本文主要是介绍TensorFlow入门(一)——理论知识介绍及简单代码实现,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
TensorFlow入门(一)——理论知识介绍及简单代码实现
- 一、TensorFlow安装
- 二、TensorFlow计算模型——计算图(Graph)
- 概念
- 属性
- 三、TensorFlow数据模型——张量(Tensor)
- 概念
- 属性
- 名字——name
- 维度——shape
- 类型——type
- 查看Tensor具体内容
- 四、Tensorflow运行模型——会话(Session)
- 概念
- 使用步骤
- 方式一(不推荐)
- 方式二(推荐)
- 五、完整代码展示
tf是tensorflow的简写,在编程时注意使用import tensorflow as tf,为了方便,以后所有的tf都表示tensorflow
一、TensorFlow安装
此处不再赘述,请参考本人博客,见下面链接
https://blog.csdn.net/u011609063/article/details/84188942
二、TensorFlow计算模型——计算图(Graph)
概念
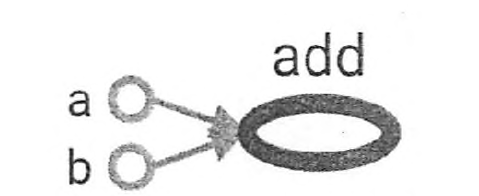
该图中每一个节点都是一个运算,每条边代表了计算之间的依赖关系。a和b不依赖其它计算,而add计算依赖a和b,因此有一条a到add和b到add的边。没有任何计算依赖add的结果,所以代表加法的add节点没有指向任何其它节点的边。这种组织方式就是计算图。
注意:不同计算图中的Tensor(张量)不会共享
属性
在计算图中,可以通过集合(collection)来管理不同类别的资源。
例如:
tf.add_to_collection函数可以加入一个或者多个资源到集合中
tf.get_collection函数获取一个集合中所有资源。可以是张量、变量或者运行中队列的资源
TensorFlow中常用集合
| 集合名称 | 集合内容 | 使用场景 |
|---|---|---|
| tf.GraphKeys.VARIABLES | 所有变量 | 持久化TensorFlow模型 |
| tf.GraphKeys.TRAIN_VARIABLES | 可学习的变量(一般指神经网络中的参数) | 模型训练、生成模型可视化内容 |
| tf.GraphKeys.SUMMARIES | 日志生成相关的张量 | TensorFlow计算可视化 |
| tf.GraphKeys.QUEUE_RUNNERS | 处理输入的QueueRunner | 输入处理 |
| tf.GraphKeys.MOVING_AVERAGE_VARIABLES | 所有计算了滑动平均值的变量 | 计算变量的滑动平均值 |
三、TensorFlow数据模型——张量(Tensor)
概念
Tensor是TensorFlow中管理数据的形式,所有的数据都通过Tensor的形式表示。
Tensor可以被理解为多维数组,其中
零阶Tensor表示标量(scalar),即一个数
一阶Tensor为向量(vector),即一维数组
n阶Tensor可被理解为n阶数组
Tensor中并没有真正保存数据,它保存的是如何得到这些数字的计算过程的应用,因此无法直接通过print输出结果
属性
下图是通过print函数直接输出的Tensor的结果
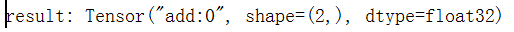
-
名字——name
张量的命名可以通过"node:src_output"表示,其中node为节点名称,src_output表示来自节点的第几个输出。在该图中"add:0"说明了result这个张量是计算节点"add"输出的第一个结果(编号从0开始)
-
维度——shape
该属性描述了Tensor的维度信息,shape=(2, )说明是一个一维数组,长度为2
-
类型——type
每个Tensor都会有唯一的一个类型,当类型不匹配时会报错,例如:
a = tf.constant([1, 2], name="a") b = tf.constant([1.0, 2.0], name="b") result = a + b运行这段代码就会报错,报错具体信息可以自行尝试
查看Tensor具体内容
with tf.Session() as sess:# method 1print("result: {}".format(sess.run(tensor_name)))# method 2print("result: {}".format(tensor_name.eval()))
四、Tensorflow运行模型——会话(Session)
概念
主要是用来执行定义好的运算。会话拥有并管理TensorFlow程序运行时的所哟资源。当计算完成时帮助系统回收资源,否则的话会出现资源泄露的情况。
使用步骤
方式一(不推荐)
- 创建——sess = tf.Session()
- 使用——sess.run(…)
- 关闭——sess.close()
方式二(推荐)
使用该方式无需手动关闭,推荐该方式,因为上述方式当发生异常时,不一定能关闭会话,从而造成资源泄露
with tf.Session() as sess:sess.run(...)
五、完整代码展示
"""
This scripts shows how to generate a new graph and
how to define and use variables in different graph.
Note that:Tensor and Computation in different graphs won't shared with each other
"""
import tensorflow as tfg1 = tf.Graph()
with g1.as_default():# define variable "v" and make it equal to 0 in graph g1v = tf.get_variable("v", shape=[2, 3], initializer=tf.zeros_initializer())g2 = tf.Graph()
with g2.as_default():# define variable "v" and make it equal to 1 in graph g2v = tf.get_variable("v", shape=[3, 2], initializer=tf.ones_initializer())# read the v's value in g1
with tf.Session(graph=g1) as sess:tf.global_variables_initializer().run()with tf.variable_scope("", reuse=True):print("g1_v: {}".format(sess.run(tf.get_variable("v"))))# read the v's value in g2
with tf.Session(graph=g2) as sess:tf.global_variables_initializer().run()with tf.variable_scope("", reuse=True):print("g2_v: {}".format(sess.run(tf.get_variable("v"))))g = tf.Graph()a = tf.constant([1, 2], name="a", dtype=tf.float32)
b = tf.constant([1.0, 2.0], name="b")
result = tf.add(a, b, name="add")# specify the device to run
with g.device("/cpu:0"):with tf.Session() as sess:print("result: {}".format(result.eval()))
写博客不易,转载请注明原出处
这篇关于TensorFlow入门(一)——理论知识介绍及简单代码实现的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!




