
主从复制,读写分离;
-
垂直拆分,根据你模块的耦合度,将一个大的系统分为多个小的系统,也就是分布式系统;
-
水平切分,针对数据量大的表,这一步 麻烦, 能考验技术水平,要选择一个合理的sharding key, 为了有好的查询效率,表结构也要改动,
做一定的冗余,应用也要改,sql中尽量带sharding key,将数据定位到限定的表上去查,而不是扫描全部的表;
41. 超大分页怎么处理?
1、超大的分页一般从两个方向上来解决:
- 数据库层面,这也是我们主要集中关注的(虽然收效没那么大),类似于
select * from table where age > 20 limit 1000000,10这种查询其实也是有可以优化的余地的. 这条语句需要load1000000数据然后基本上全部丢弃,只取10条当然比较慢. 当时我们可以修改为select * from table where id in (select id from table where age > 20 limit 1000000,10).这样虽然也load了一百万的数据,但是由于索引覆盖,要查询的所有字段都在索引中,所以速度会很快. 同时如果ID连续的好,我们还可以select * from table where id > 1000000 limit 10,效率也是不错的,优化的可能性有许多种, 但是核心思想都一样,就是减少load的数据. - 从需求的角度减少这种请求…主要是不做类似的需求(直接跳转到几百万页之后的具体某一页.只允许逐页查看或者按照给定的路线走,这样可预测,可缓存)以及防止ID泄漏且连续被人恶意攻击.
解决超大分页,其实主要是靠缓存,可预测性的提前查到内容,缓存至redis等k-V数据库中,直接返回即可。
2、在阿里巴巴《Java开发手册》中,对超大分页的解决办法是类似于上面提到的第一种:
【推荐】利用延迟关联或者子查询优化超多分页场景。 说明:MySQL并不是跳过offset行,而是取offset+N行,然后返回放弃前offset行,返回N行,那当offset特别大的时候,效率就非常的低下,要么控制返回的总页数,要么对超过特定阈值的页数进行SQL改写。 正例:先快速定位需要获取的id段,然后再关联:
SELECT a.* FROM 表1 a,(select id from 表1 where 条件 LIMIT 100000,20) b w here a.id=b.id
42.怎么查询慢sql日志?
用于记录执行时间超过某个临界值的SQL日志,用于快速定位慢查询,为我们的优化做参考。
1、开启慢查询日志:
配置项:slow_query_log 。
可以使用 show variables like ‘slov_query_log’查看是否开启,如果状态值为OFF,可以使用set GLOBAL slow_query_log = on来开启,它会在datadir下产生一个xxx-slow.log的文件。
2、设置临界时间:
配置项:long_query_time 查看:show VARIABLES like ‘long_query_time’,单位秒设置:set long_query_time=0.5。
实操时应该从长时间设置到短的时间,即将 慢的SQL优化掉。
查看日志,一旦SQL超过了我们设置的临界时间就会被记录到xxx-slow.log中。
43. 慢查询都怎么优化过?
在业务系统中,除了使用主键进行的查询,其他的我都会在测试库上测试其耗时,慢查询的统计主要由运维在做,会定期将业务中的慢查询反馈给我们。慢查询的优化首先要搞明白慢的原因是什么? 是查询条件没有命中索引?是 load了不需要的数据列?还
是数据量太大?所以优化也是针对这三个方向来的。
- 首先分析语句,看看是否load了额外的数据,可能是查询了多余的行并且抛弃掉了,可能是加载了许多结果中并不需要的列,对语句进行分析以及重写。
- 分析语句的执行计划,然后获得其使用索引的情况,之后修改语句或者修改索引,使得语句可以尽可能的命中索引。
- 如果对语句的优化已经无法进行,可以考虑表中的数据量是否太大,如果是的话可以进行横向或者纵向的分表。
44. 主键使用自增ID还是UUID?
推荐使用自增ID,不要使用UUID。
因为在InnoDB存储引擎中,主键索引是作为聚簇索引存在的,也就是说,主键索引的B+树叶子节点上存储了主键索引以及全部的数据(按照顺序),如果主键索引是自增ID,那么只需要不断向后排列即可,如果是UUID,由于到来的ID与原来的大小不确定,会造成非常多的数据插入,数据移动,然后导致产生很多的内存碎片,进而造成插入性能的下降。
总之,在数据量大一些的情况下,用自增主键性能会好一些。
关于主键是聚簇索引,如果没有主键,InnoDB会选择一个唯一键来作为聚簇索引,如果没有唯一键,会生成一个隐式的主键。
45.大表怎么优化?
-
限定数据的范围: 务必禁止不带任何限制数据范围条件的查询语句。比如:我们当用户在查询订单历史的时候,我们可以控制在一个月的范围内。;
-
读/写分离: 经典的数据库拆分方案,主库负责写,从库负责读;
-
缓存: 使用MySQL的缓存,另外对重量级、更新少的数据可以考虑使用应用级别的缓存;
-
有就是通过分库分表的方式进行优化,主要有垂直分表和水平分表
46. 分库分表?
1、为什么要分库分表
如果一个网站业务快速发展,那这个网站流量也会增加,数据的压力也会随之而来,比如电商系统来说双十一大促对订单数据压力很大,Tps十几万并发量,如果传统的架构(一主多从),主库容量肯定无法满足这么高的Tps,业务越来越大,单表数据超出了数据库支持的容量,持久化磁盘IO,传统的数据库性能瓶颈,产品经理业务·必须做,改变程序,数据库刀子切分优化。数据库连接数不够需要分库,表的数据量大,优化后查询性能还是很低,需要分。
2、什么是分库分表
分库分表方案是对关系型数据库数据存储和访问机制的一种补充。
分库:将一个库的数据拆分到多个相同的库中,访问的时候访问一个库
分表:把一个表的数据放到多个表中,操作对应的某个表就行
3、分库分表的几种方式
3.1垂直拆分
(1) 数据库垂直拆分
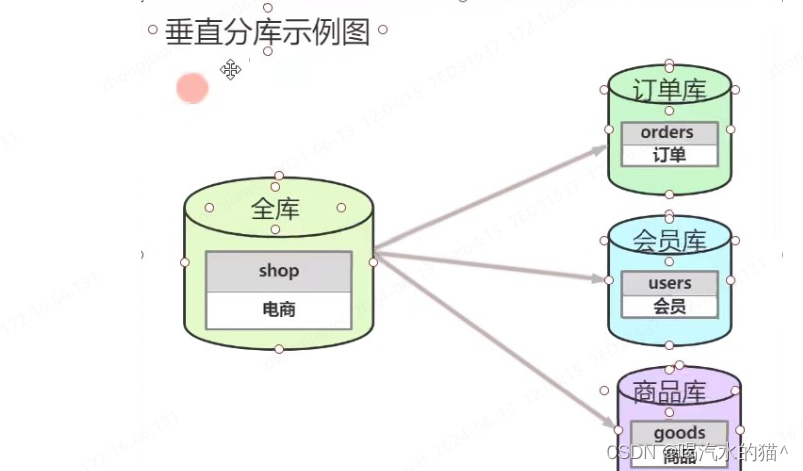
根据业务拆分,如图,电商系统,拆分成订单库,会员库,商品库
(2)表垂直拆分
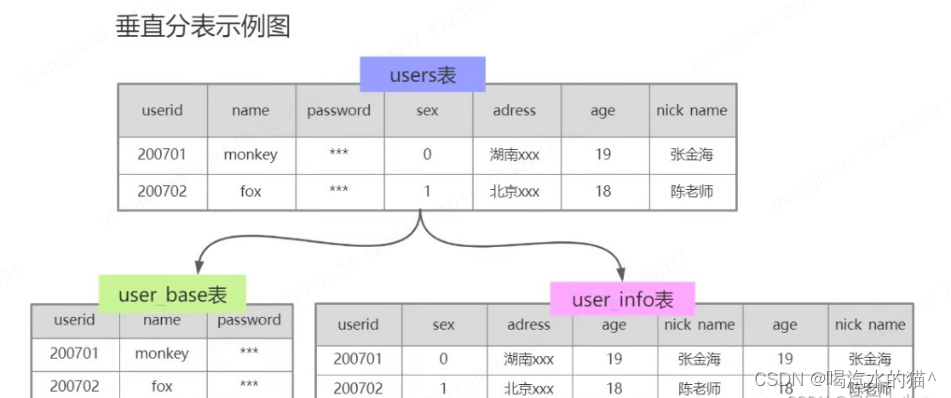
根据业务去拆分表,如图,把user表拆分成user_base表和user_info表,use_base负责存储登录,user_info负责存储基本用户信息
垂直拆分特点:
1.每个库(表)的结构都不一样
2.每个库(表)的数据至少一列一样
3.每个库(表)的并集是全量数据
垂直拆分优缺点:
优点:
1.拆分后业务清晰(专库专用按业务拆分)
2.数据维护简单,按业务不同,业务放到不同机器上
缺点:
1.如果单表的数据量,写读压力大
2.受某种业务决定,或者被限制,也就是说一个业务往往会影响到数据库的瓶颈(性能问题,如双十一抢购)
3.部分业务无法关联join,只能通过java程序接口去调用,提高了开发复杂度
3.2.水平拆分
(1) 数据库水平拆分
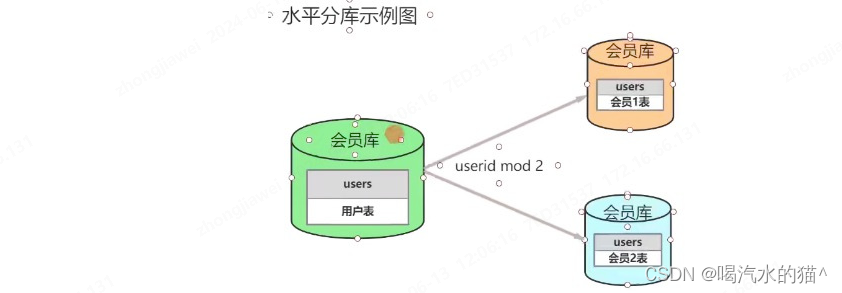
如图,按会员库拆分,拆分成会员1库,会员2库,以userId拆分,userId尾号0-5为1库
6-9为2库,还有其他方式,进行取模,偶数放到1库,奇数放到2库
(2) 表水平拆分
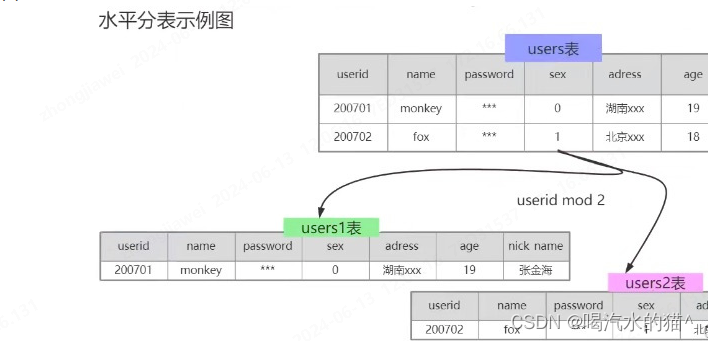
如图把users表拆分成users1表和users2表,以userId拆分,进行取模,偶数放到users1表,奇数放到users2表
水平拆分的其他方式
-
range来分,每个库一段连续的数据,这个一般是按比如时间范围来的,但是这种一般较少用,因为很容易产生热点问题,大量的流量都打在最新的数据上了,优点:扩容的时候,就很容易,因为你只要预备好,给每个月都准备一个库就可以了,到了一个新的月份的时候,自然而然,就会写新的库了 缺点:大部分的 请求,都是访问最新的数据。实际生产用range,要看场景,你的用户不是仅仅访问最新的数据,而是均匀的访问现在的数据以及历史的数据
-
hash分发,优点:可以平均分配每个库的数据量和请求压力 缺点:扩容起来比较麻烦,会有一个数据迁移的这么一个过程
水平拆分特点:
1.每个库(表)的结构都一样
2.每个库(表)的数据都不一样
3.每个库(表)的并集是全量数据
水平拆分优缺点:
优点:
1.单库/单表的数据保持在一定量(减少),有助于性能提高
2.提高了系统的稳定性和负载能力
3.拆分表的结构相同,程序改造较少。
缺点:
1.数据的扩容很有难度维护量大
2.拆分规则很难抽象出来
3.分片事务的一致性问题部分业务无法关联join,只能通过java程序接口去调用
4、分库分表带来的问题
分布式事务
跨库join查询
分布式全局唯一id
开发成本 对程序员要求高
47. MySQL的复制原理以及流程?
主从复制:将主数据库中的DDL和DML操作通过二进制日志(BINLOG)传输到从数据库上,然后将这些日志重新执行。
主从复制的作用
- 主数据库出现问题,可以切换到从数据库。
- 可以进行数据库层面的读写分离。
- 可以在从数据库上进行日常备份。
MySQL主从复制解决的问题
- 数据分布:随意开始或停止复制,并在不同地理位置分布数据备份
- 负载均衡:降低单个服务器的压力
- 高可用和故障切换:帮助应用程序避免单点失败
- 升级测试:可以用更高版本的MySQL作为从库
MySQL主从复制工作原理
- 在主库上把数据操作记录到二进制日志
- 从库将主库的日志复制到自己的中继日志
- 从库读取中继日志的事件,将其重放到从库执行
基本原理流程,3个线程以及之间的关联
主:binlog线程——记录下所有改变了数据库数据的语句,放进master上的binlog中
从:io线程——在使用start slave 之后,负责从master上拉取 binlog 内容,放进自己的relay log中
从:sql执行线程——执行relay log中的语句
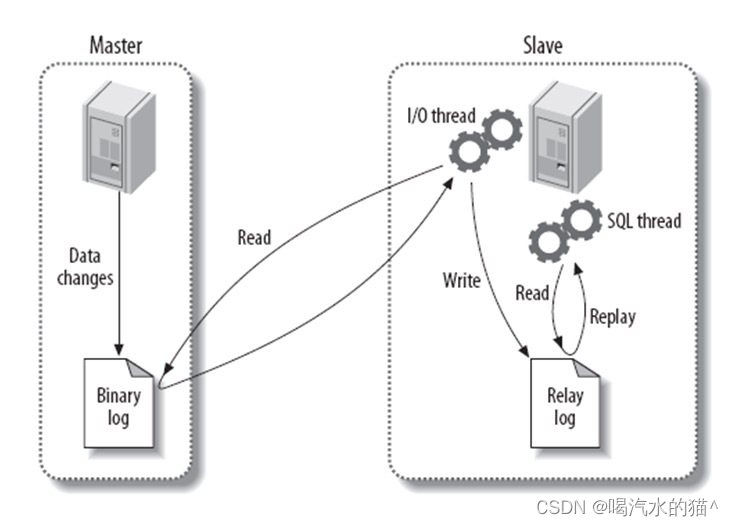
Binary log:主数据库的二进制日志
binlog 有三种格式:
- Statement(Statement-Based Replication,SBR):每一条会修改数据的 SQL语句都会记录在 binlog 中。
- Row(Row-Based Replication,RBR):不记录 SQL 语句上下文信息,记录某一条记录被修改成什么样子了。
- Mixed(Mixed-Based Replication,MBR):Statement 和 Row 的混合体。
Relay log:从服务器的中继日志
第一步:master在每个事务更新数据完成之前,将该操作记录串行地写入到binlog文件中。
第二步:salve开启一个I/O Thread,该线程在master打开一个普通连接,主要工作是binlog dump process。如果读取的进度已经跟上了master,就进入睡眠状态并等待master产生新的事件。I/O线程最终的目的是将这些事件写入到中继日志中。
第三步:SQL Thread会读取中继日志,并顺序执行该日志中的SQL事件,从而与主数据库中的数据保持一致。
48. 读写分离有哪些解决方案?
读写分离是依赖于主从复制,而主从复制又是为读写分离服务的。因为主从复制要求slave不能写只能读(如果对slave执行写操作,那么show slave status将会呈现Slave_SQL_Running=NO,此时你需要按照前面提到的手动同步一下slave)。
方案一
使用mysql-proxy代理
优点:直接实现读写分离和负载均衡,不用修改代码,master和slave用一样的帐号,mysql官方不建议实际生产中使用
缺点:降低性能, 不支持事务
方案二
使用AbstractRoutingDataSource+aop+annotation在dao层决定数据源。如果采用了mybatis, 可以将读写分离放在ORM层,比如mybatis可以通过mybatis plugin拦截sql语句,所有的insert/update/delete都访问master库,所有的select 都访问salve库,这样对于dao层都是透明。 plugin实现时可以通过注解或者分析语句是读写方法来选定主从库。不过这样依然有一个问题, 也就是不支持事务, 所以我们还需要重写一下DataSourceTransactionManager, 将read-only的事务扔进读库, 其余的有读有写的扔进写库。
方案三
使用AbstractRoutingDataSource+aop+annotation在service层决定数据源,可以支持事务.
缺点:类内部方法通过this.xx()方式相互调用时,aop不会进行拦截,需进行特殊处理
九、Linux
1. 什么是Linux
Linux是一套免费使用和自由传播的类Unix操作系统,是一个基于POSIX和Unix 的多用户、多任务、支持多线程和多CPU的操作系统。它能运行主要的Unix工 具软件、应用程序和网络协议。它支持32位和64位硬件。Linux继承了Unix以网 络为核心的设计思想,是一个性能稳定的多用户网络操作系统。
2. Unix和Linux有什么区别?
Linux和Unix都是功能强大的操作系统,都是应用广泛的服务器操作系统,有很 多相似之处,甚至有一部分人错误地认为Unix和Linux操作系统是一样的,然 而,事实并非如此,以下是两者的区别。
- 开源性 Linux是一款开源操作系统,不需要付费,即可使用;Unix是一款对源码实行知 识产权保护的传统商业软件,使用需要付费授权使用。
- 跨平台性 Linux操作系统具有良好的跨平台性能,可运行在多种硬件平台上;Unix操作系 统跨平台性能较弱,大多需与硬件配套使用。
- 可视化界面 Linux除了进行命令行操作,还有窗体管理系统;Unix只是命令行下的系统。
- 硬件环境 Linux操作系统对硬件的要求较低,安装方法更易掌握;Unix对硬件要求比较苛 刻,按照难度较大。
- 用户群体 Linux的用户群体很广泛,个人和企业均可使用;Unix的用户群体比较窄,多是 安全性要求高的大型企业使用,如银行、电信部门等,或者Unix硬件厂商使 用,如Sun等。
相比于Unix操作系统,Linux操作系统更受广大计算机爱好者的喜爱,主要原因 是Linux操作系统具有Unix操作系统的全部功能,并且能够在普通PC计算机上实 现全部的Unix特性,开源免费的特性,更容易普及使用!
3. 什么是 Linux 内核?
Linux 系统的核心是内核。内核控制着计算机系统上的所有硬件和软件,在必要 时分配硬件,并根据需要执行软件。
系统内存管理
应用程序管理
硬件设备管理
文件系统管理
4. Linux的基本组件是什么?
就像任何其他典型的操作系统一样,Linux拥有所有这些组件:内核,shell和 GUI,系统实用程序和应用程序。Linux比其他操作系统更具优势的是每个方面 都附带其他功能,所有代码都可以免费下载。
5. Linux 的体系结构
从大的方面讲,Linux 体系结构可以分为两块:
- 用户空间(User Space) :用户空间又包括用户的应用程序(User Applications)、C 库(C Library) 。
- 内核空间(Kernel Space) :内核空间又包括系统调用接口(System Call Interface)、内核(Kernel)、平台架构相关的代码(Architecture-Dependent Kernel Code) 。
为什么 Linux 体系结构要分为用户空间和内核空间的原因?
- 现代 CPU 实现了不同的工作模式,不同模式下 CPU 可以执行的指令和访问 的寄存器不同。
- Linux 从 CPU 的角度出发,为了保护内核的安全,把系统分成了两部分。
用户空间和内核空间是程序执行的两种不同的状态,我们可以通过两种方式完成 用户空间到内核空间的转移:
1)系统调用;
2)硬件中断。
6. Linux 有哪些系统日志文件?
比较重要的是 /var/log/messages 日志文件。 该日志文件是许多进程日志文件的汇总,从该文件可以看出任何入侵企图或成功的入 侵。
另外,如果胖友的系统里有 ELK 日志集中收集,它也会被收集进去。
7. 什么是CLI?
命令行界面(英语**:command-line interface**,缩写]:CLI)是在图形用户界面得到普及之前使用 为广泛的用户界面,它通常不支持鼠标,用户通过键盘输入指令,计算机接收到指令后,予以执行。也有人称之为字符用户界面
(CUI)通常认为,命令行界面
(CLI)没有图形用户界面
(GUI)那么方便用户操作
因为命令行界面的软件通常需要用户记忆操作的命令,但是,由于其本身的特点,命令行界面要较图形用户界面节约计算机系统的资源。在熟记命令的前提下,使用命令行界面往往要较使用图形用户界面的操作速度要快。所以,图形用户界面的操作系统中,都保留着可选的命令行界面。
8. Linux 的目录结构是怎样的?
这个问题,一般不会问。更多是实际使用时,需要知道。
Linux 文件系统的结构层次鲜明,就像一棵倒立的树, 顶层是其根目录:
常见目录说明:
- /bin: 存放二进制可执行文件(ls,cat,mkdir等),常用命令一般都在这里;
- /etc: 存放系统管理和配置文件;
- /home: 存放所有用户文件的根目录,是用户主目录的基点,比如用户user的主目录就是/home/user,可以用~user表示;
- **/usr **: 用于存放系统应用程序;
- /opt: 额外安装的可选应用程序包所放置的位置。一般情况下,我们可以把
- tomcat等都安装到这里;
- /proc: 虚拟文件系统目录,是系统内存的映射。可直接访问这个目录来获取系统信息;
- /root: 超级用户(系统管理员)的主目录(特权阶级o);
- /sbin: 存放二进制可执行文件,只有root才能访问。这里存放的是系统管理员使用的系统级别的管理命令和程序。如ifconfig等;
- /dev: 用于存放设备文件;
- /mnt: 系统管理员安装临时文件系统的安装点,系统提供这个目录是让用户临时挂载其他的文件系统;
- /boot: 存放用于系统引导时使用的各种文件;
- **/lib **: 存放着和系统运行相关的库文件 ;
- /tmp: 用于存放各种临时文件,是公用的临时文件存储点;
- /var: 用于存放运行时需要改变数据的文件,也是某些大文件的溢出区,比方说各种服务的日志文件(系统启动日志等。)等;
- /lost+found: 这个目录平时是空的,系统非正常关机而留下“无家可归”的文件(windows下叫什么.chk)就在这里。
9.什么是 inode ?
一般来说,面试不会问 inode 。但是 inode 是一个重要概念,是理解 Unix/Linux 文件系统和硬盘储存的基础。
理解inode,要从文件储存说起。
文件储存在硬盘上,硬盘的 小存储单位叫做"扇区"(Sector)。每个扇区储存512字节(相当于0.5KB)。
操作系统读取硬盘的时候,不会一个个扇区地读取,这样效率太低,而是一次性连续读取多个扇区,即一次性读取一个"块"(block)。这种由多个扇区组成的"块",是文件存取的 小单位。"块"的大小, 常见的是4KB,即连续八个 sector组成一个 block。
文件数据都储存在"块"中,那么很显然,我们还必须找到一个地方储存文件的元信息,比如文件的创建者、文件的创建日期、文件的大小等等。这种储存文件元信息的区域就叫做inode,中文译名为"索引节点"。
每一个文件都有对应的inode,里面包含了与该文件有关的一些信息。
10.一台 Linux 系统初始化环境后需要做一些什么安全工作?
添加普通用户登陆,禁止 root 用户登陆,更改 SSH 端口号。修改 SSH 端口不一定绝对哈。
当然,如果要暴露在外网,建议改下:
- 服务器使用密钥登陆,禁止密码登陆。
- 开启防火墙,关闭 SElinux ,根据业务需求设置相应的防火墙规则。
- 装 fail2ban 这种防止 SSH 暴力破击的软件。
- 设置只允许公司办公网出口 IP 能登陆服务器(看公司实际需要)
- 也可以安装 VPN 等软件,只允许连接 VPN 到服务器上。
- 只允许有需要的服务器可以访问外网,其它全部禁止。
- 做好软件层面的防护。
- 设置 nginx_waf 模块防止 SQL 注入。
- 把 Web 服务使用 www 用户启动,更改网站目录的所有者和所属组为 www 。
11.什么叫 CC 攻击?什么叫 DDOS 攻击?
攻击:即是通过大量合法的请求占用大量网络资源,以达到瘫痪网络的目的。
CC 攻击:主要是用来攻击页面的,模拟多个用户不停的对你的页面进行访问,从而使你的系统资源消耗殆尽。
DDOS 攻击:DDoS攻击一般指分布式拒绝攻击,是一种攻击者操纵大量计算机,或位于不同位置的多个攻击者,在短时间内通过将攻击伪装成大量的合法请求,向服务器资源发动的攻击,导致请求数量超过了服务器的处理能力,造成服务器运行缓慢或者宕机。通常由僵尸网络用于执行此恶意任务,由于攻击的发出点是分布在不同地方的,这类攻击称为分布式拒绝服务攻击。
怎么预防 CC 攻击和 DDOS 攻击?
防 CC、DDOS 攻击,这些只能是用硬件防火墙做流量清洗,将攻击流量引入黑洞。
流量清洗这一块,主要是买 ISP 服务商的防攻击的服务就可以,机房一般有空余流量,我们一般是买服务,毕竟攻击不会是持续长时间。
12.请问当用户反馈网站访问慢,你会如何处理?
有哪些方面的因素会导致网站网站访问慢?
1、服务器出口带宽不够用
- 本身服务器购买的出口带宽比较小。一旦并发量大的话,就会造成分给每个用户的出口带宽就小,访问速度自然就会慢。
- 跨运营商网络导致带宽缩减。例如,公司网站放在电信的网络上,那么客户这边对接是长城宽带或联通,这也可能导致带宽的缩减。
2、服务器负载过大,导致响应不过来
可以从两个方面入手分析:
- 分析系统负载,使用 w 命令或者 uptime 命令查看系统负载。如果负载很高,则使用 top 命令查看 CPU ,MEM 等占用情况,要么是 CPU 繁忙,要么是内存不够。
- 如果这二者都正常,再去使用 sar 命令分析网卡流量,分析是不是遭到了攻击。一旦分析出问题的原因,采取对应的措施解决,如决定要不要杀死一些进程,或者禁止一些访问等。
3、数据库瓶颈
- 如果慢查询比较多。那么就要开发人员或 DBA 协助进行 SQL 语句的优化。
- 如果数据库响应慢,考虑可以加一个数据库缓存,如 Redis 等。然后,也可以搭建 MySQL 主从,一台 MySQL 服务器负责写,其他几台从数据库负责读。
4、网站开发代码没有优化好
- 例如 SQL 语句没有优化,导致数据库读写相当耗时。
针对网站访问慢,怎么去排查?
1、首先要确定是用户端还是服务端的问题。当接到用户反馈访问慢,那边自己立即访问网站看看,如果自己这边访问快,基本断定是用户端问题,就需要耐心跟客户解释,协助客户解决问题。不要上来就看服务端的问题。一定要从源头开始,逐步逐步往下。
2、如果访问也慢,那么可以利用浏览器的调试功能,看看加载那一项数据消耗时间过多,是图片加载慢,还是某些数据加载慢。
3、针对服务器负载情况。查看服务器硬件(网络、CPU、内存)的消耗情况。如果是购买的云主机,比如阿里云,可以登录阿里云平台提供各方面的监控,比如 CPU、内存、带宽的使用情况。
4、如果发现硬件资源消耗都不高,那么就需要通过查日志,比如看看 MySQL慢查询的日志,看看是不是某条 SQL 语句查询慢,导致网站访问慢。怎么去解决?
- 如果是出口带宽问题,那么久申请加大出口带宽。
- 如果慢查询比较多,那么就要开发人员或 DBA 协助进行 SQL 语句的优化。
- 如果数据库响应慢,考虑可以加一个数据库缓存,如 Redis 等等。然后也可以搭建MySQL 主从,一台 MySQL 服务器负责写,其他几台从数据库负责读。
- 申请购买 CDN 服务,加载用户的访问。
- 如果访问还比较慢,那就需要从整体架构上进行优化咯。做到专角色专用,多台服务器提供同一个服务。
13. 命令
1、文件管理命令 cat 命令
cat 命令用于连接文件并打印到标准输出设备上。
cat 主要有三大功能:
1.一次显示整个文件:
cat filename
2.从键盘创建一个文件
cat > filename
只能创建新文件,不能编辑已有文件
3.将几个文件合并为一个文件:
cat file1 file2 > file
2. chmod 命令
Linux/Unix 的文件调用权限分为三级 : 文件拥有者、群组、其他。利用 chmod 可以控制文件如何被他人所调用。
用于改变 linux 系统文件或目录的访问权限。用它控制文件或目录的访问权限。该命令有两种用法。一种是包含字母和操作符表达式的文字设定法;另一种是包含数字的数字设定法。
每一文件或目录的访问权限都有三组,每组用三位表示,分别为文件属主的读、写和执行权限;与属主同组的用户的读、写和执行权限;系统中其他用户的读、写和执行权限。可使用 ls -l test.txt 查找。
3. chown 命令
chown 将指定文件的拥有者改为指定的用户或组,用户可以是用户名或者用户 ID;组可以是组名或者组 ID;文件是以空格分开的要改变权限的文件列表,支持通配符。
1 ‐c 显示更改的部分的信息
2 ‐R 处理指定目录及子目录
实例:
(1) 改变拥有者和群组 并显示改变信息
1 chown ‐c mail:mail log2012.log
(1) 改变文件群组
1 chown ‐c :mail t.log
(2) 改变文件夹及子文件目录属主及属组为 mail
1 chown ‐cR mail: test/
4. cp 命令
将源文件复制至目标文件,或将多个源文件复制至目标目录。
注意:命令行复制,如果目标文件已经存在会提示是否覆盖,而在 shell 脚本中,如果不加 -i 参数,则不会提示,而是直接覆盖!
1 ‐i 提示
2 ‐r 复制目录及目录内所有项目
3 ‐a 复制的文件与原文件时间一样
实例:
(1) 复制 a.txt 到 test 目录下,保持原文件时间,如果原文件存在提示是否覆盖。
1 cp ‐ai a.txt test
(2) 为 a.txt 建议一个链接(快捷方式)
1 cp ‐s a.txt link_a.txt
5.find 命令
用于在文件树中查找文件,并作出相应的处理。
6. head 命令
head 用来显示档案的开头至标准输出中,默认 head 命令打印其相应文件的开头 10 行。常用参数:
1 ‐n<行数> 显示的行数(行数为复数表示从最后向前数)
实例:
(1) 显示 1.log 文件中前 20 行
1 head 1.log ‐n 20
(2) 显示 1.log 文件前 20 字节
1 head ‐c 20 log2014.log
(3) 显示 t.log 后 10 行
1 head ‐n ‐10 t.log
7.mv 命令
移动文件或修改文件名,根据第二参数类型(如目录,则移动文件;如为文件则重命令该文件)。
当第二个参数为目录时,第一个参数可以是多个以空格分隔的文件或目录,然后移动第一个参数指定的多个文件到第二个参数指定的目录中。
实例:
(1) 将文件 test.log 重命名为 test1.txt
1 mv test.log test1.txt
(2) 将文件 log1.txt,log2.txt,log3.txt 移动到根的 test3 目录中
1 mv llog1.txt log2.txt log3.txt /test3
(3) 将文件 file1 改名为 file2,如果 file2 已经存在,则询问是否覆盖
1 mv ‐i log1.txt log2.txt
(4) 移动当前文件夹下的所有文件到上一级目录
1 mv * ../
8. rm 命令
删除一个目录中的一个或多个文件或目录,如果没有使用 -r 选项,则 rm 不会删除目录。如果使用 rm 来删除文件,通常仍可以将该文件恢复原状。
1 rm[选项] 文件…
实例:
(1) 删除任何 .log 文件,删除前逐一询问确认:
1 rm ‐i *.log
(2) 删除 test 子目录及子目录中所有档案删除,并且不用一一确认:
1 rm ‐rf test
(3) 删除以 -f 开头的文件
1 rm ‐‐ ‐f*
9.tail 命令
用于显示指定文件末尾内容,不指定文件时,作为输入信息进行处理。常用查看日志文件。常用参数:
1 ‐f 循环读取(常用于查看递增的日志文件)
2 ‐n<行数> 显示行数(从后向前)
(1)循环读取逐渐增加的文件内容
1 ping 127.0.0.1 > ping.log &
后台运行:可使用 jobs -l 查看,也可使用 fg 将其移到前台运行。
1 tail ‐f ping.log
10. vim 命令
Vim是从 vi 发展出来的一个文本编辑器。代码补完、编译及错误跳转等方便编程的功能特别丰富,在程序员中被广泛使用。
11. mkdir 命令
mkdir 命令用于创建文件夹。
可用选项:
-m: 对新建目录设置存取权限,也可以用 chmod 命令设置;
-p: 可以是一个路径名称。此时若路径中的某些目录尚不存在,加上此选项后,系统将自动建立好那些尚不在的目录,即一次可以建立多个目录。
实例:
(1) 当前工作目录下创建名为 t的文件夹
1 mkdir t
(2) 在 tmp 目录下创建路径为 test/t1/t 的目录,若不存在,则创建:
1 mkdir ‐p /tmp/test/t1/t
12.pwd 命令
pwd 命令用于查看当前工作目录路径。
实例:
(1) 查看当前路径
1 pwd
(2) 查看软链接的实际路径
1 pwd
13.rmdir 命令
从一个目录中删除一个或多个子目录项,删除某目录时也必须具有对其父目录的写权限。
注意:不能删除非空目录实例:
(1)当 parent 子目录被删除后使它也成为空目录的话,则顺便一并删除:
1 rmdir ‐p parent/child/child11
14. netstat 命令
Linux netstat命令用于显示网络状态。
15. ping 命令
Linux ping命令用于检测主机。
执行ping指令会使用ICMP传输协议,发出要求回应的信息,若远端主机的网络功能没有问题,就会回应该信息,因而得知该主机运作正常。指定接收包的次数
ping ‐c 2 www.baidu.com
十、Redis
1.什么是Redis
Redis(Remote Dictionary Server) 是一个使用 C 语言编写的,开源的(BSD许 可)高性能非关系型(NoSQL)的键值对数据库。
Redis 可以存储键和五种不同类型的值之间的映射。键的类型只能为字符串,值 支持五种数据类型:字符串、列表、集合、散列表、有序集合。
与传统数据库不同的是 Redis 的数据是存在内存中的,所以读写速度非常快, 因此 redis 被广泛应用于缓存方向,每秒可以处理超过 10万次读写操作,是已知性能快的Key-Value DB。
另外,Redis 也经常用来做分布式锁。除此之 外,Redis 支持事务 、持久化、LUA脚本、LRU驱动事件、多种集群方案。
2.Redis有哪些优缺点
优点
- 读写性能优异, Redis能读的速度是110000次/s,写的速度是81000次/s。
- 支持数据持久化,支持AOF和RDB两种持久化方式。
- 支持事务,Redis的所有操作都是原子性的,同时Redis还支持对几个操作合并 后的原子性执行。
- 数据结构丰富,除了支持string类型的value外还支持hash、set、zset、list等 数据结构。
- 支持主从复制,主机会自动将数据同步到从机,可以进行读写分离。
缺点
- 数据库容量受到物理内存的限制,不能用作海量数据的高性能读写,因此Redis 适合的场景主要局限在较小数据量的高性能操作和运算上。
- Redis 不具备自动容错和恢复功能,主机从机的宕机都会导致前端部分读写请求 失败,需要等待机器重启或者手动切换前端的IP才能恢复。
- 主机宕机,宕机前有部分数据未能及时同步到从机,切换IP后还会引入数据不一 致的问题,降低了系统的可用性。
- Redis 较难支持在线扩容,在集群容量达到上限时在线扩容会变得很复杂。为避 免这一问题,运维人员在系统上线时必须确保有足够的空间,这对资源造成了很大的 浪费。
3. 为什么要用 Redis /为什么要用缓存
主要从“高性能”和“高并发”这两点来看待这个问题。
高性能:
假如用户第一次访问数据库中的某些数据。这个过程会比较慢,因为是从硬盘上 读取的。将该用户访问的数据存在数缓存中,这样下一次再访问这些数据的时候 就可以直接从缓存中获取了。操作缓存就是直接操作内存,所以速度相当快。如 果数据库中的对应数据改变的之后,同步改变缓存中相应的数据即可!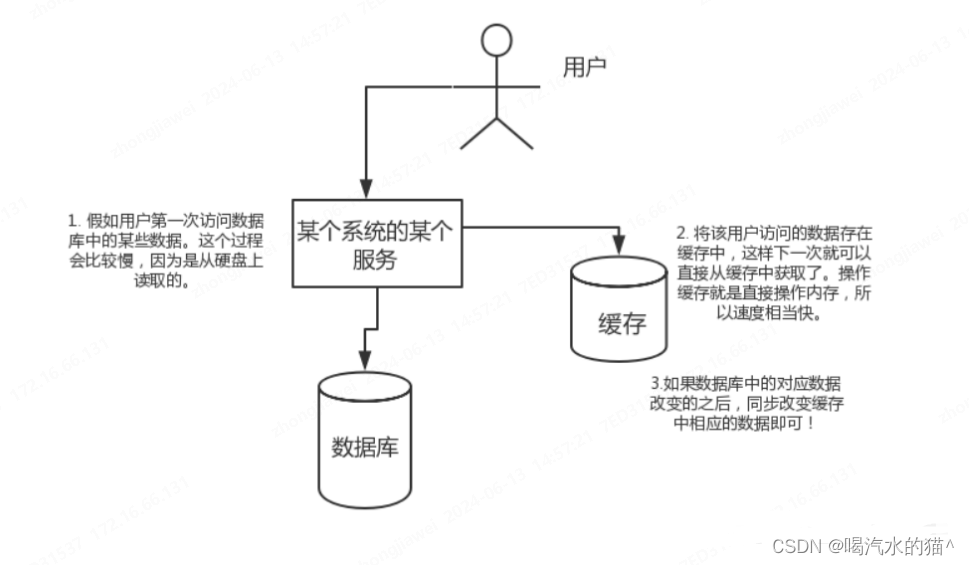
高并发:
直接操作缓存能够承受的请求是远远大于直接访问数据库的,所以我们可以考虑 把数据库中的部分数据转移到缓存中去,这样用户的一部分请求会直接到缓存这 里而不用经过数据库。
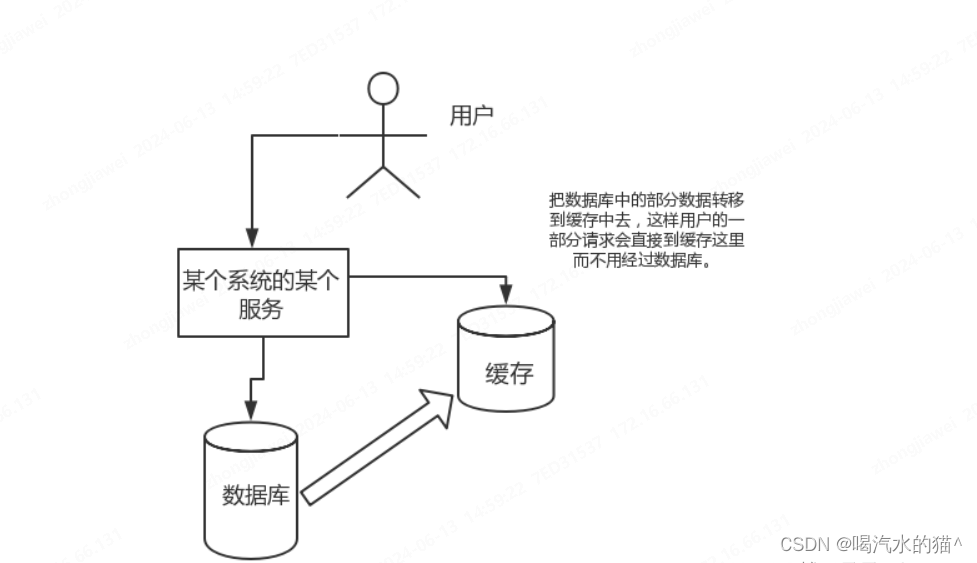
4.为什么要用 Redis 而不用 map/guava 做缓存?
缓存分为本地缓存和分布式缓存。以 Java 为例,使用自带的 map 或者 guava 实现的是本地缓存,主要的特点是轻量以及快速,生命周期随着 jvm 的销毁 而结束,并且在多实例的情况下,每个实例都需要各自保存一份缓存,缓存不具有一致性。
使用 redis 或 memcached 之类的称为分布式缓存,在多实例的情况下,各实 例共用一份缓存数据,缓存具有一致性。缺点是需要保持 redis 或 memcached 服务的高可用,整个程序架构上较为复杂。
5. Redis为什么这么快
- 完全基于内存,绝大部分请求是纯粹的内存操作,非常快速。数据存在内存 中,类似于 HashMap,HashMap 的优势就是查找和操作的时间复杂度都是 O(1);
- 数据结构简单,对数据操作也简单,Redis 中的数据结构是专门进行设计 的;
- 采用单线程,避免了不必要的上下文切换和竞争条件,也不存在多进程或者 多线程导致的切换而消耗 CPU,不用去考虑各种锁的问题,不存在加锁释放锁 操作,没有因为可能出现死锁而导致的性能消耗;
- 使用多路 I/O 复用模型,非阻塞 IO;
- 使用底层模型不同,它们之间底层实现方式以及与客户端之间通信的应用协 议不一样,Redis 直接自己构建了 VM 机制 ,因为一般的系统调用系统函数的 话,会浪费一定的时间去移动和请求;
6.Redis有哪些数据类型
Redis主要有5种数据类型,包括String,List,Set,Zset,Hash,满足大部分 的使用要求 数据类型 可以存储 的值 操作 应用场景
| 数据类型 | 可以存储 的值 | 操作 | 应用场景 |
|---|---|---|---|
| STRING | 字符串、 整数或者 浮点数 | 对整个字 符串或者 字符串的 其中一部 分执行操 作 对整数和 浮点数执 行自增或 者自减操 作 | 做简单的 键值对缓 存 |
| LIST | 列表 | 从两端压 入或者弹 出元素 对单个或 者多个元 素进行修 剪, 只保留一 个范围内 的元素 | 存储一些 列表型的 数据结 构,类似 粉丝列 表、文章 的评论列 表之类的 数据 |
| SET | 无序集合 | 添加、获 取、移除 单个元素 检查一个 元素是否 存在于集 合中 | 交集、并 集、差集 的操作, 比如交 集,可以 把两个人 的粉丝列 |
| HASH | 包含键值 对的无序 散列表 | 添加、获 取、移除 单个键值 对 获取所有 键值对 检查某个 键是否存 在 | 结构化的 数据,比 如一个对 象 |
| ZSET | 有序集合 | 添加、获 取、删除 元素 根据分值 范围或者 成员来获 取元素 计算一个 键的排名 | 去重但可 以排序, 如获取排 名前几名 的用户 |
7.Redis的应用场景
总结一
计数器
可以对 String 进行自增自减运算,从而实现计数器功能。Redis 这种内存型数 据库的读写性能非常高,很适合存储频繁读写的计数量。
缓存
将热点数据放到内存中,设置内存的大使用量以及淘汰策略来保证缓存的命中率。
会话缓存
可以使用 Redis 来统一存储多台应用服务器的会话信息。当应用服务器不再存 储用户的会话信息,也就不再具有状态,一个用户可以请求任意一个应用服务 器,从而更容易实现高可用性以及可伸缩性。
全页缓存(FPC)
除基本的会话token之外,Redis还提供很简便的FPC平台。以Magento为例, Magento提供一个插件来使用Redis作为全页缓存后端。此外,对WordPress的用户来说,Pantheon有一个非常好的插件 wp-redis,这个插件能帮助你以 快速度加载你曾浏览过的页面。
查找表
例如 DNS 记录就很适合使用 Redis 进行存储。查找表和缓存类似,也是利用了 Redis 快速的查找特性。但是查找表的内容不能失效,而缓存的内容可以失效, 因为缓存不作为可靠的数据来源。
消息队列(发布/订阅功能)
List 是一个双向链表,可以通过 lpush 和 rpop 写入和读取消息。不过好使用 Kafka、RabbitMQ 等消息中间件。
分布式锁实现 在分布式场景下,无法使用单机环境下的锁来对多个节点上的进程进行同步。可 以使用 Redis 自带的 SETNX 命令实现分布式锁,除此之外,还可以使用官方提 供的 RedLock 分布式锁实现。
其它
Set 可以实现交集、并集等操作,从而实现共同好友等功能。ZSet 可以实现有 序性操作,从而实现排行榜等功能。
总结二
Redis相比其他缓存,有一个非常大的优势,就是支持多种数据类型。
数据类型说明string字符串,简单的k-v存储hashhash格式,value为field和 value,适合ID-Detail这样的场景。list简单的list,顺序列表,支持首位或者末 尾插入数据set无序list,查找速度快,适合交集、并集、差集处理sorted set有 序的set
其实,通过上面的数据类型的特性,基本就能想到合适的应用场景了。
string——适合简单的k-v存储,类似于memcached的存储结构,短信验证 码,配置信息等,就用这种类型来存储。
hash——一般key为ID或者唯一标示,value对应的就是详情了。如商品详情, 个人信息详情,新闻详情等。
list——因为list是有序的,比较适合存储一些有序且数据相对固定的数据。如省 市区表、字典表等。因为list是有序的,适合根据写入的时间来排序,如:新 的***,消息队列等。
set——可以简单的理解为ID-List的模式,如微博中一个人有哪些好友,set 牛的地方在于,可以对两个set提供交集、并集、差集操作。例如:查找两个人 共同的好友等。
Sorted Set——是set的增强版本,增加了一个score参数,自动会根据score的 值进行排序。比较适合类似于top 10等不根据插入的时间来排序的数据。 如上所述,虽然Redis不像关系数据库那么复杂的数据结构,但是,也能适合很 多场景,比一般的缓存数据结构要多。了解每种数据结构适合的业务场景,不仅 有利于提升开发效率,也能有效利用Redis的性能。
8.什么是Redis持久化?
持久化就是把内存的数据写到磁盘中去,防止服务宕机了内存数据丢失。
9.Redis 的持久化机制是什么?各自的优缺点?
Redis 提供两种持久化机制 RDB(默认) 和 AOF 机制:
RDB:是Redis DataBase缩写快照
RDB是Redis默认的持久化方式。按照一定的时间将内存的数据以快照的形式保 存到硬盘中,对应产生的数据文件为dump.rdb。通过配置文件中的save参数来 定义快照的周期。
优点:
- 只有一个文件 dump.rdb,方便持久化。
- 容灾性好,一个文件可以保存到安全的磁盘。
- 性能大化,fork 子进程来完成写操作,让主进程继续处理命令,所以是 IO 大化。使用单独子进程来进行持久化,主进程不会进行任何 IO 操作,保证了 redis 的高性能
- 相对于数据集大时,比 AOF 的启动效率更高。
缺点:
- 数据安全性低。RDB 是间隔一段时间进行持久化,如果持久化之间 redis 发 生故障,会发生数据丢失。所以这种方式更适合数据要求不严谨的时候)
- AOF(Append-only file)持久化方式: 是指所有的命令行记录以 redis 命 令请 求协议的格式完全持久化存储)保存为 aof 文件。
AOF:持久化
AOF持久化(即Append Only File持久化),则是将Redis执行的每次写命令记录 到单独的日志文件中,当重启Redis会重新将持久化的日志中文件恢复数据。 当两种方式同时开启时,数据恢复Redis会优先选择AOF恢复。
优点:
- 数据安全,aof 持久化可以配置 appendfsync 属性,有 always,每进行一 次 命令操作就记录到 aof 文件中一次。
- 通过 append 模式写文件,即使中途服务器宕机,可以通过 redis-checkaof 工具解决数据一致性问题。
- AOF 机制的 rewrite 模式。AOF 文件没被 rewrite 之前(文件过大时会对命 令 进行合并重写),可以删除其中的某些命令(比如误操作的 flushall))
缺点:
- AOF 文件比 RDB 文件大,且恢复速度慢。
- 数据集大的时候,比 rdb 启动效率低。
优缺点是什么?
- AOF文件比RDB更新频率高,优先使用AOF还原数据。
- AOF比RDB更安全也更大
- RDB性能比AOF好
- 如果两个都配了优先加载AOF
10.如何选择合适的持久化方式
- 一般来说, 如果想达到足以媲美PostgreSQL的数据安全性,你应该 同时使用两种持久化功能。在这种情况下,当 Redis 重启的时候会优先载 入AOF文件来恢复原始的数据,因为在通常情况下AOF文件保存的数据集 要比RDB文件保存的数据集要完整。
- 如果你非常关心你的数据, 但仍然可以承受数分钟以内的数据丢失, 那么你可以只使用RDB持久化。
- 有很多用户都只使用AOF持久化,但并不推荐这种方式,因为定时生 成RDB快照(snapshot)非常便于进行数据库备份, 并且 RDB 恢复数据 集的速度也要比AOF恢复的速度要快,除此之外,使用RDB还可以避免 AOF程序的bug。
- 如果你只希望你的数据在服务器运行的时候存在,你也可以不使用任 何持久化方式。
11.Redis持久化数据和缓存怎么做扩容?
如果Redis被当做缓存使用,使用一致性哈希实现动态扩容缩容。
如果Redis被当做一个持久化存储使用,必须使用固定的keys-tonodes映射关系,节点的数量一旦确定不能变化。否则的话(即Redis节点需要动态变化的情况),必须使用可以在运行时进行数据再平衡的一套系统,而当前只有Redis集群可以做到这样。
12.Redis的过期键的删除策略
我们都知道,Redis是key-value数据库,我们可以设置Redis中缓存的key的过期时间。Redis的过期策略就是指当Redis中缓存的key过期了,Redis如何处理。
过期策略通常有以下三种:
-
定时过期:每个设置过期时间的key都需要创建一个定时器,到过期时间就会立即清除。该策略可以立即清除过期的数据,对内存很友好;但是会占用大量的CPU资源去处理过期的数据,从而影响缓存的响应时间和吞吐量。
-
惰性过期:只有当访问一个key时,才会判断该key是否已过期,过期则清除。该策略可以 大化地节省CPU资源,却对内存非常不友好。极端情况可能出现大量的过期key没有再次被访问,从而不会被清除,占用大量内存。
-
定期过期:每隔一定的时间,会扫描一定数量的数据库的expires字典中一定数量的key,并清除其中已过期的key。该策略是前两者的一个折中方案。通过调整定时扫描的时间间隔和每次扫描的限定耗时,可以在不同情况下使得CPU和内存资源达到 优的平衡效果。
(expires字典会保存所有设置了过期时间的key的过期时间数据,其中,key是指向键空间中的某个键的指针,value是该键的毫秒精度的UNIX时间戳表示的过期时间。键空间是指该Redis集群中保存的所有键。)
Redis中同时使用了惰性过期和定期过期两种过期策略。
13.Redis key的过期时间和永久有效分别怎么设置?
EXPIRE和PERSIST命令。
14.我们知道通过expire来设置key 的过期时间,那么对过期的数据怎么处理呢?
除了缓存服务器自带的缓存失效策略之外(Redis默认的有6中策略可供选择),我们还可以根据具体的业务需求进行自定义的缓存淘汰,常见的策略有两种:
-
定时去清理过期的缓存;
-
当有用户请求过来时,再判断这个请求所用到的缓存是否过期,过期的话就去底层系统得到新数据并更新缓存。
两者各有优劣,第一种的缺点是维护大量缓存的key是比较麻烦的,第二种的缺点就是每次用户请求过来都要判断缓存失效,逻辑相对比较复杂!具体用哪种方案,大家可以根据自己的应用场景来权衡。
15. Redis的内存淘汰策略有哪些?
Redis的内存淘汰策略是指在Redis的用于缓存的内存不足时,怎么处理需要新写入且需要申请额外空间的数据。
全局的键空间选择性移除:
- noeviction:当内存不足以容纳新写入数据时,新写入操作会报错。
- allkeys-lru:当内存不足以容纳新写入数据时,在键空间中,移除近少使用的key。(这个是最常用的)
- allkeys-random:当内存不足以容纳新写入数据时,在键空间中,随机移除某个key。(不建议)
设置过期时间的键空间选择性移除:
- volatile-lru:当内存不足以容纳新写入数据时,在设置了过期时间的键空间中,移除 近 少使用的key。
- volatile-random:当内存不足以容纳新写入数据时,在设置了过期时间的键空间中,随机移除某个key。
- volatile-ttl:当内存不足以容纳新写入数据时,在设置了过期时间的键空间中,有更早过期时间的key优先移除。
总结
Redis的内存淘汰策略的选取并不会影响过期的key的处理。内存淘汰策略用于处理内存不足时的需要申请额外空间的数据;过期策略用于处理过期的缓存数据。
16. Redis事务的概念
Redis 事务的本质是通过MULTI、EXEC、WATCH等一组命令的集合。
事务支持一次执行多个命令,一个事务中所有命令都会被序列化。在事务执行过程,会按照顺序串行化执行队列中的命令,其他客户端提交的命令请求不会插入到事务执行命令序列中。
总结:redis事务就是一次性、顺序性、排他性的执行一个队列中的一系列命令。
17.Redis事务的三个阶段
\1. 事务开始 MULTI
\2. 命令入队
\3. 事务执行 EXEC
事务执行过程中,如果服务端收到有EXEC、DISCARD、WATCH、MULTI之外的请求,将会把请求放入队列中排队
18.说说Redis哈希槽的概念?
Redis集群没有使用一致性hash,而是引入了哈希槽的概念,Redis集群有16384 个哈希槽,每个key通过CRC16校验后对16384取模来决定放置哪个槽,集群的每个节点负责一部分hash槽。
19.Redis集群会有写操作丢失吗?为什么?
Redis并不能保证数据的强一致性,这意味这在实际中集群在特定的条件下可能会丢失写操作。
20.Redis集群之间是如何复制的?
异步复制
21.Redis集群最大节点个数是多少?
16384个
22.Redis是单线程的,如何提高多核CPU的利用率?
可以在同一个服务器部署多个Redis的实例,并把他们当作不同的服务器来使用,在某些时候,无论如何一个服务器是不够的, 所以,如果你想使用多个CPU,你可以考虑一下分片(shard)。
23.为什么要做Redis分区?
分区可以让Redis管理更大的内存,Redis将可以使用所有机器的内存。如果没有分区,你 多只能使用一台机器的内存。分区使Redis的计算能力通过简单地增加计算机得到成倍提升,Redis的网络带宽也会随着计算机和网卡的增加而成倍增长。
24.Redis分区有什么缺点?
- 涉及多个key的操作通常不会被支持。例如你不能对两个集合求交集,因为他们可能被存储到不同的Redis实例(实际上这种情况也有办法,但是不能直接使用交集指令)。
- 同时操作多个key,则不能使用Redis事务.
- 分区使用的粒度是key,不能使用一个非常长的排序key存储一个数据集
- 当使用分区的时候,数据处理会非常复杂,例如为了备份你必须从不同的Redis 实例和主机同时收集RDB / AOF文件。
- 分区时动态扩容或缩容可能非常复杂。Redis集群在运行时增加或者删除Redis 节点,能做到 大程度对用户透明地数据再平衡,但其他一些客户端分区或者代理分区方法则不支持这种特性。然而,有一种预分片的技术也可以较好的解决这个问题。
25.什么是 RedLock?
Redis 官方站提出了一种权威的基于 Redis 实现分布式锁的方式名叫 Redlock,此种方式比原先的单节点的方法更安全。它可以保证以下特性:
-
安全特性:互斥访问,即永远只有一个 client 能拿到锁
-
避免死锁: 终 client 都可能拿到锁,不会出现死锁的情况,即使原本锁住某资源的 client crash 了或者出现了网络分区
-
容错性:只要大部分 Redis 节点存活就可以正常提供服务缓存异常缓存雪崩
缓存雪崩是指缓存同一时间大面积的失效,所以,后面的请求都会落到数据库上,造成数据库短时间内承受大量请求而崩掉。
解决方案
-
缓存数据的过期时间设置随机,防止同一时间大量数据过期现象发生。
-
一般并发量不是特别多的时候,使用 多的解决方案是加锁排队。
-
给每一个缓存数据增加相应的缓存标记,记录缓存的是否失效,如果缓存标记失效,则更新数据缓存。
26.缓存穿透
缓存穿透是指缓存和数据库中都没有的数据,导致所有的请求都落到数据库上,造成数据库短时间内承受大量请求而崩掉。
解决方案
-
接口层增加校验,如用户鉴权校验,id做基础校验,id<=0的直接拦截;
-
从缓存取不到的数据,在数据库中也没有取到,这时也可以将key-value对写为key-null,缓存有效时间可以设置短点,如30秒(设置太长会导致正常情况也没法使用)。这样可以防止攻击用户反复用同一个id暴力攻击
-
采用布隆过滤器,将所有可能存在的数据哈希到一个足够大的 bitmap 中,一个一定不存在的数据会被这个 bitmap 拦截掉,从而避免了对底层存储系统的查询压力附加对于空间的利用到达了一种极致,
27.缓存击穿
缓存击穿是指缓存中没有但数据库中有的数据(一般是缓存时间到期),这时由于并发用户特别多,同时读缓存没读到数据,又同时去数据库去取数据,引起数据库压力瞬间增大,造成过大压力。和缓存雪崩不同的是,缓存击穿指并发查同一条数据,缓存雪崩是不同数据都过期了,很多数据都查不到从而查数据库。
解决方案
1.设置热点数据永远不过期。
2.加互斥锁,互斥锁缓存预热
缓存预热就是系统上线后,将相关的缓存数据直接加载到缓存系统。这样就可以避免在用户请求的时候,先查询数据库,然后再将数据缓存的问题!用户直接查询事先被预热的缓存数据!
解决方案
-
直接写个缓存刷新页面,上线时手工操作一下;
-
数据量不大,可以在项目启动的时候自动进行加载;
-
定时刷新缓存;
28.缓存降级
当访问量剧增、服务出现问题(如响应时间慢或不响应)或非核心服务影响到核心流程的性能时,仍然需要保证服务还是可用的,即使是有损服务。系统可以根据一些关键数据进行自动降级,也可以配置开关实现人工降级。
缓存降级的 终目的是保证核心服务可用,即使是有损的。而且有些服务是无法降级的(如加入购物车、结算)。
在进行降级之前要对系统进行梳理,看看系统是不是可以丢卒保帅;从而梳理出哪些必须誓死保护,哪些可降级;比如可以参考日志级别设置预案:
-
一般:比如有些服务偶尔因为网络抖动或者服务正在上线而超时,可以自动降级;
-
警告:有些服务在一段时间内成功率有波动(如在95~100%之间),可以自动降级或人工降级,并发送告警;
-
错误:比如可用率低于90%,或者数据库连接池被打爆了,或者访问量突然猛增到系统能承受的 大阀值,此时可以根据情况自动降级或者人工降级;
-
严重错误:比如因为特殊原因数据错误了,此时需要紧急人工降级。
服务降级的目的,是为了防止Redis服务故障,导致数据库跟着一起发生雪崩问题。因此,对于不重要的缓存数据,可以采取服务降级策略,例如一个比较常见的做法就是,Redis出现问题,不去数据库查询,而是直接返回默认值给用户。
29.热点数据和冷数据
热点数据,缓存才有价值。对于冷数据而言,大部分数据可能还没有再次访问到就已经被挤出内存,不仅占用内存,而且价值不大。频繁修改的数据,看情况考虑使用缓存对于热点数据,比如我们的某IM产品,生日祝福模块,当天的寿星列表,缓存以后可能读取数十万次。
再举个例子,某导航产品,我们将导航信息,缓存以后可能读取数百万次。
数据更新前至少读取两次,缓存才有意义。这个是基本的策略,如果缓存还没有起作用就失效了,那就没有太大价值了。
那存不存在,修改频率很高,但是又不得不考虑缓存的场景呢?
有!比如,这个读取接口对数据库的压力很大,但是又是热点数据,这个时候就需要考虑通过缓存手段,减少数据库的压力,比如我们的某助手产品的,点赞数,收藏数,分享数等是非常典型的热点数据,但是又不断变化,此时就需要将数据同步保存到Redis缓存,减少数据库压力。
30.缓存热点key
缓存中的一个Key(比如一个促销商品),在某个时间点过期的时候,恰好在这个时间点对这个Key有大量的并发请求过来,这些请求发现缓存过期一般都会从后端DB加载数据并回设到缓存,这个时候大并发的请求可能会瞬间把后端DB压垮。
解决方案对缓存查询加锁,如果KEY不存在,就加锁,然后查DB入缓存,然后解锁;其他进程如果发现有锁就等待,然后等解锁后返回数据或者进入DB查询
31.Redis与Memcached的区别
两者都是非关系型内存键值数据库,现在公司一般都是用 Redis 来实现缓存,而且 Redis 自身也越来越强大了!Redis 与 Memcached 主要有以下不同:
| 对比参数 | Redis | Memcac hed |
|---|---|---|
| 类型 | 1. 支持内存 2. 非关系型数据库 | 1. 支持内存 2. 键值对形式 3. 缓存形式 |
| 数据存储类型 | 1. String 2. List 3. Set 4. Hash 5. Sort Set 【俗称 ZSet】 | 1. 文本型 2. 二进制类型 |
| 查询【操作】类型 | 1. 批量操作 2. 事务支持 3. 每个类型不同的 CRUD | 1.常用的 CRUD 2. 少量的其他命令 |
| 附加功能 | 1. 发布/订阅模式 2. 主从分区 3. 序列化 支持 4. 脚本支持 【Lua脚本】 | 1. 多线程服务支持 |
| 网络IO模型 | 1. 单线程的多路 IO 复用模型 | 1. 多线程,非阻塞IO模式 |
| 事件库 | 自封转简易事件库 AeEvent | 贵族血统的 LibEvent 事件库 |
| 持久化支持 | 1. RDB 2. AOF | 不支持 |
| 集群模式 | 原生支持 cluster 模式,可以实现主从复制,读写分离 | 没有原生的集群模式,需要依靠客户端来实现往集群中分片写入数据 |
| 内存管理机制 | 在 Redis 中,并不是所有数据都一直存储在内存中,可以将一些很久没用 的 value 交换到磁盘 | Memcach ed 的数据则会一直在内存中, Memcach ed 将内存分割成特定长度的块来存储数据,以完全解决内存碎片的问题。但是这种方式会使得内存的利用率不高,例如块的大小为 128 bytes,只存储 100 bytes 的数据,那么剩下的 28 bytes 就浪费掉了。 |
| 复杂数据 | 纯key- value,数据量非常大,并发量非常大的业务 | |
| 适用场景 | 结构,有持久化,高可用需求,value 存储内容较大 |
(1) memcached所有的值均是简单的字符串,redis作为其替代者,支持更为丰富的数据类型
(2) redis的速度比memcached快很多
(3) redis可以持久化其数据
32.如何保证缓存与数据库双写时的数据一致性?
| 问题场景 | 描述 | 解决 |
|---|---|---|
| 先写缓存,再写数据库,缓存写成功,数据库写失败 | 缓存写成功,但写数据库失败或者响应延迟,则下次读取(并发读)缓存时,就出现脏读 | 这个写缓存的方式,本身就是错误的,需要改为先写数据库,把旧缓存置为失效;读取数据的时候,如果缓存不存在,则读取数据库再写缓存 |
| 先写数据库,再写缓存,数据库写成功,缓存写失败 | 写数据库成功,但写缓存失败,则下次读取(并发读)缓存时,则读不到数据 | 缓存使用时,假如读缓存失败,先读数据库,再回写缓存的方式实现 |
| 需要缓存异步刷新 | 指数据库操作和写缓存不在一个操作步骤中,比如在分布式场景下,无法做到同时写缓存或需要异步刷新(补救措施)时候 | 确定哪些数据适合此类场景,根据经验值确定合理的数据不一致时间,用户数据刷新的时间间隔 |
33.Redis常见性能问题和解决方案?
-
Master 好不要做任何持久化工作,包括内存快照和AOF日志文件,特别是不要启用内存快照做持久化。
-
如果数据比较关键,某个Slave开启AOF备份数据,策略为每秒同步一次。
-
为了主从复制的速度和连接的稳定性,Slave和Master 好在同一个局域网内。
-
尽量避免在压力较大的主库上增加从库
-
Master调用BGREWRITEAOF重写AOF文件,AOF在重写的时候会占大量的CPU和内存资源,导致服务load过高,出现短暂服务暂停现象。
-
为了Master的稳定性,主从复制不要用图状结构,用单向链表结构更稳定,即主从关系为:Master<–Slave1<–Slave2<–Slave3…,这样的结构也方便解决单点故障问题,实现Slave对Master的替换,也即,如果
Master挂了,可以立马启用Slave1做Master,其他不变。
34.假如Redis里面有1亿个key,其中有10w个key是以某个固定的已知的前缀开头的,如果将它们全部找出来?
使用keys指令可以扫出指定模式的key列表。
对方接着追问:
如果这个redis正在给线上的业务提供服务,那使用keys指令会有什么问题?
这个时候你要回答redis关键的一个特性:
redis是单线程的。keys指令会导致线程阻塞一段时间,线上服务会停顿,直到指令执行完毕,服务才能恢复。这个时候可以使用scan指令,scan指令可以无阻塞的提取出指定模式的key列表,但是会有一定的重复概率,在客户端做一次去重就可以了,但是整体所花费的时间会比直接用keys指令长。
35.使用Redis做过异步队列吗,是如何实现的?
使用list类型保存数据信息,rpush生产消息,lpop消费消息,当lpop没有消息时,可以sleep一段时间,然后再检查有没有信息,如果不想sleep的话,可以使用blpop, 在没有信息的时候,会一直阻塞,直到信息的到来。
redis可以通过 pub/sub主题订阅模式实现一个生产者,多个消费者,当然也存在一定的缺点,当消费者下线时,生产的消息会丢失。
36.Redis如何实现延时队列
使用sortedset,使用时间戳做score, 消息内容作为key,调用zadd来生产消息,消费者使用zrangbyscore获取n秒之前的数据做轮询处理。
37.Redis回收进程如何工作的?
-
一个客户端运行了新的命令,添加了新的数据。
-
Redis检查内存使用情况,如果大于maxmemory的限制, 则根据设定好的策略进行回收。
-
一个新的命令被执行,等等。
-
所以我们不断地穿越内存限制的边界,通过不断达到边界然后不断地回收回到边界以下。
如果一个命令的结果导致大量内存被使用(例如很大的集合的交集保存到一个新的键),不用多久内存限制就会被这个内存使用量超越。
38.Redis回收使用的是什么算法?
LRU算法
十一、Rabbit MQ
1.什么是RabbitMQ?
RabbitMQ是一款开源的,Erlang编写的,基于AMQP协议的消息中间件
2.Rabbitmq 的使用场景
- 异步处理 - 相比于传统的串行、并行方式,提高了系统吞吐量。
- 应用解耦 - 系统间通过消息通信,不用关心其他系统的处理。
- 流量削锋 - 可以通过消息队列长度控制请求量;可以缓解短时间内的高并发请 求。
- 日志处理 - 解决大量日志传输。
- 消息通讯 - 消息队列一般都内置了高效的通信机制,因此也可以用在纯的消息通 讯。比如实现点对点消息队列,或者聊天室等。
3.RabbitMQ基本概念
- Broker: 简单来说就是消息队列服务器实体
- Exchange: 消息交换机,它指定消息按什么规则,路由到哪个队列
- Queue: 消息队列载体,每个消息都会被投入到一个或多个队列
- Binding: 绑定,它的作用就是把exchange和queue按照路由规则绑定起来
- Routing Key: 路由关键字,exchange根据这个关键字进行消息投递
- VHost: vhost 可以理解为虚拟 broker ,即 mini-RabbitMQ server。其内部 均含有独立的 queue、exchange 和 binding 等,但最最重要的是,其拥有独立的 权限系统,可以做到 vhost 范围的用户控制。当然,从 RabbitMQ 的全局角度, vhost 可以作为不同权限隔离的手段(一个典型的例子就是不同的应用可以跑在不同 的 vhost 中)。
- Producer: 消息生产者,就是投递消息的程序
- Consumer: 消息消费者,就是接受消息的程序
- Channel: 消息通道,在客户端的每个连接里,可建立多个channel,每个 channel代表一个会话任务
由Exchange、Queue、RoutingKey三个才能决定一个从Exchange到Queue的 唯一的线路。
4. MQ优缺点
优点:
应用解耦
生产者(客户端)发送消息到消息队列中去,接受者(服务端)处理消息,需要消费的系统直接去消息队列取消息进行消费即可,而不需要和其他系统有耦合,这显然也提高了系统的扩展性。
异步提速
将用户的请求数据存储到消息队列之后就立即返回结果。随后,系统再对消息进行消费。
削峰限流
先将短时间内高并发产生的事务消息存储在消息队列中,然后后端服务再慢慢根据自己的能力去消费这些消息,这样就避免直接把后端服务打垮掉。
缺点
系统可用性降低
系统引入的外部依赖越多,系统稳定性越差。一旦 MQ 宕机,就会对业务造成影响。
系统复杂度提高
MQ 的加入大大增加了系统的复杂度,以前系统间是同步的远程调用,现在是通过 MQ 进行异步调用。
一致性问题
A 系统处理完业务,通过 MQ 给 B、C、D 三个系统发消息数据,如果 B 系统、C 系统处理成功,D 系统处理失败,则会造成数据处理的不一致。
5.Kafka、ActiveMQ、RabbitMQ、RocketMQ 有 什么优缺点?
| ActiveMQ | RabbitMQ | RocketMQ | Kafka | ZeroMQ | |
|---|---|---|---|---|---|
| 单机吞吐 量 | 比 RabbitM Q低 | 2.6w/s( 消息做持 久化) | 11.6w/s | 17.3w/s | 29w/s |
| 开发语言 | Java | Erlang | Java | Scala/Java | C |
| 主要维护者 | Apache | Mozilla/Spring | Alibaba | Apache | iMatix创始人已去世 |
| 成熟度 | 成熟 | 成熟 | 开源版本不够成熟 | 比较成熟 | 只有C、PHP等版本成熟 |
| 订阅形式 | 点对点 (p2p)、广 播(发布订阅) | 提供了4 种: direct, topic,Headers 和 fanout。 fanout就 是广播模 式 | 基于 topic/me ssageTag 以及按照消息类 型、属性 进行正则 匹配的发 布订阅模 式 | 基于topic 以及按照 topic进行 正则匹配的发布订 阅模式 | 点对点(P2P) |
| 持久化 | 支持少量 堆积 | 支持少量 堆积 | 支持大量 堆积 | 支持大量 堆积 | 不支持 |
| 顺序消息 | 不支持 | 不支持 | 支持 | 支持 | 不支持 |
| 性能稳定 性 | 好 | 好 | 一般 | 较差 | 很好 |
| 集群方式 | 支持简单 集群模 式,比 如’主备’,对 高级集群 模式支持 不好。 | 支持简单 集群,'复 制’模 式,对高 级集群模 式支持不 好。 | 常用 多 对’Mast erSlave’ 模 式,开源 版本需手 动切换 Slave变成 Master | 天然 的‘Lead erSlave’无 状态集 群,每台 服务器既 是Master 也是Slave | 不支持 |
| 管理界面 | 一般 | 较好 | 一般 | 无 | 无 |
综上,各种对比之后,有如下建议:
一般的业务系统要引入 MQ,最早大家都用 ActiveMQ,但是现在确实大家用 的不多了,没经过大规模吞吐量场景的验证,社区也不是很活跃,所以大家还是 算了吧,我个人不推荐用这个了;
后来大家开始用 RabbitMQ,但是确实 erlang 语言阻止了大量的 Java 工程师 去深入研究和掌控它,对公司而言,几乎处于不可控的状态,但是确实人家是开 源的,比较稳定的支持,活跃度也高;
不过现在确实越来越多的公司会去用 RocketMQ,确实很不错,毕竟是阿里出 品,但社区可能有突然黄掉的风险(目前 RocketMQ 已捐给 Apache,但 GitHub 上的活跃度其实不算高)对自己公司技术实力有绝对自信的,推荐用 RocketMQ,否则回去老老实实用 RabbitMQ 吧,人家有活跃的开源社区,绝 对不会黄。
所以中小型公司,技术实力较为一般,技术挑战不是特别高,用 RabbitMQ 是 不错的选择;大型公司,基础架构研发实力较强,用 RocketMQ 是很好的选 择。
如果是大数据领域的实时计算、日志采集等场景,用 Kafka 是业内标准的,绝 对没问题,社区活跃度很高,绝对不会黄,何况几乎是全世界这个领域的事实性 规范。
6.RabbitMQ的工作模式
1.simple模式(即最简单的收发模式)

特点:
一个生产者对应一个消费者,通过队列进行消息传递。
该模式使用 direct 交换机,direct 交换机是 RabbitMQ 默认交换机。
2. 工作队列模式(Work Queue)

与简单模式相比,工作队列模式(Work Queue)多了一些消费者,该模式也使用 direct 交换机,应用于处理消息较多的情况。特点如下:
一个队列对应多个消费者。
一条消息只会被一个消费者消费。
消息队列默认采用 轮询 的方式将消息平均发送给消费者。
3. 发布订阅模式(Publish/Subscribe)
在开发过程中,有一些消息需要不同消费者进行不同的处理,如电商网站的同一条促销信息需要短信发送、邮件发送、站内信发送等。此时可以使用发布订阅模式(Publish/Subscribe),特点如下:
- 生产者将消息发送给交换机,交换机将消息转发到绑定此交换机的 每个队列 中。
- 工作队列模式的交换机只能将消息发送给一个队列,发布订阅模式的交换机能将消息发送给多个队列。
- 发布订阅模式使用 fanout 交换机。
4. 路由模式(Routing)
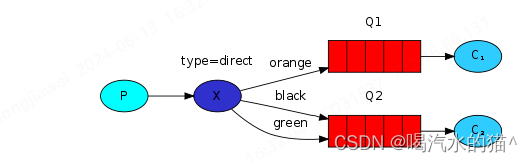
使用发布订阅模式时,所有消息都会发送到绑定的队列中,但很多时候,不是所有消息都无差别的发布到所有队列中。比如电商网站的促销活动,618大促可能会发布到所有队列;而一些小的促销活动为了节约成本,只发布到站内信队列。此时需要使用 路由模式 (Routing)完成这一需求。特点如下:
- 每个队列绑定路由关键字 RoutingKey
- 生产者将带有 RoutingKey 的消息发送给交换机,交换机根据 RoutingKey 转发到指定队列。
- 路由模式使用 direct 交换机。
- 能按照路由键将消息发送给指定队列
5. 通配符模式(Topics)
通配符模式(Topics)是在路由模式的基础上,给队列绑定带通配符的路由关键字,只要消息的 RoutingKey 能实现通配符匹配,就会将消息转发到该队列。通配符模式比路由模式更灵活,通配符模式使用 topic 交换机。 能按照通配符规则将消息发送给指定队列
通配符规则如下:
- 队列设置 RoutingKey 时,“#” 可以匹配任意多个单词,“*” 可以匹配任意一个单词。
- 消息设置 RoutingKey 时,RoutingKey 由多个单词构成,中间以 “.” 分割。
7.如何保证RabbitMQ消息的顺序性?
拆分多个 queue,每个 queue 一个 consumer,就是多一些 queue 而已,确 实是麻烦点;或者就一个 queue 但是对应一个 consumer,然后这个 consumer 内部用内存队列做排队,然后分发给底层不同的 worker 来处理。
8.如何保证消息不被重复消费?或者说,如何保证消息消费时的幂等性?
1.什么情况会导致消息被重复消费呢
生产者:生产者可能会重复推送一条数据到 MQ 中,比如 Controller 接口被重复调用了 2 次,没有做接口幂等性导致的;
MQ:在消费者消费完准备响应 ack 消息消费成功时,MQ 突然挂了,导致 MQ 以为消费者还未消费该条数据,MQ 恢复后再次推送了该条消息,导致了重复消费。
消费者:消费者已经消费完消息,正准备但是还未响应给ack消息到时,此时消费者挂了,服务重启后 MQ 以为消费者还没有消费该消息,再次推送了该条消息。
2.解决方案
2.1使用数据库唯一键约束
缺点:局限性很大,仅仅只能用在我们数据新增场景,并且性能也比较低
2.2使用乐观锁
假设是更新订单状态,在发送的消息的时候带上修改字段的版本号
缺点:如果说更新字段比较多,并且更新场景比较多,可能会导致数据库字段增加并且还有可能出现多条消息同时在队列中此时他们修改字段版本号一致,排在后续的消息无法被消费
2.3 简单的消息去重,插入消费记录,增加数据库判断
优点:很多场景下的确能起到不错的效果
缺点:
这个消费者的代码执行需要1秒,重复消息在执行期间(假设100毫秒)内到达(例如生产者快速重发,Broker重启等),增加校验的地方是不是还是没数据(因为上一条消息还没消费完,没有记录)
那么就会穿透掉检查的挡板,最后导致重复的消息消费逻辑进入到非幂等安全的业务代码中,从而引发重复消费的问题
2.4并发消息去重基于消息幂等表
缺点:如果说第一次消息投递异常没有消费成功,并且没有将消息状态给置为成功或者没有删除消息表记录,此时延时消费每次执行下列都是一直处于消费中,最后消费就会被视为消费失败而被投递到死信Topic中
方案:插入的消息表必须要带一个最长消费过期时间,例如10分钟.
上述方案只需要一个存储的中心媒介,那我们可以选择更灵活的存储中心媒介,比如Redis。使用Redis有两个好处:
- 性能上损耗更低
- 上面我们讲到的超时时间可以直接利用Redis本身的ttl实现
3.总结
- 利用数据库唯一键约束
- 可以利用我们的乐观锁
- 插入消费记录
- 不丢和不重是矛盾的(在分布式场景下),总的来说,开发者根据业务的实际需求来选择相应的方式即可。
9.如何保证RabbitMQ消息的可靠传输?
一、可靠传输
本篇文章主要讲 RabbitMQ 如何保证消息的可靠传输,所以在讲RabbitMQ的实现之前,我们需要先来搞懂一个问题,就是什么是消息的可靠传输。
在 RabbitMQ 中,一个消息从产生到被消费大致需要经过三个步骤,即生产者生产消息,消息投递到 RabbitMQ,RabbitMQ 再将消息推送消费者(或者是消费者拉取),最终消费者将这条消息成功消费。
所以消息丢失也可以划分为三种情况——生产者、消息队列、消费者,如下图所示:
所以消息的可靠传输,就是确保消息能够百分百从生产者发送到服务器,再从服务器发送到消费者。接下来我们就针对这三种情况分别讨论解决方案。
二、生产者投递消息失败
1. 事务机制
使用 RabbitMQ 的事务功能,此时可以选择用 RabbitMQ 提供的事务功能,就是生产者发送数据之前开启 RabbitMQ 事务 channel.txSelect,然后发送消息,如果消息没有成功被 RabbitMQ 接收到,那么生产者会收到异常报错,此时就可以回滚事务 channel.txRollback,然后重试发送消息;如果收到了消息,那么可以提交事务 channel.txCommit。
// 开启事务
channel.txSelect();
try {
// 发送消息
} catch(Exception e) {
channel.txRollback();
// 重发消息
}
// 提交事务
channel.txCommit();
事务机制可以基本确保生产者投递消息成功,但是这种方式有比较大的缺点,基本上 RabbitMQ 事务机制(同步)一搞,基本上吞吐量会下来,因为太耗性能了。
2. confirm机制
针对上述问题,如果还要确保 RabbitMQ 生产者的消息正确投递,可以开启 confirm 模式,在生产者端设置开启 confirm 模式之后,你每次写的消息都会分配一个唯一的 id,然后如果写入了 RabbitMQ 中,RabbitMQ 会给你回传一个 ACK 消息,告诉你说这个消息 ok 了。
如果 RabbitMQ 没能处理这个消息,会回调你一个 nack 接口,告诉你这个消息接收失败,你可以重试。而且你可以结合这个机制自己在内存里维护每个消息 id 的状态,如果超过一定时间还没接收到这个消息的回调,那么你可以重发。
try {channel.confirmSelect(); //将信道置为 publisher confirm 模式// 之后正常发送消息channel.basicPushlish("exchange", "routingKey", null,"publisher confirm test".getBytes());if (!channel.waitFormConfirms()) {System.out.println("Send message failed");// do something else...} catch (InterruptedException e) {e.printStackTrace();}
}
事务机制和 confirm 机制最大的不同在于,事务机制是同步的,你提交一个事务之后会阻塞在那儿,但是 confirm 机制是异步的,你发送个消息之后就可以发送下一个消息,然后那个消息 RabbitMQ 接收之后会异步回调你一个接口通知你这个消息接收到了。
所以一般生产者到 RabbitMQ 这块避免数据丢失,会采用 confirm 机制更多些。
三、消息队列自身丢失
就是 RabbitMQ 自己弄丢了数据,这个你必须开启 RabbitMQ 的持久化,就是消息写入之后会持久化到磁盘,哪怕是 RabbitMQ 自己挂了,恢复之后会自动读取之前存储的数据,一般数据不会丢。除非极其罕见的是,RabbitMQ 还没持久化,自己就挂了,可能导致少量数据丢失,但是这个概率较小。
设置持久化有两个步骤:
-
创建 queue 的时候将其设置为持久化
这样就可以保证 RabbitMQ 持久化 queue 的元数据,但是不会持久化 queue 里的数据。 -
发送消息时将消息的 deliveryMode 设置为 2
就是将消息设置为持久化,此时 RabbitMQ 就会将消息持久化到磁盘上去。
必须要同时设置这两个持久化才行,RabbitMQ 哪怕是挂了,再次重启,也会从磁盘上重启恢复 queue,恢复这个 queue 里的数据。
同时持久化也可以跟生产者那边的 confirm 机制配合起来,只有消息被持久化到磁盘后,才会通知生产者 ack 了,所以哪怕是在持久化到磁盘之前,RabbitMQ 挂了,数据丢了,生产者收不到 ACK,你也是可以自己重发的。
注意,哪怕是你给 RabbitMQ 开启了持久化机制,也有一种可能,就是这个消息写到了 RabbitMQ 中,但是还没来得及持久化到磁盘上,结果不巧,此时 RabbitMQ 挂了,就会导致内存中的数据丢失。
四、消费者宕机
对于消费者端所产生的情况就是:消费者成功接收到消息,但是还未将消息处理完毕就宕机了。针对这种情况,可以利用 RabbitMQ 提供的 消息确认机制。
- 消息确认机制
为了保证消息从队列可靠地到达消费者,RabbitMQ 提供了消息确认机制(message acknowledgement)。消费者在订阅队列时,可以指定 autoAck 参数:
-
当 autoAck 等于 true 时,RabbitMQ 会自动把发送出去的消息置为确认,然后从内存(或者磁盘)中删除,而不管消费者是否真正地消费到了这些消息;
-
当 autoAck 等于 false 时,RabbitMQ 会等待消费者显示地回复确认信号后才从内存(后者磁盘)中移去消息(实质上是先打上删除标记,之后再删除)。
所以对于消费者可能发生宕机地情况,我们可以将 autoAck 参数置为 false,消费者就有足够的时间处理这条消息,不用担心处理消息过程中消费者进程挂掉后消息丢失的问题,因为 RabbitMQ 会一直等待并且持有这条消息,直到消费者显示调用 Basic.Ack 命令为止。
当 autoAck 参数设置为 false,对于 RabbitMQ 服务端而言,队列中的消息分成了两个部分:一部分是等待投递给消费者的消息,另一部分是已经投递给消费者,但是还没有收到消费者确认信号的消息。如果 RabbitMQ 一直没有收到消费者的确认信号,并且消费此消息的消费者已经断开连接,则 RabbitMQ 会安排该消息重新进入队列,等待投递给下一个消费者,当然也可能还是原来的那个消费者。
十二、 Spring Boot
1.什么是 Spring Boot?
Spring Boot 是 Spring 开源组织下的子项目,是 Spring 组件一站式解决方案,主要是简化了使用 Spring 的难度,简省了繁重的配置,提供了各种启动器,开发者能快速上手。
2.Spring Boot 有哪些优点?
Spring Boot 主要有如下优点:
-
容易上手,提升开发效率,为 Spring 开发提供一个更快、更广泛的入门体验。
-
开箱即用,远离繁琐的配置。
-
提供了一系列大型项目通用的非业务性功能,例如:内嵌服务器、安全管理、运行数据监控、运行状况检查和外部化配置等。
-
没有代码生成,也不需要XML配置。
-
避免大量的 Maven 导入和各种版本冲突。
3.Spring Boot 的核心注解是哪个?它主要由哪几个注解组成的?
启动类上面的注解是@SpringBootApplication,它也是 Spring Boot 的核心注解,主要组合包含了以下 3 个注解:
-
@SpringBootConfiguration:组合了 @Configuration 注解,实现配置文件的功能。
-
@EnableAutoConfiguration:打开自动配置的功能,也可以关闭某个自动配置的选项,如关闭数据源自动配置功能: @SpringBootApplication(exclude = { DataSourceAutoConfiguration.class })。
-
@ComponentScan:Spring组件扫描。
4.Spring Boot 自动配置原理是什么?
注解 @EnableAutoConfiguration, @Configuration, @ConditionalOnClass 就是自动配置的核心,
@EnableAutoConfiguration 给容器导入META-INF/spring.factories 里定义的自动配置类。筛选有效的自动配置类。
每一个自动配置类结合对应的 xxxProperties.java 读取配置文件进行自动配置功能。
5.Spring Boot 中如何解决跨域问题 ?
跨域可以在前端通过 JSONP 来解决,但是 JSONP 只可以发送 GET 请求,无法发送其他类型的请求,在 RESTful 风格的应用中,就显得非常鸡肋,因此我们推荐在后端通过 (CORS,Cross-origin resource sharing) 来解决跨域问题。这种解决方案并非 Spring Boot 特有的,在传统的 SSM 框架中,就可以通过 CORS 来解决跨域问题,只不过之前我们是在 XML 文件中配置 CORS ,现在可以通过实现WebMvcConfigurer接口然后重写addCorsMappings方法解决跨域问题。
1 @Configuration
2 public class CorsConfig implements WebMvcConfigurer { 3
4 @Override
5 public void addCorsMappings(CorsRegistry registry) {
6 registry.addMapping("/**")
7 .allowedOrigins("*")
8 .allowCredentials(true)
9 .allowedMethods("GET", "POST", "PUT", "DELETE", "OPTIONS")
10 .maxAge(3600);
11 }
12
13 }
项目中前后端分离部署,所以需要解决跨域的问题。
我们使用cookie存放用户登录的信息,在spring拦截器进行权限控制,当权限不符合时,直接返回给用户固定的json结果。
当用户登录以后,正常使用;当用户退出登录状态时或者token过期时,由于拦截器和跨域的顺序有问题,出现了跨域的现象。
我们知道一个http请求,先走filter,到达servlet后才进行拦截器的处理,如果我们把cors放在filter里,就可以优先于权限拦截器执行。
1 @Configuration
2 public class CorsConfig {
4 @Bean
5 public CorsFilter corsFilter() {
6 CorsConfiguration corsConfiguration = new CorsConfiguration();
7 corsConfiguration.addAllowedOrigin("*");
8 corsConfiguration.addAllowedHeader("*");
9 corsConfiguration.addAllowedMethod("*");
10 corsConfiguration.setAllowCredentials(true);
11 UrlBasedCorsConfigurationSource urlBasedCorsConfigurationSource = new U rlBasedCorsConfigurationSource();
12 urlBasedCorsConfigurationSource.registerCorsConfiguration("/**", corsCo nfiguration);
13 return new CorsFilter(urlBasedCorsConfigurationSource);
14 }
15
16 }
7.springBoot的核心配置文件有哪些,作用是什么
application 和 bootstrap 配置文件。
application: 用于项目的自动化配置。
bootstrap: 一些不能被覆盖的属性和加密或解密的场景。比application要先加载。
8.spring Boot常用注解
@SpringBootApplication: SpringBootConfiguration配置类、componentScan扫描包、EnableAutoConfiguration导入其他配置类
@RestController: @ResponseBody和@Controller的作用。
@Component,@Service,@Controller,@Repository: 将类注入容器。
@GetMapping、@PostMapping、@PutMapping、@DeleteMapping: 映射请求,只能接收的对应的请求。
@AutoWired: 按照类型匹配注入。
@Qualifier: 和AutoWired联合使用,在按照类型匹配的基础上,在按照名称匹配。
@Resource: 按照名称匹配依赖注入。
@Bean: 用于将方法返回值对象放入容器。
@RequestParam: 获取查询参数。即url?name=这种形式
@RequestBody: 该注解用于获取请求体数据(body),get没有请求体,故而一般用于post请求。@PathVariable: 获取路径参数。即url/{id}这种形式。
@Value: 将外部的值动态注入到 Bean 中。
@Value(“${}”):可以获取配置文件的值。
@Value(“#{}”):表示SpEl(Spring Expression Language是Spring表达式语言,可以在运行时查询和操作数据。)表达式通常用来获取 bean 的属性,或者调用 bean 的某个方法。
十三、Spring Cloud
1.什么是Spring Cloud
Spring Cloud是一系列框架的有序集合。它利用Spring Boot的开发便利性巧妙地简化了分布式系统基础设施的开发,如服务发现注册、配置中心、智能路由、消息总线、负载均衡、断路器、数据监控等,都可以用Spring Boot的开发风格做到一键启动和部署。
Spring Cloud并没有重复制造轮子,它只是将各家公司开发的比较成熟、经得起实际考验的服务框架组合起来,通过Spring Boot风格进行再封装屏蔽掉了复杂的配置和实现原理,最终给开发者留出了一套简单易懂、易部署和易维护的分布式系统开发工具包。
2.为什么需要学习Spring Cloud?
不论是商业应用还是用户应用,在业务初期都很简单,我们通常会把它实现为单体结构的应用。
但是,随着业务逐渐发展,产品思想会变得越来越复杂,单体结构的应用也会越来越复杂。这就会给应用带来如下的几个问题:
-
代码结构混乱:业务复杂,导致代码量很大,管理会越来越困难。同时,这也会给业务的快速迭代带来巨大挑战;
-
开发效率变低:开发人员同时开发一套代码,很难避免代码冲突。开发过程会伴随着不断解决冲突的过程,这会严重的影响开发效率;
-
排查解决问题成本高:线上业务发现 bug,修复 bug 的过程可能很简单。但是,由于只有一套代码,需要重新编译、打包、上线,成本很高。
由于单体结构的应用随着系统复杂度的增高,会暴露出各种各样的问题。近些年来,微服务架构逐渐取代了单体架构,且这种趋势将会越来越流行。Spring Cloud是目前最常用的微服务开发框架,已经在企业级开发中大量的应用。
3.Spring Cloud 优缺点?
微服务的框架那么多比如:dubbo、Kubernetes,为什么就要使用Spring Cloud的呢?
优点:
- 产出于Spring大家族,Spring在企业级开发框架中无人能敌,来头很大,可以保证后续的更新、完善
- 组件丰富,功能齐全。Spring Cloud 为微服务架构提供了非常完整的支持。例如、配置管理、服务发现、断路器、微服务网关等;
- Spring Cloud 社区活跃度很高,教程很丰富,遇到问题很容易找到解决方案服务拆分粒度更细,耦合度比较低,有利于资源重复利用,有利于提高开发效率可以更精准的制定优化服务方案,提高系统的可维护性减轻团队的成本,可以并行开发,不用关注其他人怎么开发,先关注自己的开发微服务可以是跨平台的,可以用任何一种语言开发适于互联网时代,产品迭代周期更短。
缺点:
- 微服务过多,治理成本高,不利于维护系统
- 分布式系统开发的成本高(容错,分布式事务等)对团队挑战大总的来说优点大过于缺点,目前看来Spring Cloud是一套非常完善的分布式框架,目前很多企业开始用微服务、Spring Cloud的优势是显而易见的。因此对于想研究微服务架构的同学来说,学习Spring Cloud是一个不错的选择。
4.Spring Cloud Config
集中配置管理工具,分布式系统中统一的外部配置管理,默认使用Git来存储配置,可以支持客户端配置的刷新及加密、解密操作。
5.Spring Cloud Netflix
Netflix OSS 开源组件集成,包括Eureka、Hystrix、Ribbon、Feign、Zuul等核心组件。
Eureka:服务治理组件,包括服务端的注册中心和客户端的服务发现机制;
Ribbon:负载均衡的服务调用组件,具有多种负载均衡调用策略;
Hystrix:服务容错组件,实现了断路器模式,为依赖服务的出错和延迟提供了容错能力;
Feign:基于Ribbon和Hystrix的声明式服务调用组件;
Zuul:API网关组件,对请求提供路由及过滤功能。
6.Spring Cloud Bus
用于传播集群状态变化的消息总线,使用轻量级消息代理链接分布式系统中的节点,可以用来动态刷新集群中的服务配置。
Spring Cloud Consul 基于Hashicorp Consul的服务治理组件。
Spring Cloud Security 安全工具包,对Zuul代理中的负载均衡OAuth2客户端及登录认证进行支持。
7.Spring Cloud Sleuth
Spring Cloud应用程序的分布式请求链路跟踪,支持使用Zipkin、HTrace和基于日志(例如ELK)的跟踪。
8.Spring Cloud Stream
轻量级事件驱动微服务框架,可以使用简单的声明式模型来发送及接收消息,主要实现为Apache Kafka及RabbitMQ。
9.Spring Cloud Task
用于快速构建短暂、有限数据处理任务的微服务框架,用于向应用中添加功能性和非功能性的特性。
Spring Cloud Zookeeper 基于Apache Zookeeper的服务治理组件。
Spring Cloud Gateway API网关组件,对请求提供路由及过滤功能。
10.Spring Cloud OpenFeign
基于Ribbon和Hystrix的声明式服务调用组件,可以动态创建基于Spring MVC 注解的接口实现用于服务调用,在Spring Cloud 2.0中已经取代Feign成为了一等公民。
11.SpringBoot和SpringCloud的区别?
SpringBoot专注于快速方便的开发单个个体微服务。
SpringCloud是关注全局的微服务协调整理治理框架,它将SpringBoot开发的一个个单体微服务整合并管理起来,为各个微服务之间提供,配置管理、服务发现、断路器、路由、微代理、事件总线、全局锁、决策竞选、分布式会话等等集成服务
SpringBoot可以离开SpringCloud独立使用开发项目, 但是SpringCloud离不开SpringBoot ,属于依赖的关系
SpringBoot专注于快速、方便的开发单个微服务个体,SpringCloud关注全局的服务治理框架。
12.什么是Spring Cloud Config?
在分布式系统中,由于服务数量巨多,为了方便服务配置文件统一管理,实时更新,所以需要分布式配置中心组件。在Spring Cloud中,有分布式配置中心组件spring cloud config ,它支持配置服务放在配置服务的内存中(即本地),也支持放在远程Git仓库中。在spring cloud config 组件中,分两个角色,一是 config server,二是config client。
使用:
(1) 添加pom依赖
(2) 配置文件添加相关配置
(3) 启动类添加注解@EnableConfigServer
13.什么是Spring Cloud Gateway?
Spring Cloud Gateway是Spring Cloud官方推出的第二代网关框架,取代Zuul 网关。网关作为流量的,在微服务系统中有着非常作用,网关常见的功能有路由转发、权限校验、限流控制等作用。
使用了一个RouteLocatorBuilder的bean去创建路由,除了创建路由 RouteLocatorBuilder可以让你添加各种predicates和filters,predicates断言的意思,顾名思义就是根据具体的请求的规则,由具体的route去处理,filters 是各种过滤器,用来对请求做各种判断和修改。
14…Spring Cloud Hystrix
1.说一说什么是服务雪崩
服务雪崩:多个服务相互调用时,A调B,B调C,C调D等等更多调用,那么如果中间调用需要很长时间,然后再去调用A,那么占用的资源就越来越多,导致系统崩溃。
2.Hystrix断路器是什么
防止服务雪崩的一个工具,具有服务降级、服务熔断(@HystrixCommand(fallbackMethod = “hystrixById”) //失败了调用的方法)、服务隔离、监控等防止雪崩的技术。
3.什么是服务降级、服务熔断、服务隔离
服务降级: 当出现请求超时、资源不足时(线程或者信号量),会进行服务降级,就是去返回fallback方法的结果。
服务熔断: 当失败率(网络故障或者超时造成)达到阈值自动触发降级,是一种特殊的降级。
服务隔离: 为隔离的服务开启一个独立的线程,这样在高并发情况下,也不会影响该服务。一般使用线程池实现(还有信号量方式实现)。
4.服务降级和服务熔断的区别
区别: 降级每个请求都会发送过去,而熔断不一定,达到失败率,请求就不会再去发送了。请求出错时熔断返回的是fallback数据,而熔断则是一段时间不会去访问服务提供者。
比如:
①降级:A调B,发送10个请求,即使每个请求都超时,也会去请求B。
②熔断:A调B,发送10个请求,失败率设置为50%,如果5个请求失败,此时失败率到了50%,那么后面的5个请求就不会走到B。
15.Spring Cloud Alibaba Nacos
1.Nacos可以做什么?
注册中心和配置中心。
2.Eureka保证是AP,那么Nacos保证的是什么?默认是什么?
Nacos可以是AP也可以是CP。默认是AP
十四、分布式
点击查看详情
十五、计算机网络体系结构
1.网络协议是什么?
在计算机网络要做到有条不紊地交换数据,就必须遵守一些事先约定好的规则, 比如交换数据的格式、是否需要发送一个应答信息。这些规则被称为网络协议。
OSI 七层模型 是国际标准化组织提出的一个网络分层模型,其大体结构以及每一层提供的功能如下图所示:
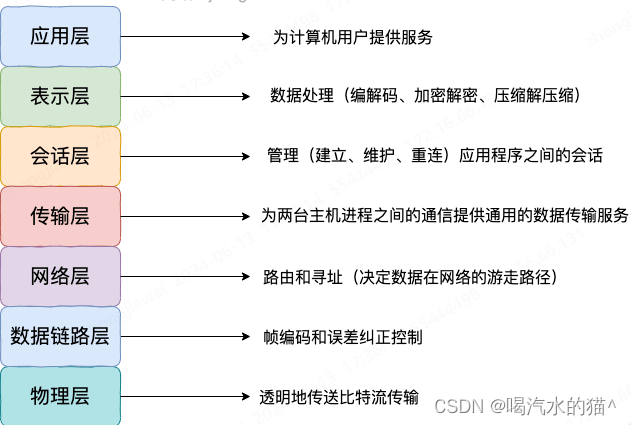
2.为什么要对网络协议分层?
- 简化问题难度和复杂度。由于各层之间独立,我们可以分割大问题为小问题。
- 灵活性好。当其中一层的技术变化时,只要层间接口关系保持不变,其他层不受 影响。
- 易于实现和维护。
- 促进标准化工作。分开后,每层功能可以相对简单地被描述。
网络协议分层的缺点: 功能可能出现在多个层里,产生了额外开销。 为了使不同体系结构的计算机网络都能互联,国际标准化组织 ISO 于1977年提 出了一个试图使各种计算机在世界范围内互联成网的标准框架,即著名的开放系统互联基本参考模型 OSI/RM,简称为OSI。
OSI 的七层协议体系结构的概念清楚,理论也较完整,但它既复杂又不实用, TCP/IP 体系结构则不同,但它现在却得到了非常广泛的应用。TCP/IP 是一个四 层体系结构,它包含应用层,运输层,网际层和网络接口层(用网际层这个名字 是强调这一层是为了解决不同网络的互连问题),不过从实质上讲,TCP/IP 只 有上面的三层,因为下面的网络接口层并没有什么具体内容,因此在学习计 算机网络的原理时往往采用折中的办法,即综合 OSI 和 TCP/IP 的优点,采用 一种只有五层协议的体系结构,这样既简洁又能将概念阐述清楚,有时为了方 便,也可把底下两层称为网络接口层。
- 四层协议,五层协议和七层协议的关系如下:
- TCP/IP是一个四层的体系结构,主要包括:应用层、运输层、网际层和网络接 口层。
- 五层协议的体系结构主要包括:应用层、运输层、网络层,数据链路层和物理层。
- OSI七层协议模型主要包括是:应用层(Application)、表示层 (Presentation)、会话层(Session)、运输层(Transport)、网络层 (Network)、数据链路层(Data Link)、物理层(Physical)。
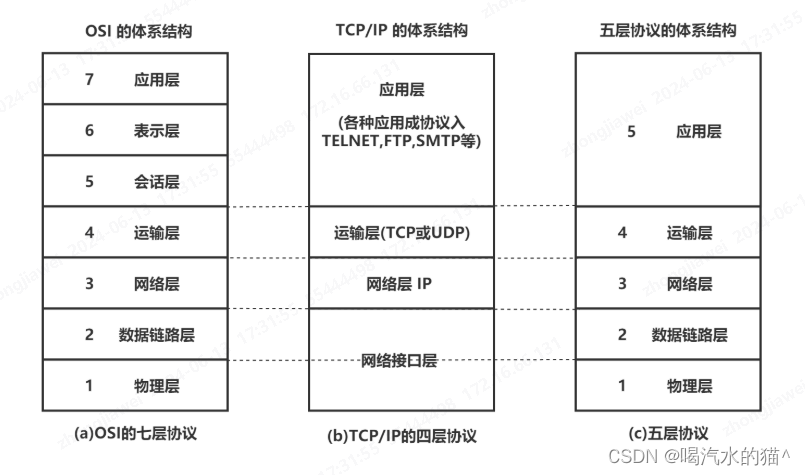
注:五层协议的体系结构只是为了介绍网络原理而设计的,实际应用还是 TCP/IP 四层体系结构。
3.应用层
应用层( application-layer )的任务是通过应用进程间的交互来完成特定网络应 用。应用层协议定义的是应用进程(进程:主机中正在运行的程序)间的通信和 交互的规则。
对于不同的网络应用需要不同的应用层协议。在互联网中应用层协议很多,如域 名系统 DNS,支持万维网应用的 HTTP 协议,支持电子邮件的 SMTP 协议等 等。
4.运输层
运输层(transport layer)的主要任务就是负责向两台主机进程之间的通信提供通 用的数据传输服务。应用进程利用该服务传送应用层报文。 运输层主要使用一下两种协议
- 传输控制协议-TCP:提供面向连接的,可靠的数据传输服务。
- 用户数据协议-UDP:提供无连接的,尽大努力的数据传输服务(不 保证数据传输的可靠性)。
| UDP | TCP | |
|---|---|---|
| 是否连接 | 无连接 | 面向连接 |
| 是否可靠 | 不可靠传 输,不使 用流量控 制和拥塞 控制 | 可靠传 输,使用 流量控制 和拥塞控 制 |
| 连接对象 个数 | 支持一对 一,一对 多,多对 一和多对 多交互通 信 | 只能是一 对一通信 |
| 传输方式 | 面向报文 | 面向字节 流 |
| 首部开销 | 首部开销 小,仅8字 节 | 首部小 20字节, 大60字 节 |
| 场景 | 适用于实 时应用 (IP电 话、视频会议、直 播等) | 适用于要 求可靠传 输的应 用,例如 文件传输 |
每一个应用层(TCP/IP参考模型的最高层)协议一般都会使用到两个传输层协 议之一:
运行在TCP协议上的协议:
- HTTP(Hypertext Transfer Protocol,超文本传输协议),主要用于普通浏 览。
- HTTPS(HTTP over SSL,安全超文本传输协议),HTTP协议的安全版本。
- FTP(File Transfer Protocol,文件传输协议),用于文件传输。
- POP3(Post Office Protocol, version 3,邮局协议),收邮件用。
- SMTP(Simple Mail Transfer Protocol,简单邮件传输协议),用来发送电子 邮件。
- TELNET(Teletype over the Network,网络电传),通过一个终端 (terminal)登陆到网络。
- SSH(Secure Shell,用于替代安全性差的TELNET),用于加密安全登陆用。 运行在UDP协议上的协议:
- BOOTP(Boot Protocol,启动协议),应用于无盘设备。
- NTP(Network Time Protocol,网络时间协议),用于网络同步。
- DHCP(Dynamic Host Configuration Protocol,动态主机配置协议),动态 配置IP地址。 运行在TCP和UDP协议上:
- DNS(Domain Name Service,域名服务),用于完成地址查找,邮件转发等 工作。
5.网络层
网络层的任务就是选择合适的网间路由和交换结点,确保计算机通信的数据及时 传送。在发送数据时,网络层把运输层产生的报文段或用户数据报封装成分组和 包进行传送。在 TCP/IP 体系结构中,由于网络层使用 IP 协议,因此分组也叫 IP 数据报 ,简称数据报。
互联网是由大量的异构(heterogeneous)网络通过路由器(router)相互连 接起来的。互联网使用的网络层协议是无连接的网际协议(Intert Prococol) 和许多路由选择协议,因此互联网的网络层也叫做网际层或 IP 层。
6.数据链路层
数据链路层(data link layer)通常简称为链路层。两台主机之间的数据传输,总 是在一段一段的链路上传送的,这就需要使用专门的链路层的协议。
在两个相邻节点之间传送数据时,数据链路层将网络层交下来的 IP 数据报组装 成帧,在两个相邻节点间的链路上传送帧。每一帧包括数据和必要的控制信息 (如同步信息,地址信息,差错控制等)。
在接收数据时,控制信息使接收端能够知道一个帧从哪个比特开始和到哪个比特 结束。
发送端在层与层之间传输数据时,每经过一层时会被打上一个该层所属的首部信 息。反之,接收端在层与层之间传输数据时,每经过一层时会把对应的首部信息 去除。
7.物理层
在物理层上所传送的数据单位是比特。 物理层(physical layer)的作用是实现相 邻计算机节点之间比特流的透明传送,尽可能屏蔽掉具体传输介质和物理设备的 差异。使其上面的数据链路层不必考虑网络的具体传输介质是什么。“透明传送 比特流”表示经实际电路传送后的比特流没有发生变化,对传送的比特流来说, 这个电路好像是看不见的。
8.TCP/IP 协议族
在互联网使用的各种协议中重要和著名的就是 TCP/IP 两个协议。现在人们 经常提到的 TCP/IP 并不一定是单指 TCP 和 IP 这两个具体的协议,而往往是表 示互联网所使用的整个 TCP/IP 协议族。
互联网协议套件(英语:Internet Protocol Suite,缩写IPS)是一个网络通讯模型, 以及一整个网络传输协议家族,为网际网络的基础通讯架构。它常被通称为TCP/IP协 议族(英语:TCP/IP Protocol Suite,或TCP/IP Protocols),简称TCP/IP。因为该 协定家族的两个核心协定:TCP(传输控制协议)和IP(网际协议),为该家族中早 通过的标准。
划重点: TCP(传输控制协议)和IP(网际协议) 是先定义的两个核心协议,所以才统称为TCP/IP协议族
9.三次握手
三次握手的本质是确认通信双方收发数据的能力首先,我让信使运输一份信件给对方,对方收到了,那么他就知道了我的发件能力和他的收件能力是可以的。
于是他给我回信,我若收到了,我便知我的发件能力和他的收件能力是可以的,并且他的发件能力和我的收件能力是可以。
然而此时他还不知道他的发件能力和我的收件能力到底可不可以,于是我 后回馈一次,他若收到了,他便清楚了他的发件能力和我的收件能力是可以的。这,就是三次握手,这样说,你理解了吗?
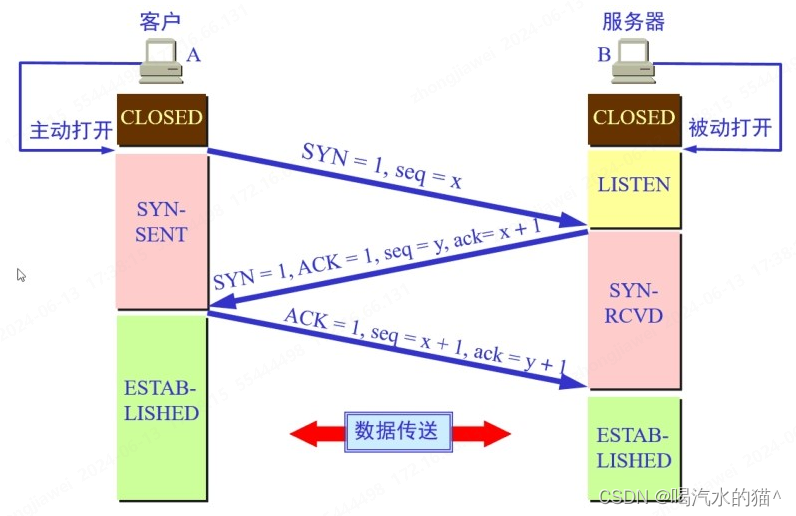
- 第一次握手:客户端要向服务端发起连接请求,首先客户端随机生成一个起始序列号ISN(比如是100),那客户端向服务端发送的报文段包含SYN标志位(也就是SYN=1),序列号seq=100。
- 第二次握手:服务端收到客户端发过来的报文后,发现SYN=1,知道这是一个连接请求,于是将客户端的起始序列号100存起来,并且随机生成一个服务端的起始序列号(比如是300)。然后给客户端回复一段报文,回复报文包含SYN和ACK标志(也就是SYN=1,ACK=1)、序列号seq=300、确认号ack=101(客户端发过来的序列号+1)。
- 第三次握手:客户端收到服务端的回复后发现ACK=1并且ack=101,于是知道服务端已经收到了序列号为100的那段报文;同时发现SYN=1,知道了服务端同意了这次连接,于是就将服务端的序列号300给存下来。然后客户端再回复一段报文给服务端,报文包含ACK标志位(ACK=1)、ack=301(服务端序列号+1)、seq=101(第一次握手时发送报文是占据一个序列号的,所以这次seq就从101开始,需要注意的是不携带数据的ACK报文是不占据序列号的,所以后面第一次正式发送数据时seq还是101)。当服务端收到报文后发现ACK=1并且ack=301,就知道客户端收到序列号为300的报文了,就这样客户端和服务端通过TCP建立了连接。
10.四次挥手
四次挥手的目的是关闭一个连接
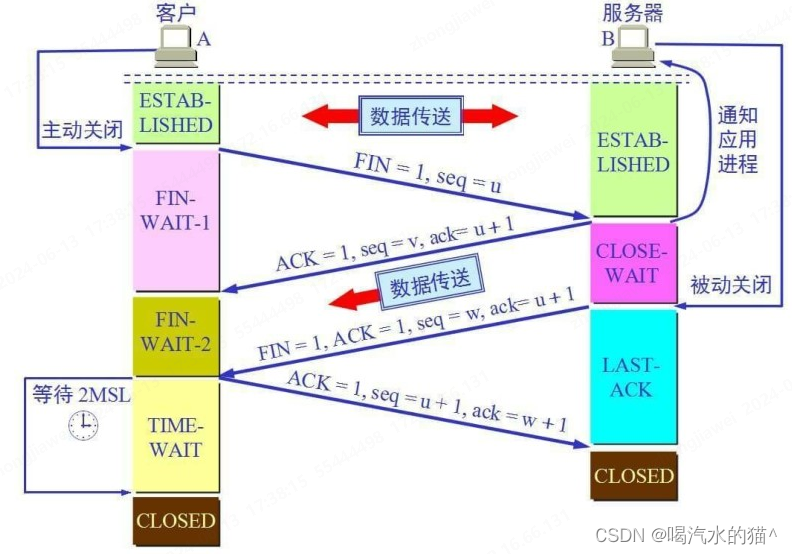
比如客户端初始化的序列号ISA=100,服务端初始化的序列号ISA=300。TCP连接成功后客户端总共发送了1000个字节的数据,服务端在客户端发FIN报文前总共回复了2000个字节的数据。
- 第一次挥手:当客户端的数据都传输完成后,客户端向服务端发出连接释放报文(当然数据没发完时也可以发送连接释放报文并停止发送数据),释放连接报文包含FIN标志位(FIN=1)、序列号seq=1101(100+1+1000,其中的1是建立连接时占的一个序列号)。需要注意的是客户端发出FIN报文段后只是不能发数据了,但是还可以正常收数据;另外FIN报文段即使不携带数据也要占据一个序列号。
- 第二次挥手:服务端收到客户端发的FIN报文后给客户端回复确认报文,确认报文包含ACK标志位(ACK=1)、确认号ack=1102(客户端FIN报文序列号1101+1)、序列号seq=2300(300+2000)。此时服务端处于关闭等待状态,而不是立马给客户端发FIN报文,这个状态还要持续一段时间,因为服务端可能还有数据没发完。
- 第三次挥手:服务端将最后数据(比如50个字节)发送完毕后就向客户端发出连接释放报文,报文包含FIN和ACK标志位(FIN=1,ACK=1)、确认号和第二次挥手一样ack=1102、序列号seq=2350(2300+50)。
- 第四次挥手:客户端收到服务端发的FIN报文后,向服务端发出确认报文,确认报文包含ACK标志位(ACK=1)、确认号ack=2351、序列号seq=1102。注意客户端发出确认报文后不是立马释放TCP连接,而是要经过2MSL(最长报文段寿命的2倍时长)后才释放TCP连接。而服务端一旦收到客户端发出的确认报文就会立马释放TCP连接,所以服务端结束TCP连接的时间要比客户端早一些。
11.为什么TCP连接的时候是3次?2次不可以吗?
因为需要考虑连接时丢包的问题,如果只握手2次,第二次握手时如果服务端发给客户端的确认报文段丢失,此时服务端已经准备好了收发数(可以理解服务端已经连接成功)据,而客户端一直没收到服务端的确认报文,所以客户端就不知道服务端是否已经准备好了(可以理解为客户端未连接成功),这种情况下客户端不会给服务端发数据,也会忽略服务端发过来的数据。
如果是三次握手,即便发生丢包也不会有问题,比如如果第三次握手客户端发的确认ack报文丢失,服务端在一段时间内没有收到确认ack报文的话就会重新进
行第二次握手,也就是服务端会重发SYN报文段,客户端收到重发的报文段后会再次给服务端发送确认ack报文。
12.为什么TCP连接的时候是3次,关闭的时候却是4次?
因为只有在客户端和服务端都没有数据要发送的时候才能断开TCP。而客户端发出FIN报文时只能保证客户端没有数据发了,服务端还有没有数据发客户端是不知道的。而服务端收到客户端的FIN报文后只能先回复客户端一个确认报文来告诉客户端我服务端已经收到你的FIN报文了,但我服务端还有一些数据没发完,等这些数据发完了服务端才能给客户端发FIN报文(所以不能一次性将确认报文和FIN报文发给客户端,就是这里多出来了一次)。
13.为什么客户端发出第四次挥手的确认报文后要等2MSL的时间才能释放TCP连接?
这里同样是要考虑丢包的问题,如果第四次挥手的报文丢失,服务端没收到确认 ack报文就会重发第三次挥手的报文,这样报文一去一回 长时间就是2MSL,所以需要等这么长时间来确认服务端确实已经收到了。
14.如果已经建立了连接,但是客户端突然出现故障了怎么办?
TCP设有一个保活计时器,客户端如果出现故障,服务器不能一直等下去,白白浪费资源。服务器每收到一次客户端的请求后都会重新复位这个计时器,时间通常是设置为2小时,若两小时还没有收到客户端的任何数据,服务器就会发送一个探测报文段,以后每隔75秒钟发送一次。若一连发送10个探测报文仍然没反应,服务器就认为客户端出了故障,接着就关闭连接。
什么是HTTP,HTTP 与 HTTPS 的区别
HTTP 是一个在计算机世界里专门在两点之间传输文字、图片、音频、视频等超文本数据的约定和规范
| 区别 | HTTP | HTTPS |
|---|---|---|
| 协议 | 运行在 TCP 之上,明文传输,客户端与服务器端都无法验证对方的身份 | 身披 SSL( Secure Socket Layer )外壳的 HTTP,运行于 SSL 上,SSL 运行于 TCP 之 上, 是添加了加密和认证机制的 HTTP。 |
| 端口 | 80 | 443 |
| 资源消耗 | 较少 | 由于加解密处理,会消耗更 多的 CPU 和内存资源 |
| 开销 | 无需证书 | 需要证书,而证书一般需要向认证机构购买 |
| 加密机制 | 无 | 共享密钥加密和公开密钥加密并用的混合加密机制 |
| 安全性 | 弱 | 由于加密机制,安全性强 |
15.常用HTTP状态码
HTTP状态码表示客户端HTTP请求的返回结果、标识服务器处理是否正常、表明请求出现的错误等。
状态码的类别:
| 类别 | 原因短语 |
|---|---|
| 1XX | Informational(信息性状态码)接受的请求正在处理 |
| 2XX | Success(成功状态码)请求正常处理完毕 |
| 3XX | Redirection(重定向状态码)需要进行附加操作以完成请求 |
| 4XX | Client Error(客户端错误状态码)服务器无法处理请求 |
| 5XX | Server Error(服务器错误状态码)服务器处理请求出错 |
常用HTTP状态码:
| 2XX | 成功(这系列表明请求被正常处理了) |
|---|---|
| 200 | OK,表示从客户端发来的请求在服务器端被正确处理 |
| 204 | No content,表示请求成功,但响应报文不含实体的主体部分 |
| 206 | Partial Content ,进行范围请求成功 |
| 3XX | 重定向 (表明浏览器要执行特殊处理) |
| 301 | moved permanently,永久 性重定向,表示资源已被分配了新的 URL |
| 302 | found,临时性重定向,表示资源临时被分配了新的 URL |
| 303 | see other,表示资源存在着另一个 URL, 应使用 GET 方法获取资源 (对于 301/302/ 303响应,几乎所有浏览器都会删除报文主体并 自动用 GET重新请求) |
| 304 | not modified ,表示服务器允许访问资源,但请求未满足条件的情况(与重定向无关) |
| 307 | temporary redirect,临时重定 向,和302 含义类似,但是期望客户端保持请求方法不变向新的地址发出请求 |
| 4XX | 客户端错误 |
| 400 | bad request,请求报文存在语法错误 |
| 401 | unauthorized,表示发送的请求需要有通过 HTTP 认证的认证信息 |
| 403 | forbidden ,表示对请求资源的访问被服务器拒绝,可在实体主体部分返回原因描述 |
| 404 | not found,表示在服务器上没有找到请求的资源 |
| 5XX | 服务器错误 |
| 500 | internal sever error,表 示服务器端在执行请求时发生了错误 |
| 501 | Not Implemented,表示服务器不支持当前请求所需要的某个功能 |
| 503 | service unavailable,表明服务器暂时处于超负载或正在停机维护,无法处理请求 |
16.什么是对称加密与非对称加密
对称密钥加密是指加密和解密使用同一个密钥的方式,这种方式存在的最大问题就是密钥发送问题,即如何安全地将密钥发给对方;
而非对称加密是指使用一对非对称密钥,即公钥和私钥,公钥可以随意发布,但私钥只有自己知道。发送密文的一方使用对方的公钥进行加密处理,对方接收到加密信息后,使用自己的私钥进行解密。
17.Session、Cookie和Token的主要区别
HTTP协议本身是无状态的。什么是无状态呢,即服务器无法判断用户身份。
什么是cookie
cookie是由Web服务器保存在用户浏览器上的小文件(key-value格式),包含用户相关的信息。客户端向服务器发起请求,如果服务器需要记录该用户状态,就使用response向客户端浏览器颁发一个Cookie。客户端浏览器会把Cookie保存起来。当浏览器再请求该网站时,浏览器把请求的网址连同该Cookie一同提交给服务器。服务器检查该Cookie,以此来辨认用户身份。
什么是session
session是依赖Cookie实现的。session是服务器端对象。
session 是浏览器和服务器会话过程中,服务器分配的一块储存空间。服务器默认为浏览器在cookie中设置 sessionid,浏览器在向服务器请求过程中传输 cookie 包含 sessionid ,服务器根据 sessionid 获取出会话中存储的信息,然后确定会话的身份信息。
cookie与session区别
存储位置与安全性:cookie数据存放在客户端上,安全性较差,session数据放在服务器上,安全性相对更高;
存储空间:单个cookie保存的数据不能超过4K,很多浏览器都限制一个站点多保存20个cookie,session无此限制
占用服务器资源:session一定时间内保存在服务器上,当访问增多,占用服务器性能,考虑到服务器性能方面,应当使用cookie。
什么是Token
Token的引入:Token是在客户端频繁向服务端请求数据,服务端频繁的去数据库查询用户名和密码并进行对比,判断用户名和密码正确与否,并作出相应提示,在这样的背景下,Token便应运而生。
Token的定义:Token是服务端生成的一串字符串,以作客户端进行请求的一个令牌,当第一次登录后,服务器生成一个Token便将此Token返回给客户端,以后客户端只需带上这个Token前来请求数据即可,无需再次带上用户名和密码。使用Token的目的:Token的目的是为了减轻服务器的压力,减少频繁的查询数据库,使服务器更加健壮。
Token 是在服务端产生的。如果前端使用用户名/密码向服务端请求认证,服务端认证成功,那么在服务端会返回 Token 给前端。前端可以在每次请求的时候带上 Token 证明自己的合法地位
session与token区别
- session机制存在服务器压力增大,CSRF跨站伪造请求攻击,扩展性不强等问题;
- session存储在服务器端,token存储在客户端
- token提供认证和授权功能,作为身份认证,token安全性比session好;
- session这种会话存储方式方式只适用于客户端代码和服务端代码运行在同一台服务器上,token适用于项目级的前后端分离(前后端代码运行在不同的服务器下)
十六、二十三种设计模式
1. 单例模式:确保某一个类只有一个实例,而且自行实例化并向整个系统提供这 个实例。
(1)懒汉式 public class Singleton { /* 持有私有静态实例,防止被引用,此处赋值为null,目的是实现延迟加载 */ private static Singleton instance = null; /* 私有构造方法,防止被实例化 */ private Singleton() { } /* 1:懒汉式,静态工程方法,创建实例 */ public static Singleton getInstance() { if (instance == null) { instance = new Singleton(); } return instance; } } (2)饿汉式 public class Singleton { /* 持有私有静态实例,防止被引用 */ private static Singleton instance = new Singleton(); /* 私有构造方法,防止被实例化 */ private Singleton() { } /* 1:懒汉式,静态工程方法,创建实例 */ public static Singleton getInstance() { return instance; } }
使用场景:
- 要求生成唯一序列号的环境;
- 在整个项目中需要一个共享访问点或共享数据,例如一个Web页面上的计数 器,可以不用把每次刷新都记录到数据库中,使用单例模式保持计数器的值,并 确保是线程安全的;
- 创建一个对象需要消耗的资源过多,如要访问IO和数据库等资源;
- 需要定义大量的静态常量和静态方法(如工具类)的环境,可以采用单例模式 (当然,也可以直接声明为static的方式)。
2. 工厂模式:定义一个用于创建对象的接口,让子类决定实例化哪一个类。工厂 方法使一个类的实例化延迟到其子类。
接口public interface Fruit {
public void print(); }
2个实现类
public class Apple implements Fruit{ @Override public void print() { System.out.println("我是一个苹果"); }
}
public class Orange implements Fruit{ @Override public void print() { System.out.println("我是一个橘子"); }
} 工厂类public class FruitFactory { public Fruit produce(String type){ if(type.equals("apple")){ return new Apple(); }else if(type.equals("orange")){ return new Orange(); }else{ System.out.println("请输入正确的类型!"); return null; } }
}
使用场景:jdbc连接数据库,硬件访问,降低对象的产生和销毁
3. 抽象工厂模式:为创建一组相关或相互依赖的对象提供一个接口,而且无须指 定它们的具体类。
相对于工厂模式,我们可以新增产品类(只需要实现产品接口),只需要同时新 增一个工厂类,客户端就可以轻松调用新产品的代码。
interface food{}
class A implements food{}
class B implements food{}
interface produce{ food get();}
class FactoryForA implements produce{ @Override public food get() { return new A(); }
}
class FactoryForB implements produce{ @Override public food get() { return new B(); }
}
public class AbstractFactory { public void ClientCode(String name){ food x= new FactoryForA().get(); x = new FactoryForB().get(); }
}
使用场景:一个对象族(或是一组没有任何关系的对象)都有相同的约束。 涉及不同操作系统的时候,都可以考虑使用抽象工厂模式
4.建造者模式:将一个复杂对象的构建与它的表示分离,使得同样的构建过程可 以创建不同的表示。
public class Build { static class Student{ String name = null ; int number = -1 ; String sex = null ; public Student(Builder builder) { this.name=builder.name; this.number=builder.number; this.sex=builder.sex; } static class Builder{String name = null ; int number = -1 ; String sex = null ; public Builder setName(String name){ this.name=name; return this; } public Builder setNumber(int number){ this.number=number; return this; } public Builder setSex(String sex){ this.sex=sex; return this; } public Student build(){ return new Student(this); }}
}
public static void main(String[] args) {
Student A=new Student.Builder().setName("张 三").setNumber(1).build(); Student B=new Student.Builder().setSex("男").setName("李四").build(); System.out.println(A.name+" "+A.number+" "+A.sex); System.out.println(B.name+" "+B.number+" "+B.sex); }
}
使用场景:
- 相同的方法,不同的执行顺序,产生不同的事件结果时,可以采用建造者模 式。
- 多个部件或零件,都可以装配到一个对象中,但是产生的运行结果又不相同 时,则可以使用该模式。
- 产品类非常复杂,或者产品类中的调用顺序不同产生了不同的效能,这个时候 使用建造者模式非常合适。
5. 原型模式:用原型实例指定创建对象的种类,并且通过拷贝这些原型创建新的 对象。
public class Prototype implements Cloneable{ private String name; public String getName() { return name; } public void setName(String name) { this.name = name; } @Override protected Object clone() { try { return super.clone(); } catch (CloneNotSupportedException e) { e.printStackTrace(); }finally { return null; } } public static void main ( String[] args){ Prototype pro = new Prototype(); Prototype pro1 = (Prototype)pro.clone(); }
}
原型模式实际上就是实现Cloneable接口,重写clone()方法。
使用原型模式的优点:
1.性能优良
原型模式是在内存二进制流的拷贝,要比直接new一个对象性能好很多,特别是 要在一个循环体内产生大量的对象时,原型模式可以更好地体现其优点。
2.逃避构造函数的约束
这既是它的优点也是缺点,直接在内存中拷贝,构造函数是不会执行的(参见 13.4节)。
使用场景:
资源优化场景 类初始化需要消化非常多的资源,这个资源包括数据、硬件资源等。
性能和安全要求的场景 通过new产生一个对象需要非常繁琐的数据准备或访问权限,则可以使用原型模 式。
一个对象多个修改者的场景 一个对象需要提供给其他对象访问,而且各个调用者可能都需要修改其值时,可 以考虑使用原型模式拷贝多个对象供调用者使用。
浅拷贝和深拷贝:
浅拷贝:Object类提供的方法clone只是拷贝本对象,其对象内部的数组、引用 对象等都不拷贝,还是指向原生对象的内部元素地址,这种拷贝就叫做浅拷贝, 其他的原始类型比如int、long、char、string(当做是原始类型)等都会被拷 贝。
注意: 使用原型模式时,引用的成员变量必须满足两个条件才不会被拷贝:一 是类的成员变量,而不是方法内变量;二是必须是一个可变的引用对象,而不是 一个原始类型或不可变对象。
深拷贝:对私有的类变量进行独立的拷贝
如:this.arrayList = (ArrayList)this.arrayList.clone();
6. 适配器模式:将一个类的接口变换成客户端所期待的另一种接口,从而使原本 因接口不匹配而无法在一起工作的两个类能够在一起工作。
主要可分为3种:
- 类适配:创建新类,继承源类,并实现新接口,例如 class adapter extends oldClass implements newFunc{}
- 对象适配:创建新类持源类的实例,并实现新接口,例如 class adapter implements newFunc { private oldClass oldInstance ;}
- 接口适配:创建新的抽象类实现旧接口方法。例如 abstract class adapter implements oldClassFunc { void newFunc();}
使用场景:
你有动机修改一个已经投产中的接口时,适配器模式可能是适合你的模式。比 如系统扩展了,需要使用一个已有或新建立的类,但这个类又不符合系统的接 口,怎么办?使用适配器模式,这也是我们例子中提到的。
7. 装饰器模式:动态地给一个对象添加一些额外的职责。就增加功能来说,装饰 器模式相比生成子类更为灵活 。
interface Source{ void method();}
public class Decorator implements Source{ private Source source ; public void decotate1(){ System.out.println("decorate"); } @Override public void method() { decotate1(); source.method(); }
}
使用场景:
- 需要扩展一个类的功能,或给一个类增加附加功能。
- 需要动态地给一个对象增加功能,这些功能可以再动态地撤销。
- 需要为一批的兄弟类进行改装或加装功能,当然是首选装饰模式。
8. 代理模式:为其他对象提供一种代理以控制对这个对象的访问。
interface Source{ void method();}
class OldClass implements Source{ @Override public void method() { }
}
class Proxy implements Source{ private Source source = new OldClass(); void doSomething(){} @Override public void method() { new Class1().Func1(); source.method(); new Class2().Func2(); doSomething(); }
}
9. 中介者模式:用一个中介对象封装一系列的对象交互,中介者使各对象不需要 显示地相互作用,从而使其耦合松散,而且可以独立地改变它们之间的交互。
public abstract class Mediator { //定义同事类 protected ConcreteColleague1 c1; protected ConcreteColleague2 c2; //通过getter/setter方法把同事类注入进来 public ConcreteColleague1 getC1() { return c1; }public void setC1(ConcreteColleague1 c1) { this.c1 = c1; } public ConcreteColleague2 getC2() { return c2; } public void setC2(ConcreteColleague2 c2) { this.c2 = c2; } //中介者模式的业务逻辑 public abstract void doSomething1(); public abstract void doSomething2();
}
使用场景: 中介者模式适用于多个对象之间紧密耦合的情况,紧密耦合的标准是:在类图中 出现了蜘蛛网状结构,即每个类都与其他的类有直接的联系。
10. 命令模式:将一个请求封装成一个对象,从而让你使用不同的请求把客户端 参数化,对请求排队或者记录请求日志,可以提供命令的撤销和恢复功能。
Receiver接受者角色:该角色就是干活的角色,命令传递到这里是应该被执行的
Command命令角色:需要执行的所有命令都在这里声明
Invoker调用者角色:接收到命令,并执行命令
//通用Receiver类
public abstract class Receiver { public abstract void doSomething();
}
//具体Receiver类
public class ConcreteReciver1 extends Receiver{ //每个接收者都必须处理一定的业务逻辑 public void doSomething(){ }
}
public class ConcreteReciver2 extends Receiver{ //每个接收者都必须处理一定的业务逻辑 public void doSomething(){ }
}
//抽象Command类 public abstract class Command { public abstract void execute();
}
//具体的Command类
public class ConcreteCommand1 extends Command { //对哪个Receiver类进行命令处理 private Receiver receiver; //构造函数传递接收者 public ConcreteCommand1(Receiver _receiver){ this.receiver = _receiver; } //必须实现一个命令 public void execute() { //业务处理 this.receiver.doSomething(); }
}
public class ConcreteCommand2 extends Command { //哪个Receiver类进行命令处理 private Receiver receiver; //构造函数传递接收者public ConcreteCommand2(Receiver _receiver){ this.receiver = _receiver;
}
//必须实现一个命令 public void execute() { //业务处理 this.receiver.doSomething(); } } //调用者Invoker类 public class Invoker { private Command command;public void setCommand(Command _command){ this.command = _command; }
public void action() { this.command.execute(); }
} //场景类
public class Client { public static void main(String[] args){ Invoker invoker = new Invoker(); Receiver receiver = new ConcreteReceiver1();Command command = new ConcreteCommand1(receiver); invoker.setCommand(command); invoker.action(); }
}
使用场景: 认为是命令的地方就可以采用命令模式,例如,在GUI开发中,一个按钮的点击 是一个命令,可以采用命令模式;模拟DOS命令的时候,当然也要采用命令模
式;触发-反馈机制的处理等。
11.责任链模式:使多个对象都有机会处理请求,从而避免了请求的发送者和接受者之间的耦合关系。将这些对象连成一条链,并沿着这条链传递该请求,直到有对象处理它为止。
public abstract class Handler {private Handler nextHandler;//每个处理者都必须对请求做出处理public final Response handleMessage(Request request){Response response = null; //判断是否是自己的处理级别if(this.getHandlerLevel().equals(request.getRequestLevel())){response = this.echo(request);}else{ //不属于自己的处理级别//判断是否有下一个处理者if(this.nextHandler != null){response = this.nextHandler.handleMessage(request);}else{//没有适当的处理者,业务自行处理}}return response;}//设置下一个处理者是谁public void setNext(Handler _handler){this.nextHandler = _handler;}//每个处理者都有一个处理级别protected abstract Level getHandlerLevel();//每个处理者都必须实现处理任务protected abstract Response echo(Request request);
}12.策略模式:定义一组算法,将每个算法都封装起来,并且使它们之间可以互换。
使用场景:
-
多个类只有在算法或行为上稍有不同的场景。
-
算法需要自由切换的场景。
-
需要屏蔽算法规则的场景。
13.迭代器模式:它提供一种方法访问一个容器对象中各个元素,而又不需暴露该对象的内部细节。
迭代器模式已经被淘汰,java中已经把迭代器运用到各个聚集类(collection)中了,使用java自带的迭代器就已经满足我们的需求了。
14.组合模式:将对象组合成树形结构以表示“部分-整体”的层次结构,使得用户对单个对象和组合对象的使用具有一致性。
public class Composite extends Component {//构件容器private ArrayList componentArrayList = new ArrayList();//增加一个叶子构件或树枝构件public void add(Component component){this.componentArrayList.add(component);}//删除一个叶子构件或树枝构件public void remove(Component component){
this.componentArrayList.remove(component);}//获得分支下的所有叶子构件和树枝构件public ArrayList getChildren(){return this.componentArrayList;}
}
使用场景:
-
维护和展示部分-整体关系的场景,如树形菜单、文件和文件夹管理。
-
从一个整体中能够独立出部分模块或功能的场景。
15.观察者模式:定义对象间一种一对多的依赖关系,使得每当一个对象改变状态,则所有依赖于它的对象都会得到通知并被自动更新。
public abstract class Subject {//定义一个观察者数组private Vector obsVector = new Vector();//增加一个观察者public void addObserver(Observer o){this.obsVector.add(o);}//删除一个观察者public void delObserver(Observer o){this.obsVector.remove(o);}//通知所有观察者public void notifyObservers(){for(Observer o:this.obsVector){o.update();
}}
}
使用场景:
-
关联行为场景。需要注意的是,关联行为是可拆分的,而不是“组合”关系。
-
事件多级触发场景。
-
跨系统的消息交换场景,如消息队列的处理机制
16.门面模式:要求一个子系统的外部与其内部的通信必须通过一个统一的对象进行。门面模式提供一个高层次的接口,使得子系统更易于使用。
public class Facade {private subSystem1 subSystem1 = new subSystem1();private subSystem2 subSystem2 = new subSystem2();private subSystem3 subSystem3 = new subSystem3();public void startSystem(){subSystem1.start();subSystem2.start(); subSystem3.start();}public void stopSystem(){subSystem1.stop();subSystem2.stop(); subSystem3.stop();}
}
使用场景:
-
为一个复杂的模块或子系统提供一个供外界访问的接口
-
子系统相对独立——外界对子系统的访问只要黑箱操作即可
-
预防低水平人员带来的风险扩散
17.备忘录模式:在不破坏封装性的前提下,捕获一个对象的内部状态,并在该对象之外保存这个状态。这样以后就可将该对象恢复到原先保存的状态。
public class Originator {private String state;/**
* 工厂方法,返回一个新的备忘录对象*/public Memento createMemento(){return new Memento(state);}/**
* 将发起人恢复到备忘录对象所记载的状态*/public void restoreMemento(Memento memento){this.state = memento.getState();}public String getState() {return state;}public void setState(String state) {this.state = state;System.out.println("当前状态:" + this.state);}
}
使用场景:
-
需要保存和恢复数据的相关状态场景。
-
提供一个可回滚(rollback)的操作。
-
需要监控的副本场景中。
-
数据库连接的事务管理就是用的备忘录模式。
18.访问者模式:封装一些作用于某种数据结构中的各元素的操作,它可以在不改变数据结构的前提下定义作用于这些元素的新的操作。
使用场景:
-
一个对象结构包含很多类对象,它们有不同的接口,而你想对这些对象实施一些依赖于其具体类的操作,也就说是用迭代器模式已经不能胜任的情景。
-
需要对一个对象结构中的对象进行很多不同并且不相关的操作,而你想避免让这些操作“污染”这些对象的类。
19.状态模式:当一个对象内在状态改变时允许其改变行为,这个对象看起来像改变了其类。
使用场景:
-
行为随状态改变而改变的场景这也是状态模式的根本出发点,例如权限设计,人员的状态不同即使执行相同的行为结果也会不同,在这种情况下需要考虑使用状态模式。
-
条件、分支判断语句的替代者
20.解释器模式:给定一门语言,定义它的文法的一种表示,并定义一个解释器,该解释器使用该表示来解释语言中的句子。
使用场景:
-
重复发生的问题可以使用解释器模式
-
一个简单语法需要解释的场景
21.享元模式:使用共享对象的方法,用来尽可能减少内存使用量以及分享资讯。
abstract class flywei{ }
public class Flyweight extends flywei{Object obj ;public Flyweight(Object obj){this.obj = obj;}
}
class FlyweightFactory{ private HashMap data;public FlyweightFactory(){ data = new HashMap<>();}public Flyweight getFlyweight(Object object){if ( data.containsKey(object)){return data.get(object);}else {Flyweight flyweight = new Flyweight(object);data.put(object,flyweight);return flyweight;}}
}
使用场景:
-
系统中存在大量的相似对象。
-
细粒度的对象都具备较接近的外部状态,而且内部状态与环境无关,也就是说对象没有特定身份。
-
需要缓冲池的场景。
22.桥梁模式:将抽象和实现解耦,使得两者可以独立地变化。
Circle类将DrwaApi与Shape类进行了桥接,
interface DrawAPI {public void drawCircle(int radius, int x, int y);
}
class RedCircle implements DrawAPI {@Overridepublic void drawCircle(int radius, int x, int y) {System.out.println("Drawing Circle[ color: red, radius: "+ radius +", x: " +x+", "+ y +"]");}
}
class GreenCircle implements DrawAPI {@Overridepublic void drawCircle(int radius, int x, int y) {System.out.println("Drawing Circle[ color: green, radius: "+ radius +", x: " +x+", "+ y +"]");}
}
abstract class Shape {protected DrawAPI drawAPI;protected Shape(DrawAPI drawAPI){this.drawAPI = drawAPI;}public abstract void draw();
}
class Circle extends Shape {private int x, y, radius;public Circle(int x, int y, int radius, DrawAPI drawAPI) {super(drawAPI);this.x = x;this.y = y;this.radius = radius;}public void draw() {drawAPI.drawCircle(radius,x,y);}
}
//客户端使用代码
Shape redCircle = new Circle(100,100, 10, new RedCircle()); Shape greenCircle = new Circle(100,100, 10, new GreenCircle()); redCircle.draw(); greenCircle.draw();
使用场景:
-
不希望或不适用使用继承的场景
-
接口或抽象类不稳定的场景
-
重用性要求较高的场景
23.模板方法模式:定义一个操作中的算法的框架,而将一些步骤延迟到子类中。使得子类可以不改变一个算法的结构即可重定义该算法的某些特定步骤。
使用场景:
-
多个子类有公有的方法,并且逻辑基本相同时。
-
重要、复杂的算法,可以把核心算法设计为模板方法,周边的相关细节功能则由各个子类实现。
-
重构时,模板方法模式是一个经常使用的模式,把相同的代码抽取到父类中,然后通过钩子函数(见“模板方法模式的扩展”)约束其行为。
这篇关于Java最新面试题(全网最全、最细、附答案)的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





