本文主要是介绍NETDEV 协议 七,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
这部分内容在于说明socket创建后如何被内核协议栈访问到,只关注两个问题:sock何时插入内核表的,sock如何被内核访问的。对于核心的sock的插入、查找函数都给出了流程图。sock如何插入内核表
socket创建后就可以用来与外部网络通信,用户可以通过文件描述符fd来找到要操作的socket,内核则通过查表来找到要操作的socket。这意味着socket创建时会在文件系统中生成相应项,同时还会插入到存储socket的表中,方便用户和内核通过两种方式进行访问。
以创建如下udp socket为例,这里的创建仅仅指定socket的协议簇是AF_INET,类型是SOCK_DGRAM,协议是0,此时创建了socket,相应文件描述符,但仍缺少其它信息,此时socket并未插入到内核表中,还是处于游离态,除了用户通过fd操作,内核是看不到的socket的。
根据作为的角色(服务器或客户端)不同,接下来执行的动作也不相同。这两句分条时服务器和客户端与外部通信的第一句,执行后,与外部连接建立,socket的插入内核表也是由这两句触发的。
服务器端udp socket
bind(fd, &serveraddr, sizeof(serveraddr));客户端udp socket
sendto(fd, buff, len, 0, &serveraddr, sizeof(serveraddr)); 下面来看下创建socket的具体动作,只涉及与socket存储相关的代码,这些系统调用的其它方面以后再具体分析。
sys_socket() 创建socket,映射文件描述符fd
在内核中,有struct socket,也就是通常所说的socket,表示网络的接口,还有struct sock,则是AF_INET域的接口。一般struct socket成员叫sock,struct sock成员叫sk,在代码中不要混淆。
sock_create() -- > __sock_create()
最终执行__sock_create()来创建,注意__sock_create()最后一个参数是0,表示是由用户创建的;如果是1,则表示是由内核创建的。
分配socket并设置sock->type为SOCK_DGRAM。
从net_families中取得AF_INET(也即PF_INET)协议族的参数,net_families数组存储不同协议族的参数,像AF_INET协议族是在加载IP模块时注册的,inet_init() -> sock_register(&inet_family_ops),sock_register()就是将参数加入到net_families数组中,inet_family_ops定义如下:
最后调用相应协议簇的创建方法,这里的pf->create()就是inet_create(),它创建INET域的结构sock。
从__sock_create()代码看到创建包含两步:sock_alloc()和pf->create()。sock_alloc()分配了sock内存空间并初始化inode;pf->create()初始化了sk。
sock_alloc()
分配空间,通过new_inode()分配了节点(包括socket),然后通过SOCKET_I宏获得sock,实际上inode和sock是在new_inode()中一起分配的,结构体叫作sock_alloc。
设置inode的参数,并返回sock。
继续往下看具体的创建过程:new_inode(),在分配后,会设置i_ino和i_state的值。
其中的alloc_inode() -> sb->s_op->alloc_inode(),sb是sock_mnt->mnt_sb,所以alloc_inode()指向的是sockfs的操作函数sock_alloc_inode。
sock_alloc_inode()中通过kmem_cache_alloc()分配了struct socket_alloc结构体大小的空间,而struct socket_alloc结构体定义如下,但只返回了inode,实际上socket和inode都已经分配了空间,在之后就可以通过container_of取到socket。
inet_create()
从inetsw中根据类型、协议查找相应的socket interface。
inetsw是在inet_init()时被注册的,有三种:tcp, udp, raw,由于我们创建的是udp socket,所以查到的是第二项,udp_prot。
sock->ops指向inet_dgram_ops,然后创建sk,sk->proto指向udp_prot,注意这里分配的大小是struct udp_sock,而不仅仅是struct sock大小。
sock->ops = answer->ops;
……
sk = sk_alloc(net, PF_INET, GFP_KERNEL, answer_prot);然后设置inet的一些参数,这里直接将sk类型转换为inet,因为在sk_alloc()中分配的是struct udp_sock结构大小,返回的是struct sock,利用了第一个成员的特性,三者之间的关系如下图:

此时sock和sk都已经分配了空间,再设置sock与sk关系,即sock->sk=sk,并做一些初始化操作,如sk的队列初始化。初后调用sk_prot->init(),inet_dgram_ops->init()为NULL,这里没做任何事情。
当创建的是一个SOCK_RAW类型的socket时,还会额外执行下列语句。当协议值赋给inet->inet_num与inet->inet_sport,然后sk->sk_prot->hash(sk)将sk插入到内核的sock表中,使用的索引值是协议号。这个可以这样理解,如果创建的是UDP或TCP的socket,它们是标准的套接字,用[sip, sport, tip, tport]这样的四元组来查找,socket()时还缺少这些信息,还不能插入到内核的sock表中。但如果创建的是RAW的socket,它只属于某一特定协议,查找它使用的应是协议号而不是套接字的四元组,因此,socket()时就通过hash()插入到内核sock表中。
那么sock是在什么时候插入到内核表中的,答案是sk->sk_prot->get_port()函数,对于UDP来讲,它指向udp_v4_get_port()函数,根据服务器和客户端的行为不同,bind()和sendto()都会调用到get_port(),也就是说,在bind()或sendto()调用时,sock才被插入到内核表中。
bind() 绑定地址
sys_bind() -> sock->ops->bind() -> inet_bind() -> sk->sk_prot->get_port()
sk->sk_prot是udp_prot,这里实际调用udp_v4_get_port()函数。
sendto() 发送到指定地址
sys_sendto() -> sock_sendmsg() -> __sock_sendmsg()() -> sock->ops->sendmsg()
由于创建的是udp socket,因此sock->ops指向inet_dgram_ops,sendmsg()实际调用inet_sendmsg()函数。该函数中的有如下语句:
客户端在执行sendto()前仅仅执行了socket()操作,此时inet_num=0,因此执行了inet_autobind(),该函数会调用sk->sk_prot->get_port()。从而回到了udp_v4_get_port()函数,它会将sk插入到内核表udp_table中。
下面重点看下插入sk的函数udp_v4_get_port():
udp_v4_get_port() 插入sk到内核表udptable中
哈希值hash2_nulladdr由[INADDR_ANY, snum]得到,hash2_partial由[inet_rcv_saddr, 0]得到,即前者用本地端口作哈希,后者用本地地址作哈希。udp_portaddr_hash存储后者的值hash2_partial,便于计算最后的哈希值。
最后调用udp_lib_get_port(),ipv4_rcv_saddr_equal()是比较地址是否相等的函数,snum是本地端口,hash2_nulladdr是由它得到的哈杀值,sk是要插入的表项。
udp_lib_get_port()
取得内核存放sock的表,对于udp socket来说,就是udp_table,它在udp_prot中被定义。在udp_table的创建过程中已经看到,udp_table有两个hash表:hash和hash2,两者大小相同,只是前者用snum作哈希值,后者用saddr, snum作哈希值。使用两个hash表的目的在于加速查找,先用snum在hash中查找,再用saddr, snum在hash2中查找,最后根据效率决定在hash或hash2中查找。
根据snum的不同会执行不同的操作,snum为0则先选择一个可用端口号,再插入;snum不为0则先确定之前没有存储相应sk,再插入。
如果snum!=0,此时执行else部分代码。hslot是从udp_table中hash表取出的表项,键值是snum。
hslot = udp_hashslot(udptable, net, snum); 如果hslot->count大于10,即在hash表中以snum为键值的项的数目在于10,此时改用在hash2表中查找。如果hslot->count不足10,那么直接在hash表中查找就可以了。这样划分是出于效率的考虑。
先看数目大于10的情况,hslot2是udptable中hash2表取出的表项,键值是[inet_rcv_addr, snum],如果hslot2项的数目比hslot还多,那么查找hash2表是不划算的,返回直接查找hash表。如果hslot2更少(这也是设计hash2的目的),使用udp_lib_lport_inuse2()查找是否有匹配项;如果没有找到,则使用新的键值hash2_nulladdr,即[INADDR_ANY, snum]从hash2中取出表项,再使用udp_lib_lport_inuse2()查找是否有匹配项。如果有,表明要插入的sk已经存在于内核表中,直接返回;如果没有,则执行sk的插入操作。scan_primary_hash代码段是在hash表的hslot项中查找,只有当在hash2中查找更费时时才会执行。
流程图:

如果snum==0,即没有绑定本地端口,此时执行if部分代码段,这种情况一般发生在客户端使用socket,此时内核会为它选择一个未使用的端口,下面来看下内核选择临时端口的策略。
在说明下列参数含义前要先弄清楚udptable中hash公式:(num + net_hash_mix(net)) & mask,net_hash_mix(net)返回一般为0,hash公式可简写为num&mask。即本地端口对udptable大小取模。因此表项是循环、均匀地分布在hash表中的。假设udptable大小为8,现插入16个表项,结果会如下图:

声明bitmap数组,大小为udp_table每个键值最多存储的表项,即最大端口号/哈希表大小。端口号的值规定范围是1-65536,而哈希表一般大小是256,因此实际分配bitmap[8]。low和high代表可用本地端口的下限和上限;remaining代表位于low和high间的端口号数目。用随机值rand生成first,注意它是unsigned short类型,16位,表示起始查找位置;last表示终止查找位置,first和last相差表大小保证了所有键值都会被查询一次。随机值rand最后处理成哈希表大小的奇数倍,之所以要是奇数倍,是为了保证哈希到同一个键值的所有端口号都能被遍历,可以试着1开始,每次+2和每次+3,直到回到1,所遍历的数有哪些不同,就会明白rand处理的意义。
使用first值作为端口号,从udptable的hash表中找到hslot项,重置bitmap数组全0,调用函数udp_lib_lport_inuse()遍历hslot项的所有表项,将所有已经使用的sport对应于bitmap的位置置1。
此时bitmap中包含了所有哈希到hslot的端口的使用情况,下面要做的就是从first位置开始,每次递增rand(保证哈希值不变),查找符合条件的端口:端口在low~high的可用范围内;端口还没有被占用。do{}while循环的判断条件snum!=first和snum+=rand一起保证了所有哈希到hslot的端口号都会被遍历到。如果找到了可用端口号,即跳出,执行插入sk的操作,否则++first,查找下一个键值,直到fisrt==last,表明所有键值都已轮循一遍,仍没有结果,则退出,sk插入失败。
流程图:

当没有在当前内核udp_table中找到匹配项时,执行插入新sk的操作。首先给sk参数赋值:inet_num, udp_port_hash, udp_portaddr_hash。然后将sk加入到hash表和hash2表中,并增加相应计数。
sock如何被内核访问
创建的udp socket成功后,当使用该socket与外部通信时,协议栈会收到发往该socket的udp报文。
udp_rcv() -> __udp4_lib_rcv() -> __udp4_lib_lookup()
在该函数中有关于udp socket的查找代码段,它以[saddr, sport, daddr, dport, iif]为键值在udptable中查找相应的sk。
__udp4_lib_lookup() sock在udptable中查找
查找的过程与插入sock的过程很相似,先以hnum作哈希得到hslot,daddr, hnum作哈希得到hslot2,如果hslot数目不足10或hslot的表项数少于hslot2的,则在hslot中查找(begin代码段)。否则,在hslot2中查找。查找时使用udp4_lib_lookup2()函数,它返回与收到报文相匹配的sock。
如果在hslot2中没有查找结果,则用INADDR_ANY, hnum作哈希得到重新得到hslot2,因为服务器端的udp socket只绑定了本地端口,没有绑定本地地址,所以查找时需要先使用[saddr, sport]查找,没有时再使用[INADDR_ANY, sport]查找。如果hslot2->count比hslot->count要多,或者在hslot2中没有查找到,则在hslot中查找(begin代码段)。
只有当不必或不能在hslot2中查找时,才会执行下面的查找,它在hslot中查找,遍历每一项,使用comute_score()计算匹配值。最后返回查找的结果。
流程图:

#对比udp socket的插入和查找的流程图,可以发现两者是有差别的,在使用INADDR_ANY作为本地地址重新计算hslot2后,前者并没有比较hslot2->count与hslot->count。虽然不碍查找结果,但个人认为,插入的流程是少了hslot2->count与hslot->count比较。
udp4_lib_lookup2()
遍历hslot2的链表项,compute_score2计算与[saddr, sport, daddr, dport, dif]相匹配的表项,返回score作为匹配值,匹配值发越大表明匹配度越高。score==SCORE2_MAX表示与传入参数完全匹配,找到匹配项,goto exact_match;score==-1表示与传入参数完全不匹配;score==中间值表示部分匹配,如果没有更高的匹配项存在,则使用该项。
其中compute_score2()用来计算匹配度,并用返回值作为匹配度,以通常的udp socket为例,只用到了本地地址、本地端口(如果是作为服务器,则本地地址也省略了)。因此compute_score2()要求本地地址和本地端口完全匹配,共余参数只要求当插入的socket有值时才进行匹配。
UDP报文接收
UDP报文的接收可以分为两个部分:协议栈收到udp报文,插入相应队列中;用户调用recvfrom()或recv()系统调用从队列中取出报文,这里的队列就是sk->sk_receive_queue,它是报文中转的纽带,两部分的联系如下图所示。
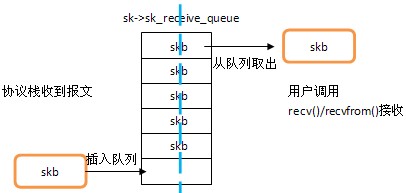
第一部分:协议栈如何收取udp报文的。
udp模块的注册在inet_init()中,当收到的是udp报文,会调用udp_protocol中的handler函数udp_rcv()。
udp_rcv() -> __udp4_lib_rcv() 完成udp报文接收,初始化udp的校验和,并不验证校验和的正确性。
在udptable中以套接字的[saddr, sport, daddr, dport]查找相应的sk,在上一篇中已详细讲过”sk的查找”,这里报文的source源端口相当于源主机的端口,dest目的端口相当于本地端口。
sk = __udp4_lib_lookup_skb(skb, uh->source, uh->dest, udptable);如果udptable中存在相应的sk,即有socket在接收,则通过udp_queue_rcv_skb()将报文skb入队列,该函数稍后分析,总之,报文会被放到sk->sk_receive_queue队列上,然后sock_put()减少sk的引用计算,并返回。之后的接收工作的完成将有赖于用户的操作。
当没有在udptable中找到sk时,则本机没有socket会接收它,因此要发送icmp不可达报文,在此之前,还要验证校验和udp_lib_checksum_complete(),如果校验和错误,则直接丢弃报文;如果校验和正确,则会增加mib中的统计,并发送icmp端口不可达报文,然后丢弃该报文。
if (udp_lib_checksum_complete(skb))
goto csum_error;
UDP_INC_STATS_BH(net, UDP_MIB_NOPORTS, proto == IPPROTO_UDPLITE);
icmp_send(skb, ICMP_DEST_UNREACH, ICMP_PORT_UNREACH, 0);
kfree_skb(skb);
udp_queue_rcv_skb() 报文入队列
sock_woned_by_user()判断sk->sk_lock.owned的值,如果等于1,表示sk处于占用状态,此时不能向sk接收队列中添加skb,执行else if部分,sk_add_backlog()将skb添加到sk->sk_backlog队列上;如果等于0,表示sk没被占用,执行if部分,__udp_queue_rcv_skb()将skb添加到sk->sk_receive_queue队列上。
那么何时sk会被占用?何时sk->sk_backlog上的skb被处理的?
创建socket时,sys_socket() -> inet_create() -> sk_alloc() -> sock_lock_init() -> sock_lock_init_class_and_name()初始化sk->sk_lock_owned=0。
比如当销毁socket时,udp_destroy_sock()会调用lock_sock()对sk加锁,操作完后,调用release_sock()对sk解锁。
实际上,lock_sock()设置sk->sk_lock.owned=1;而release_sock()设置sk->sk_lock.owned=0,并处理sk_backlog队列上的报文,release_sock() -> __release_sock(),对于sk_backlog队列上的每个报文,调用sk_backlog_rcv() -> sk->sk_backlog_rcv()。同样是在socket的创建中,sk->sk_backlog_rcv = sk->sk_prot->backlog_rcv()即__udp_queue_rcv_skb(),这个函数的作用上面已经讲过,将skb添加到sk_receive_queue,这样,所有的sk_backlog上的报文转移到了sk_receive_queue上。简单来说,sk_backlog队列的作用就是,锁定时报文临时存放在此,解锁时,报文移到sk_receive_queue队列。

第二部分:用户如何收取报文
用户可以调用sys_recvfrom()或sys_recv()来接收报文,所不同的是,sys_recvfrom()可能通过参数获得报文的来源地址,而sys_recv()则不可以,但对接收报文并没有影响。在用户调用recvfrom()或recv()接收报文前,发给该socket的报文都会被添加到sk->sk_receive_queue上,recvfrom()和recv()要做的就是从sk_receive_queue上取出报文,拷贝到用户空间,供用户使用。
sys_recv() -> sys_recvfrom()
sys_recvfrom() -> sk->ops->recvmsg()
==> sock_common_recvmsg() -> sk->sk_prot->recvmsg()
==> udp_recvmsg()
sys_recvfrom()
调用sock_recvmsg()接收udp报文,存放在msg中,如果接收到报文,从内核到用户空间拷贝报文的源地址到addr中,addr是recvfrom()调用的传入参数,表示报文源的地址。而报文的内容是在udp_recvmsg()中从内核拷贝到用户空间的。
udp_recvmsg() 接收udp报文
这个函数有三个关键操作:
1. 取到数据包 -- __skb_recv_datagram()
2. 拷贝数据 -- skb_copy_datagram_iovec()或skb_copy_and csum_datagram_iovec()
3. 必要时计算校验和 – skb_copy_and_csum_datagram_iovec()

__skb_recv_datagram(),它会从sk->sk_receive_queue上取出一个skb,前面已经分析到,内核收到发往该socket的报文会放在sk->sk_receive_queue。
如果没有报文,有两种情况:使用了非阻塞接收,且用户接收时还没有报文到来;使用阻塞接收,但之前没有报文,且在sk->sk_rcvtimeo时间内都没有报文到来。没有报文,返回错误值。
len是recvfrom()传入buf的大小,ulen是报文内容的长度,如果ulen > len,那么只需要使用buf的ulen长度就可以了;如果len < ulen,那么buf不够报文填充,只能对报文截断,取前len个字节。
如果报文被截断或使用UDP-Lite,那么需要提前验证校验和,udp_lib_checksum_complete()完成校验和计算,函数在下面具体分析。
如果报文不用验证校验和,那么执行if部分,调用skb_copy_datagram_iovec()直接拷贝报文到buf中就可以了;如果报文需要验证校验和,那么执行else部分,调用skb_copy_and_csum_datagram_iovec()拷贝报文到buf,并在拷贝过程中计算校验和。这也是为什么在内核收到udp报文时为什么先验证校验和再处理的原因,udp报文可能很大,校验和的计算可能很耗时,将其放在拷贝过程中可以节约开销,当然它的代价是一些校验和错误的报文也会被添加到socket的接收队列上,直到用户真正接收时它们才会被丢弃。
拷贝地址到msg->msg_name中,在sys_recvfrom()中msg->msg_name=&address,然后address会从内核拷贝给用户空间的addr。
下面来重点看核心操作的三个函数:
__skb_recv_datagram() 从sk_receive_queue上取一个skb
核心代码段如下,skb_peek()从sk->sk_receive_queue中取出一个skb,如果有的话,则返回skb,作为用户此次接收的报文,当然还有对skb的后续处理,但该函数只是取出一个skb;如果还没有的话,则使用wait_for_packet()等待报文到来,其中参数timeo代表等待的时间,如果使用非阻塞接收的话,timeo会设置为0(即当前没有skb的话则直接返回,不进行等待),否则设置为sk->sk_rcvtimeo。
skb_copy_datagram_iovec() 拷贝skb内容到msg中
拷贝可以分三部分:线性地址空间的拷贝,聚合/发散地址空间的拷贝,非线性地址空间的拷贝。第二部分需要硬件的支持,这里讨论另两部分。
在skb的buff中的是线性地址空间,在skb的frag_list上的是非线性地址空间;当没有分片发生的,用线性地址空间就足够了,但是当报文过长而分片时,第一个分片会使用线性地址空间,其余的分片将被链到skb的frag_list上,即非线性地址空间,具体可以参考”ipv4模块”中分片部分。
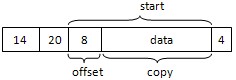
拷贝报文内容时,就要将线性和非线性空间的内容都拷贝过去。下面是拷贝线性地址空间的代码段,start是报文的线性部分长度(skb->len-skb->datalen),copy是线性地址空间的大小,offset是相对skb的偏移(即此次拷贝从哪里开始),以udp报文为例,这几个值如下图所示。memcpy_toiovec()拷贝内核到to中,要注意的是它改变了to的成员变量。
下面是拷贝非线性地址空间的代码段,遍历skb的frag_list链表,对上面的每个分片,拷贝内容到to中,这里start, end的值不重要,重要的是它们的差值end-start,表示了当前分片frag_iter的长度,使用skb_copy_datagram_iovec()拷贝当前分片内容,即把每个分片都作为单独报文来处理。不过对于分片,感觉只有拷贝的第一部分和第二部分,在IP层分片重组时,并没有将分片链在分片的frag_list上的情况,而都链在头分片的frag_list上。
还是以一个例子来说明,主机收到一个udp报文,内容长度为4000 bytes,MTU是1500,传入buff数组大小也为4000。根据MTU,报文会会被分成三片,分片IP报内容大小依次是1480, 1480, 1040。每个分片都有一个20节字的IP报文,第一个分片还有一个8节字的udp报头。接收时数据拷贝情况如下:
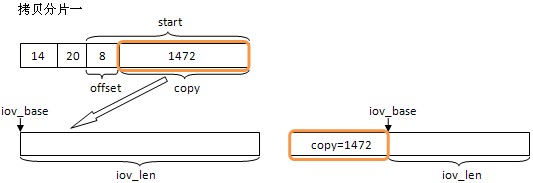
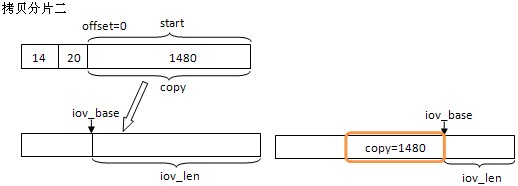

分片一是第一个分片,包含UDP报文,在拷贝时要跳过,因为使用的是udp socket接收,只要报文内容就可以了。三张图片代表了三次调用skb_copy_datagram_iovec()的情况,iov是存储内容的buff,最终结果是三个分片共4000字节拷贝到了iov中。
memcpy_toiovec()函数需要注意,不仅因为它改变了iovec的成员值,还因为最后的iov++。在udp socket的接收recvfrom()中,msg.msg_iov = &iov,而iov定义成struct iovec iov,即传入参数iov实际只有一个的空间,那么在iov++后,iov将指向非法的地址。这里只考虑udp使用时的情况,memcpy_toiovec()调用的前一句是,这里len是接收buff的长度:
而memcpy_toiovec()中又有int copy = min_t(unsigned int, iov->iov_len, len),这里len是上面传入的copy,iov_len是接收buff长度,这两句保证了函数中copy值与len相等,即完成一次拷贝后,len-=copy会使len==0,虽然iov++指向了非法内存,但由于while(len > 0)已退出,所以不会使用iov做任何事情。其次,函数中的iov++并不会对参数iov产生影响,即函数完成iov还是传入的值。最后,拷贝完后会修改iov_len和iov_base的值,iov_len表示可用长度,iov_base表示起始拷贝位置。
skb_copy_and_csum_datagram_iovec() 拷贝skb内容到msg中,同时计算校验和
这个函数提高了校验和计算效率,因为它合并了拷贝与计算操作,这样只要一次遍历操作就可以了。与skb_copy_datagram_iovec()相比,它在每次拷贝skb内容时,计算下这次拷贝内容的校验和。
csum = csum_partial(skb->data, hlen, skb->csum);
if (skb_copy_and_csum_datagram(skb, hlen, iov->iov_base, chunk, &csum))
goto fault;
UDP报文发送
发送时有两种调用方式:sys_send()和sys_sendto(),两者的区别在于sys_sendto()需要给入目的地址的参数;而sys_send()调用前需要调用sys_connect()来绑定目的地址信息;两者的后续调用是相同的。如果调用sys_sendto()发送,地址信息在sys_sendto()中从用户空间拷贝到内核空间,而报文内容在udp_sendmsg()中从用户空间拷贝到内核空间。
sys_send() -> sys_sendto()
sys_sendto() -> sock_sendmsg() -> __sock_sendmsg() -> sock->ops->sendmsg()
==> inet_sendmsg() -> sk->sk_prot->sendmsg()
==> udp_sendmsg()
udp_sendmsg()的核心流程如下图所示,只列出了核心的函数调用了参数赋值,大致步骤是:获取信息 -> 获取路由项rt -> 添加数据 -> 发送数据。

udp_sock结构体中的pending用于标识当前udp_sock上是否有待发送数据,如果有的话,则直接goto do_append_data继续添加数据;否则先要做些初始化工作,再才添加数据。实际上,pending!=0表示此调用前已经有数据在udp_sock中的,每次调和sendto()发送数据时,pending初始等于0;在添加数据时,设置up->pending = AF_INET。直到最后调用udp_push_pending_frames()将数据发送给IP层或skb_queue_empty(&sk->sk_write_queue)发送链表上为空,这时设置up->pending = 0。因此,这里可以看到,报文发送时pending值的变化:
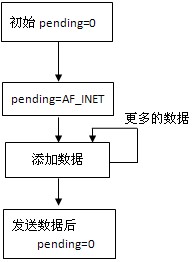
通常使用sendto()发送都是一次调用对应一个报文,即pending=0->AF_INET->0;但如果调用sendto()时参数用到了MSG_MORE标志,则pending=0->AF_INET,直到调用sendto()时未使用MSG_MORE标志,表示此次发送数据是最后一部分数据时,pending=AF_INET->0。
如果pending=0没有待发送数据,执行初始化操作:报文长度、地址信息、路由项。
ulen初始为sendto()传入的数据长度,由于是第一部分数据(如果没有后续数据,则就是报文),ulen要添加udp报头的8字节。
这段代码获取要发送数据的目的地址和端口号。一种情况是调用sendto()发送数据,此时目的的信息以参数传入,存储在msg->msg_name中,因此从中取出daddr和dport;另一种情况是调用connect(), send()发送数据,在connect()调用时绑定了目的的信息,存储在inet中,并且由于是调用了connect(),sk->sk_state会设置为TCP_ESTABLISHED。以后调用send()发送数据时,无需要再给入目的信息参数,因此从inet中取出dadr和dport。而connected表示了该socket是否已绑定目的。
下一步是获取路由项rt,如果已连接(调用过connect),则路由信息在connect()时已获取,直接拿就可以了;如果未连接或拿到的路由项已被删除,则需要重新在路由表中查找,还是使用ip_route_output_flow()来查找,如果是连接状态的socket,则要用新找到的rt来更新socket,当然,前提条件是之前的rt已过期。
存储信息daddr, dport, saddr, sport到cork.fl中,它们会在生成udp报头和计算udp校验和时用到。up->pending=AF_INET标识了数据添加的开始,下面将开始数据的添加工作。
如果pending!=0或执行完初始化操作,则直接执行添加数据操作:
up->len表示要发送数据的总长度,包括udp报头,因此每发送一部分数据就要累加它的长度,在发送后up->len被清0。然后调用ip_append_data()添加数据到sk->sk_write_queue,它会处理数据分片等问题,在 ”ICMP模块” 中有详细分析过。
ip_append_data()添加数据正确会返回0,否则udp_flush_pending_frames()丢弃将添加的数据;如果添加数据正确,且没有后续的数据到来(由MSG_MORE来标识),则udp_push_pending_frames()将数据发送给IP层,下面将详细分析这个函数。最后一种情况是当sk_write_queue上为空时,它触发的条件必须是发送多个报文且sk_write_queue上为空,而实际上在ip_append_data过后sk_write_queue不会为空的,因此正常情况下并不会发生。哪种情况会发生呢?重置pending值为0就是在这里完成的,三个条件语句都会将pending设置为0。
if (err)
udp_flush_pending_frames(sk);
else if (!corkreq)
err = udp_push_pending_frames(sk);
else if (unlikely(skb_queue_empty(&sk->sk_write_queue)))
up->pending = 0;数据已经处理完成,释放取到的路由项rt,如果有IP选项,也释放它。如果发送数据成功,返回发送的长度len;否则根据错误值err进行错误处理并返回err。
在 “ICMP模块” 中往IP层发送数据使用的是ip_push_pending_frames()。而在UDP模块中往IP层发送数据使用的是ip_push_pending_frames()。而在UDP模块中往IP层发送数据的udp_push_pending_frames()只是对ip_push_pending_frames()的封装,主要是增加对UDP的报头的处理。同理,udp_flush_pending_frames()也是,只是它更简单,仅仅重置了up->len和up->pending的值,重置后可以开始一个新报文。那么udp_push_pending_frames()封装了哪些处理呢。
udp_push_pending_frames() 发送数据给IP层
设置udp报头,包括源端口source,目的端口dest,报文长度len。
计算udp报头中的校验和,包括了伪报头、udp报头和报文内容。
将报文发送给IP层,这个函数已经分析过了。
同样,在发送完报文后,重置len和pending的值,以便开始下一个报文发送。
这篇关于NETDEV 协议 七的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!







