本文主要是介绍PG sql调优案例学习,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
一,开发范式
1.不要轻易把字段嵌入到表达式
例:在sal列上有索引,但是条件语句中把sal列放在了表达式当中,导致索引被压抑,因为索引里面储存的是sal列的值,而不是sal加上100以后的值。

在条件中查询谁的工资+100=2000。这样写即使在sal上有索引也会走全表扫描,主要原因就是sal列存放的是sal的值,并不是sal+100的值,
改写思路:通过等式等换,把sal列从表达式中剥离出来,就会用到索引:

如上图,代价远远小于全表扫描。
2.不要轻易把字段嵌入到函数中
例:在 hiredate列上有索引,但是条件语句中把该列放在了函数当中,导致索引被压抑,因为索引里面储存的是该列的值,而不是函数处理以后的值。

如上图,hiredate列有索引,但是放在了函数中,导致被压抑,执行计划走了全表扫描。
改写思路:通过等式转换,把列从函数中剥离出来,就会用到索引,比较成本,差别很大。

如上图,索引没有被压抑。
3.如果査询中比较固定查询某些列,可以基于这几个列建复合索引,直接查询索引(覆盖索引),避开回表扫描。

4.改变索引的关联度--类似Oracle的集簇因子

意思就是,在范围扫描的时候,索引关联度高的会扫描更少的块,关联度特别低的类似于b,与走了一遍全表扫描没有什么差别,在这种情况,我们可以改变索引的关联度。
在Oracle中,一般改变索引的集簇因子有两种方法
1、对表的行进行重排序
2、使用单表集簇 这两种办法可以用来维持行的顺序。将所有列值相同或者相邻的行放置在同一数据块中, 消除了全表扫描,使查询速度的增加高达 30 倍或者更多。
在PG中,可以使用重排序的方式。
例1:t1列有索引,如果此时不是范围扫描

主要查看correlation一列(Oracle中叫 clustering_factor),这一列如果和1相差很多,则认为关联度比较松散,此时总成本为12.47。
此时改变索引的关联度:

此时correlation为1,此时总成本为8。
例2:t1列有索引,如果此时是一个范围扫描

从上图可以看到,索引关联度不同,范围扫描消耗的成本更大。
二.多表查询技巧
1.驱动表上有很好的条件限制,同时,驱动表上的限制性条件字段上应该有索引,包括主键、唯一索引或其它索引、复合索引等
2.在每次连接操作之后尽量保证返回记录数最少,传递给下一个连接操作
3.根据返回的行的数量对应正确的连接方式。
4..尽量通过在被驱动表的连接字段上的索引,访问被驱动表。
5..单表扫描应该有效率,如果被驱动表上还有其它限制条件,可以遵循复合索引创建原则,创建合适的复合索引(连接字段与条件字段)
6..全表扫描也许是合理的,例如若干小表、代码表的访问。
7.依次类推,顺序完成所有表的连接操作。
多表查询案例分析1:如果有一张表有条件约束

此时,PG会把emp表作为驱动表,使用emp表上的索引来访问被驱动表dept。
dept表作为被驱动表,连接条件列要有索引。
emp表的deptno列就不需要有索引了。
多表查询案例分析2:如果两张表都有条件约束

如果根据案例1的思路,此时emp表为驱动表,empno上应该有索引,dept表为被驱动表,根据连接条件列d.deptno=e.deptno 被驱动表d.deptno上面要有索引,但dept表有限制条件d.dname='DALLS',此时分情况来讨论:
如果d.deptno为主键约束,那么可以不在d.dname列建索引,因为使用d.deptno即可访问。
如果d.dept不是主键索引,那么建议建复合索引(deptno,dname)。
多表查询案例分析3:如果有五张表的关联查询

可以看到,employees表访问了两次,起了两个不同的别名,可以当作两张单独的表,同时关联的还有departments,locations,jobs表。
看限制条件列
首先第一列:I.city= ‘South San Francisco’ , 那么在location的city列上要有索引。
再看location 这张表和哪个表进行连接:
![]()
很显然是这一列,所以d.location需要建索引。
再看d表还和哪个表连接:
![]()
索引emp.department需要建索引。
所以总而言之:有连接条件列,一般最好建索引
根据我们的思路,来逐步看执行计划:
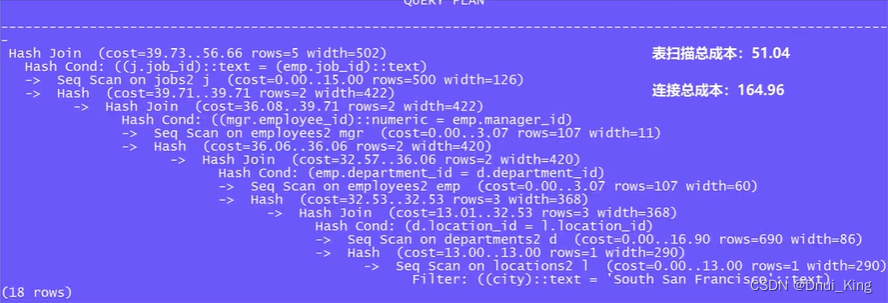
第一种情况-无索引
在没有任何索引的情况下查看其执行计划,由于没有索引,所以所有扫描方式均为全表扫描,连接方式为 hash join。
第二种情况:建立单列索引
在 locations的city,location_id列上创建索引。
在 departments的 location_id上创建索引在 departments的 department_id上创建主键约束
在 employees的 employee_id上创建主键约束
在jobs的job_id上创建主键约束。

第三种情况-创建复合索引
在 locations的city、 location_id列上创建复合索引。
在 departments的 department_id、 location_id上创建复合索引
在 employees的 employee_id、 department_id、 manager_id、 job_id上创建复合索引(或者单列索引)
在jobs的 job_id上创建主键约束
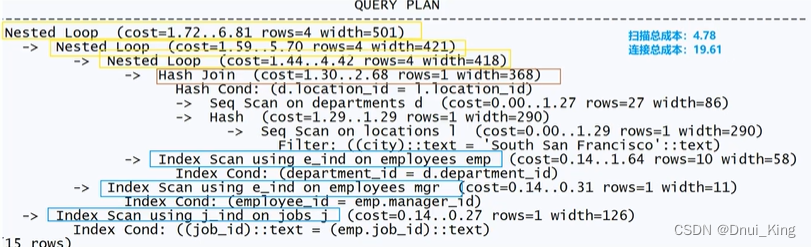
三种执行计划成本对比:

经过分析发现,如果连接方式能够走嵌套循环,那么其成本比其它连接方式都低,当然我们要提供条件让优化器自动选择成本最低的连接方式,只要有一张表的访问方式是索引扫描,那么连接方式一般会选择嵌套循环。
Employees表的复合索引在执行计划中起到了作用,或者选择在连接条件列上( employee_id, department_id, manager_id)创建单列索引
Departments和 locations表的记录比较少,即使创建了单列或者多列索引,都不会使用索引。
连接顺序是L>D->EMP-MGR-J
虽然复合索引效率很客观,但复合索引维护成本较高,具体的sql调优手段还需要具体问题具体分析。
这篇关于PG sql调优案例学习的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





