本文主要是介绍中间件复习之-分布式存储系统,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
单机存储系统介绍
存储引擎:存储系统的发动机,提供数据的增、删、改、查能力,直接决定存储系统的功能(支持怎么样的查询,锁能锁到什么程度)和性能(增删改查速度)。
- 性能因素
- 写入方式
- 顺序写
- 随机写
- 读取方式
- 随机读
- 顺序扫描
无论是HD还是SSD硬盘,都是顺序读写性能高一些。
- 写入方式
单机存储引擎
- Hash存储引擎:点查的场景,不适合范围查询
- B树存储引擎:有序,适合范围查询
- LSM存储引擎:一颗大树拆分成n多的小树
Hash存储引擎
有一个hashTable,PK经过hash计算,找到了HashTable的位置。
先通过fileid找到文件,再通过pos偏移量找到位置,再通过size得到存储数据。
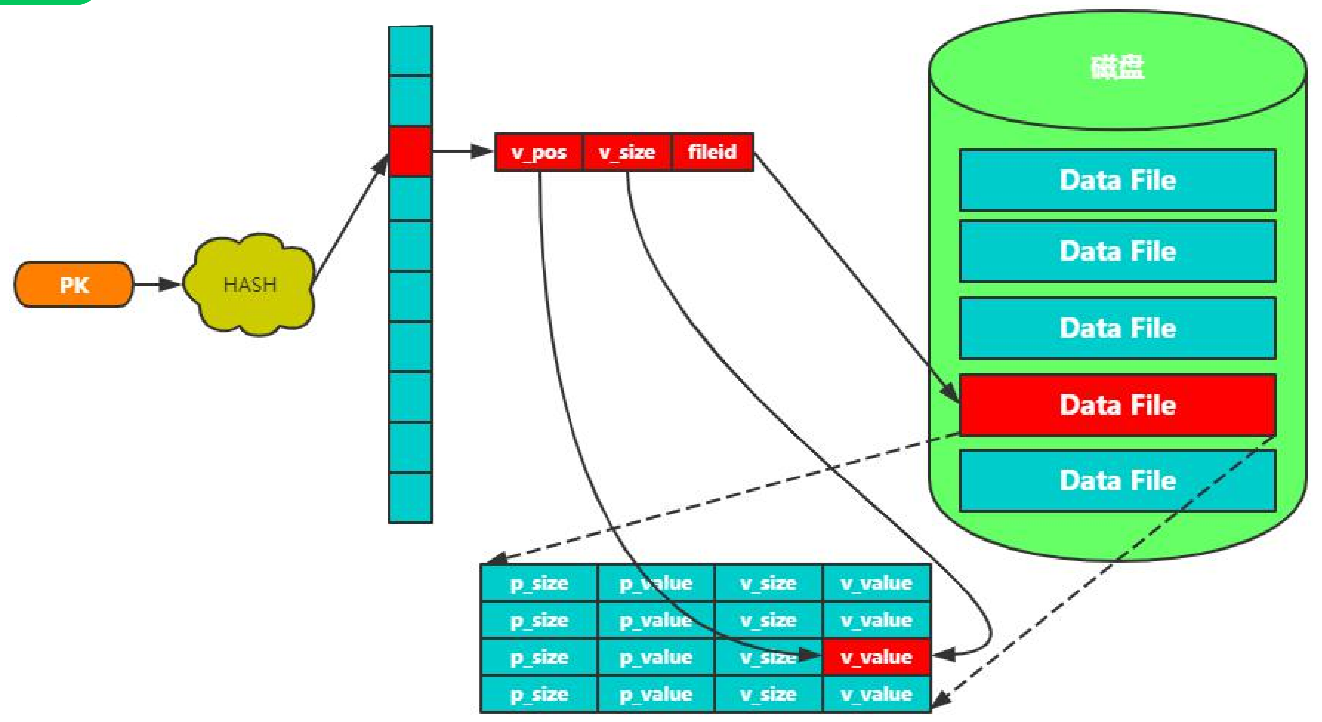
特性:
- 时间复杂度O(1)
- 满足“=”、“IN”查询
- 不支持范围查询
- 不支持排序
代表产品:Redis、Memcached
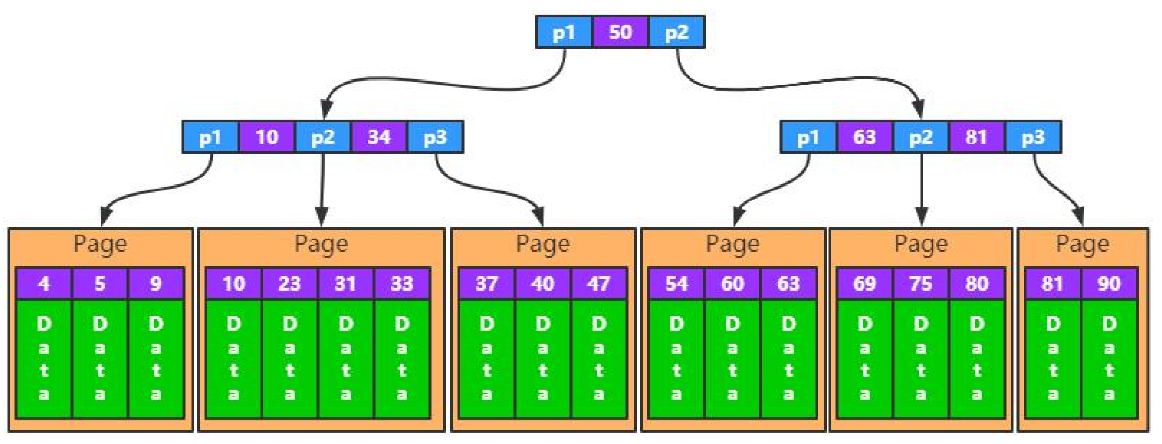
B树存储引擎
MySQL通过该结构做聚簇索引、二级索引。
查找原素时从根结点指针入口进行查找。如果是聚簇索引,叶子节点跟的就是value,如果不是聚簇索引,跟的就是PK。
各个叶子结点双向链表连接。可以通过DATA指针做全表扫描。
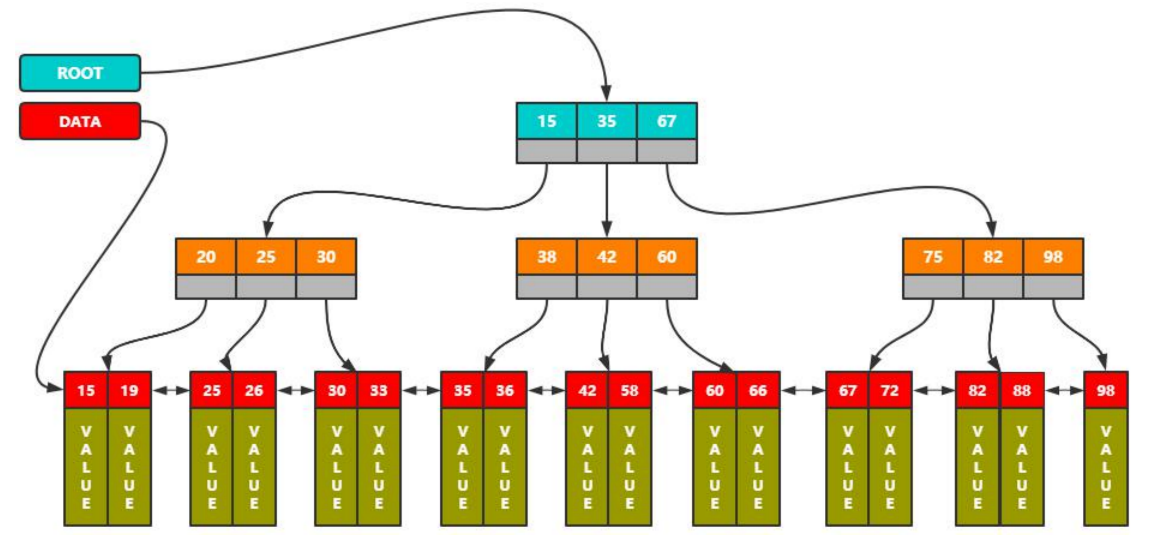
特性:
- 根节点常驻内存,最多h-1次磁盘IO
- 蓝色那一层是在内存中的,最坏的话如图,查找2次。橘色读一次磁盘,红色读一次磁盘。(大多数情况蓝色和橘色都在内存中)
- 非叶子节点容纳尽量多的元素
- 一页最大16k
- 擅长范围查询
- 随机写问题
- 因为数据是有序的所以写入文件不是顺序写入。比如写入37,不能直接写到尾节点98的后面。
- 节点分裂
- 比如35,36节点页满了,还想插入37,那就要分裂节点重新连接。
代表产品:MySQL-InnoDB
LSM存储引擎
所有的写入(更新、插入、删除)都往MemTable中写(为了方式内存里的数据不丢,会同时写.log文件),写满之后锁住当前的MemTable->Immutable MemTable,往磁盘中刷数据。新的写入新构建一个MemTable。
Immutable MemTable写入Level0层,Level0层有序,但是各个模块数据有交叉。(如第一块0-100,第二块95-195)
Level0内的文件多到一定程度后会往下压缩。
Level1内的文件数据不会有交叉。
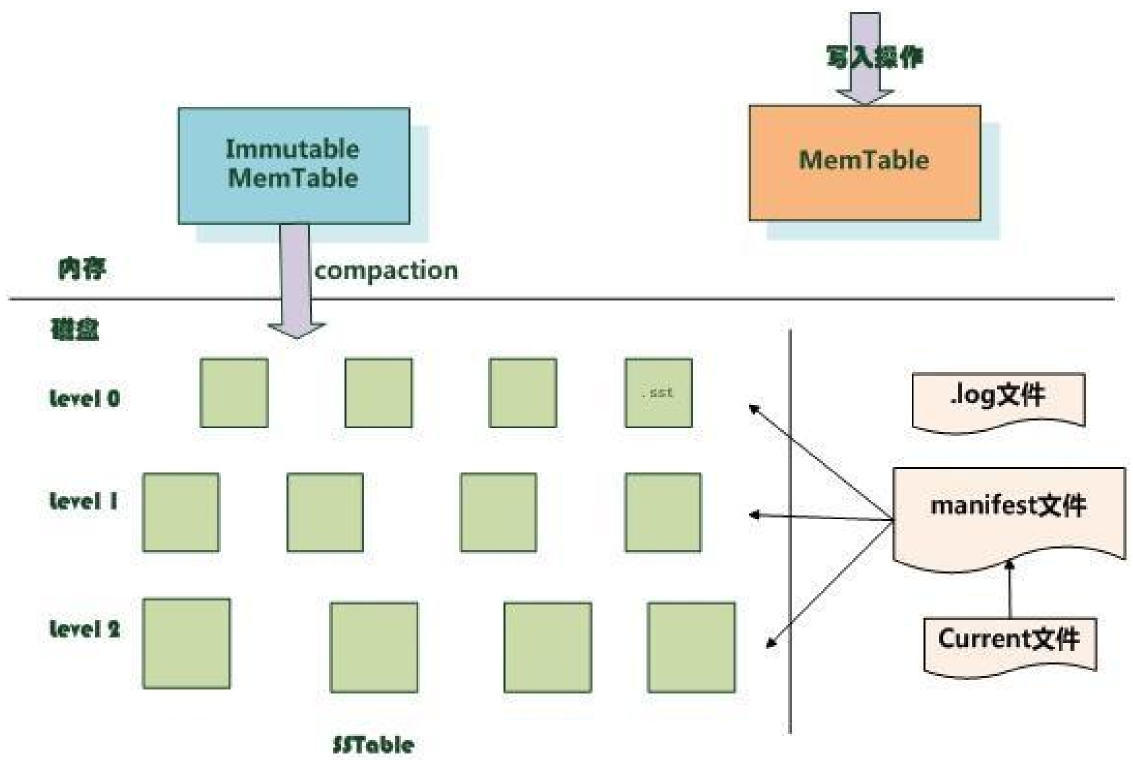
删除、更新如何做?
因为LSM的存储结构是一层层结构,如果更新的话需要找到该数据每一层的位置并执行更新,非常复杂,所以更新使用以下的方式去执行。
更新:往MemTable中写入一个新的记录 K1:V1(原来K1:V0);查找时查找到level0的最新的记录( K1:V1)就直接返回了。
删除:往MemTable中写入一个新的记录 K1:deleted;查找时找到level0的最新记录就直接返回了。
整体的数据一层层往下沉,发现冲突了,就按照最新的记录做合并。
特性:
- 随机写变顺序写
- 插入、更新、删除都转换成了顺序写
- 牺牲读性能
- Level0读不到读Level1;Level1读不到读Level2
- 增加后台合并开销
- 文件往下沉
读可能需要读多层文件 设计初衷是什么?
写入优化比较困难,读的话可以增加多层中间缓存做优化。
LSM存储引擎特性
- Flush:Immutable MemTable -> Level0
- SSTFile:L0、L1、L2等文件都称为SSTFile
- Compaction(压缩):L0多个文件合并成L1,L1多个文件合并成L2
LSM存储引擎优化
- 布隆过滤器快速判断(读优化)
- 文件内数据有序(读优化)
代表产品
LevelDB(谷歌项目)、RocksDB(嵌入式存储引擎)
存储模型
数据模型是存储系统的外壳,描述存储系统以什么样的形式存储或管理数据
- 关系模型(表间的关系)
- 键值模型(K-V存储)
- 时序 influxDB:主要用于监控场景
- 组织结构: 时间戳t1-(。。。。。一些数据),时间戳t2-(。。。。。一些数据)
- 图 风控、算法场景主要使用
Redis存储原理深入剖析
Redis原理分析
Redis是用C语言开发的一个开源的高性能键值对(key-value)内存数据库。
- 数据存储原理
- 数据固化方式
- 可靠性保障方案
Redis数据存储原理

- redisDB(一个数据节点)
- dict
- dictht(ht -> hashTable)
- dictEntry
- union c语言的一个联合体,内部的数据不是同时有效而是只能存在一个。
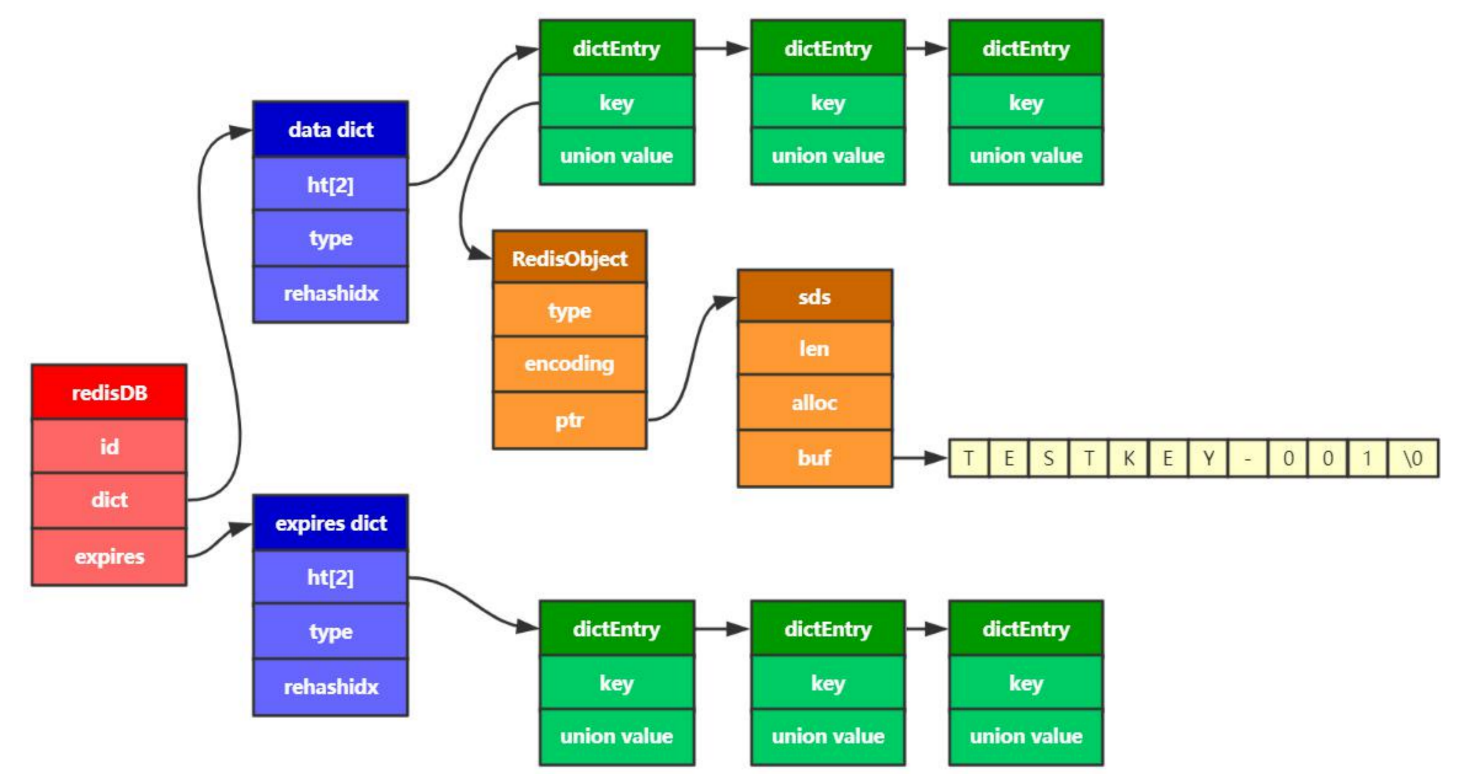
一个redisDB代表一个数据节点,包含2个dict,一个dict存储数据,一个dict存储过期时间。
- union c语言的一个联合体,内部的数据不是同时有效而是只能存在一个。
- RedisObject
- type:key的类型
- encoding:key的编码
- ptr-key的指针:key的值需要一个结构去描述,因此指向一个sds
- sds
- len:key的长度
- alloc:分配空间
- buf:key的内容
- sds
Key对存储效率的影响
dictEntry:16字节
RedisObjct:12字节
sds:8字节+字符串长度
一个10个字节的key需要的空间数量:16+12+8+10+1 = 47,再加上过期时间要存储的dict还需要*2,将近100字节。
redis除了本身要存的数据存储空间还需要额外增加一些其他redis基本存储结构的存储空间。
内存清理
定期删除
1、 能否直接遍历过期字典表(expires dict)按照过期时间删除?
不可,redis单工作线程,如果花大代价去过滤所有的过期字典表会影响工作线程。
redis的策略:找到平衡点,随机选择dictEntry判断是否过期然后做清理。如果发现清理的数量大于查找数量的25%了,那redis认为有很多数据已经过期了,那就再执行一次循环,删除过期。
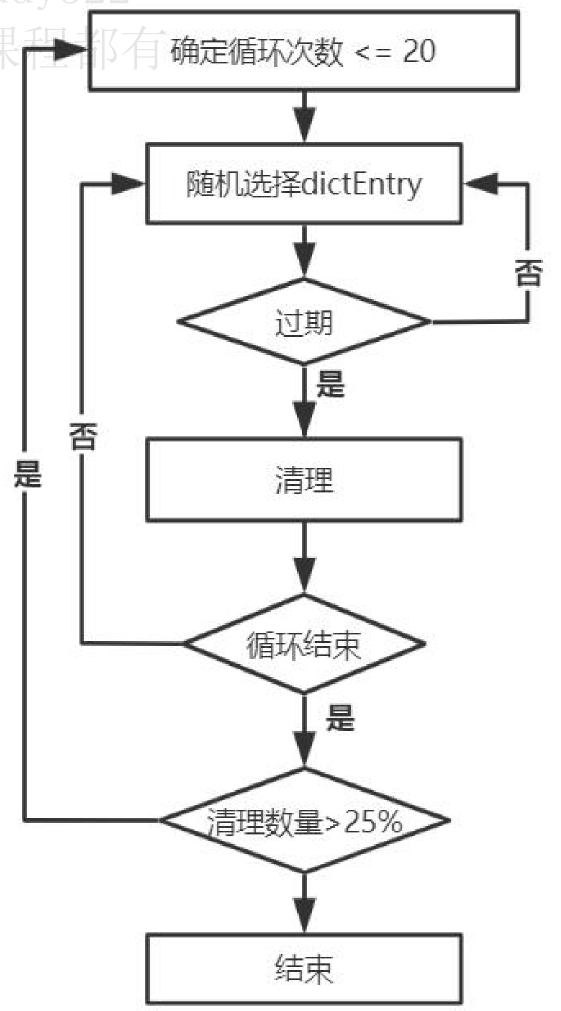
惰性删除
当客户端尝试访问一个键时,Redis服务器才会检查这个键是否已经过期。如果发现该键已过期,则在返回结果前立即将其从数据库中删除。这种策略节省了CPU资源,因为它只在访问时才进行检查和删除操作,但存在可能长时间不访问而导致内存无法及时释放的风险。
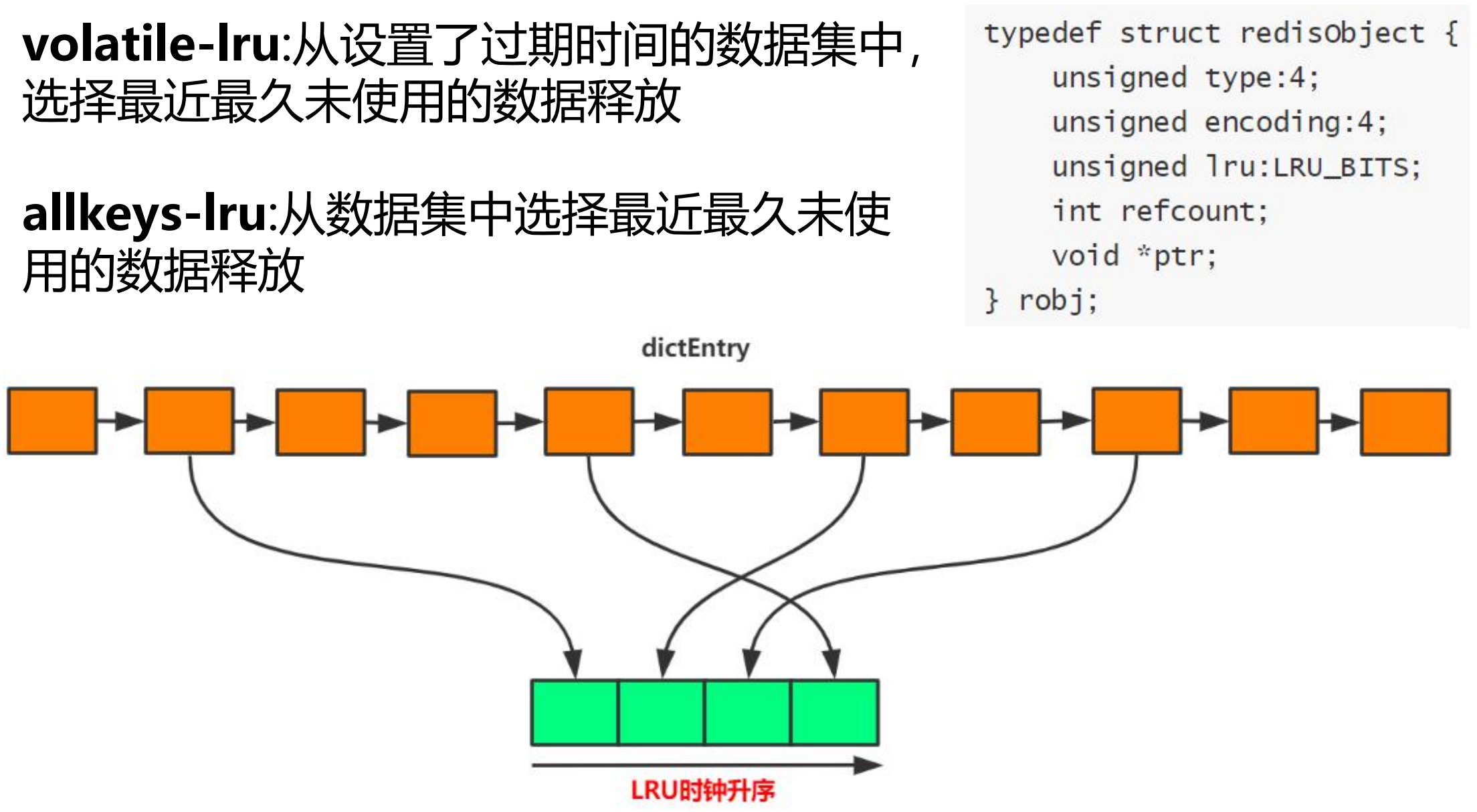
LRU
redis内存不够用了,需要淘汰一些内存。
LRU策略尽量使用volatile-lru。
- 每个redisObject中都存在一个LRU_BIITS,标识这条记录最近一次的访问时间。
- 定时清理时随机从所有数据中选出几个元素,根据LRU_BIITS做排序,然后淘汰最久没被使用的节点。
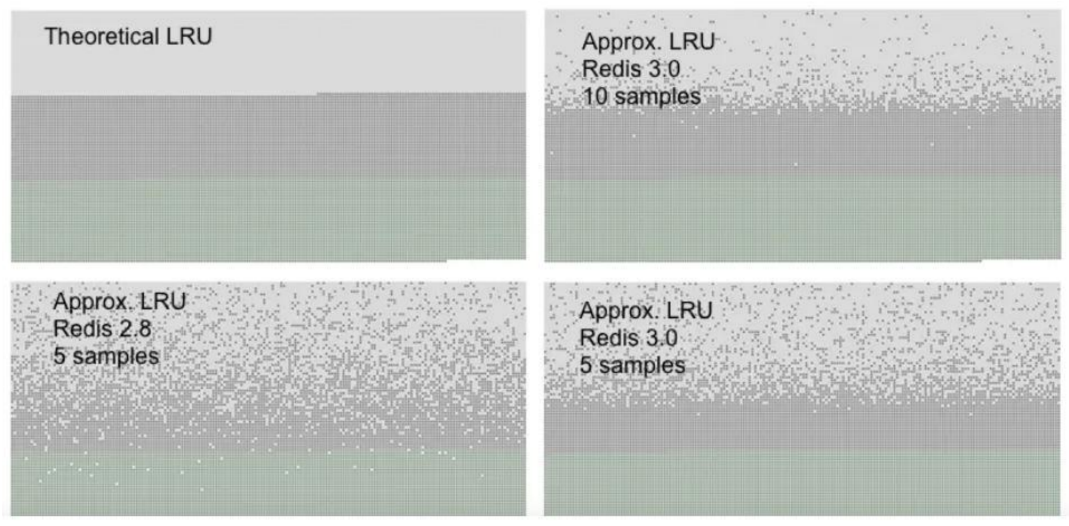
在LRU时钟升序队列为5的时候,效果不是很好,当升级到10之后深灰色的点就少很多效果就好很多了。
LFU
按照使用频率做淘汰策略,使用频率低的先淘汰。
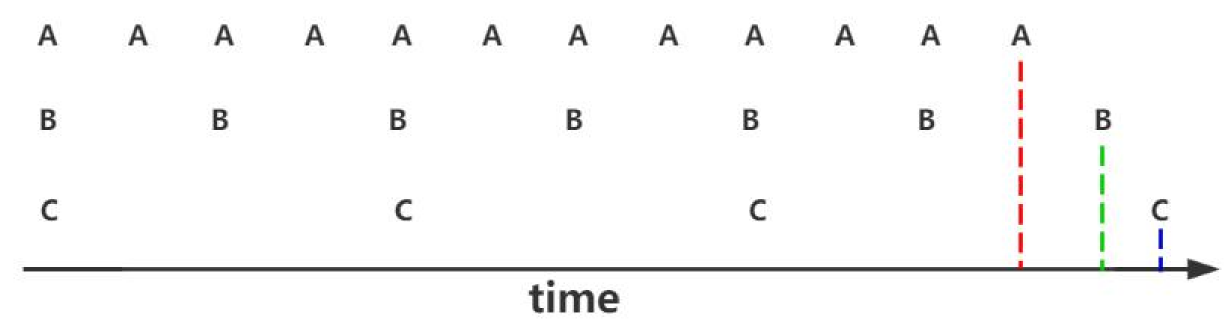
先淘汰C。
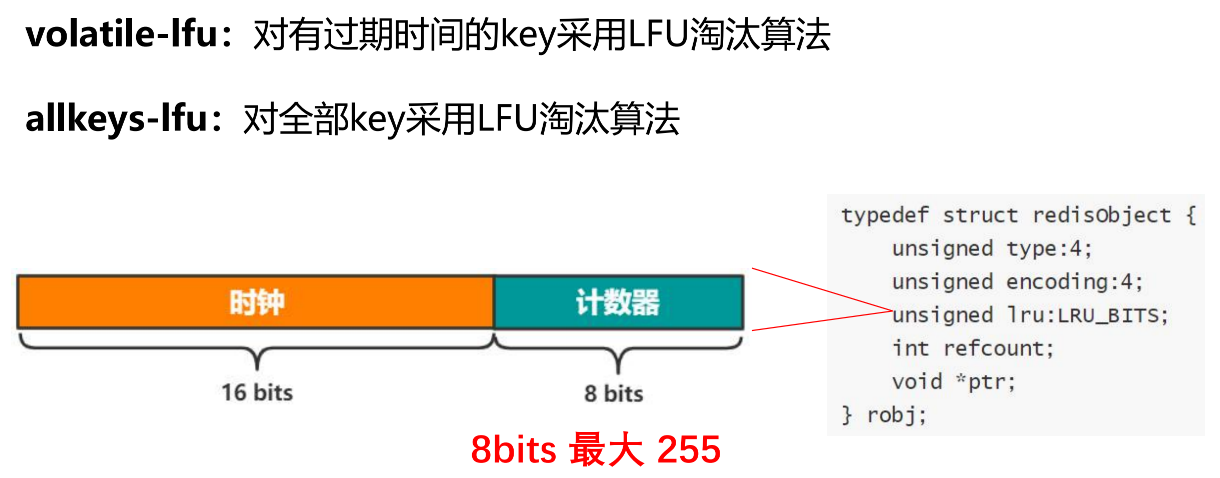
同理,LFU优先使用volatile-lfu的策略。LFU重用了LRU_BIITS字段,将他拆分为2段。
时钟:访问的计时,但是精度没原来那么高了。计数器:访问频率,一段时间内的请求数量(目前最多放255)。
因为计数器目前最大只能到255,线上实际环境存在比255大得多的业务场景。因此redis针对这个最大值做了优化。
优化方案:引入lfu-log-factor,调整计数器counter的增长速度。以及调整频率减少的速度。
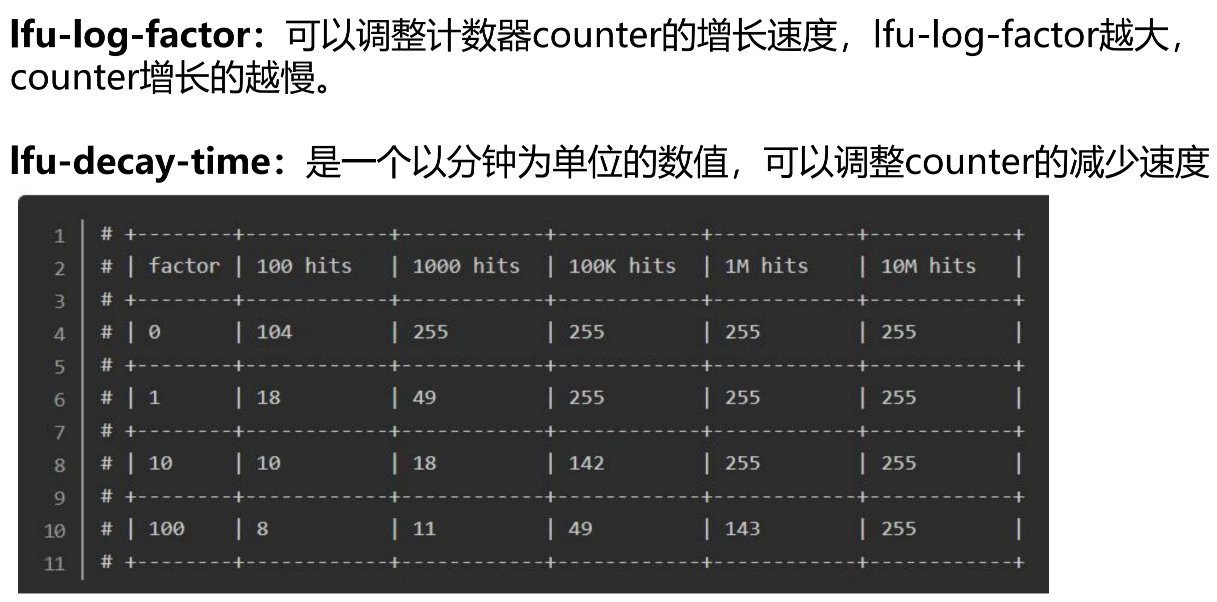
factor设置为0时,100次命中则值为104;设置为1时100次命中值为18;10为10;100为8;
Redis数据固化方式
- RDB
- 快照
- 手动/自动触发
- AOF
公司目前redis只用作缓存,允许挥发,只针对从库做AOF
RDB快照方式
- 手动方式
- 手动调用save方法:工作线程去执行,阻塞当前Redis服务器,直到备份完成RDB过程完成为止。
- 自动方式
- bgsave:后台执行,fork子进程,持久化过程由子进程负责,完成后自动结束。
- 配置项:save m n,m秒存在n次写入,触发bgsave。
- 优点:
- 对Redis性能影响低(子进程)
- 二进制压缩文件体积小(dump镜像,不是日志这种形式,所以是二进制文件体积小,压缩效果比较好)
- 数据恢复快(文件直接读到内存里就恢复了)
- 缺点:
- 由数据丢失可能 save m n,m(时间)到了但是n(次数)没到,此时服务挂了就会丢失数据。
- 备份文件版本兼容问题 数据固化到磁盘了,不同版本可能存在不同的数据组织方式,可能高版本的固化文件,低版本恢复不了。
- RDB快照方式存储流程
- 写临时文件(tmpfile)
- dump内存数据时可能存在异常,为了不影响源文件,所以先写临时文件
- 覆盖老文件
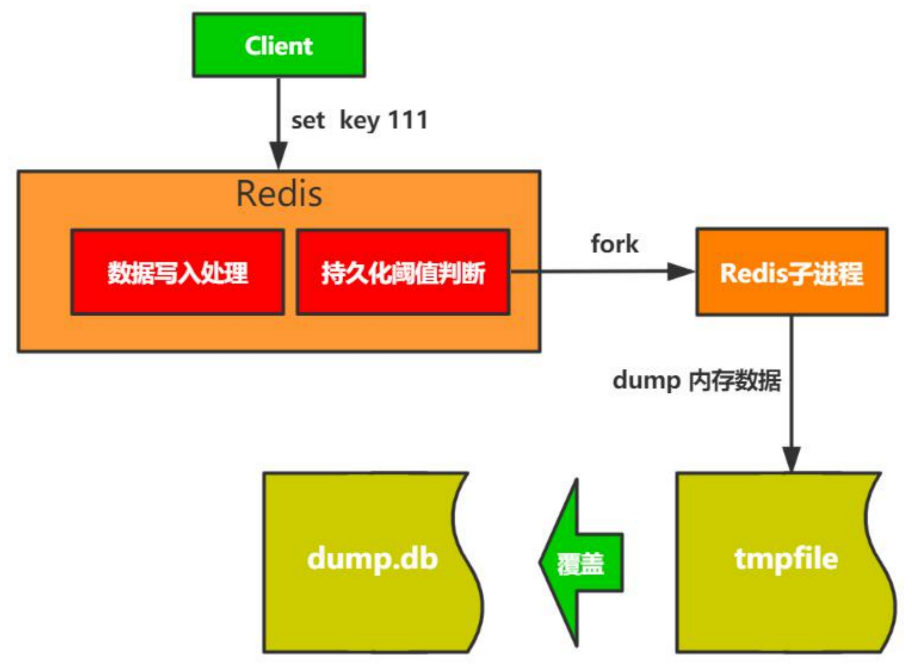
- 写临时文件(tmpfile)
AOF
- append only file
- 日志形式记录,写入指令
- 能做到实时持久化
AOF存储过程
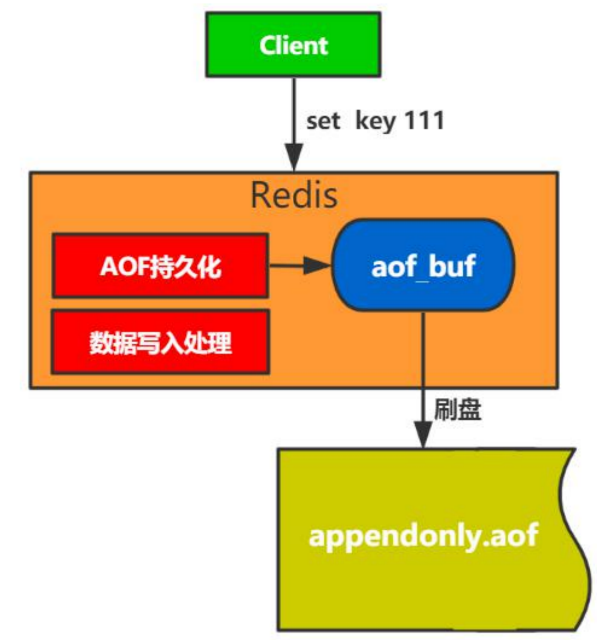
- 命令写入
- 文件同步
- 文件同步配置(一般当缓存,不会做always)

- 文件重写(一直追加,会存在无效数据,恢复的时候会做很多无效操作。因此清除无效的操作,保留最终结果。比如add update 然后又多次update 然后再delete)
- 整理压缩aof文件(清理无效数据)
- 整理方式
- 过期数据(过期的key清除掉)
- 重复更新(保留最后一条)
- 删除数据(已删除的也不需要了)
- 命令聚合
- 手动触发
- 调用bgrewriteaof命令
- 被动触发
- auto-aof-rewrite-min-size :触发aof重写的最小值
- auto-aof-rewrite-percentage :(当前大小-上次触发完大小 )/ 上次触发完大小的最小比例
- aof_current_size:当前AOF文件大小
- aof_base_size:上一次压缩完以后的大小
- 被动触发公式:
- 当前AOF size>auto-aof-rewrite-minsize && (当前AOF size - aof_base_size)/aof_base_size >= auto-aof-rewritepercentage
- 整理方式
- 整理压缩aof文件(清理无效数据)
AOF文件重写过程
- fork子进程不影响父进程处理请求
- 子进程双写(双写2个buf,aof_buf、aof_rewrite_buf),确保数据不丢失
- 如果不做双写的话只写入到aof_rewrite_buf,当写aof_rewrite_buf失败了,那数据就丢失了。
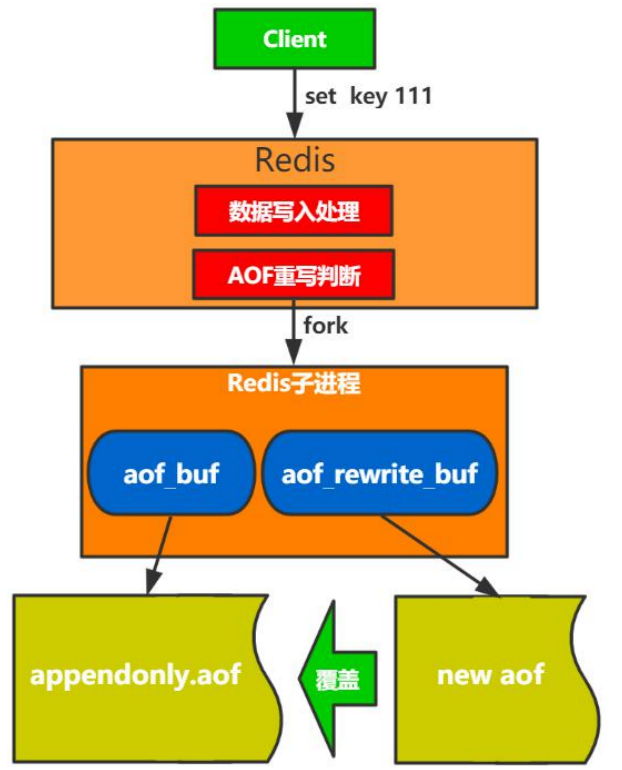
- 如果不做双写的话只写入到aof_rewrite_buf,当写aof_rewrite_buf失败了,那数据就丢失了。
Redis重启恢复过程
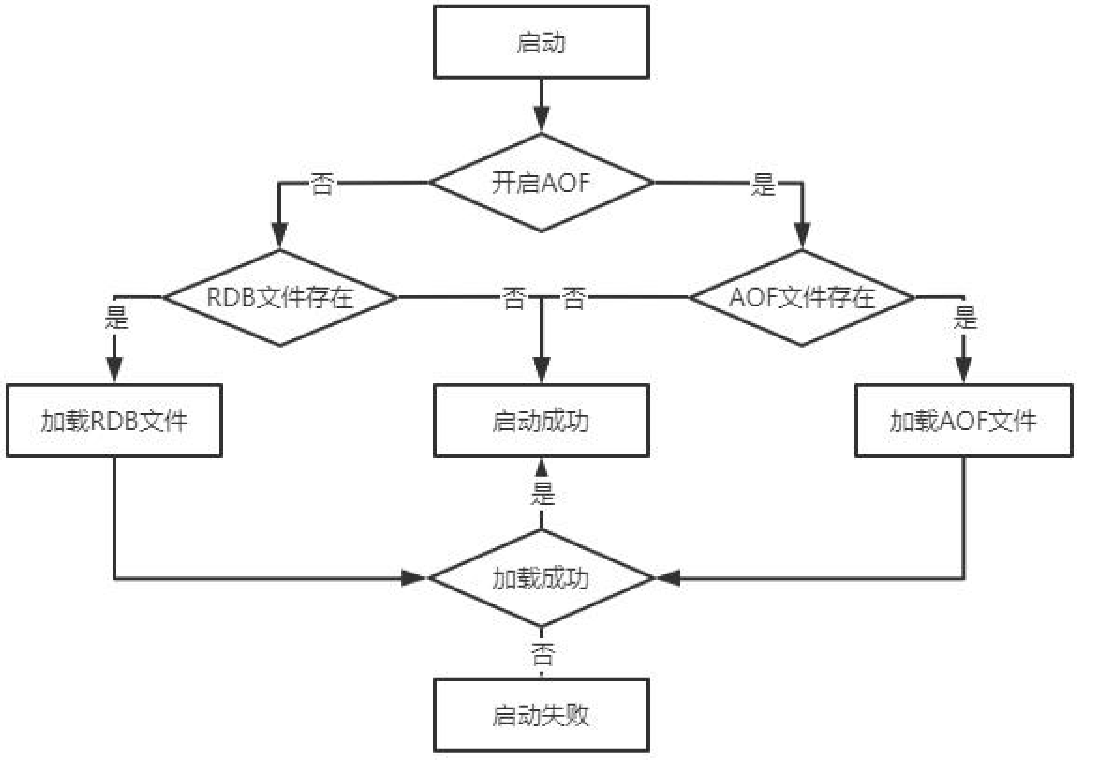
redis恢复的小坑:当开启aof,但是没有aof文件时(同时存在rdb文件),**此时启动后空数据会覆盖掉rdb文件导致文件丢失。**应当启动时先关闭aof,等rdb启动恢复完之后再打开aof。
Redis可靠性保障
可用性保障方案
- 主从模式
- 哨兵模式
- 集群模式
主从模式
- 全量同步
- Redis Slave新节点启动之后给主节点发送同步请求。
- 主节点创建快照,缓存些命令(创建快照过程中的新命令会一并缓存后续同步)。
- 将快照发送给从节点,从节点加载快照
- 将缓存的命令同步给从节点,从节点装载数据
- 增量同步:后续新的命令做增量同步
- 运行ID
- Master启动时生成
- 同步给Slave
- Slave通过运行ID与Master建立关系
- 复制偏移量
- 确定同步位置
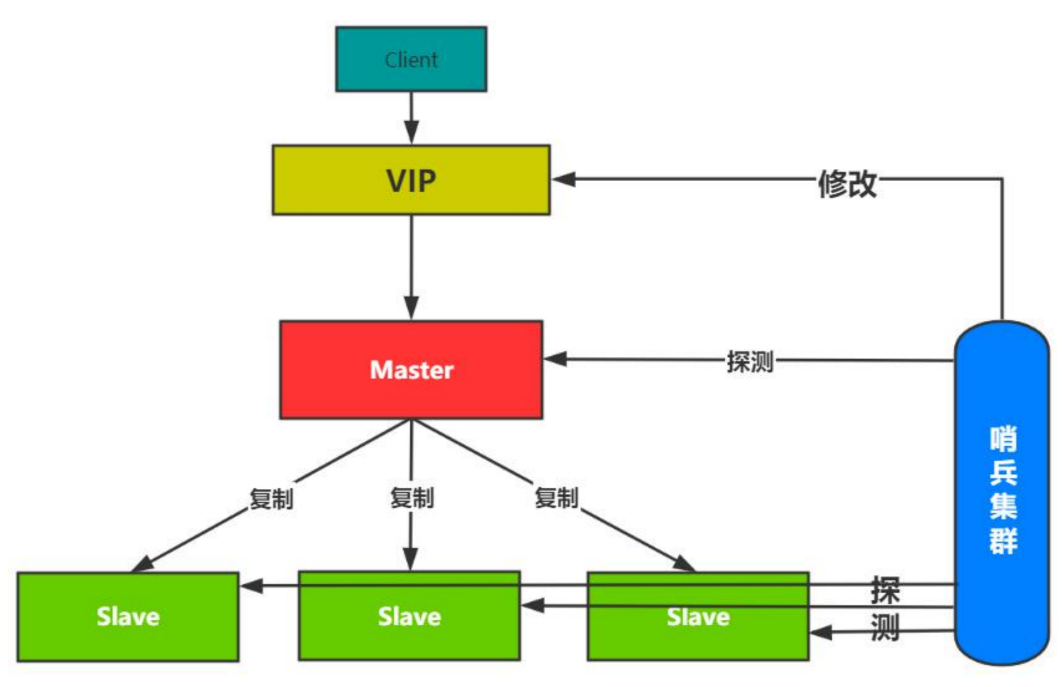
哨兵模式
- 哨兵模式可以认为就是一个监控:不断地检查Master和Slave是否运作正常;
- 提醒:发现故障通知管理员和客户端;
- 故障转移:自动主从切换,更新配置信息;
- 集群配置信息提供 :客户端应用初始化时连接Sentinel(哨兵)获取节点信息;
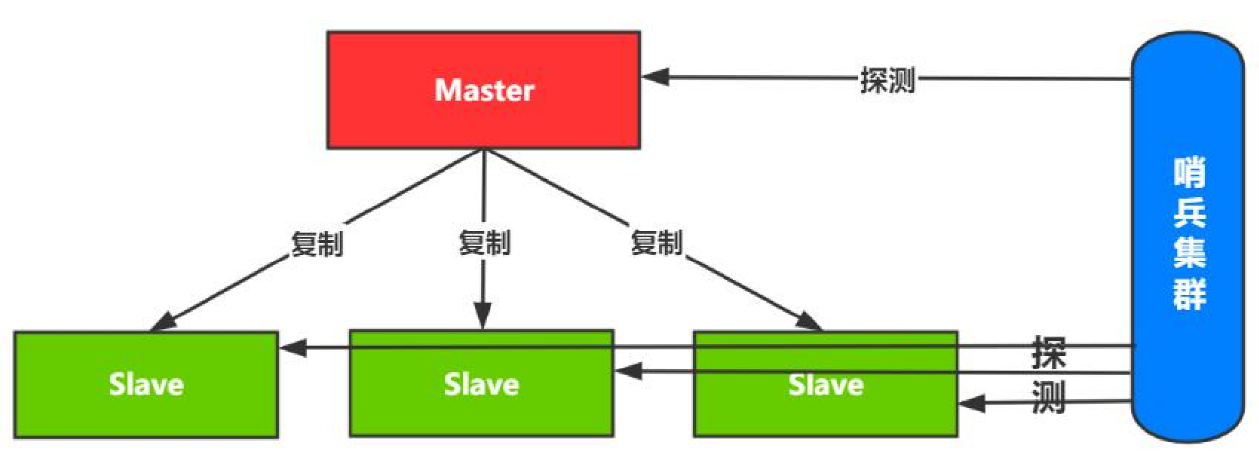
如果客户端直连master的话,当集群发生故障切换主从时,客户端还得感知变化。因此引入VIP层的概念,架构图如下:哨兵模式架构:对client完全透明
集群模式(分布式方案)
- 无需Sentinel哨兵
- 支持水平扩容
- 自动迁移
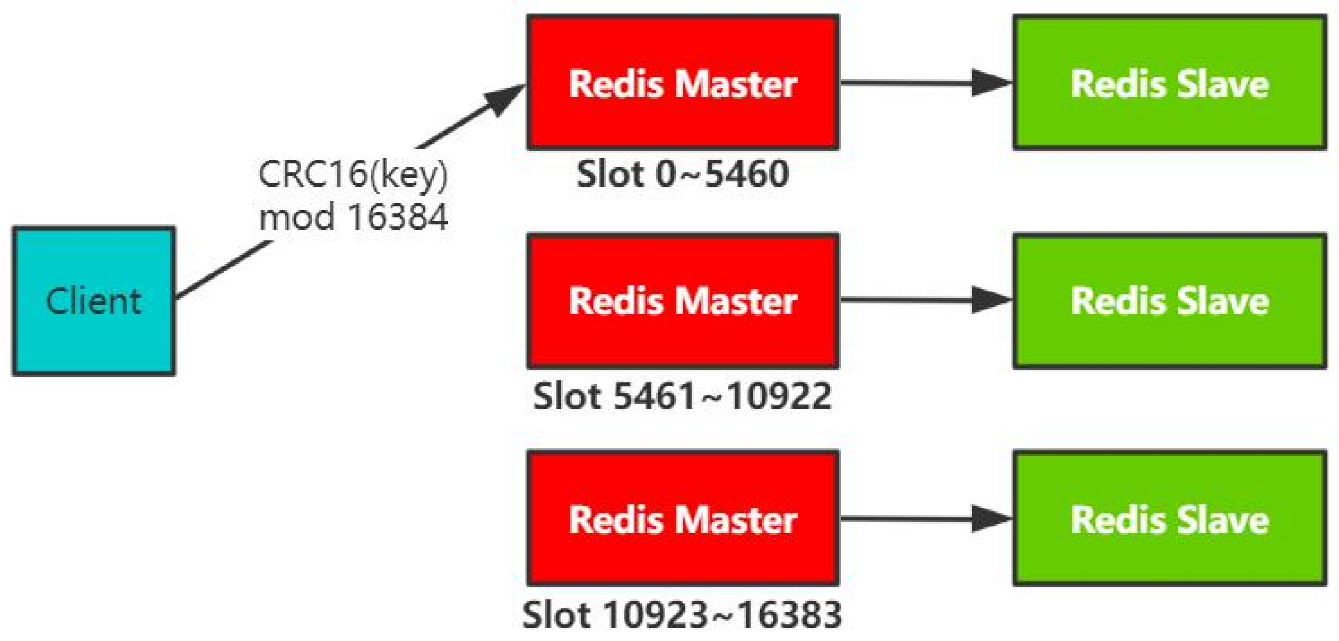
集群模式引入的问题:不支持批量操作(同时查多个key),因为多个key不知道分散在哪个槽,因此只能一个个查询。
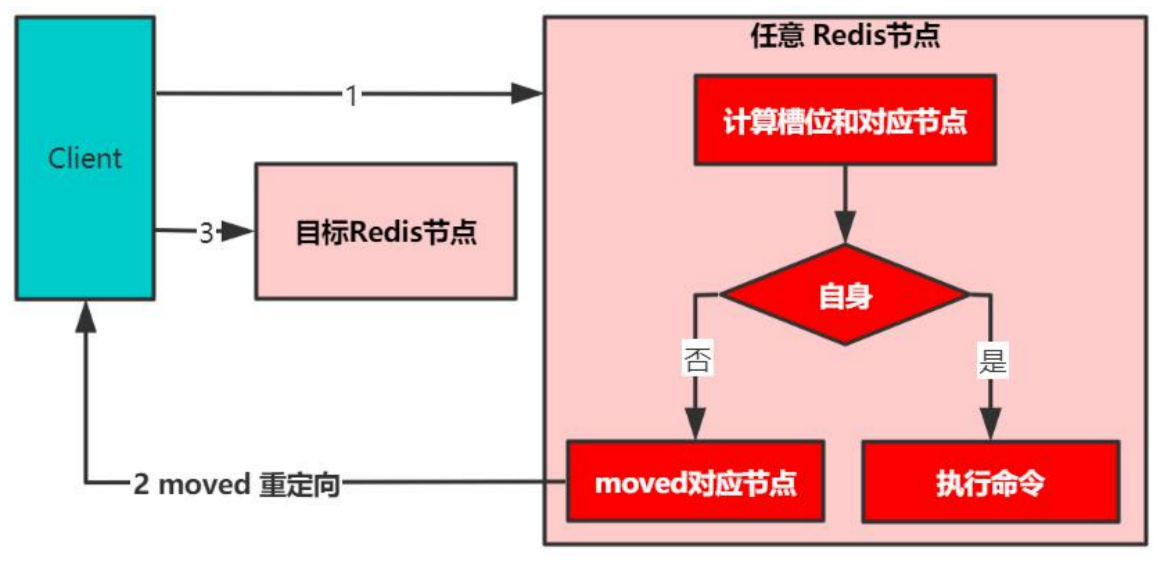
集群模式的实现: - 客户端路由
- 两次交互:给集群中的任意一个master发请求,计算key是否在自身,不是的话告诉客户端应该访问哪个节点。
- 存在性能问题:集群越多,两次交互的概率就更大。
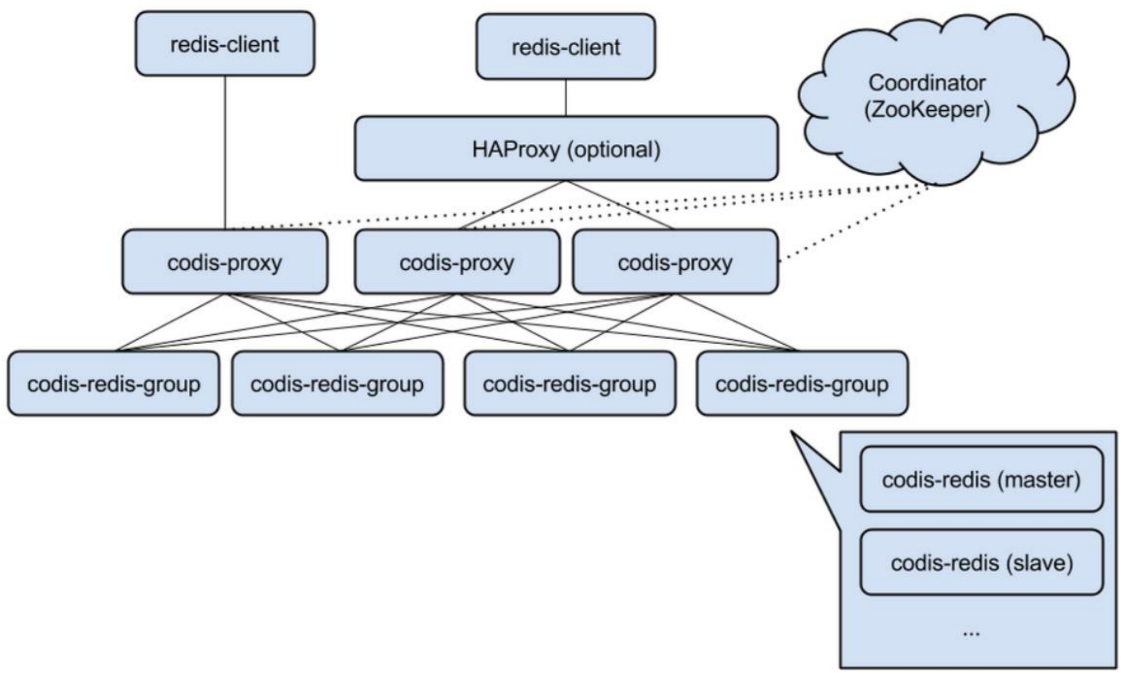
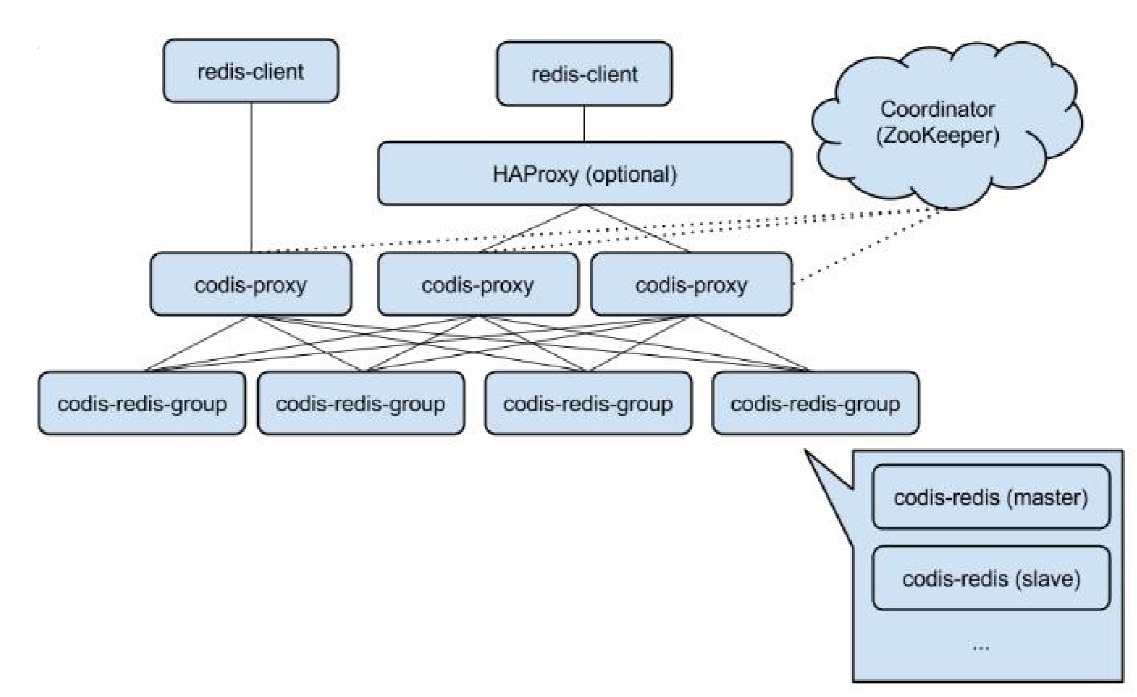
集群模式(Codis)
- codis-redis-group:一主一从
- codis-proxy:redis协议代理,对客户端来说连接的都是一样的codis-proxy(proxy做路由,不需要2次交互)
特点:
- 数据分片策略对客户端透明
- Zookeeper作为name server (存储分片信息)
- 提供支持Redis协议的Proxy
- Proxy负责请求路由
MySQL InnoDB存储原理深入剖析
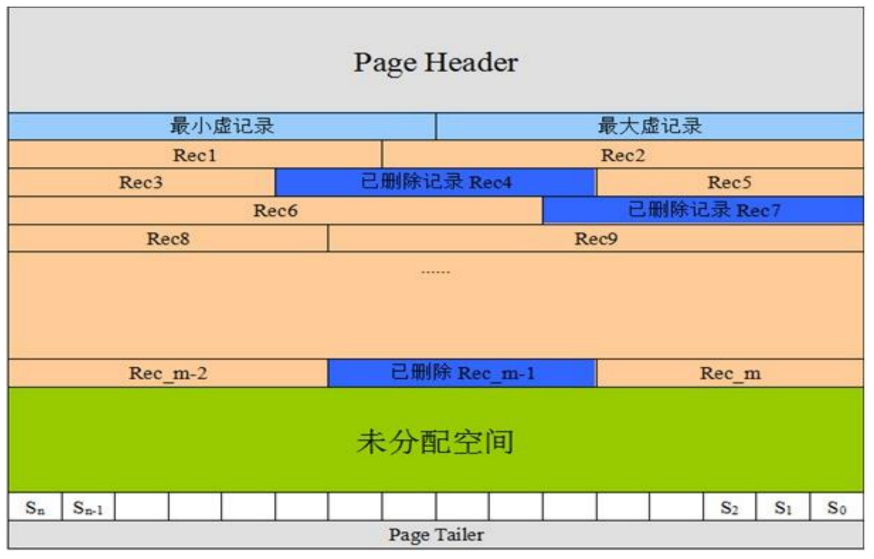
MySQL记录存储格式
- 页头:记录页面的控制信息,共占56字节,包括页的左右兄弟页面指针、页面空间使用情况等。
- 虚记录:标识页面记录的范围
- 最大虚记录:比页内最大主键还大(innoDB数据按主键聚簇索引有序)
- 最小虚记录:比页内最小主键还小
- 记录堆:行记录存储区,分为有效记录和已删除记录两种
- 自由空间链表:已删除记录组成的链表
- 未分配空间:页面未使用的存储空间
- Slot区
- 页尾:页面最后部分,占8个字节,主要存储页面的校验信息
页内记录维护
- 顺序保证:如何保证顺序?
- 插入策略:如何插入?优先往哪里写?
- 页内查询:如何定位page?
顺序保证
- 物理连续(类似数组,往前插入的话就往后挪)
- 逻辑连续(链表连接)
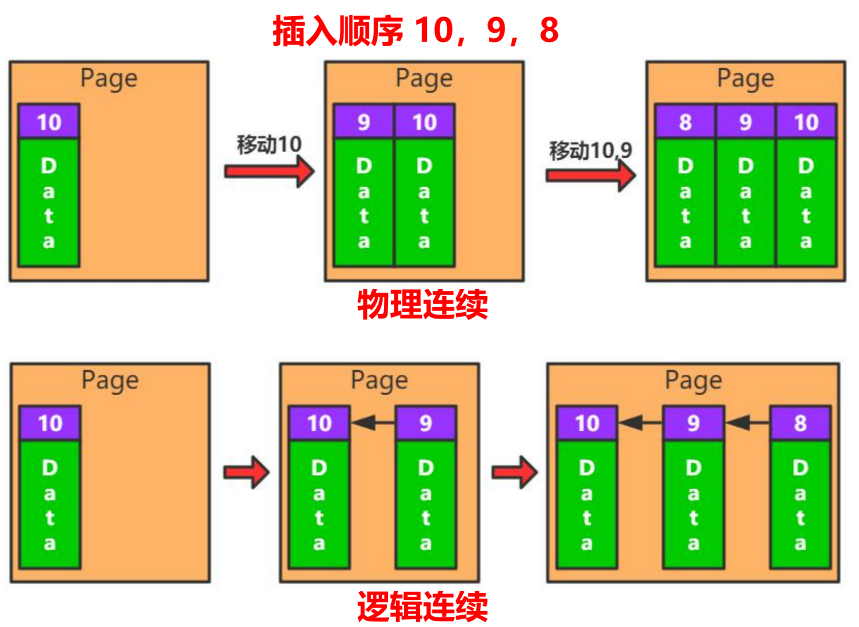
为了方便空间利用率,因此选择逻辑连续。
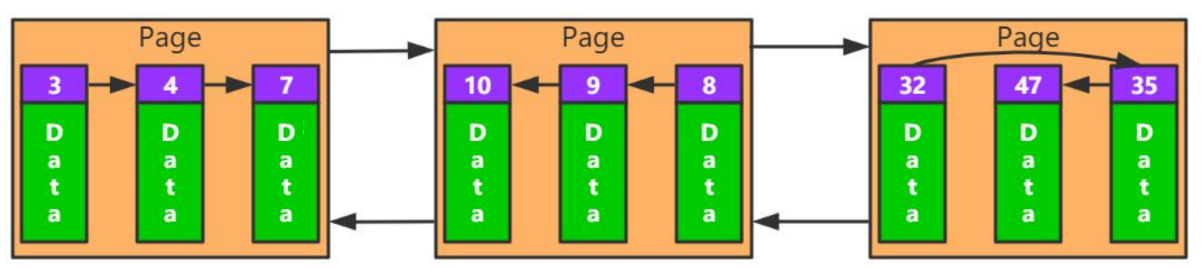
页内也是逻辑连接。
插入策略
- 自由空间链表(蓝色的已删除记录):为了增加内存利用率,优先使用该空间。
- 未使用空间:其次使用未使用
页内查询
- 遍历(直接一个个查询,性能不好)
- 二分查找(物理连续+定长),可以使用二分查找,但是mysql是逻辑连续。
- 引入Slot槽位,根据页面里的一些值的特性定义多个槽位,通过Slot去连接起来,比如S0指向Record0,Sn指向Recordn,其余指向中间。这时候找数据时,就可以先在n多个槽位内做二分查找,然后再在链表中做遍历。实现一个近似二分查找的功能。
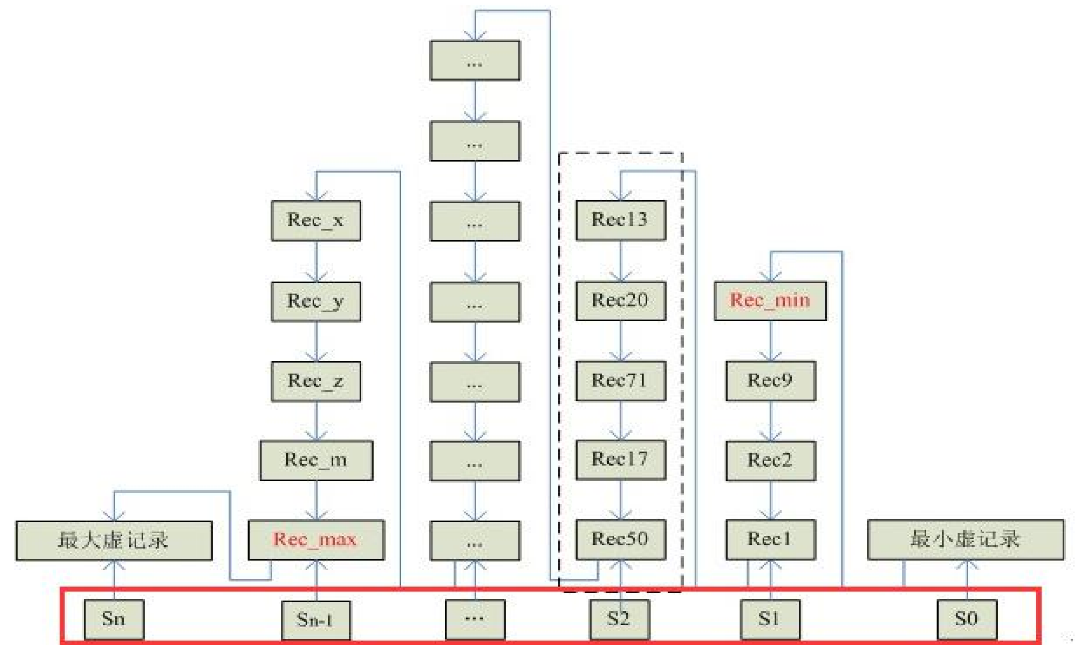
- 引入Slot槽位,根据页面里的一些值的特性定义多个槽位,通过Slot去连接起来,比如S0指向Record0,Sn指向Recordn,其余指向中间。这时候找数据时,就可以先在n多个槽位内做二分查找,然后再在链表中做遍历。实现一个近似二分查找的功能。
变长数据存储-InnoDB
- PageSize 16KB;
- 每页至少两条数据
- 单行最大8KB;
- 最多存储10个大字段;
- 数据段最大768;
- 超出部分存储在溢出页;
- (768+20)*10 < 8K; (最大10个的原因)
- VARCHAR
- 1或2个字节描述字符长度;
- 实际内容存储在长度字节之后;如下
VARCHAR(255) 1个长度字节+内容
VARCHAR(256) 2个长度字节(一个不够了)+内容
MySQL InnoDB索引实现原理及使用优化分析
索引原理分析
- 聚簇索引(主键索引和数据放在一起)
- 二级索引(非聚簇索引都叫二级索引,key对应的data是主键值,要回到聚簇索引拿值)
- 联合索引
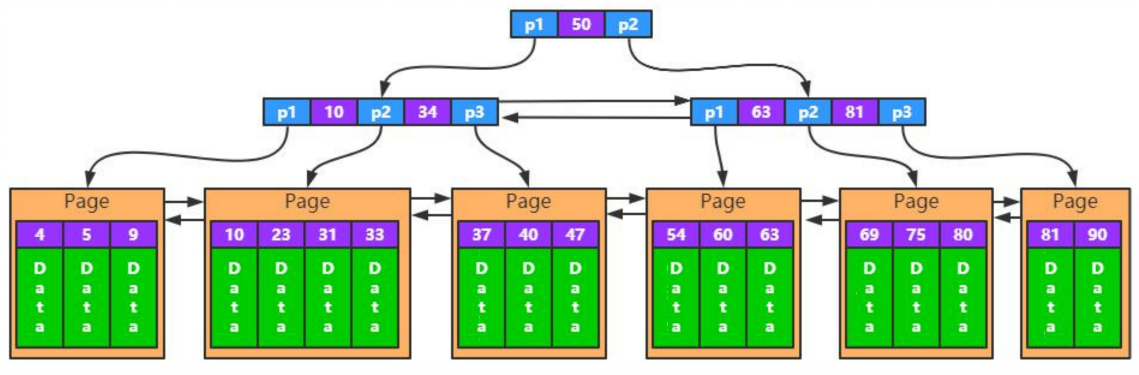
聚簇索引特性
- 数据存储在主键索引中
- 数据按主键顺序存储
- 自增主键 VS 随机主键??如何选择
- 自增主键:顺序写,没有页分裂的情况。
- 随机主键:
二级索引特性
- 除主键索引以外的索引都叫做二级索引
- 叶子中存储主键值(Primary Key)
- 一次查询需要走两遍索引(回查聚簇索引)
- 主键大小会影响所有索引的大小(主键如果很大的话,二级索引的叶子结点data就会很大)
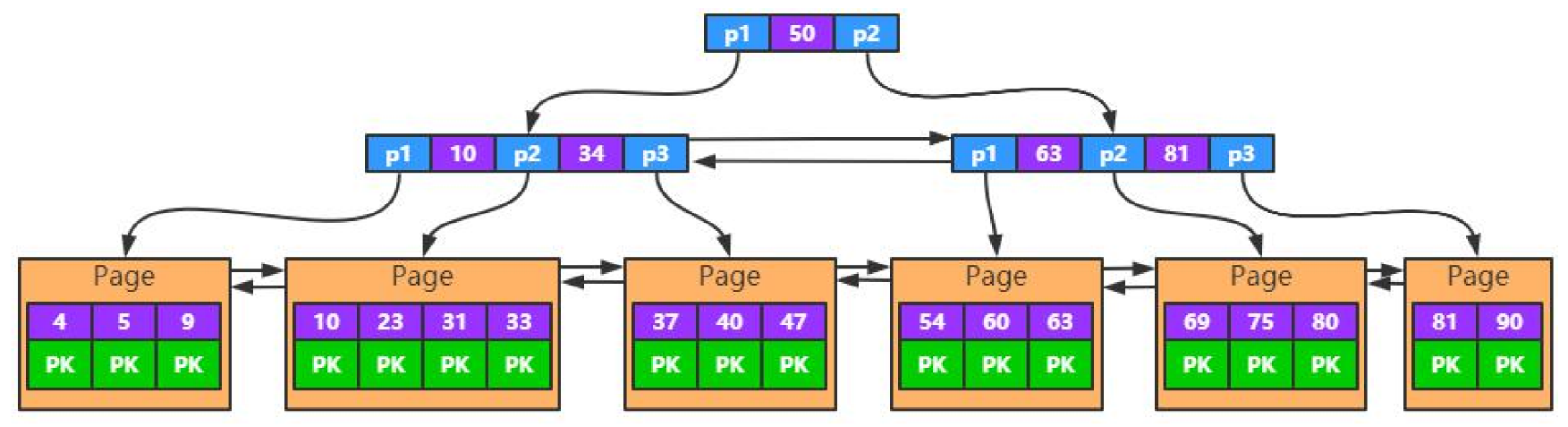
联合索引特性
- Key由多个字段组成
- 最左匹配原则,先匹配第一个
- 一个索引只创建一棵树,如下图
- 按第一列排序,第一列相同按第二列排序
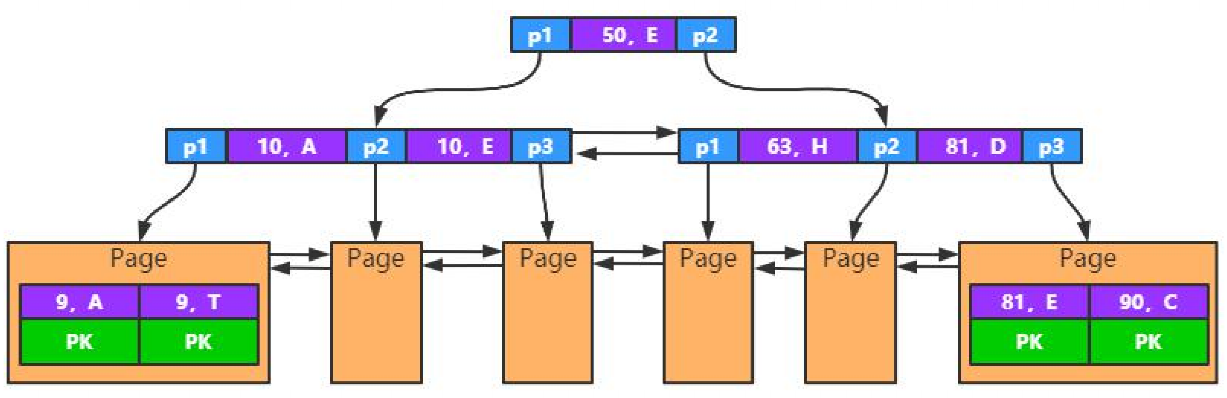
如果不是按照最左开始查找,无法使用索引,不能跳过中间列。某列使用范围查询,后面的列不能使用索引。如a、b、c为联合索引,当用where b=xxx,c=xxx来查询的话是无法使用联合索引的;where a=xxx,c=xxx 只能使用a=xxx;where a=xxx,b>xxx,c=xx 这样也无法用上c的索引
索引使用优化分析
- 存储空间
- 主键选择
- 联合索引使用
- 字符串索引
存储空间
- 索引文件大小是由什么决定的?
- 字段大小->页内节点个数->决定page的数量->树的层数;
16KB -> 一个PageSize
BIGINT类型主键3层可以存储约10亿条数据
16KB/(8B(key-主键数据)+8B(指针))=1K
10^3 * 10^3 * 10^3 = 10亿
32字节主键3层可以存储6400W
主键选择
- 自增主键,顺序写入,效率高;
- 随机主键,结点分裂、分裂后就需要做数据移动;
**自增主键:写入磁盘利用率高,每次查询走两级索引;(业务键做查询,查询到PK后回查数据) **
随机主键:写入磁盘利用率低,每次查询走两级索引;
业务主键:写入、查询磁盘利用率都高,可以使用一级索引;(用递增的业务主键会比自增主键更好,推荐使用)
联合主键:影响索引大小,不易维护,不建议使用;
联合索引使用
- 按索引区分度排序(索引区分度高的放前面,第一个条件能筛掉80%的数据,剩下的就不多了,区分度就高)
- 覆盖索引(查询的结果直接在联合索引中)
字符串索引
- 字符串的比较是按照字节去比较,比如abc和abb比较,先aa比较,再bb比较,再cb比较。
- 若要设置成索引的话,就需要设置合理的长度
- 不支持%开头的模糊查询(直接全表扫描)
MySQL InnoDB存储引擎内存管理
InnoDB内存管理
- 预分配内存空间(频繁的分配和销毁内存空间开销比较大,因此做预分配)
- 数据以页为单位加载
- 数据内外存交换(磁盘数据加载到空页,内存数据发生变更同步到磁盘)
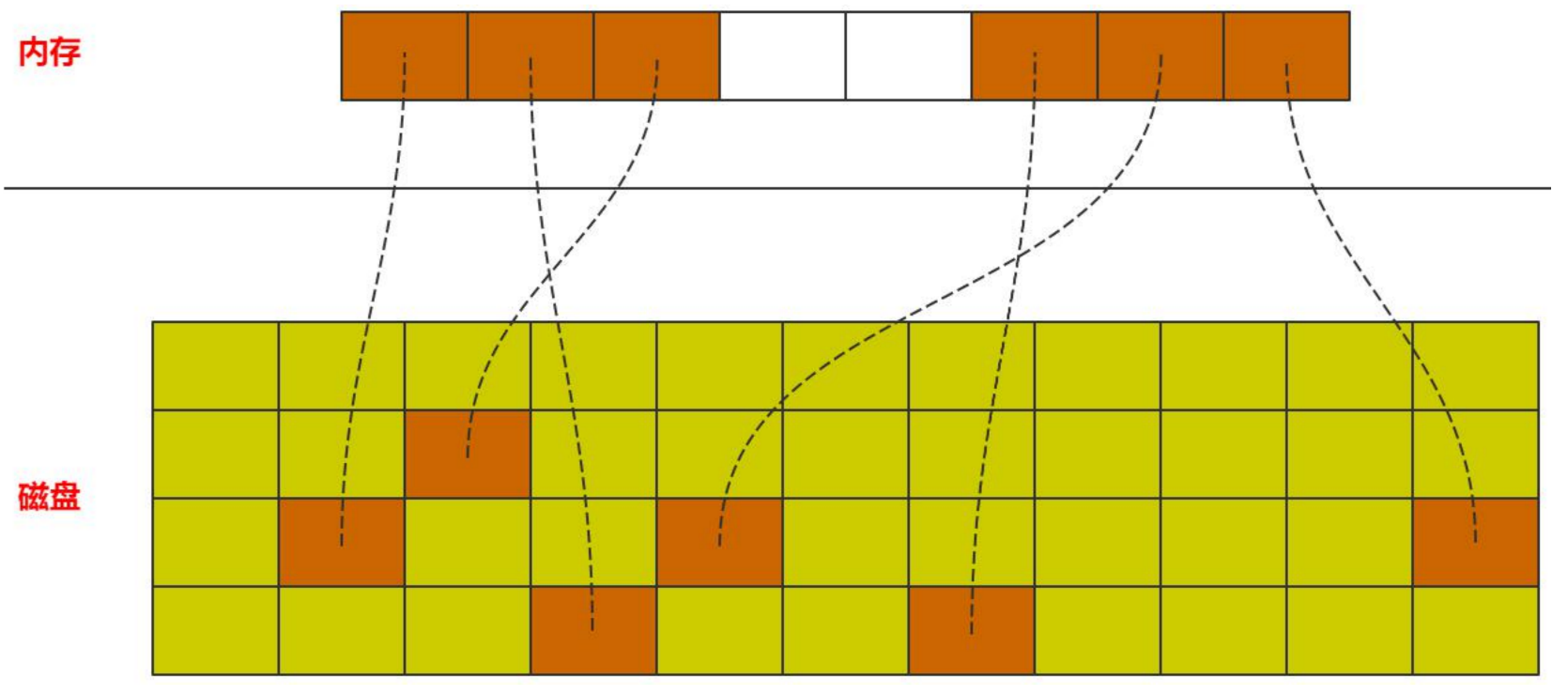
InnoDB内存管理—技术点
- 内存池(预留一片空间作为预分配空间)
- 内存页面管理
- 页面映射(内存页和磁盘页映射)
- 页面数据管理
- 数据淘汰(内存页空间小于磁盘页,当要加载新数据时且内存页满情况下,需要淘汰老的内存页数据)
- 内存页都被使用
- 需要加载新数据
InnoDB内存管理—页面管理
- 空闲页(无数据页)
- 数据页(有数据页,只用于读,暂时没有写入,随时可淘汰)
- 脏页(page内有更新或者插入)
InnoDB内存管理—页面淘汰
- LRU
每一个节点代表每个页面。访问哪个页面,该页面就变成链表头,没有空间了就在尾部淘汰页。
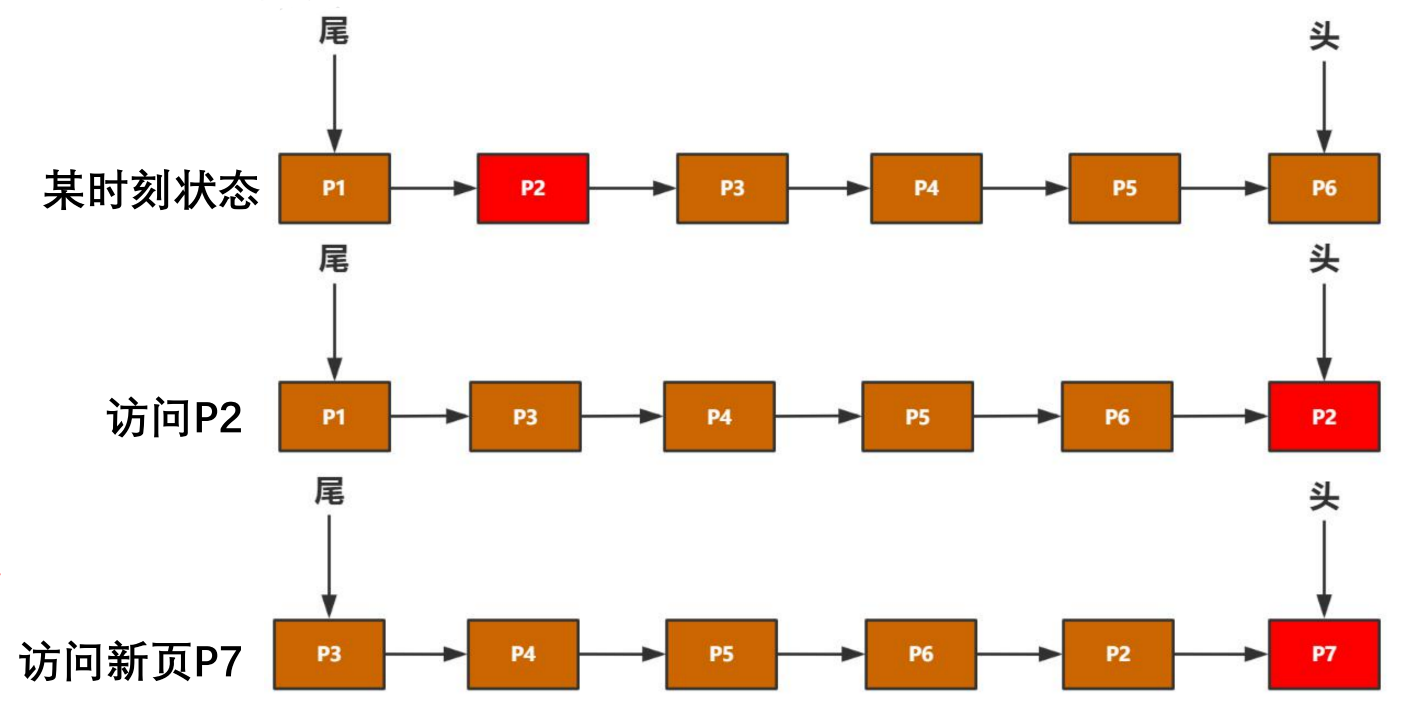
思考: 全表扫描对内存的影响?
对于一个数据库来说,不能简单做LRU,当全表扫描一次后,内存里的数据一直滚动清除,只剩下某一张表的数据。
解决问题:避免热数据被淘汰
思路:
- 访问时间 + 频率?lru+lfu
- 两个LRU表?冷热分离
MySQL是如何解决的…?
MySQL内存管理
- Buffer Pool
- 预分配的内存池
- Page
- Buffer Pool的最小单位
- Free list
- 空闲Page组成的链表
- Flush list
- 脏页链表
- Page hash 表
- 维护内存Page和文件Page的映射关系
- 查询数据先从内存中找,找不到再去磁盘中查找
- LRU List(所有有数据页都在这个链表下)
- 内存淘汰算法
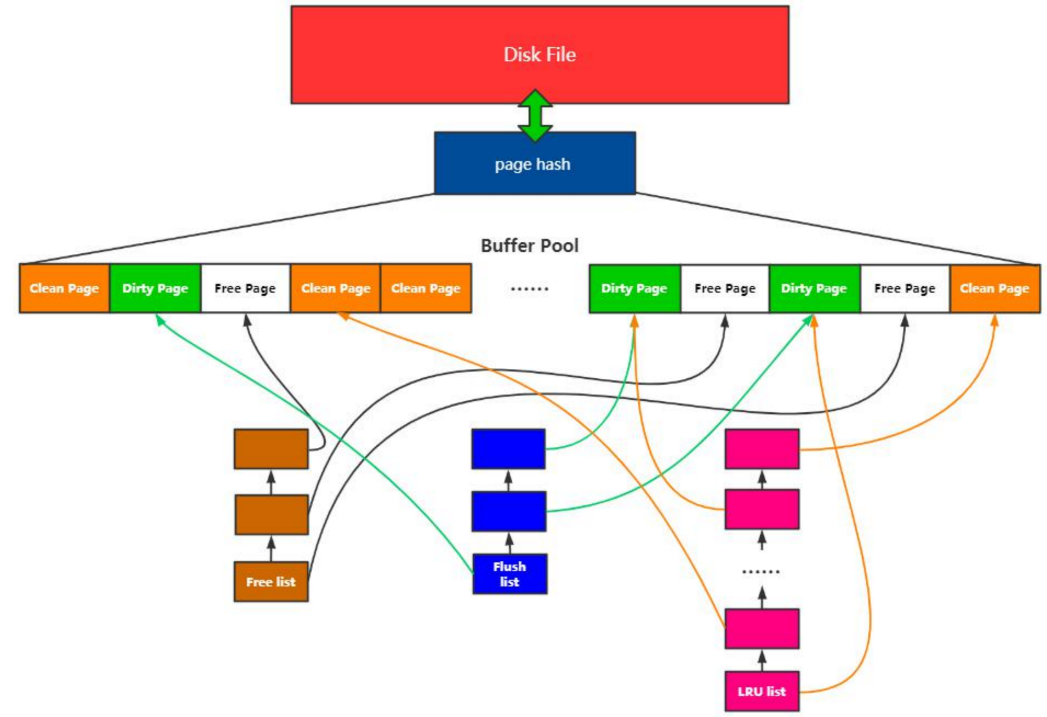
LRU
内存管理操作:
- 页面装载
- 磁盘数据到内存
- 页面淘汰
- 位置移动(new和old间的位置移动)
- LRU_new的操作
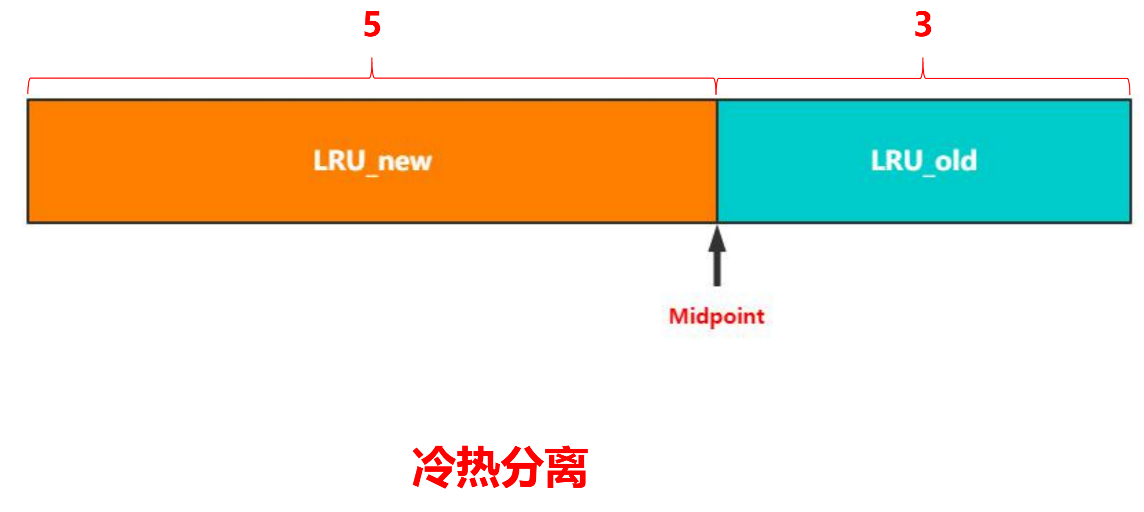
lru分了两段
- LRU_new
- LRU_old
- Midpoint(指向链表中间,左边new,右边old)
- 分成两段的初衷就是为了做冷热分离,若发生全表扫描,则只在old里发生淘汰,不在new里做淘汰。
页面装载
- 磁盘数据到内存
-
- 从空闲链表取出空闲页
-
- 写入映射关系
-
- 链入LRU-old(新数据先放到old中)
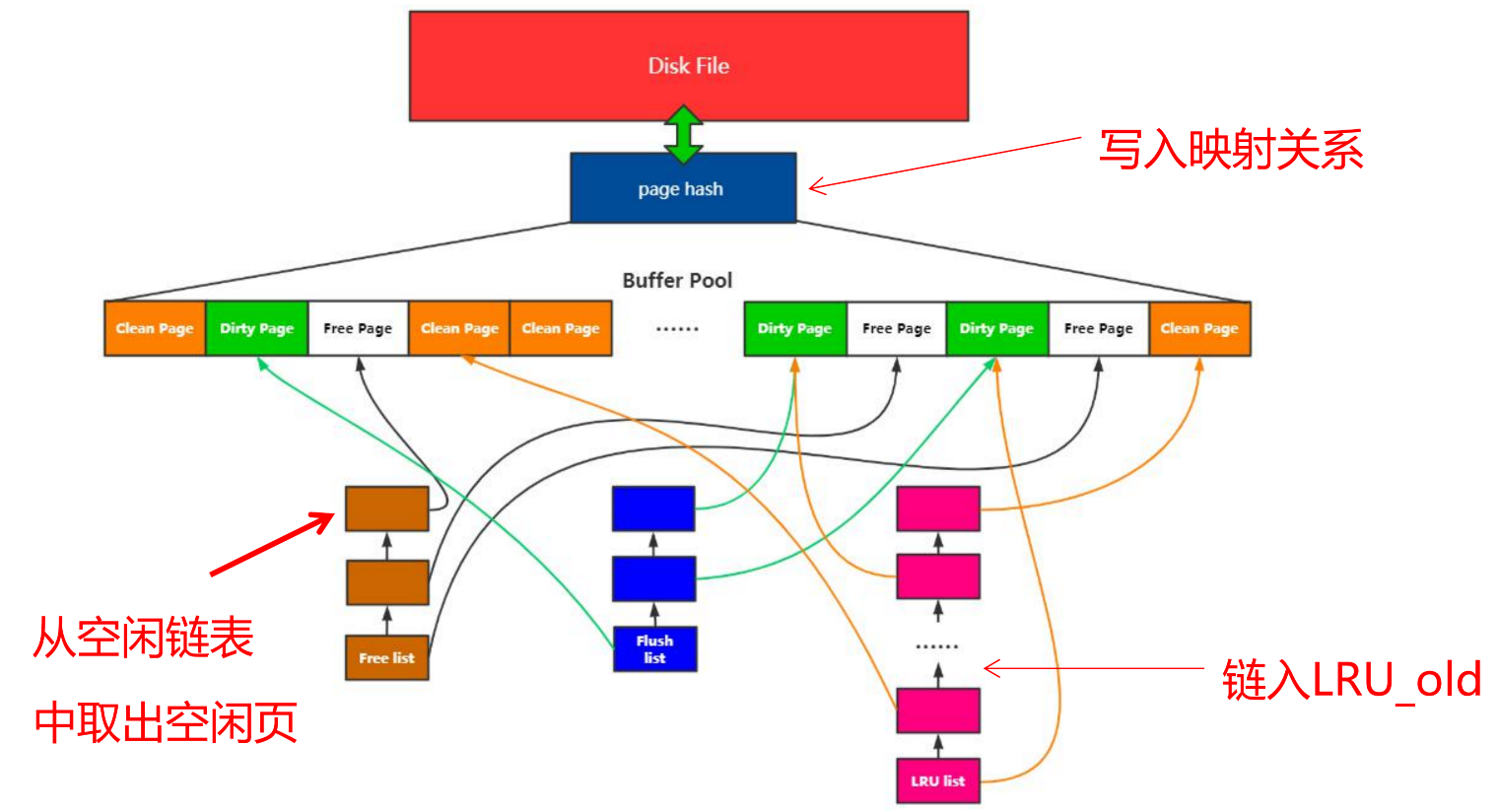
- 链入LRU-old(新数据先放到old中)
页面淘汰
- LRU尾部淘汰
- Flush LRU淘汰:LRU链表中将第一个脏页刷盘并“释放”
- 释放:淘汰完后直接放到FreeList中(MySQL5.x做的优化,以前是放到LRU尾部)
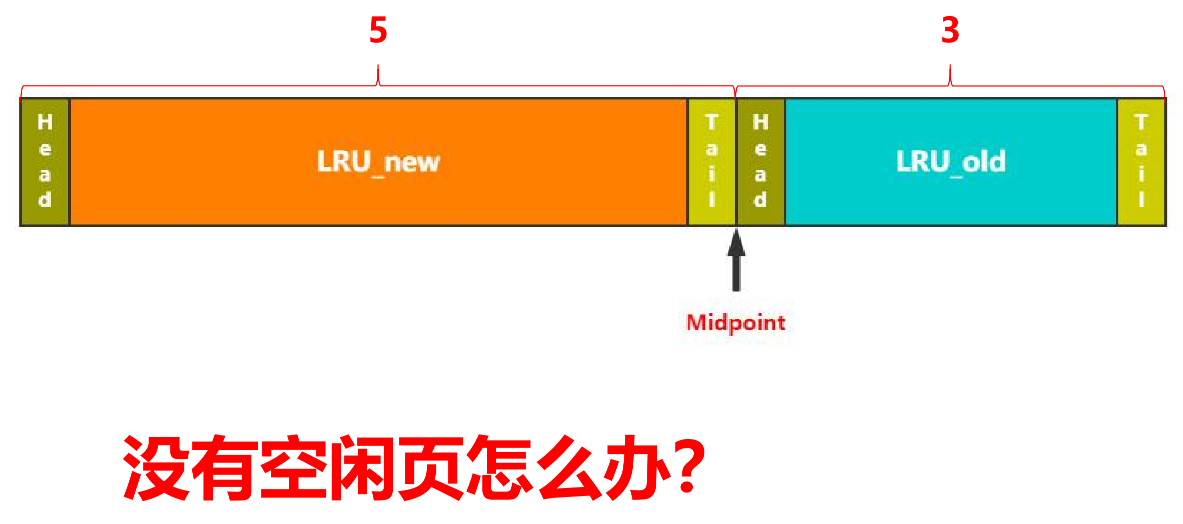
没有空闲页时:
Free list中取 > LRU List中淘汰 (如果取不到Free list)> LRU Flush(如果LRU不能淘汰,则从后往前找找到第一个脏页然后释放)
- 释放:淘汰完后直接放到FreeList中(MySQL5.x做的优化,以前是放到LRU尾部)
位置移动(new和old间的位置移动)
-
old到new
- 移动时机思考
- 假设一个page有很多条记录,一次全表扫描就会短时间内多次访问这个page,那是否该放到new?
- innodb_old_blocks_time:old区存活时间,大于此值,有机会(虽然存活时间长,但是没被访问的话就没法触发进入new)进入new区
- 每次访问该page时判断now-放入时间
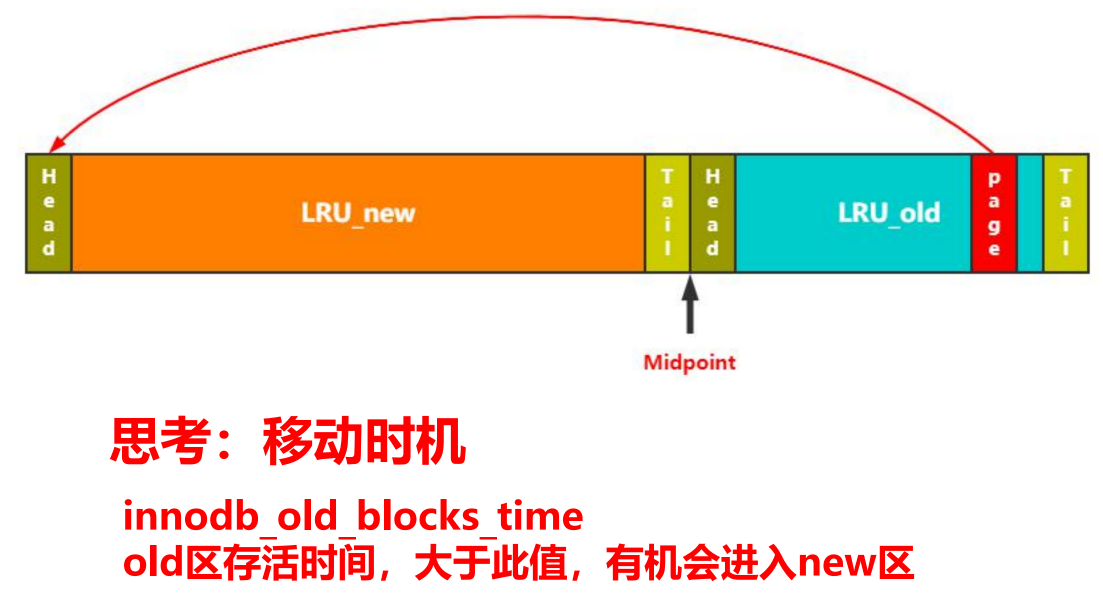
- 移动时机思考
-
new到old(热数据到冷数据)
- 当发生old -> new,或者old淘汰,都会发生链表长度变更。只要在每次链表长度发生变更时保持好Midpoint:指向5/8位置,就实现了new到old的变更。
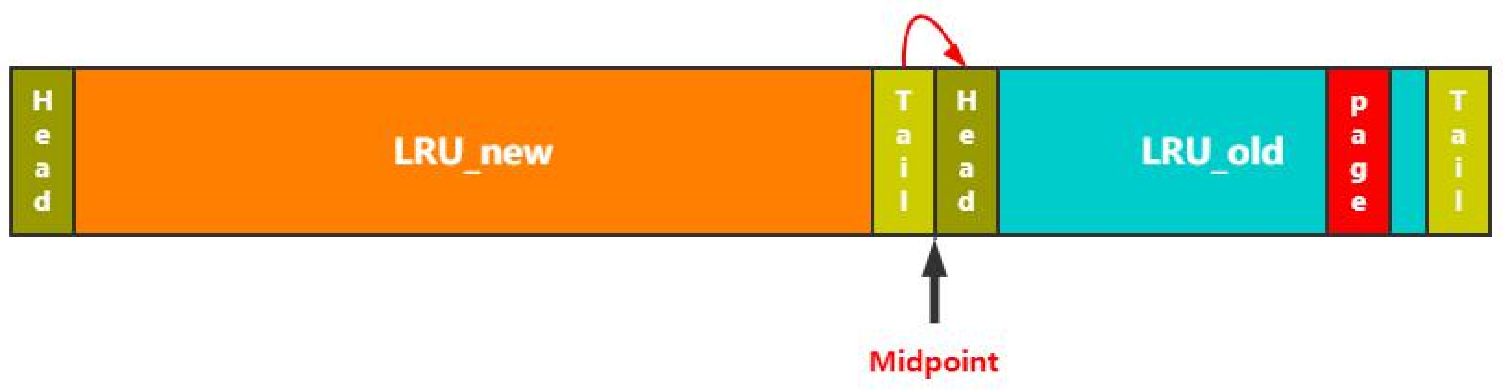
- 当发生old -> new,或者old淘汰,都会发生链表长度变更。只要在每次链表长度发生变更时保持好Midpoint:指向5/8位置,就实现了new到old的变更。
LRU_new的操作
LRU_new内部的一些操作:链表操作效率很高,每次有新的针对LRU——new访问的时候将LRU_new里的节点移动到表头Head?
因为链表移动需要加锁,所以频繁移动会有性能开销,因此针对移动MySQL做了策略。
MySQL设计思路:减少移动次数
两个重要参考:
1、freed_page_clock:Buffer Pool淘汰页数(每淘汰一个页freed_page_clock就++)
2、LRU_new长度1/4
当前freed_page_clock - 上次移动到Header时freed_page_clock > LRU_new长度1/4
从上次成为Header到现在,整个内存发生了多少次的页面淘汰。 如果淘汰次数大于LRU_new长度1/4,就认为可能比较危险了,需要再次将节点移动到头。
MySQL事务管理机制原理
MySQL事务基本概念
- 事务特性
- 并发问题
- 隔离级别
事务特性
- A(Atomicity原子性):全部成功或全部失败
- I(Isolation隔离性):并行事务之间互不干扰
- D(Durability持久性):事务提交后,永久生效
- C(Consistency一致性):通过AID保证
并发问题(找相关的demo资料)
- 脏读(Drity Read):读取到未提交的数据
- 不可重复读(Non-repeatable read):两次读取结果不同
- 幻读(Phantom Read):select 操作得到的结果所表征的数据状态无法支撑后续的业务操作
隔离级别
- Read Uncommitted(读取未提交内容):最低隔离级别,会读取到其他事务未提交的数据,脏读;
- Read Committed(读取提交内容):事务过程中可以读取到其他事务已提交的数据,不可重复读;
- Repeatable Read(可重复读):每次读取相同结果集,不管其他事务是否提交,幻读;
- Serializable(串行化):事务排队,隔离级别最高,性能最差;
MySQL事务机制原理分析
- MVCC
- undo log
- redo log
MVCC
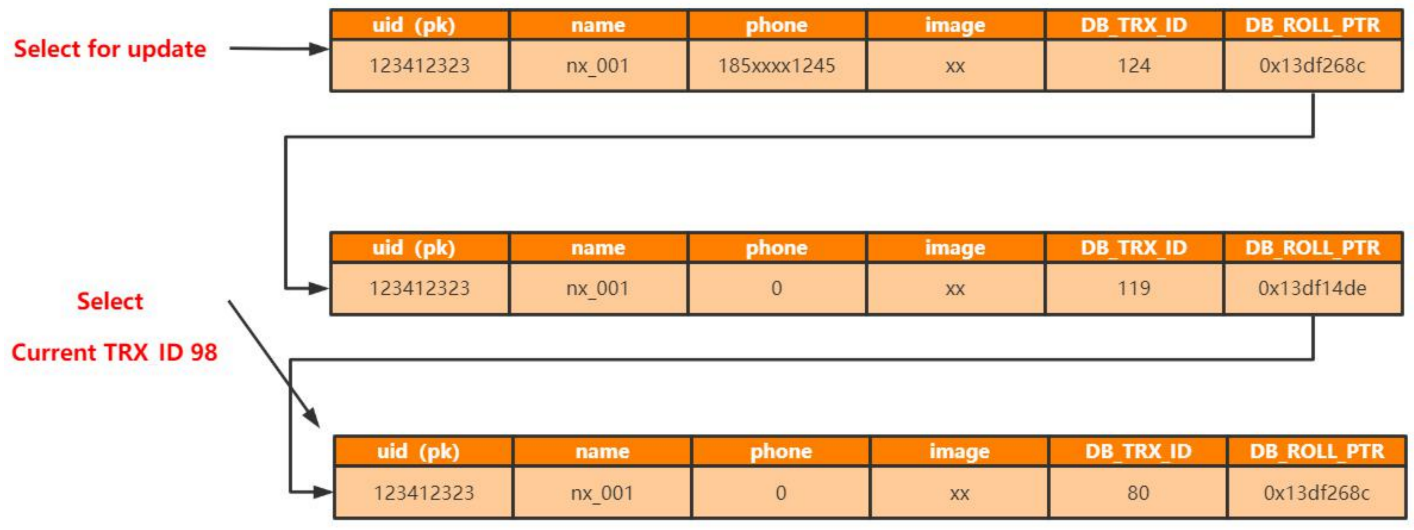
多版本并发控制,解决读-写冲突问题,通过隐藏列(DB_TRX_ID-,DB_ROLL_PTR)实现。
隐藏列:
-
DB_TRX_ID:不管是记录创建插入、还是更新,都在一个事务内。MySQL InnoDB事务id全局唯一,全局递增。
-
DB_ROLL_PTR:回滚指针,指向上一个记录。
-
当前读(读数据的最新版本,加锁)
-
快照读(有一个比较策略,判断本次要读的是哪个历史的某个版本)
-
可见性判断
- 查询时创建快照这一刻,还存在未提交的事务,那看不到本次事务。
- 创建快照之后创建的事务,本次查询也看不到。
-
Read View(可见性判断的实现通过Read View来做)
- 快照读 活跃事务列表
- 在select这一刻会把当前活跃的事务id(已经创建的事务单未提交的)全部取出来。
- 获取列表中最小事务ID
- 获取列表中最大事务ID(不存在的事务ID,当前最大的事务+1)
- 快照读 活跃事务列表
查询的时候判断能否看到这条记录的逻辑:
- 查询到db里的记录并获取到TX_ID,如果比活跃事务链表里最小的还小,那db里这条记录可见。
- 如果查询到的记录的TX_ID比最大的还大,那最新数据是在查询生成快照这一刻之后生成的事务,本次快照查询就查不到db里的这条记录,然后通过回滚指针找上一个版本。
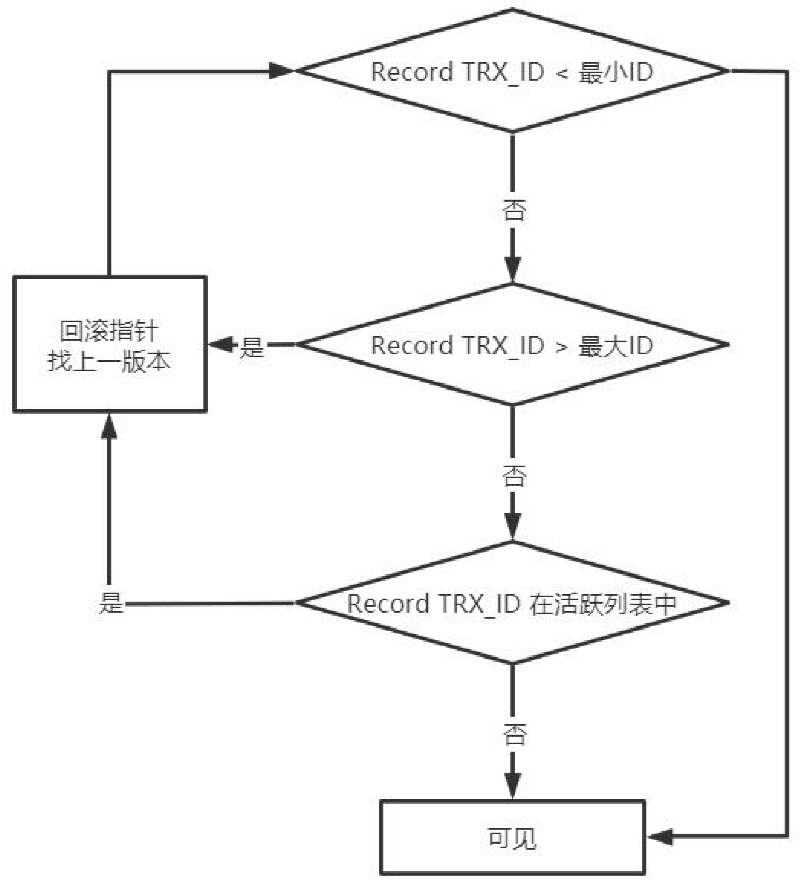
MVCC需要历史数据的支持,历史数据是怎么支持的?存储结构是如何的?
请看下面undo log和redo log。
undo log
- 回滚日志:用来做事务回滚(保存个历史版本)
- 保证事务原子性(用回滚日志来保证都成功或者都失败)
- 实现数据多版本
- delete undo log:用于回滚,提交即清理;
- update undo log:用于回滚,同时实现快照读,不能随便删除
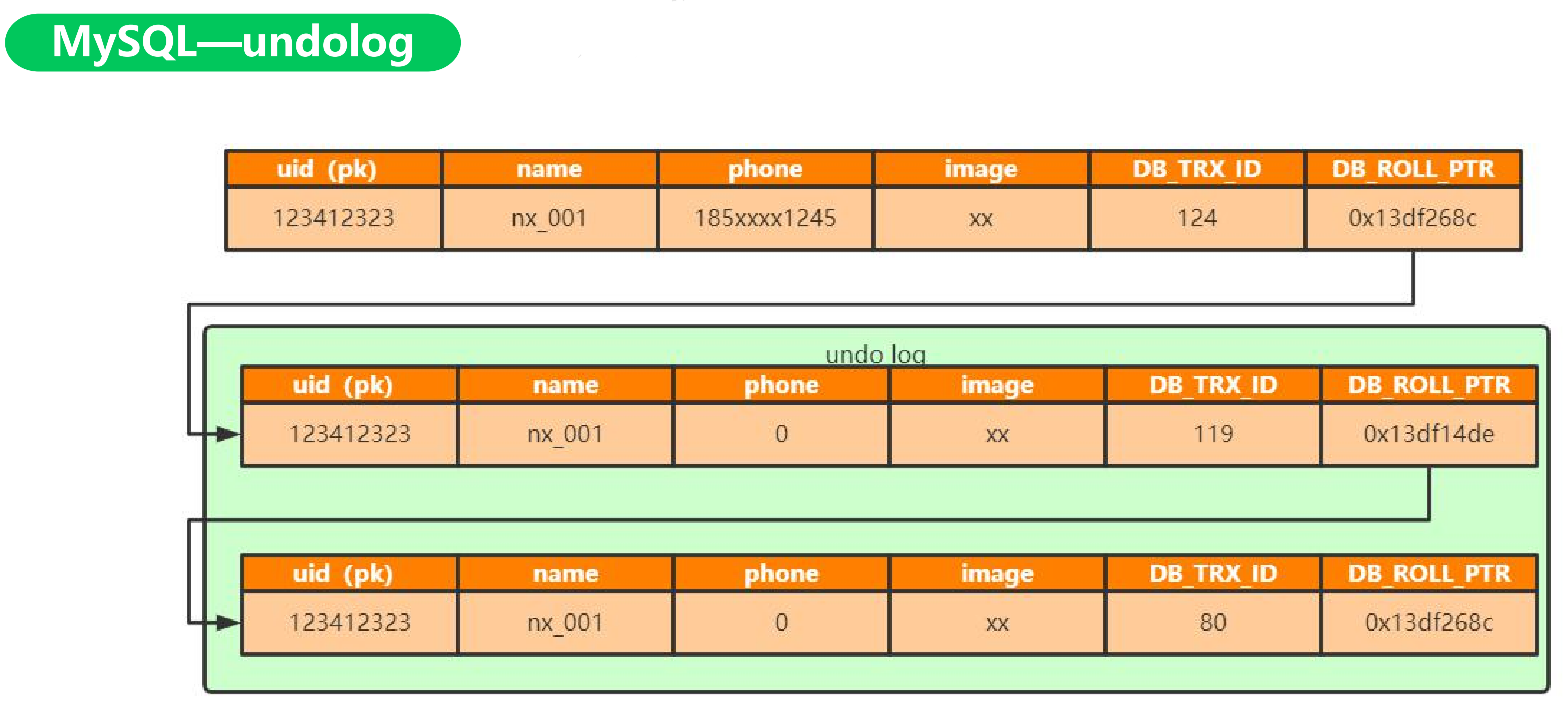
回滚指针指向undo_log
undolog如何清理??
依据系统活跃的最小活跃事务ID做一个 Read view。如果这条记录都可见了,那之前的记录都可以删除了。
redo log
用于实现事务持久性
- 记录修改(记录本次的修改)
- 用于异常恢复(事务没来及刷盘,就挂了,用于恢复本次修改)
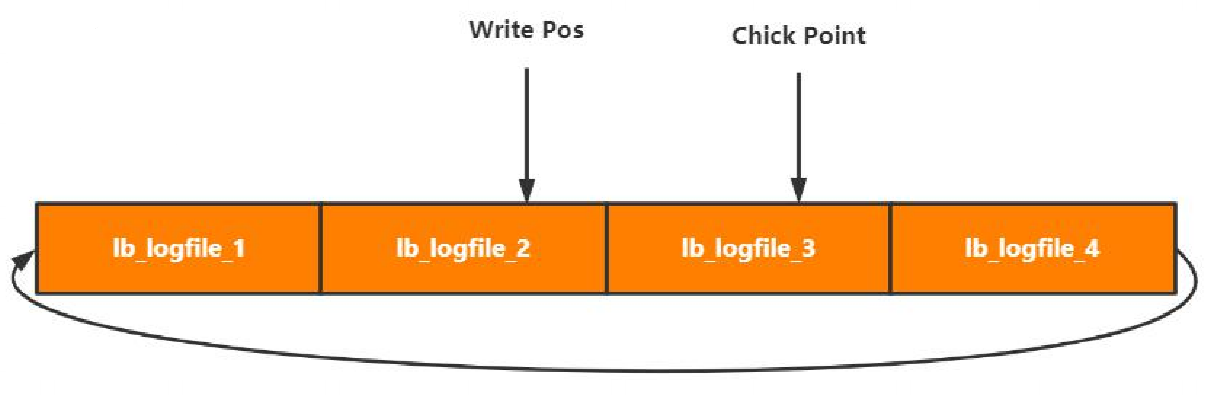
- 循环写文件
- Write Pos:写入位置
- Chick Point:刷盘位置(Chick Point往右到Write Pos表示没刷盘的数据)
- Chick Point -> Write Pos:待落盘数据
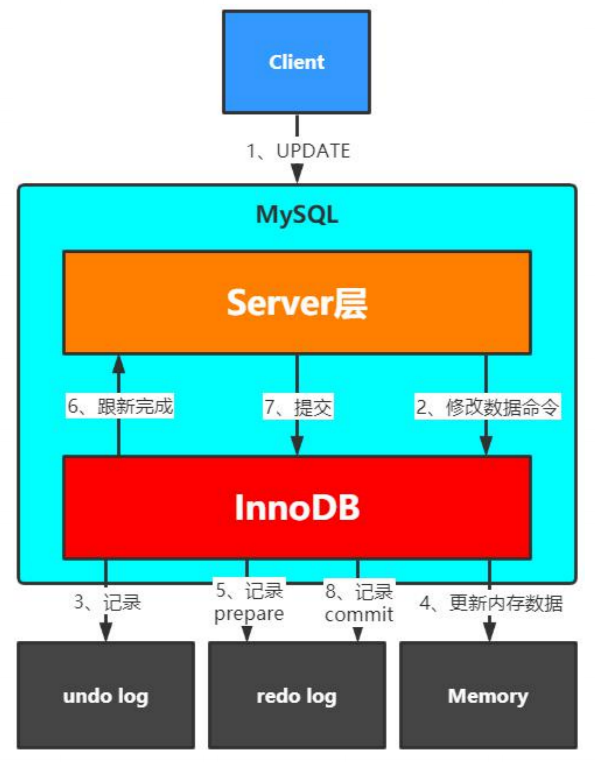
写入流程
- 记录页的修改,状态为prepare
- 事务提交,将事务记录为commit状态(生效redolog)
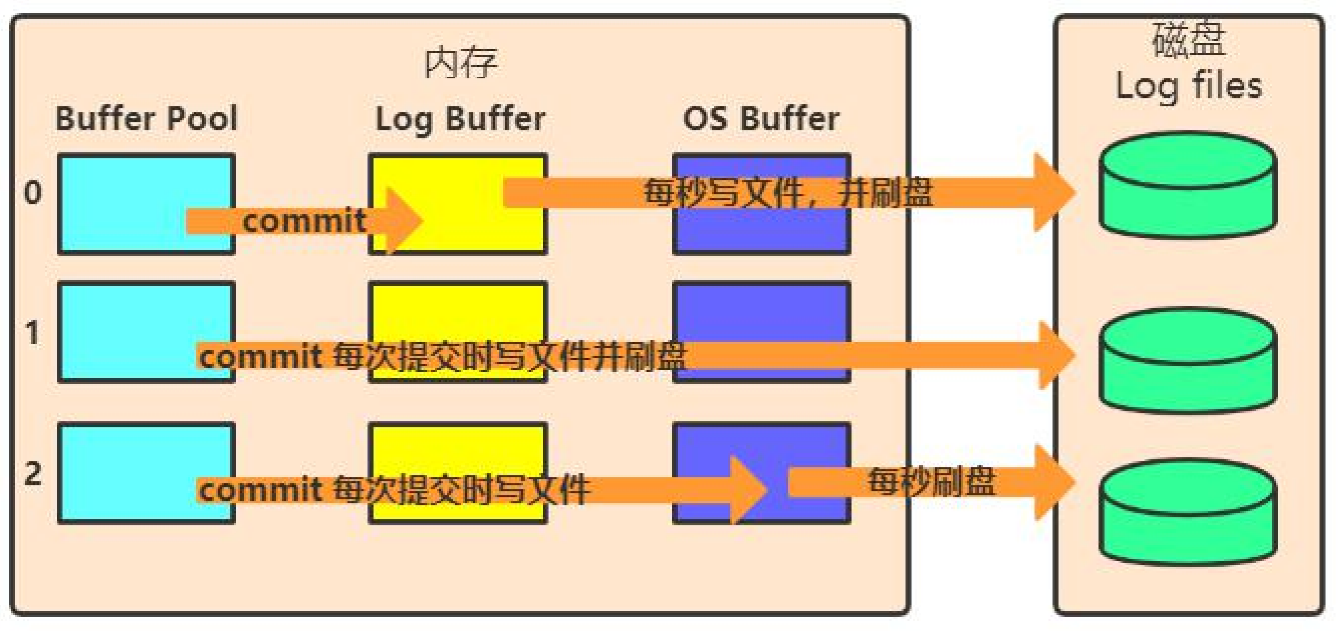
刷盘时机:innodb_flush_log_at_trx_commit
下图是commit后做的事情,分三种策略。
redolog存在意义(为什么不拿Page直接刷盘?)
- 体积小,记录的是页面的修改,不是整个页面,比写入页代价低。
- 末尾追加,随机写变顺序写(page的刷盘随机写),发生改变的页不固定。
MySQL使用及调优实践分析
索引使用技巧
- 联合索引:优于多列独立索引
- 索引顺序:选择性高的在前面
- 覆盖索引:二级索引存储主键值更有利
- 索引排序:索引同时满足查询和排序
分库分表设计
- 是否分表
- 建议单表不超过1KW
- 分表方式
- 取模:存储均匀&访问均匀
- 按时间:冷热库
- 分库
- 按业务垂直分
- 水平查分多个库
使用建议
- 数据库字符集使用utf8mb4;
- VARCHAR按实际需要分配长度;
- 文本字段建议使用VARCHAR;
- 时间字段建议使用long;
- bool字段建议使用tinyint;
- 枚举字段建议使用tinyint;
- 交易金额建议使用long;
- 禁止使用“%”前导的查询;
- 禁止在索引列进行数学运算,会导致索引失效;
- select * from t1 where id+1 >1121 **不会使用索引 **
- select * from t1 where id >1121 - 1 会使用索引
- 表必须有主键,建议使用业务主键;
- 单张表中索引数量不超过5个;
- 单个索引字段数不超过5个;
- 字符串索引使用前缀索引,前缀长度不超过10个字符;
RocksDB数据库存储原理分析
RocksDB:使用C++编写的嵌入式kv存储引擎,其键值均允许使用二进制流。由Facebook基于levelDB开发。
- Log Structured-Merge Tree
- LSM的设计依据
- 随机写转换成顺序写(提升写性能)
- 优化读性能
- 三种数据结构
- MenTable
- logfile
- sstfiles
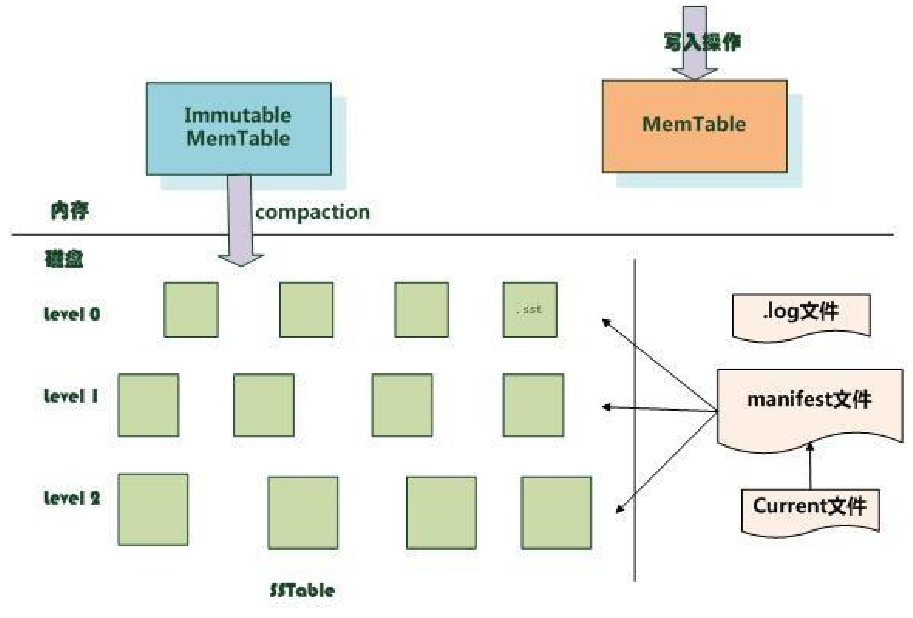
RocksDB写入
- 插入
- 记录log
- MenTable写入新记录
- 更新
- 记录log
- MenTable写入新记录
- 删除
- 记录log
- MenTable标记key删除
WAL:write-ahead log,先记录日志,再写数据。确保数据不丢失 全部是内存写入,没有磁盘I/O
MenTable写满后写入磁盘,顺序I/O
LSM读
- 读MemTable
- 定位sslFile(每个sslFile都是一个小的SLM tree,数据有序),文件内查找。数据有交叉,第一层查询时每个文件都需要查一下。

RocksDB读优化
- 数据冗余:定时压缩,清除冗余数据,减少文件数量;
- 布隆过滤器:提高检索效率;
- 文件分层
- 页面缓存
RocksDB性能问题
- 读放大:按层查找
- 空间放大:顺序写造成,更新和插入都是新记录。
- 写放大:压缩造成
分布式存储技术
原理分析
CAP定理:在一个分布式计算机系统中,一致性,可用性和分区容错性这三种保证无法同时得到满足。
- Consistency 一致性
- Availability 可用性
- Partition Tolerance分区容错性
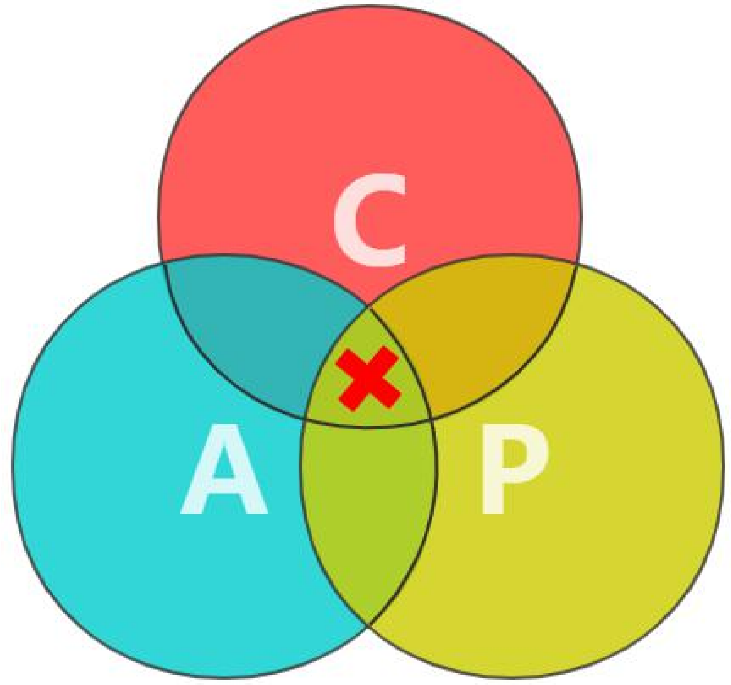
CAP取舍 - CP:发生分区,需要牺牲用户的体验,等待所有数据全部一致了之后再让用户访问系统。
- AP:发生分区,为了高可用,每个节点只能用本地数据提供服务,会导致全局数据的不一致性。
理想情况下 单机数据库 AC;
分布式数据 库系统 CP;
单机数据库分布式解决方案
- 垂直拆分
- 水平拆分
- 读写分离
业务侵入大,维护成本高 带来分布式事务问题!
分布数据库特性
- 存储量不受单机容量限制(存储量按机器数量水平扩展)
- 计算能力不受单机资源限制
- 扩展性强
- 容错能力强
- 数据可靠性高
分布数据库设计思路
- 多副本存储(一份数据做多个副本,raft协议同步)
- 保证数据一致性
- 一般使用KV存储模型
- 主从模式
- 提供数据分片路由支持
多副本存储方式
- 不是一份完整的数据,一张表的数据可能分散在多个实例
- 底层KV存储
- 数据一致性协议(raft)
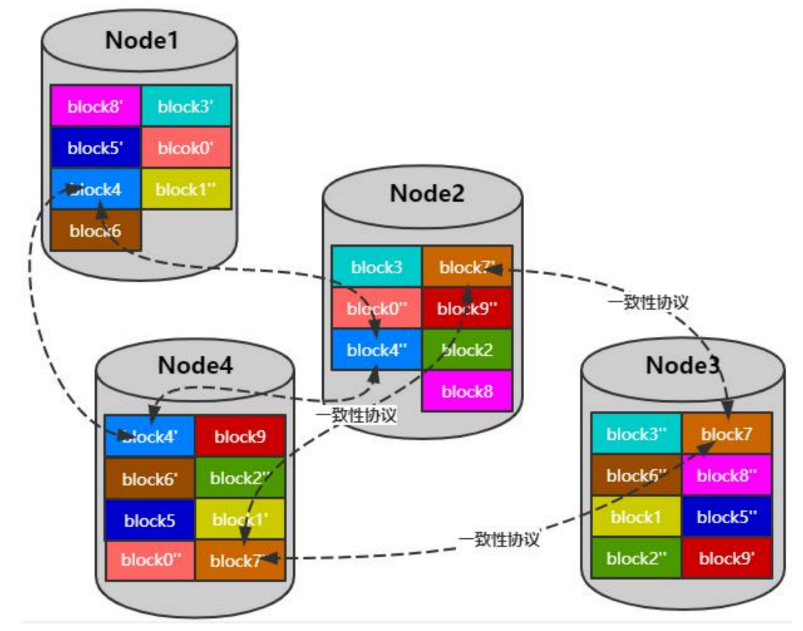
技术难点
- 热点数据(读写请求都到Leader)
- 数据分块(可能一个Node上的数据全部都是Leader)
- 热数据迁移(需要均匀分散每台机器的Leader)
- 原子性
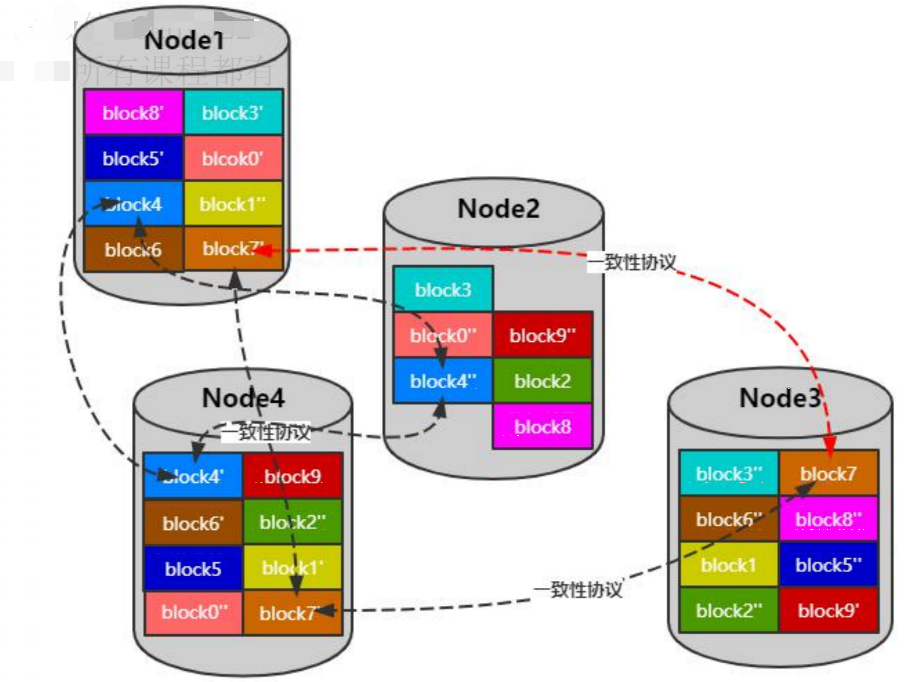
热点数据
倘若Node2的Leader过多,则可以在Node1的节点上加一个新的block节点,然后将Node2的Leader-block下线。
实时调整块位置将读写频繁的块均匀分布在各个存储节点
调整前:
调整后:
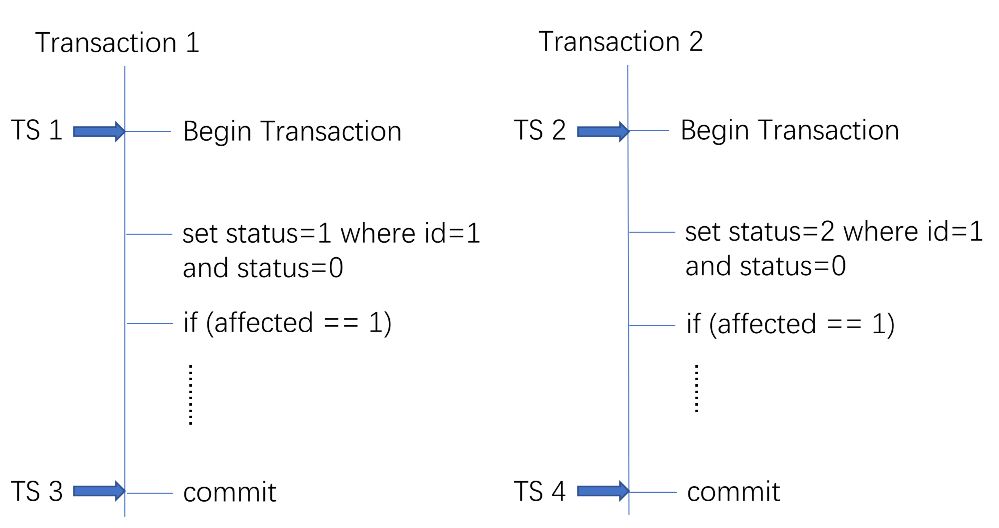
原子性
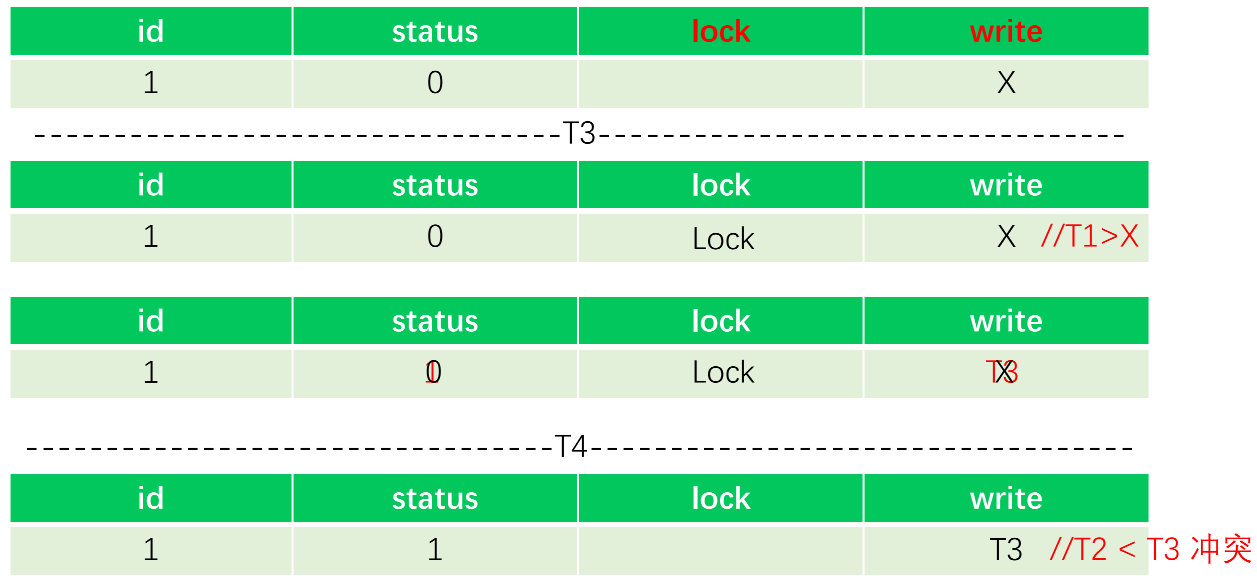
保障多个Key写入的原子性,Percolator 谷歌分布式事务模型。
-
乐观锁方式实现事务:以下是2个事务执行的动作。
-
两阶段提交
- prewrite 获取锁 写入数据(写入内存)
- commit 提交变更
-
隐藏列:L列(锁)&W列(事务更新时间戳)
-
前提:T1时刻开启事务,T3时刻提交。提交时T1>X 表示在T1事务开启之后,这条记录没有被改过,因此可以上锁。
-
加锁成功后修改记录,将write修改成T3
-
T4时刻提交T2时刻开启的事务,此时T2<T3,有冲突,提交失败。
常见分布式存储产品
- MongoDB
- Pika(360)
- Pegasus(小米)
- Titan(美图)
- Codis(Redis分布式解决方案)
- TiDB
分布式存储技术产品选型及适用场景分析
分布式存储分类
数据模型维度
- NoSQL
- MongoDB
- Pika(360)
- Pegasus(小米)
- Titan(美图)
- Codis
- 关系型
- TiDB
持久化维护
- TiDB
- 内存
- Codis
- 固化
- TiDB
- MongoDB
- Pika
- Pegasus
- Titan
MongoDB
- 文档型数据库
- 支持主从同步
- 支持副本集模式
- 支持数据分片
- 快速水平扩展
- 高效数据压缩
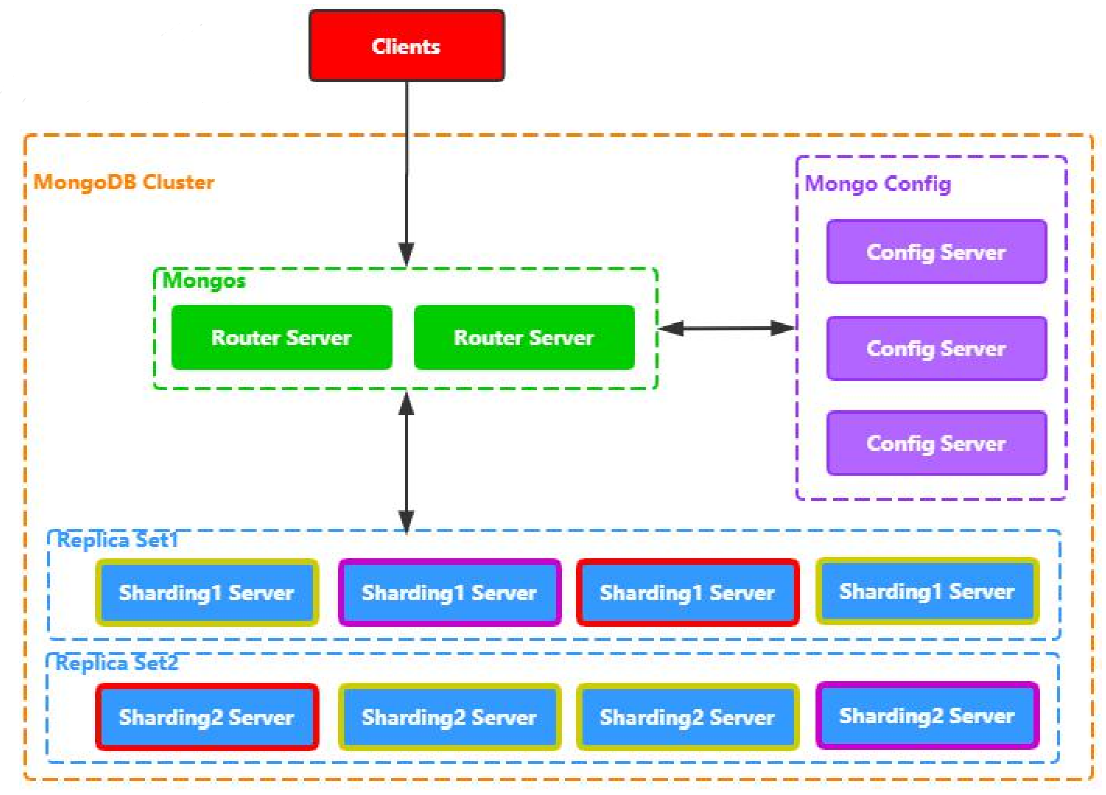
Mongos是路由节点,客户端访问路由节点。
TiDB
- SQL语句支持(支持关系型查询)
- 水平线性弹性扩展
- 分布式事务
- 数据强一致性保证
- 故障自恢复的高可用
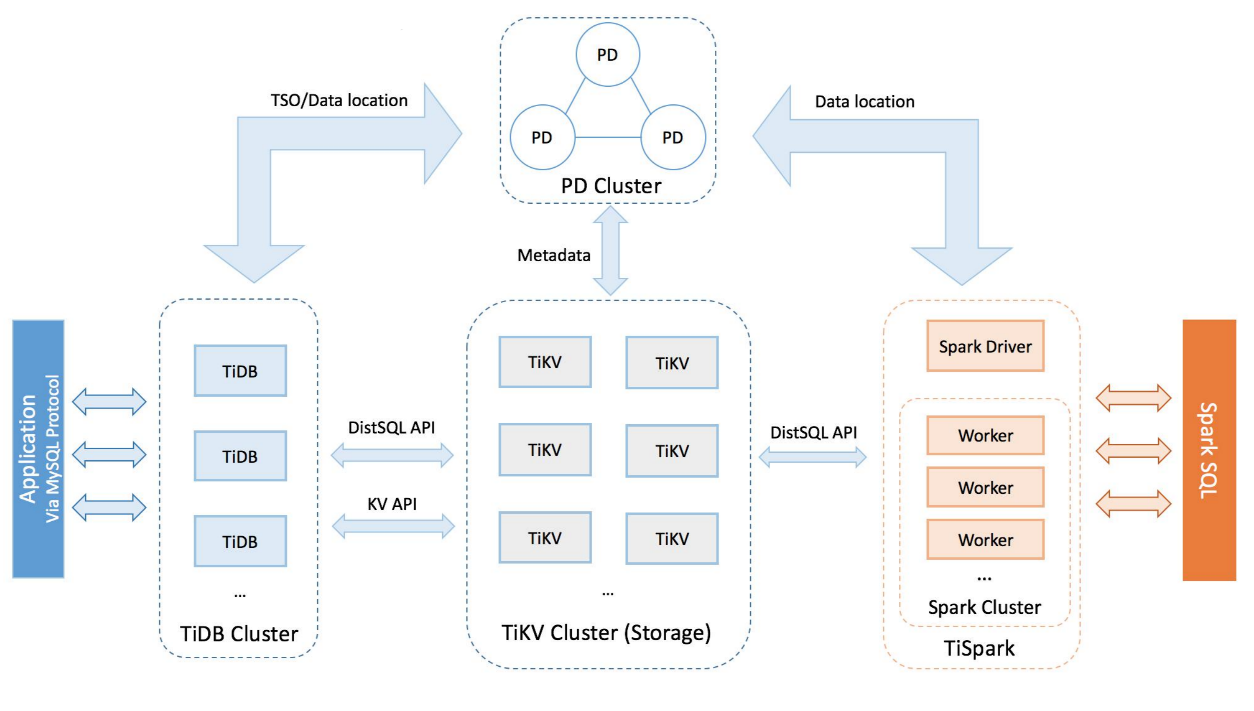
TiDB架构
- 基于RocksDB
- Raft一致性协议(TiKV Cluster-Storage 集群)
- Etcd存储元数据(定位的Key在哪放在TiPD-PD Cluster)
- 支持OLTP(线上业务)
- 支持OLAP(线下分析,开启读写分离)
Codis
redis分布式解决方案
Pika
- 360开源
- 可持久化
- 容量受单机磁盘限制
- 支持主从部署
- 支持Redis协议
结合Codis的Proxy 提供分布式解决方案
将上图codis-redis的位置换成pika
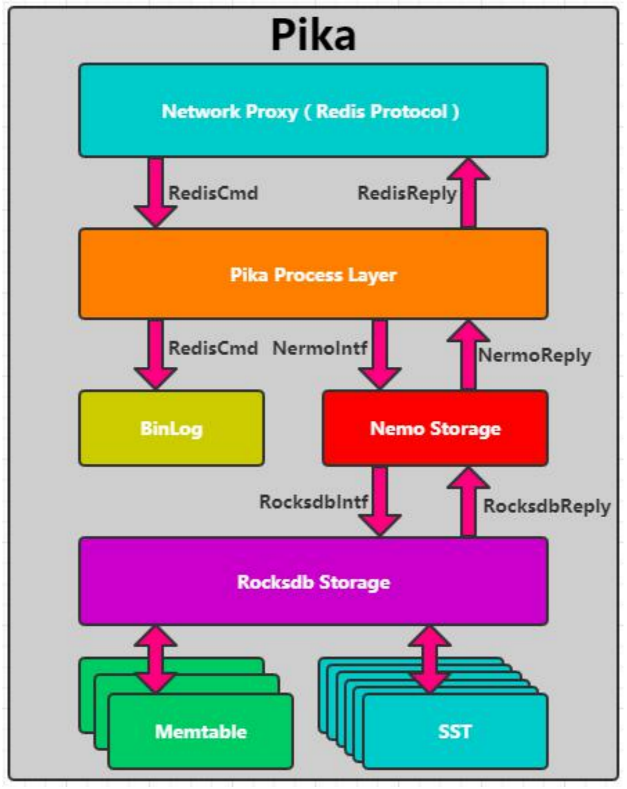
实现原理
- 基于RocksDB存储
- 提供Redis协议代理
- 基于BinLog实现主从同步
- 磁盘换内存
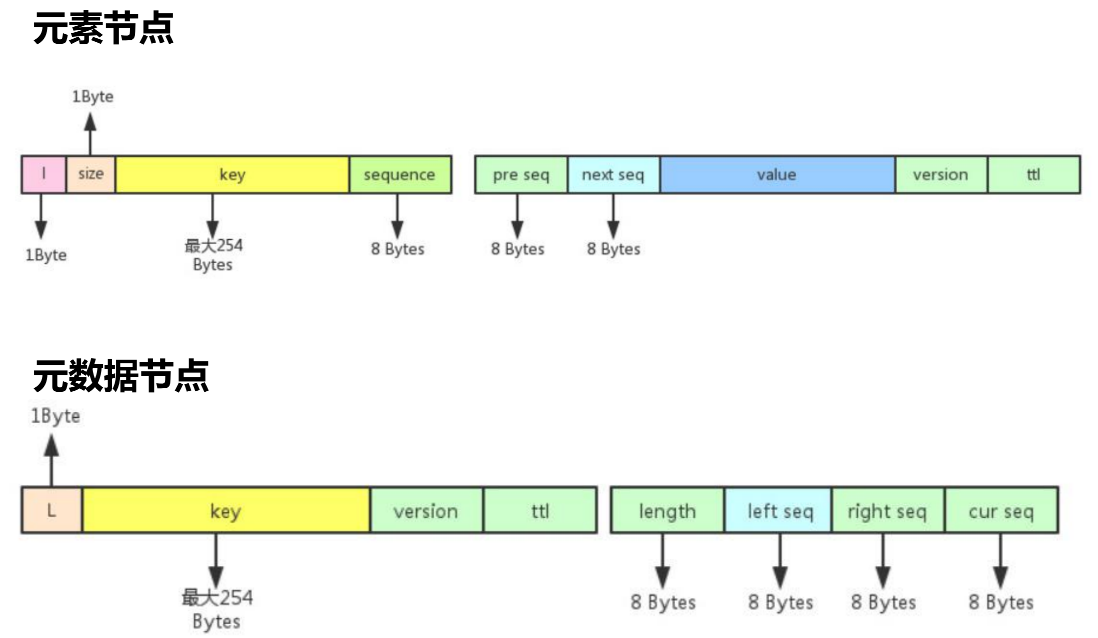
Pika List存储设计
- 元素节点
- 元数据节点
Pegasus
- 小米开源
- 持久化KV存储系统
- 支持Redis协议
- 支持数据压缩
- 可水平扩展
- 数据强一致
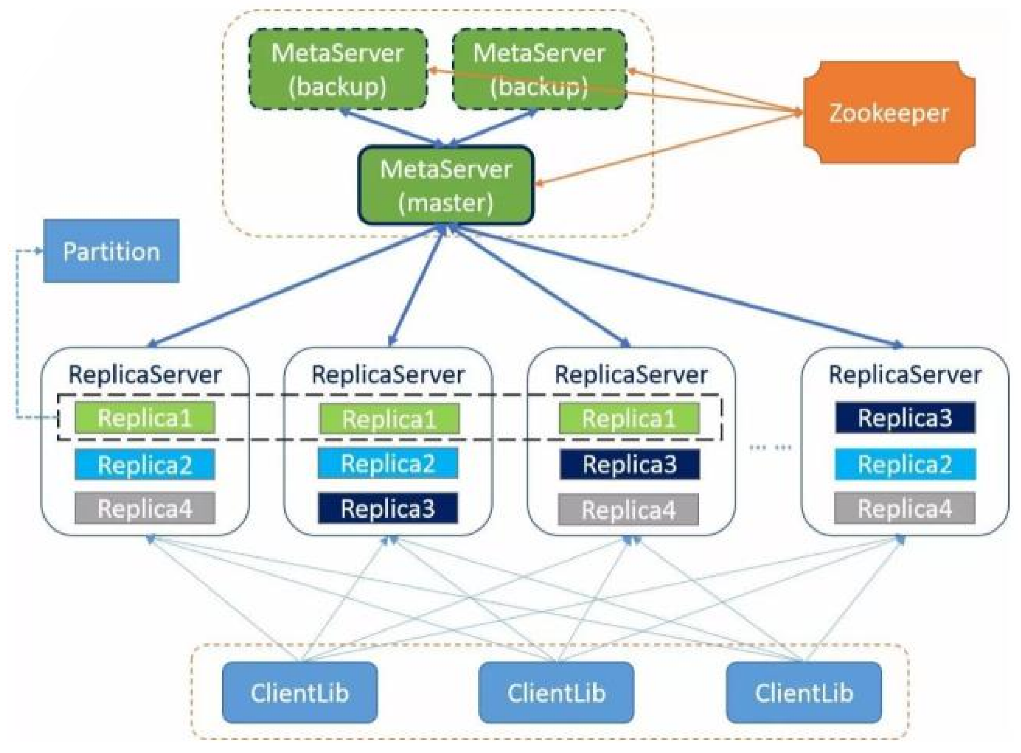
实现原理
- 基于RocksDB
- PacificA一致性协议
- 类似Zab,Raft基于任期和事务ID
- Redis固化、分布式解决方案
Titan
- 美图开源
- 持久化KV存储系统
- 支持Redis协议
- 可水平扩展
- 支持热点数据迁移
- 基于TiKV
实现原理
- Redis固化和分布式解决方案
- 基于TiKV
- Redis协议代理
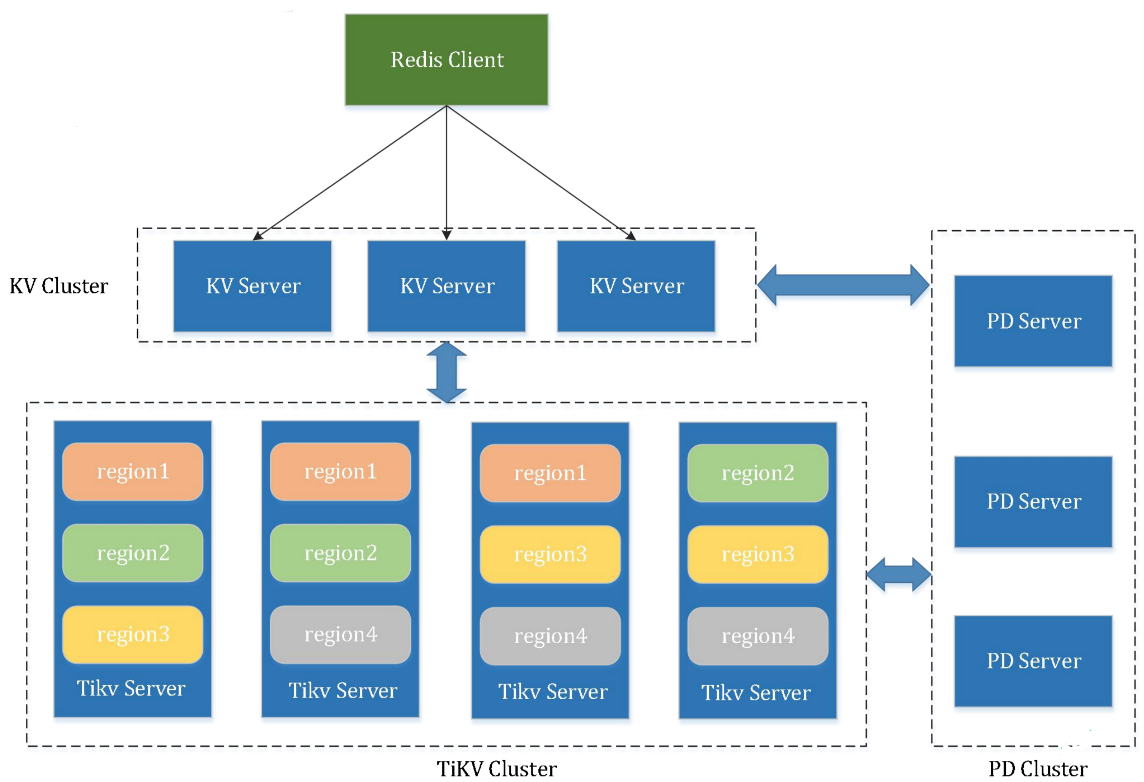
综合对比分析
- 协议(支持redis)
- 持久化
- 存储模型(底层kv存储)
- 分布式方案
MySQL到TiDB迁移案例
MySQL使用问题
- 数据量大,快速水平扩展存储比较难;
- 大数据量下,快速 DDL可能锁表;
- 分库分表造成业务逻辑非常复杂;
- 常规 MySQL 主从故障转移会导致业务访问短暂不可用
TiDB测试数据
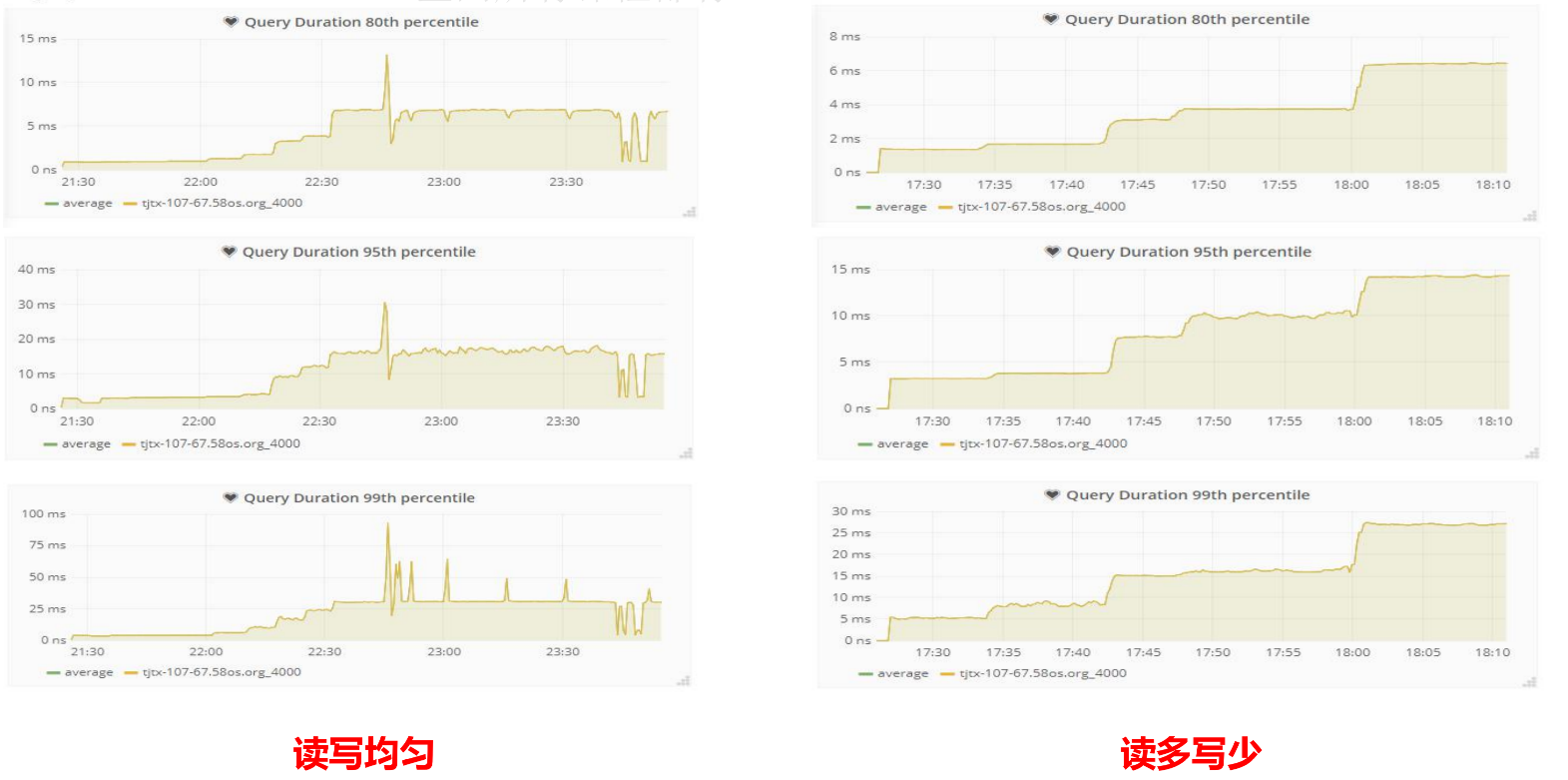
读写均匀的情况下表现不是特别好,读多写少的情况下表现比较稳定。
模拟业务场景测试
- 选择场景
- IM联系人列表
- 测试验证
- 构造数据
- 模拟流量
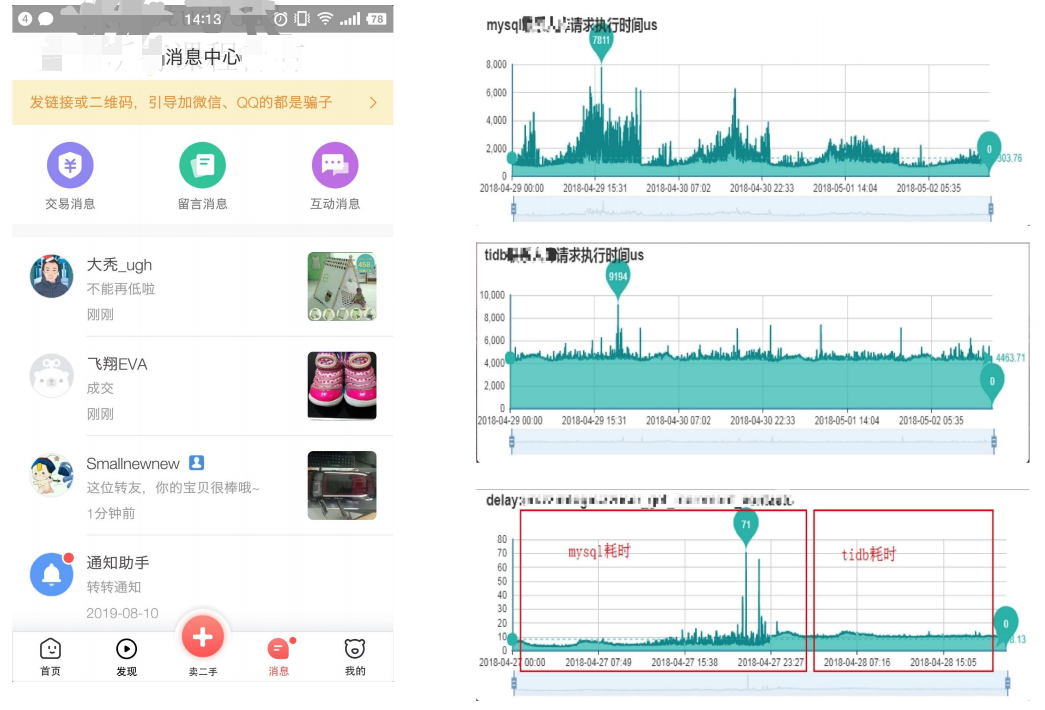
读写均匀的情况下测试:
mysql虽然表现还好,但是毛刺比较多。
TiDB虽然耗时稍微多了一点,但是非常平稳。
数据及流量迁移
-
数据迁移
-
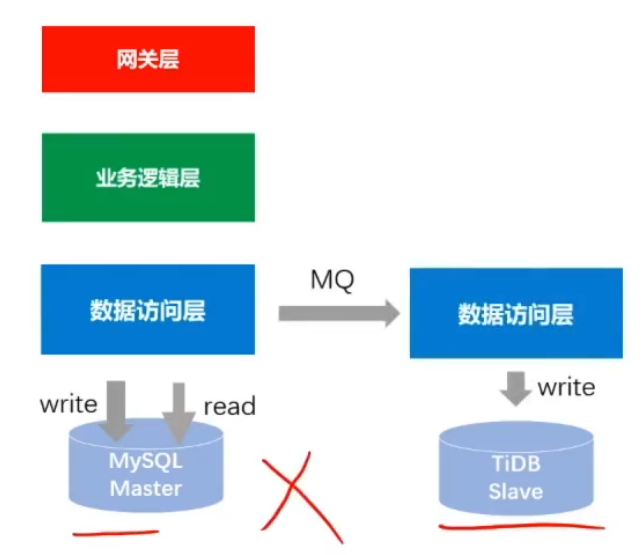
主从同步(mysql同步到TiDB,主从建立好后就可以认为两边数据追齐了)
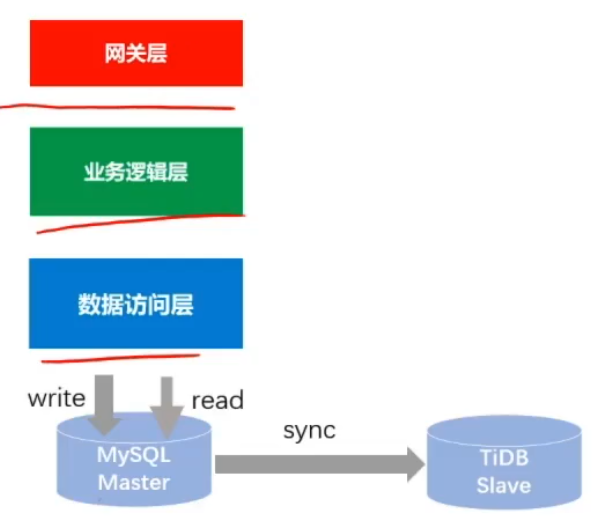
-
双写(断掉主从同步,写mysql数据库的时候发个MQ事务消息,消费端消费消息并写入TiDB)
-
-
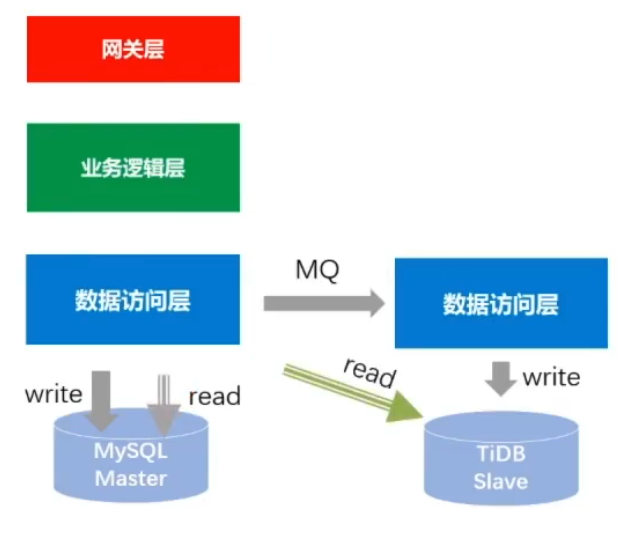
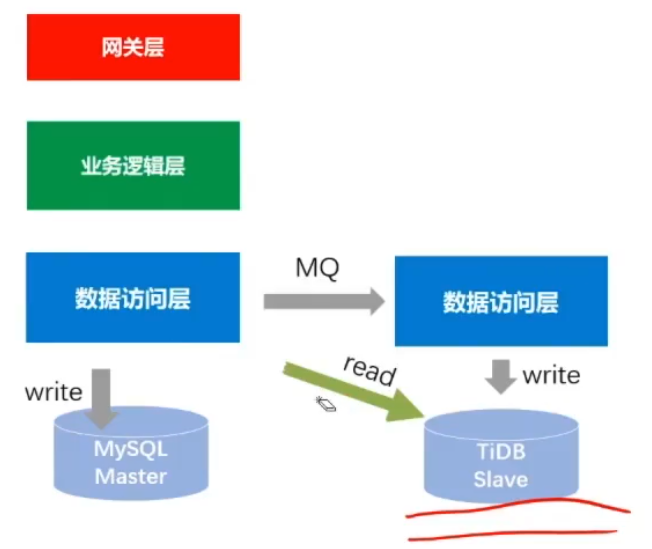
流量迁移
-
切读(灰度切流,切一部分的流量,最终把读流量全部切换到TiDB)
-
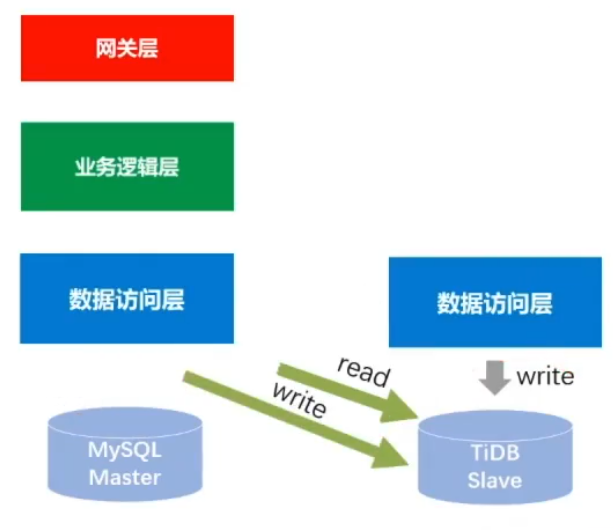
停双写(用比较新的技术的话要特别关注,双写这个动作可以保留个半年再去停)
-
迁移时遇到的问题
锁冲突问题
业务场景——手机通知栏推送
- 用户 — 设备ID 映射
- 数据变更场景
- 1账号登陆多手机(U1之前用的是P1,之后换成了P3这个设备)
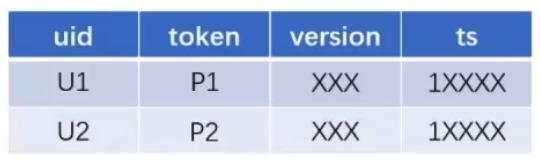
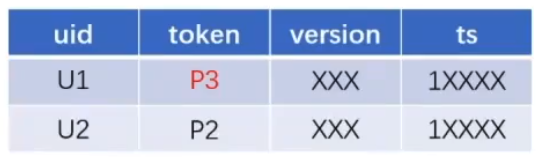
- 1手机登陆多账号(U2使用P3,需要修改绑定关系并删除原来U2这条记录)


部分山寨机的Token不是标准的Token,取不到Token时前端会给一个Default默认值,那此时出现1手机登陆多账号时就会出现一直更新default对应U3的这条记录,导致出现大量锁冲突。

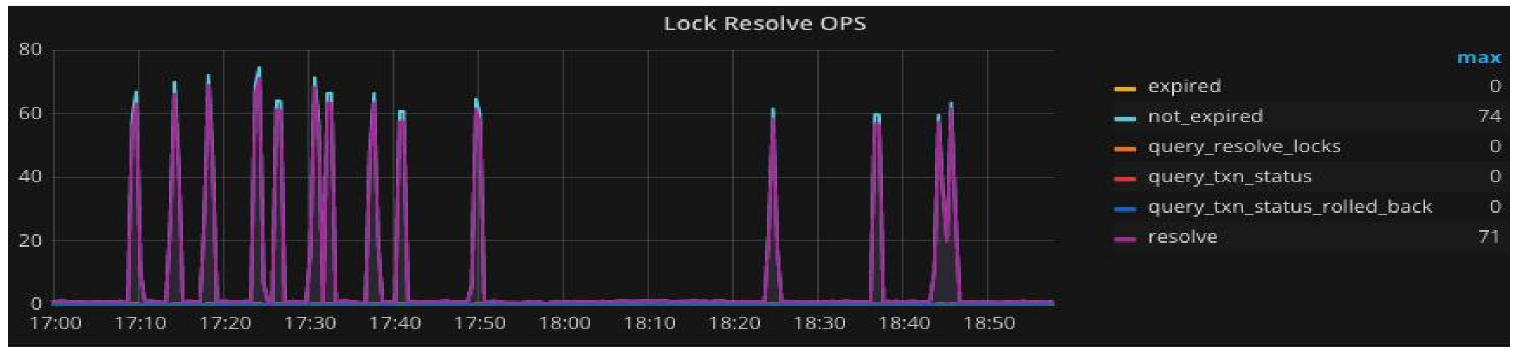
解决方案:优化业务,过滤默认值的数据
- 1账号登陆多手机(U1之前用的是P1,之后换成了P3这个设备)
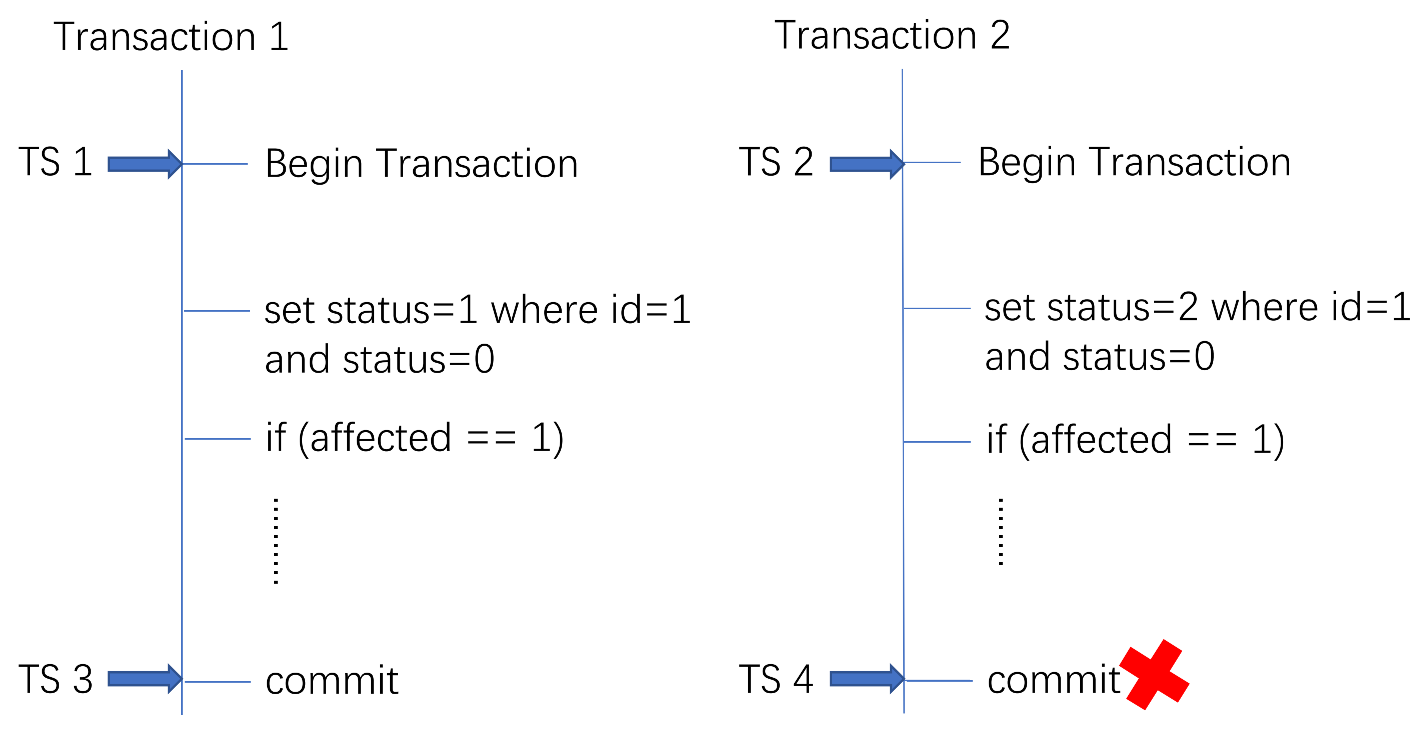
乐观锁的问题
商品状态流转
- 发布者想下架商品 状态:0-1
- 买家拍下商品 状态:0-2
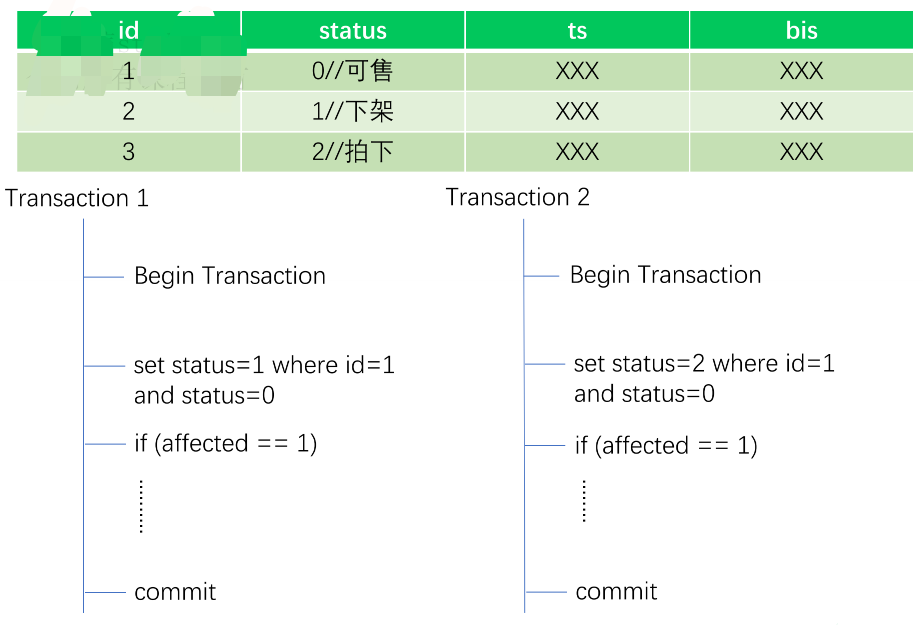
MySQL处理方式
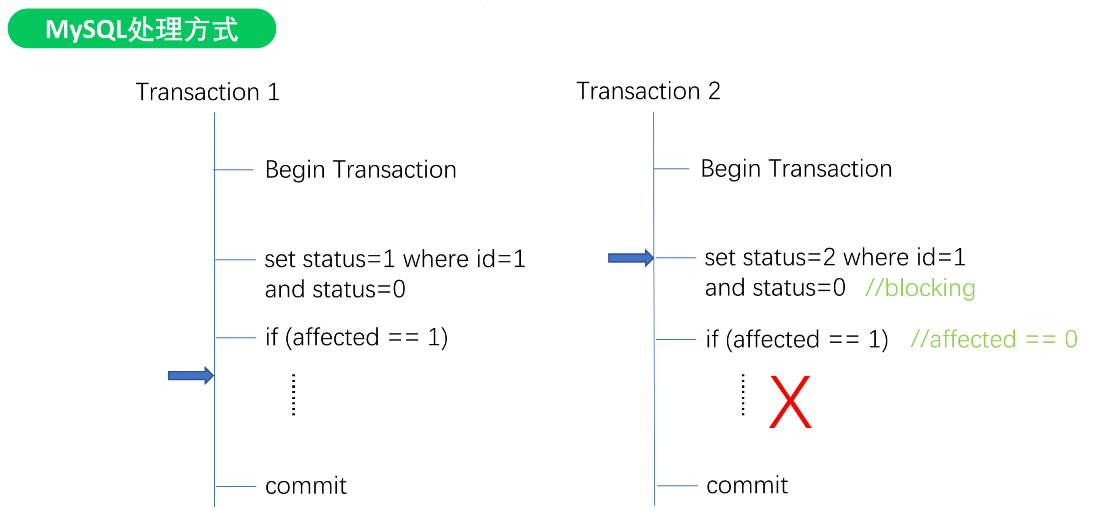
TiDB处理方式
TiDB使用乐观锁模型,导致T2 set xxx锁不住,导致中间多了很多MQ或者RPC
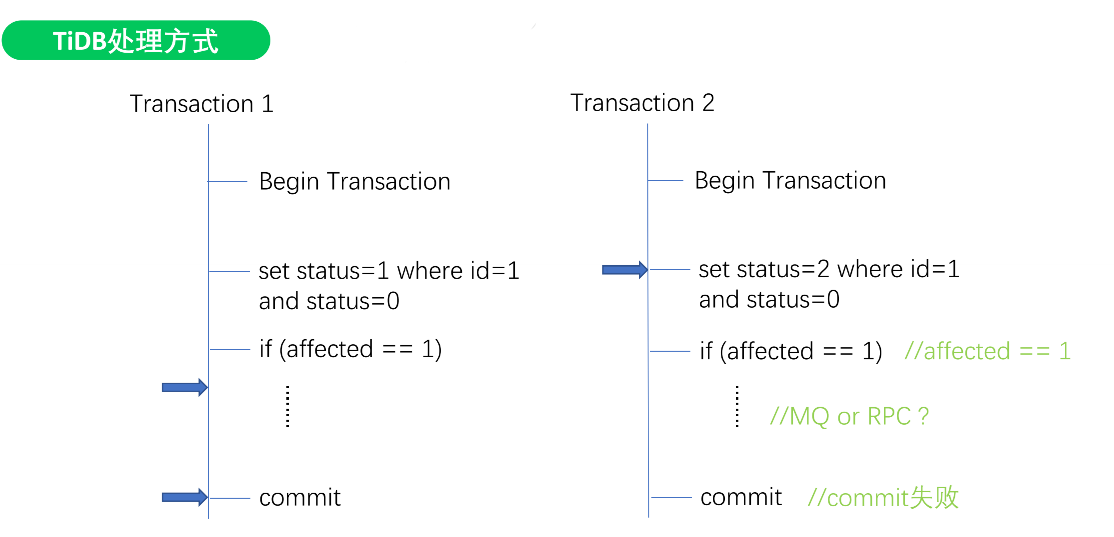
解决方案:使用分布式锁,串行化处理
这篇关于中间件复习之-分布式存储系统的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!








