本文主要是介绍Interview preparation--RabbitMQ,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
AMQP
- AMQP(Advanced Message Queueing protocol). 高级消息队列协议,是进程之间床底一步新消息的网络协议
- AMQP工作原理如下:
- 发布者(Publisher)发布消息(Message)经过交换机(Exchange),交换机根据绑定的路由规则(RoutingKey)将收到消息分发给交换机绑的队列(Queue),最后AMQP代理会将消息投递给订阅了此队列的消费者,或者消费者按照需求自行获取(取RoutingKey对应的消息)。

RabbitMQ 中交换机
- 交换机负责接收客户端传递过来的消息,并且转发到对应的队列中,在Rabbit中有4中交换机
| 交换机 | 作用 |
|---|---|
| Direct Exchange 直接交换机 | direct交换机是Rabbit默认交换机,默认会进行公平调度,交换机中的所有消息会依次投递到每一个绑定的Queue中,采用轮询的方式,当轮训到A队列时候一定会分发到A队列对其他BCD队列没有任何影响 ,同时能绑定RoutingKey,按照RoutingKey直接精确匹配路由 |
| Fanout Exchange 扇形交换机 | 扇形交换机,实际上就是广播模式,fanout会把消息发送给所有绑定的交换机的队列。并且每个队列消息中第一个consumer能收到消息,并且忽略Routingkey |
| Topic Exchange 主题交换机 | topic交换机,允许路由键(RoutingKey)中出现匹配规则,路由键的写法和包名写法类似,com.za.xxx.xxx格式,绑定可以带上特殊字符,例如 * 代表任意单词, # 代表0个或者多个字符匹配所有 |
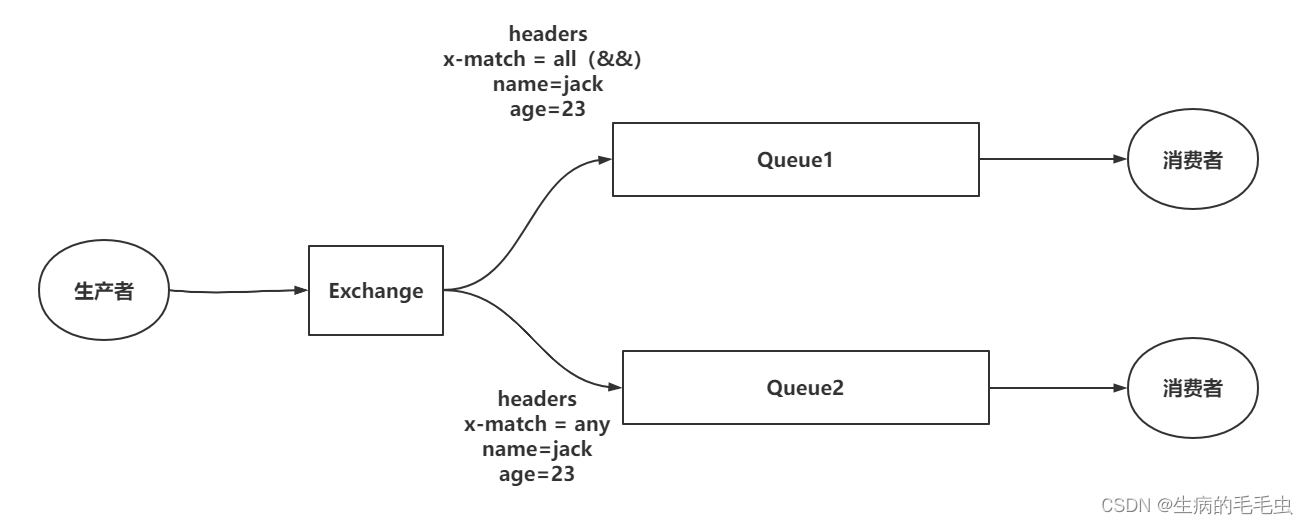
| Header Exchange 首部交换机 | header模式是基于一个key-value方式的绑定关系,让Exchange和Queue安指定的关系绑定在一起的一种规则,可以采用类型更加丰富 如下图示例, 设置绑定匹配规则x-match = all/any, all:代表key value 都必须匹配才能投递,any:代表key value任意匹配即可投递,因此生产者发消息时候必须携带一个header的参数,header中包括key value值,在按照如上规则去实施投递 |
RabbitMQ中vHost的作用
- vHost可以看成是一个迷你版本的服务器,里面有自己的exchange,queue,binding关系,vHost还有自己的权限系统,我们可以通过admin账号将某个vHost授权给某个账号A,这样账号A才能看到vHost内部的queue,exchange,binding关系
- 这样设计目的,利用vHost来完成不同权限的隔离,比如公司有多个域,但是公用一套RabbitMQ,这样我们可以为每一个域创建不同的账号以及vHost,这样每个域就可以用自己的账号单独使用RabbitMQ而且互相不干扰
RabbitMQ上的Queue中存放的Message是否有数量限制,限制多少
- 默认情况下一般是没有限制的,因为限制取决于机器的内存,但是消息过多会导致处理效率降低
- 在RabbitMQ中提供了参数来限制Message的数量,x-max-length:队列中消息的条数限制,x-max-length-bytes:队列中消息总量大小限制
RabbitMQ开启持久化机制,有什么要注意的点
- RabbitMQ中每个vHost都有exchange,Queue,bingding关系,当没持久化的时候,queue中数据是在内存中,因此开启持久化之后,投递的消息不仅仅写入内存还需要写入磁盘中
- 即使数据持久化了,当RabbitMQ宕机,vhost中的关键数据exchange,queue,binding关系也会丢失,因此我们必须将queue队列名称元数据,binding关系,exchange元数据信息也必须持久化
- 一旦开启持久化,性能会大受影响,不开启持久化官方给的性能指标并发度是1.2W TPS,开启持久化之后可能降低到原来的1/4 ,2k到3k的TPS,因此如果业务流量并不少特别大并且要保证消息不丢失,可以采用持久化的方法,否则不建议开启持久化,毕竟RabbitMQ宕机是小概率事件,并且我们可以通过其他方式保证高可用例如集群等。
RabbitMQ如何保证消息发送成功和消息接收成功
-
消息发送确认
- 第一种方法 confirmCallback方法:
- confirmCallback方法是一个回调接口,消息发送到Broker后触发回调,确认消息是否到达Broker服务器,也就是只确认是否正确到达Exchange中
- 第二种方法:ReturnCallback方法
- 通过实现RenturnCallback接口,启动消息失败返回,此接口是在交换器路由不到队列的时候触发回调,改方法可以不使用,因为交换机和队列是在代码里面绑定的,如果消息成功投递到Exchange后几乎不存在绑定队列收不到,除非代码写错了
-
消息确认接收:
- Rabbit消息确认机制(ACK)默认是自动ACK的,自动ACK会在消息发送给消费者后立刻确认,但是存在消息丢失的可能,因为如果消费者消费逻辑异常回滚此时也是只能保证数据一致性,之前被消费的消息并不会再次被消费。
- 消息确认模式有以下几种
- AcknowledgeMode.NONE : 自动确认
- AcknowledgeMode.AUTO : 更具情况确认
- AcknowledgeMode.MANUAL : 手动确认
- 消费者收到消息后,手动调用Basic.Ack 或者 Basic.Nack 或者 Basic.Reject后,RabbitMQ收这些消息后才认为本次投递完成。
- Basic.Ack命令:用于确认当前消息已经正确消费
- Basic.Nack命令:用于否定当前消息,使用场景:当消费异常,但是非致命错误重试可能成功的情况下,我们希望RabbitMQ能够给我们重新投递这个消息,可以使用Nack反馈,可以将其中requeue设置为true,则会重新投递
- Basic.Reject命令:用于拒接当前消息,使用场景:消费数据时候遇到致命异常,重试依然会失败,那么应该直接反馈Reject命令,并且设置参数requeue为false,将丢弃这条数据或者进入死信交换机。
- Nack,Reject后都有能力要求是否重复投递消息,可以将他们投递到死信队列
RabbitMQ 死信队列,延迟队列分别是怎么实现的
-
DLX(Dead Letter Exchange) 死信交换机
-
当队列中的消息被拒绝 Basic.Reject,或者过期此时消息会变成死信,死信可以被重新投递到另外一个交换器,这个交换机就是DLX,与DLX绑定的队列就是死信队列,因此有如下三种原因:
- 信息被拒绝
- 信息超时
- 超过队列最大长度
-
过期消息定义:Rabbit可以通过参数设置消息过去时间,第一种通过队列设置,设置这个参数会使得队列中所有消息都存在相同过期时间,第二种通过对消息本身设置,那么每一条消息的过期时间都不一样,同时使用两个方法取最小的那个
-
队列设置: 队列声明的时候使用x-message-ttl,单位为秒
-
单个消息设置:设置消息属性expiration参数知,单位为秒
-
延迟队列
-
RabbitMQ支持延迟消息,投递后到exchange之后,并不会立刻给消费者,而是指定时间之后给
-
RabbitMQ没有直接支持延迟队列,而是通过死信队列实现,在死信队列中,可以为普通交换机绑定多个消息队列,假设绑定过期时间为5分钟,10分钟,30分钟,3个消息队列,然后为每一个对了设置一个DLX,为每一个DLX关联一个死信息队列,这样因为普通队列没有被消费,等指定时间后久会到DLX中,接着DLX中的绑定消费者消费这条消息,间接实现了延迟队列
这篇关于Interview preparation--RabbitMQ的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!








