本文主要是介绍【2024最新精简版】Redis面试篇,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!

文章目录
- 什么是红锁
- Redis有哪些框架?
- 你们项目中哪里用到了Redis ?
- Redis的常用数据类型有哪些 ?
- Redis的数据持久化策略有哪些 ?
- Redis的数据过期策略有哪些 ?
- Redis的数据淘汰策略有哪些 ?
- 你们使用Redis是单点还是集群 ? 哪种集群 ?
- Redis集群有哪些方案, 知道嘛 ?
- 什么是 Redis 主从同步?
- Redis分片集群中数据是怎么存储和读取的 ?
- 你们用过Redis的事务吗 ? 事务的命令有哪些 ?
- Redis的内存用完了会发生什么?
- Redis和Mysql如何保证数据⼀致?
- Redis 的延迟双删策略:
- MySQL 的延迟双删策略:
- 什么是缓存穿透 ? 怎么解决 ?
- 什么是缓存击穿 ? 怎么解决 ?
- 什么是缓存雪崩 ? 怎么解决
- 数据库有1000万数据 ,Redis只能缓存20w数据, 如何保证Redis中的数据都是热点数据 ?
- Redis分布式锁如何实现 ?
- 你的项目中哪里用到了分布式锁
- redis如何实现一个排行榜的功能
- Redis设置过期时间代码示例
更多相关内容可查看
什么是红锁
是refis分布式锁的一种算法,选择多个独立的redis实例,生成一个唯一的锁标识通过redis的setnx命令来获取锁,获取锁之后需要发送续约请求,来延长锁的过期时间,如果不需要锁的时候,向所有持锁的redis实例发送释放锁的请求,释放锁资源,避免单点故障导致锁不可用的问题
Redis有哪些框架?
- Jedis: Java,它支持连接池、分布式、哈希、列表等 Redis 数据结构的操作。
- Lettuce: Java ,Lettuce 支持基于响应式编程模型。
- StackExchange.Redis: C# ,提供了异步操作、连接复用、分区等功能
- redis-py:redis-py,支持连接池、发布订阅、事务等功能。
- ioredis: Node.js,支持异步操作、连接池、管道等特性。
- lettuce-core:l Kotlin/Java 客户端库,支持响应式流 API。
- Redisson:Java ,提供了分布式、面向对象的 API,封装了分布式锁、分布式集合等功能
- Spring Data Redis:Spring Framework 提供的 Redis 抽象框架支持声明式事务、RedisTemplate、注解驱动
- Django-Redis:Django 框架的 Redis 客户端库,提供了对 Redis 数据库的简单、高效的操作接口,可用于缓存、会话存储等场景。
你们项目中哪里用到了Redis ?
在我们的项目中很多地方都用到了Redis , Redis在我们的项目中主要有三个作用 :
- 使用Redis做热点数据缓存/接口数据缓存
- 使用Redis存储一些业务数据 , 例如 : 验证码 , 用户信息 , 用户行为数据 , 数据计算结果 , 排行榜数据等
- 使用Redis实现分布式锁 , 解决并发环境下的资源竞争问题
- 码表,字典
- 小于20000的缓存表数据:小于20000:表数据修改后会进行缓存通知;
其他场景:库存数量: Redis可以存储实时的库存数量信息,如产品的库存数量、仓库位置等。这些数据可以通过Redis的哈希表结构或者简单的键值对来表示。
库存状态: 除了库存数量,还可以存储库存的状态信息,如产品是否可用、是否处于锁定状态等。这些状态信息可以通过Redis的字符串或者布尔值来表示。
库存更新: 库存信息可能会被频繁地更新,如订单下单、商品退货等操作会导致库存数量的变化。Redis可以提供快速的写入操作,以支持实时的库存更新。
库存查询: 库存信息经常需要被查询,如查询某个产品的当前库存数量、查询某个仓库的所有产品等。Redis可以提供高效的读取操作,以支持快速的库存查询。
库存缓存: 为了进一步提高性能,可以将常用的库存信息缓存到Redis中,以减少数据库的访问频率,提高系统的响应速度。 代码示例
Redis的常用数据类型有哪些 ?
Redis中的数据类型有很多 , 例如 :
- string:最基本的数据类型,二进制安全的字符串,最大512M
- list:按照添加顺序保持顺序的字符串列表
- set:无序的字符串集合,不存在重复的元素
- sorted set:已排序的字符串集合
- hash:key-value对的一种集合
- bitmap(位图):更细化的一种操作,以bit为单位
- hyperlog:基于概率的数据结构
- Geo(Geospatial地理空间索引) : 地理位置类型
常用的就是string ,list , set , zset 和hash
Redis的数据持久化策略有哪些 ?
Redis 提供了两种方式,实现数据的持久化到硬盘。
- RDB 持久化(全量),是指在指定的时间间隔内将内存中的数据集快照写入磁盘。
- AOF持久化(增量),以日志的形式记录服务器所处理的每一个写、删除操作
RDB和AOF一起使用, 在Redis4.0版本支持混合持久化方式 ( 设置 aof-use-rdb-preamble yes )
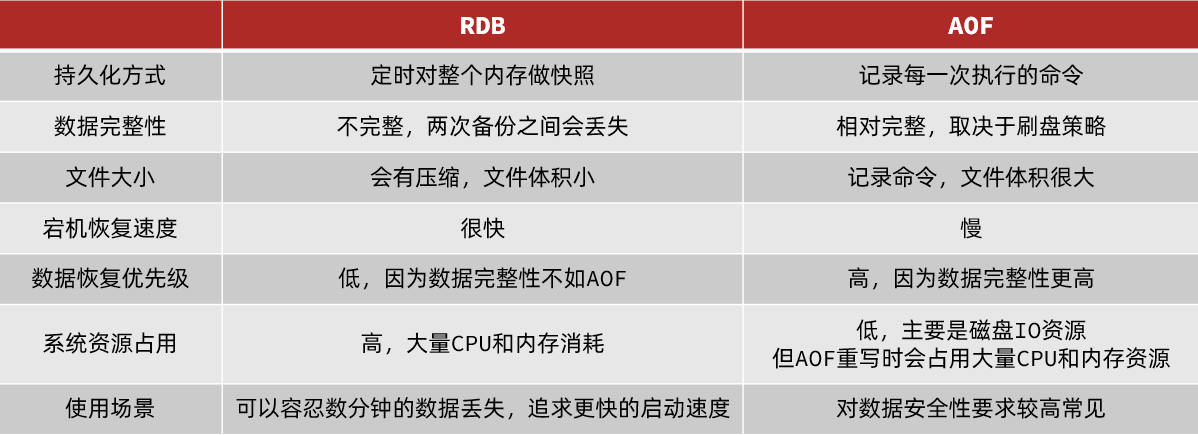
**RDB和AOF区别 ? **
- 备份方式不同 , RDB是定时对整个内存的数据做快照 , AOF采用的是日志追加方案, 记录的是一个个指令
- RDB因为是定时备份 , 二次备份之间如果出现了系统宕机可能会导致两次备份之间的数据丢失 , AOF采用日志追加, 可以配置刷盘策略如果是always会记录每个指令 , 不会出现数据丢失, 如果是every second , 可能会导致1秒以内的数据丢失 , 如果是no ,可能会丢失大量数据
- 因为RDB备份 , 只保存内存数据 , 所以备份文件的体积比较小 , AOF存储的是指令, 所以备份文件的体积比较大
- 在宕机恢复的时候RDB只需要将备份的数据读取到内存即可, 恢复数据比较快, AOF需要将备份文件中的指令一个个重新执行一遍 , 恢复效率比较低
Redis的数据过期策略有哪些 ?
- 惰性删除 :只会在取出 key 的时候才对数据进行过期检查。这样对 CPU 最友好,但是可能会造成太多过期 key 没有被删除。
数据到达过期时间,不做处理。等下次访问该数据时,我们需要判断
- 如果未过期,返回数据
- 发现已过期,删除,返回nil
- 定期删除 : 每隔一段时间抽取一批 key 执行删除过期 key 操作。并且,Redis 底层会通过限制删除操作执行的时长和频率来减少删除操作对 CPU 时间的影响。
默认情况下 Redis 定期检查的频率是每秒扫描 10 次,用于定期清除过期键。当然此值还可以通过配置文件进行设置,在 redis.conf 中修改配置“hz”即可,默认的值为hz 10
定期删除的扫描并不是遍历所有的键值对,这样的话比较费时且太消耗系统资源。Redis 服务器采用的是随机抽取形式,每次从过期字典中,取出 20 个键进行过期检测,过期字典中存储的是所有设置了过期时间的键值对。如果这批随机检查的数据中有 25% 的比例过期,那么会再抽取 20 个随机键值进行检测和删除,并且会循环执行这个流程,直到抽取的这批数据中过期键值小于 25%,此次检测才算完成
Redis 服务器为了保证过期删除策略不会导致线程卡死,会给过期扫描增加了最大执行时间为 25ms
定期删除对内存更加友好,惰性删除对 CPU 更加友好。两者各有千秋,所以 Redis 采用的是 定期删除+惰性删除
Redis的数据淘汰策略有哪些 ?
Redis 提供 三类八种数据淘汰策略:
第一类 : 淘汰易失数据(具有过期时间的数据)
- volatile-lru(least recently used):从已设置过期时间的数据集(server.db[i].expires)中挑选最近最少使用的数据淘汰
- volatile-lfu(least frequently used):从已设置过期时间的数据集(server.db[i].expires)中挑选最不经常使用的数据淘汰
- volatile-ttl:从已设置过期时间的数据集(server.db[i].expires)中挑选将要过期的数据淘汰
- volatile-random:从已设置过期时间的数据集(server.db[i].expires)中任意选择数据淘汰
第二类 : 淘汰全库数据
- allkeys-lru(least recently used):当内存不足以容纳新写入数据时,在键空间中,移除最近最少使用的 key(这个是最常用的)
- allkeys-lfu(least frequently used):当内存不足以容纳新写入数据时,在键空间中,移除最不经常使用的 key
- allkeys-random:从数据集(server.db[i].dict)中任意选择数据淘汰
第三类 : 不淘汰
- no-eviction:禁止驱逐数据,也就是说当内存不足以容纳新写入数据时,新写入操作会报错。这个应该没人使用吧!
你们使用Redis是单点还是集群 ? 哪种集群 ?
我们Redis使用的是Cluster集群 , 三主六从 , 一个主节点挂载二个从节点 , 保证数据安全和集群的可用性
Redis集群有哪些方案, 知道嘛 ?
我所了解的Redis集群方案
- 主从复制集群 : 读写分离, 一主多从 , 解决高并发读的问题,主节点负责写操作,从节点复制主节点的数据,并提供读服务。主从复制提高了可用性和读性能,但没有提供自动故障转移的机制,需要手动进行切换。
- 哨兵(Sentinel)集群 : 主从集群的结构之上 , 加入了哨兵用于监控集群状态 , 主节点出现故障, 执行主从切换 , 解决高可用问题,每个 Sentinel 进程都会监控一组 Redis 实例,并通过投票选举出新的主节点。
- Cluster分片集群 : 多主多从 , 解决高并发写的问题, , Cluster 它将数据分片存储到多个节点上,并通过集群间的消息通信(PING命令)来实现数据的自动迁移和故障转移。由多个节点组成,每个节点负责存储部分数据,并通过哈希槽(hash slot)来实现数据的分片和路由。
- 第三方集群方案: 一些第三方的 Redis 集群方案,如 Codis、Twemproxy(也称为Nutcracker)、Predis、RediSharding 等。这些方案通常是基于代理(proxy)或中间件来实现数据分片和路由,从而将多个 Redis 实例组织成一个逻辑上的集群。
什么是 Redis 主从同步?
Redis 的主从同步(replication)机制,允许 Slave 从 Master 那里,通过网络传输拷贝到完整的数据备份,从而达到主从机制。
主数据库可以进行读写操作,当发生写操作的时候自动将数据同步到从数据库,而从数据库一般是只读的,并接收主数据库同步过来的数据。一个主数据库可以有多个从数据库,而一个从数据库只能有一个主数据库。

主从数据同步主要分二个阶段 :
第一阶段 : 全量复制阶段
- slave节点请求增量同步
- master节点判断replid,发现不一致,拒绝增量同步
- master将完整内存数据生成RDB,发送RDB到slave
- slave清空本地数据,加载master的RDB
第二阶段 : 增量复制阶段
- master将RDB期间的命令记录在repl_baklog,并持续将log中的命令发送给slave
- slave执行接收到的命令,保持与master之间的同步
Redis分片集群中数据是怎么存储和读取的 ?
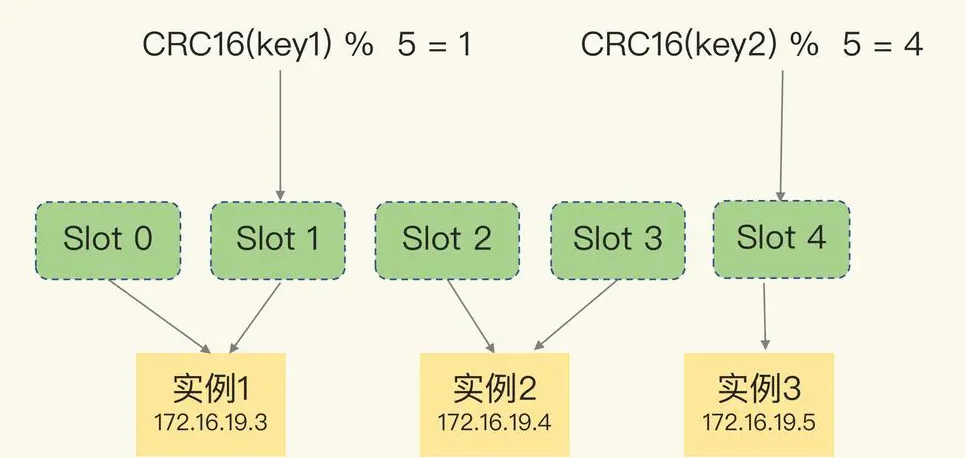
Redis集群采用的算法是哈希槽分区算法。Redis集群中有16384个哈希槽(槽的范围是 0 -16383,哈希槽),将不同的哈希槽分布在不同的Redis节点上面进行管理,也就是说每个Redis节点只负责一部分的哈希槽。在对数据进行操作的时候,集群会对使用CRC16算法对key进行计算并对16384取模(slot = CRC16(key)%16383),得到的结果就是 Key-Value 所放入的槽,通过这个值,去找到对应的槽所对应的Redis节点,然后直接到这个对应的节点上进行存取操作
你们用过Redis的事务吗 ? 事务的命令有哪些 ?
Redis 作为 NoSQL 数据库也同样提供了事务机制。在 Redis 中有四个事物相关指令
- MULTI : 开启事物
- EXEC : 提交事物
- DISCARD : 回滚事务
- WATCH : 监控事物
我们在开发过程中基本上没有用到过Redis的事务 , 如果需要保证多个操作的原子性, 经常会使用Lua脚本 , 把多个Redis操作封装到一个lua脚本中, 作为一个指令发送给Redis服务器执行
Redis的内存用完了会发生什么?
如果达到设置的上限,Redis 的写命令会返回错误信息( 但是读命令还可以正常返回)
也可以配置内存淘汰机制, 当 Redis 达到内存上限时会冲刷掉旧的内容 , 释放出内存空间
Redis和Mysql如何保证数据⼀致?
保证数据⼀致的方式有很多 , 需要根据不同的情况选择对应的解决方案, 我所了解的方案主要有三种 :
- 同步双写机制
先更新Mysql,再更新Redis,这个时候如果更新Redis失败,可能仍然不⼀致
- 删除缓存重新加载机制
先删除Redis缓存数据,再更新Mysql,再次查询的时候在将数据添加到缓存中
⽐如线程1删除了 Redis缓存数据,还没有来得及更新Mysql,此时另外⼀个查询再查询,那么就会把Mysql中⽼数据⼜查到 Redis中
- 延迟双删机制
Redis 的延迟双删策略:
在 Redis 中,主节点和从节点之间的数据同步通常通过主从复制实现。Redis 使用主从复制来实现数据的备份和读写分离,其中主节点负责处理写请求,从节点负责处理读请求。
Redis 的延迟双删策略通常是指在主节点执行删除操作后,不立即向所有从节点发送删除指令,而是将待删除键的信息放入一个待删除键列表中。然后,定期或根据一定条件,主节点将待删除键列表中的键发送给所有从节点。从节点收到待删除键列表后,首先将列表中的键标记为待删除状态,而不是立即删除。在一段时间后,再次检查待删除键列表,如果这些键仍然存在,表示可能有读请求在此期间访问了这些键,那么就执行第二次删除操作,确保从节点的数据与主节点保持一致。MySQL 的延迟双删策略:
在 MySQL 主从复制中,主库(master)负责处理写操作,从库(slave)负责复制主库的数据。在 MySQL 中,为了保证主从复制的数据一致性,通常会使用延迟双删策略。
MySQL 的延迟双删策略类似于 Redis,主要是指主库在执行删除操作后,并不立即向所有从库发送删除指令,而是将待删除数据的信息先记录到 binlog 中。从库在读取 binlog 并执行删除操作时,也会先将待删除数据标记为待删除状态,然后等待一段时间。在此期间,如果发现有查询操作需要读取已经被标记为待删除的数据,那么就暂时不执行删除操作,以保证数据的一致性。在一定时间后,再次检查待删除数据,如果依然存在,则执行删除操作。
- 对于一致性要求不高的场景, 也可以使用MQ异步同步, 保证数据的最终一致性 , 不需要直接删除
我们项目中会根据业务情况 , 使用不同的方案来解决Redis和Mysql的一致性问题 :
- 对于一些一致性要求不高的场景 , 不做处理
例如 : 用户行为数据 , 我们没有做一致性保证 , 因为就算不一致产生的影响也很小
- 对于时效性数据 , 设置过期时间
例如 : 接口缓存数据 , 我们会设置缓存的过期时间为 60S , 那么可能会出现60S之内的数据不一致, 60S后缓存过期, 重新从数据库加载就一致了
- 对于一致性要求比较高但是时效性要求不那么高的场景 , 使用MQ不断发送消息完成数据同步直到成功为止
例如 : 首页广告数据 , 首页推荐数据
数据库数据发生修改----> 发送消息到MQ -----> 接收消息更新缓存
- 对于一致性和时效性要求都比较高的场景 , 使用延迟双删机制
什么是缓存穿透 ? 怎么解决 ?
缓存穿透说简单点就是大量请求的 key 根本不存在于缓存中,导致请求直接到了数据库上,根本没有经过缓存这一层。举个例子:某个黑客故意制造我们缓存中不存在的 key 发起大量请求,导致大量请求落到数据库。

有哪些解决办法
- 最基本的就是首先做好参数校验,一些不合法的参数请求直接抛出异常信息返回给客户端。比如查询的数据库 id 不能小于 0、传入的邮箱格式不对的时候直接返回错误消息给客户端等等
- 缓存无效 key , 如果缓存和数据库都查不到某个 key 的数据就写一个到 Redis 中去并设置过期时间 , 尽量将无效的 key 的过期时间设置短一点比如 1 分钟
- 布隆过滤器 , 提前将数据库中存在的数据加载到布隆过滤器 , 当用户请求过来,先判断用户发来的请求的值是否存在于布隆过滤器中。不存在的话,直接返回请求参数错误信息给客户端,存在的话才会走下面的流程
什么是缓存击穿 ? 怎么解决 ?
某个热点 key,在缓存过期的一瞬间,同时有大量的请求打进来,由于此时缓存过期了,所以请求最终都会走到数据库,造成瞬时数据库请求量大、压力骤增,导致数据库存在被打挂的风险
有哪些解决办法
- 加互斥锁。当热点key过期后,大量的请求涌入时,只有第一个请求能获取锁并阻塞,此时该请求查询数据库,并将查询结果写入redis后释放锁。后续的请求直接走缓存
- 设置缓存不过期或者后台有线程一直给热点数据续期
什么是缓存雪崩 ? 怎么解决
缓存雪崩是指缓存在同一时间大面积的失效,后面的请求都直接落到了数据库上,造成数据库短时间内承受大量请求。这就好比雪崩一样,摧枯拉朽之势,数据库的压力可想而知,可能直接就被这么多请求弄宕机了。
有哪些解决办法
- 采用 Redis 集群,避免单机出现问题整个缓存服务都没办法使用
- 限流,避免同时处理大量的请求
- 设置不同的失效时间比如随机设置缓存的失效时间
- 针对热点数据设置缓存永不失效
数据库有1000万数据 ,Redis只能缓存20w数据, 如何保证Redis中的数据都是热点数据 ?
配置Redis的内容淘汰策略为LFU算法 , 这样会把使用频率较低的数据淘汰掉 , 留下的数据都是热点数据
Redis分布式锁如何实现 ?
Redis分布式锁主要依靠一个SETNX指令实现的 , 这条命令的含义就是“SET if Not Exists”,即不存在的时候才会设置值。
只有在key不存在的情况下,将键key的值设置为value。如果key已经存在,则SETNX命令不做任何操作。
这个命令的返回值如下。
- 命令在设置成功时返回1。
- 命令在设置失败时返回0。
假设此时有线程A和线程B同时访问临界区代码,假设线程A首先执行了SETNX命令,并返回结果1,继续向下执行。而此时线程B再次执行SETNX命令时,返回的结果为0,则线程B不能继续向下执行。只有当线程A执行DELETE命令将设置的锁状态删除时,线程B才会成功执行SETNX命令设置加锁状态后继续向下执行
Boolean isLocked = stringRedisTemplate.opsForValue().setIfAbsent(PRODUCT_ID, "binghe");
当然我们在使用分布式锁的时候也不能这么简单, 会考虑到一些实际场景下的问题 , 例如 :
- 死锁问题
在使用分布式锁的时候, 如果因为一些原因导致系统宕机, 锁资源没有被释放, 就会产生死锁
解决的方案 : 上锁的时候设置锁的超时时间
Boolean isLocked = stringRedisTemplate.opsForValue().setIfAbsent(PRODUCT_ID, "binghe", 30, TimeUnit.SECONDS);
- 锁超时问题
如果业务执行需要的时间, 超过的锁的超时时间 , 这个时候业务还没有执行完成, 锁就已经自动被删除了
其他请求就能获取锁, 操作这个资源 , 这个时候就会出现并发问题 , 解决的方案 :
- 引入Redis的watch dog机制, 自动为锁续期
- 开启子线程 , 每隔20S运行一次, 重新设置锁的超时时间
- 归一问题
如果一个线程获取了分布式锁, 但是这个线程业务没有执行完成之前 , 锁被其他的线程删掉了 , 又会出现线程并发问题 , 这个时候就需要考虑归一化问题
就是一个线程执行了加锁操作后,后续必须由这个线程执行解锁操作,加锁和解锁操作由同一个线程来完成。
为了解决只有加锁的线程才能进行相应的解锁操作的问题,那么,我们就需要将加锁和解锁操作绑定到同一个线程中,可以使用ThreadLocal来解决这个问题 , 加锁的时候生成唯一标识保存到ThreadLocal , 并且设置到锁的值中 , 释放锁的时候, 判断线程中的唯一标识和锁的唯一标识是否相同, 只有相同才会释放
public class RedisLockImpl implements RedisLock{@Autowiredprivate StringRedisTemplate stringRedisTemplate;private ThreadLocal<String> threadLocal = new ThreadLocal<String>();@Overridepublic boolean tryLock(String key, long timeout, TimeUnit unit){String uuid = UUID.randomUUID().toString();threadLocal.set(uuid);return stringRedisTemplate.opsForValue().setIfAbsent(key, uuid, timeout, unit);}@Overridepublic void releaseLock(String key){//当前线程中绑定的uuid与Redis中的uuid相同时,再执行删除锁的操作if(threadLocal.get().equals(stringRedisTemplate.opsForValue().get(key))){stringRedisTemplate.delete(key); }}
}
- 可重入问题
当一个线程成功设置了锁标志位后,其他的线程再设置锁标志位时,就会返回失败。
还有一种场景就是在一个业务中, 有个操作都需要获取到锁, 这个时候第二个操作就无法获取锁了 , 操作会失败
例如 : 下单业务中, 扣减商品库存会给商品加锁, 增加商品销量也需要给商品加锁 , 这个时候需要获取二次锁
第二次获取商品锁就会失败 , 这就需要我们的分布式锁能够实现可重入
实现可重入锁最简单的方式就是使用计数器 , 加锁成功之后计数器 + 1 , 取消锁之后计数器 -1 , 计数器减为0 , 真正从Redis删除锁
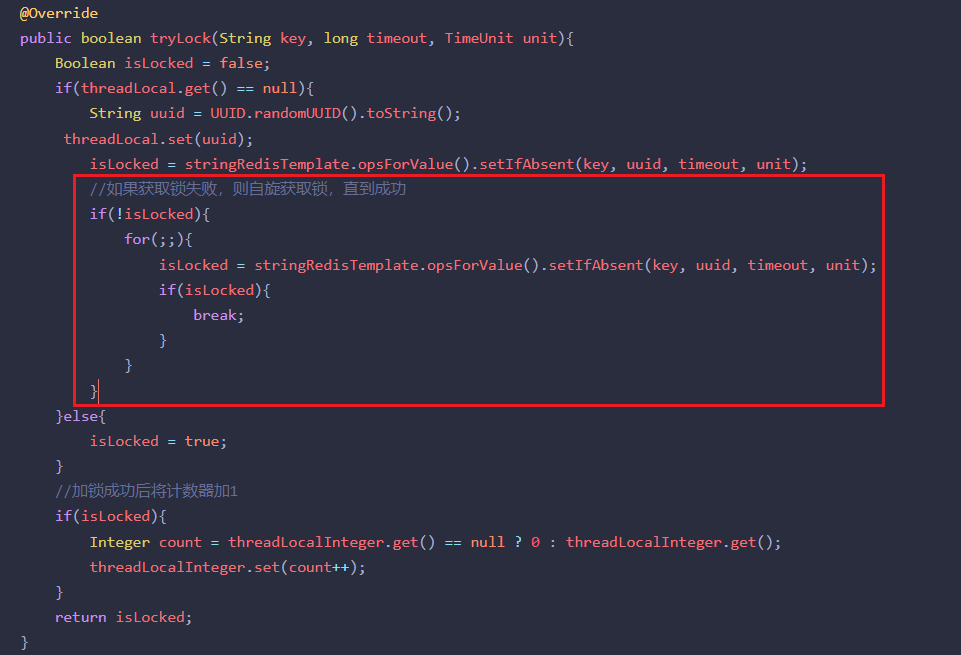
public class RedisLockImpl implements RedisLock{@Autowiredprivate StringRedisTemplate stringRedisTemplate;private ThreadLocal<String> threadLocal = new ThreadLocal<String>();private ThreadLocal<Integer> threadLocalInteger = new ThreadLocal<Integer>();@Overridepublic boolean tryLock(String key, long timeout, TimeUnit unit){Boolean isLocked = false;if(threadLocal.get() == null){String uuid = UUID.randomUUID().toString();threadLocal.set(uuid);isLocked = stringRedisTemplate.opsForValue().setIfAbsent(key, uuid, timeout, unit);}else{isLocked = true; }//加锁成功后将计数器加1if(isLocked){Integer count = threadLocalInteger.get() == null ? 0 : threadLocalInteger.get();threadLocalInteger.set(count++);}return isLocked;}@Overridepublic void releaseLock(String key){//当前线程中绑定的uuid与Redis中的uuid相同时,再执行删除锁的操作if(threadLocal.get().equals(stringRedisTemplate.opsForValue().get(key))){Integer count = threadLocalInteger.get();//计数器减为0时释放锁if(count == null || --count <= 0){stringRedisTemplate.delete(key); }}}
}
- 阻塞与非阻塞问题
在使用分布式锁的时候 , 如果当前需要操作的资源已经加了锁, 这个时候会获取锁失败, 直接向用户返回失败信息 , 用户的体验非常不好 , 所以我们在实现分布式锁的时候, 我们可以将后续的请求进行阻塞,直到当前请求释放锁后,再唤醒阻塞的请求获得分布式锁来执行方法。
具体的实现就是参考自旋锁的思想, 获取锁失败自选获取锁, 直到成功为止 , 当然为了防止多条线程自旋带来的系统资料消耗, 可以设置一个自旋的超时时间 , 超过时间之后, 自动终止线程 , 返回失败信息
- 公平锁(Fair Lock):
- 公平锁保证锁的获取按照请求的顺序进行,即先请求锁的线程先获取锁,遵循先来先服务的原则。
- 公平锁的实现会维护一个请求队列,当锁被释放时,队列中的第一个请求线程会被唤醒并获得锁。
- 非公平锁(Non-Fair Lock):
- 非公平锁在锁释放时不会考虑请求锁的顺序,它允许某个后来的请求线程在当前锁被释放时立即尝试获取锁。
- 非公平锁的优势在于它可以减少锁竞争的开销,尤其是在高并发情况下,因为它允许某些线程在等待队列中绕过排队直接获取锁。
你的项目中哪里用到了分布式锁
参考回答一 : 在我最近做的一个项目中 , 我们在任务调度的时候使用了分布式锁
早期我们在进行定时任务的时候我们采用的是SpringTask实现的 , 在集群部署的情况下, 多个节点的定时任务会同时执行 , 造成重复调度 , 影响运算结果, 浪费系统资源
这里为了防止这种情况的发送, 我们使用Redis实现分布式锁对任务进行调度管理 , 防止重复任务执行
后期因为我们系统中的任务越来越多 , 执行规则也比较多 , 而且单节点执行效率有一定的限制 , 所以定时任务就切换成了XXL-JOB , 系统中就没有再使用分布式锁了
参考回答二 : 我们项目在下单的过程中为了防止订单超卖 , 使用了分布式锁
参考回答三 : 我们项目中有一个用户预约充电桩的功能, 为了避免多个用户预约到同一个充电桩, 使用可分布式锁
参考回答四 : 我们项目中有一个抢座功能 , 为了避免同一个座位被多个用户购买, 使用了分布式锁
redis如何实现一个排行榜的功能
在 Redis 中实现排行榜功能通常可以通过有序集合(Sorted Set)来实现。有序集合是一种数据结构,其中的每个成员都与一个分数相关联,Redis 会根据分数的顺序对集合中的成员进行排序。以下是实现排行榜功能的一般步骤:
- 添加成员及其分数: 将需要加入排行榜的成员作为有序集合的成员,同时指定每个成员的分数。通常情况下,分数可以是某种计算得出的值,比如用户的得分、点击数、积分等。
- 查询排行榜: 可以使用有序集合的命令(如ZREVRANGE)查询排行榜中的成员。根据需求,可以查询整个排行榜,也可以指定查询排行榜的某一部分(如前 N 名、某个分数范围内的成员等)。
- 更新排行榜: 当成员的分数发生变化时,需要更新排行榜。可以使用 ZADD 命令更新成员的分数,Redis 会自动根据新的分数重新排序排行榜。
以下是一些示例命令,用于实现排行榜功能:
bash# 添加成员及其分数
ZADD leaderboard 1000 "player1"
ZADD leaderboard 900 "player2"
ZADD leaderboard 800 "player3"# 查询排行榜
ZREVRANGE leaderboard 0 -1 WITHSCORES # 查询整个排行榜及分数# 更新成员分数
ZADD leaderboard 1100 "player1" # 更新 player1 的分数为 1100
在实际应用中,还可以结合其他 Redis 数据结构和功能来实现更丰富的排行榜功能。例如,可以使用 Hash 数据结构保存每个成员的详细信息,使用过期时间设置排行榜的有效期,使用事务和 Lua 脚本确保更新操作的原子性等。
Redis设置过期时间代码示例
import redis.clients.jedis.Jedis;public class RedisExample {public static void main(String[] args) {// 连接到 Redis 服务器Jedis jedis = new Jedis("localhost", 6379);// 设置键的值,并指定过期时间(以秒为单位)setWithExpiry(jedis, "my_key", "my_value", 60);// 关闭连接jedis.close();}public static void setWithExpiry(Jedis jedis, String key, String value, int expirySeconds) {// 设置键值对,并指定过期时间jedis.setex(key, expirySeconds, value);}
}
这篇关于【2024最新精简版】Redis面试篇的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





