本文主要是介绍NETDEV 协议 四,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
内核版本:2.6.34
NetFilter在2.4.x内核中引入,成为linux平台下进行网络应用的主要扩展,不仅包括防火墙的实现,还包括报文的处理(如报文加密、报文分类统计等)等。
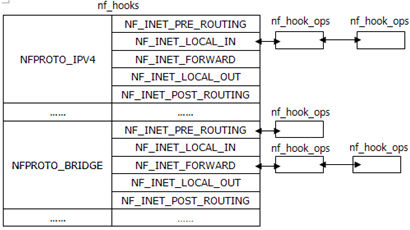
NetFilter数据结构 勾子struct nf_hook_ops[net\filter\core.c]
struct nf_hook_ops {
struct list_head list;
/* User fills in from here down. */
nf_hookfn *hook;
struct module *owner;
u_int8_t pf;
unsigned int hooknum;
/* Hooks are ordered in ascending priority. */
int priority;
};
成员list用于链入全局勾子数组nf_hooks中,它一定在第一位,保证&nf_hook_ops->list的值与&nf_hook_ops相同,稍后在使用时会用到这一技巧;
成员hook即用户定义的勾子函数;owner表示注册这个勾子函数的模块,因为netfilter是内核空间的,所以一般为模块来完成勾子函数注册;pf与hooknum一起索引到特定协议特定编号的勾子函数队列,用于索引nf_hooks; priority决定在同一队列(pf与hooknum相同)的顺序,priority越小则排列越靠前。
struct nf_hook_ops只是存储勾子的数据结构,而真正存储这些勾子供协议栈调用的是nf_hooks,从定义可以看出,它其实就是二维数组的链表。
struct list_head nf_hooks[NFPROTO_NUMPROTO][NF_MAX_HOOKS]; [net\filter\core.c]
其中NFPROTO_NUMPROTO表示勾子关联的协议,可取值:
enum {
NFPROTO_UNSPEC = 0,
NFPROTO_IPV4 = 2,
NFPROTO_ARP = 3,
NFPROTO_BRIDGE = 7,
NFPROTO_IPV6 = 10,
NFPROTO_DECNET = 12,
NFPROTO_NUMPROTO,
};
NF_MAX_HOOKS表示勾子应用的位置,可选值在每个协议模块内部定义,这些值代表了勾子函数在协议流程中应用的位置(稍后会以bridge为例详细说明),大致上都有以下值:
NF_XXX_PRE_ROUTING,
NF_XXX_LOCAL_IN,
NF_XXX_FORWARD,
NF_XXX_LOCAL_OUT,
NF_XXX_POST_ROUTING,
NF_XXX_NUMHOOKS
NetFilter注册
在了解了nf_hook_ops和nf_hooks后,来看下如何操作nf_hooks中的元素。
nf_register_hook()将nf_hook_ops注册到nf_hooks中:
int nf_register_hook(struct nf_hook_ops *reg)
{
struct nf_hook_ops *elem;
int err;
err = mutex_lock_interruptible(&nf_hook_mutex);
if (err < 0)
return err;
list_for_each_entry(elem, &nf_hooks[reg->pf][reg->hooknum], list) {
if (reg->priority < elem->priority)
break;
}
list_add_rcu(®->list, elem->list.prev);
mutex_unlock(&nf_hook_mutex);
return 0;
}
这个函数很简单,从指定pf&hooknum的nf_hooks队列遍历,按priority从小到大顺序,将reg插入相应位置,完成勾子函数的注册。
nf_unregister_hook()将nf_hook_ops从nf_hooks中注销掉:
void nf_unregister_hook(struct nf_hook_ops *reg)
{
mutex_lock(&nf_hook_mutex);
list_del_rcu(®->list);
mutex_unlock(&nf_hook_mutex);
synchronize_net();
}
这个函数更简单,从nf_hooks中删除reg。
内核同时还提供了nf_register_hooks()和nf_unregister_hooks(),将reg重复注册n次或将reg从nf_hooks中注销n次。当勾子函数注册完成后,nf_hooks的结构如图所示:
NetFilter调用
在报文在内核协议栈传递时,会调用NetFilter模块对报文进行特定的进滤,这样的过滤在代码中随处可见。
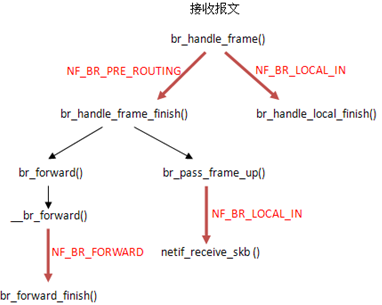
以上一篇讲过的网桥为例,对于要进行网桥处理的报文,handle_bridge()->br_handle_frame(),如果端口处理于LEARNING或FORWARDING状态,且报文目的地址正确,则会调用br_handle_frame()进行后续处理,而这个函数调用就是:
NF_HOOK(PF_BRIDGE, NF_BR_PRE_ROUTING, skb, skb->dev, NULL,
br_handle_frame_finish);
NF_HOOK()->NF_HOOK_THRESH()->nf_hook_thresh()->nf_hook_slow():
int nf_hook_slow(u_int8_t pf, unsigned int hook, struct sk_buff *skb,
struct net_device *indev,
struct net_device *outdev,
int (*okfn)(struct sk_buff *),
int hook_thresh)
{
struct list_head *elem;
unsigned int verdict;
int ret = 0;
/* We may already have this, but read-locks nest anyway */
rcu_read_lock();
elem = &nf_hooks[pf][hook];
next_hook:
verdict = nf_iterate(&nf_hooks[pf][hook], skb, hook, indev,
outdev, &elem, okfn, hook_thresh);
if (verdict == NF_ACCEPT || verdict == NF_STOP) {
ret = 1;
} else if (verdict == NF_DROP) {
kfree_skb(skb);
ret = -EPERM;
} else if ((verdict & NF_VERDICT_MASK) == NF_QUEUE) {
if (!nf_queue(skb, elem, pf, hook, indev, outdev, okfn,
verdict >> NF_VERDICT_BITS))
goto next_hook;
}
rcu_read_unlock();
return ret;
}
nf_hook_slow()从nf_hooks中找出到执行的勾子队列,依次执行,然后根据返回值决定是否继续(由nf_iterate()完成)。参数中的pf和hook代表了注册勾子函数时给的参数PF和HOOKNUM,它们共同决定勾子函数要插入的nf_hook的哪个队列中。
作为过滤报文的勾子函数的返回值是值得注意的地方,可取值如下:
#define NF_DROP 0
#define NF_ACCEPT 1
#define NF_STOLEN 2
#define NF_QUEUE 3
#define NF_REPEAT 4
#define NF_STOP 5
先以nf_iterate()函数为例,elem->hook()表示执行勾子函数,执行结构为verdict;
unsigned int nf_iterate(……)
{
unsigned int verdict;
list_for_each_continue_rcu(*i, head) {
struct nf_hook_ops *elem = (struct nf_hook_ops *)*i;
if (hook_thresh > elem->priority)
continue;
verdict = elem->hook(hook, skb, indev, outdev, okfn);
if (verdict != NF_ACCEPT) {
if (verdict != NF_REPEAT)
return verdict;
*i = (*i)->prev;
}
}
return NF_ACCEPT;
}
根据nf_iterate()返回,会有以下情况:
1.
如果结果为NF_ACCEPT,表示勾子函数允许报文继续向下处理,此时应该继续执行队列上的下一个勾子函数,因为这些勾子函数都是对同一类报文在相同位置的过滤,前一个通后,并不能返回,而要所有函数都执行完,结果仍为NF_ACCEPT时,则可返回它;
2.
如果结果为NF_REPEAT,表示要重复执行勾子函数一次;所以勾子函数要编写得当,否则报文会一直执行一个返回NF_REPEAET的勾子函数,当返回值为NF_REPEAT时,不会返回;
3.
如果为其它结果,则不必再执行队列上的其它函数,直接返回它;如NF_STOP表示停止执行队列上的勾子函数,直接返回;NF_DROP表示丢弃掉报文;NF_STOLEN表示报文不再往上传递,与NF_DROP不同的是,它没有调用kfree_skb()释放掉skb;NF_QUEUE检查给定协议(pf)是否有队列处理函数,有则进行处理,否则丢掉。
了解了这些值再来看nf_hook_slow()中对于nf_iterate()返回值的处理就明了了:
NetFilter的存在使得在内核空间对报文进行用户定义的要求处理变得可能、简单。一般来说,编写好struct nf_hook_ops,其中hook/pf/ hook是必给的参数,然后使用nf_register_hook进行注册就可以了。整个过滤文件可以写了一个内核模块,用insmod进行动态加载。
本文只是一个内核网络协议的实践的例子,先说明添加的目的,下篇开始具体的实现。
内核版本:2.6.34;在支持802.1主机上,报文的一般格式:

现在需要支持一种新的协议[二层] – BRCM协议,与IP等协议不同,它位于2层,拥有6字节的头部和4字节的尾部,添加的层次决定了比起添加其它协议要复杂一些,新的报文格式如下,而我们的目的就是要网络协议栈能正常处理这样的报文:

实际上BRCM是一种交换机的内部协议,用处是让交换机管理端口能通过BRCM获取报文来自于交换机的哪个端口,或者指定报文从交换机哪个端口出去;当然,这不是我们关心的内容,我们只需要为它挑选一个协议号0x8744,其余内容置0就可以了。因此,brcm头部会填写成 88 74 00 00 00 00,brcm尾部会填写成 00 00。一个新协议的报文内容用wireshark等捕包工具查看的形式如下:
[源/目的mac]02 03 04 05 06 07 10 11 12 13 14 15
[BRCM报头]88 74 00 00 00 00
[Vlan报头]81 00 00 01
[报文内容]……..
先从设备的概念来看下添加BRCM协议后的层次图:

eth1代表实际的B4401物理网卡;eth1.X/brcm0.x代表VLAN创建的虚拟网卡,后面的数字X是vlan号;brcm0代表BRCM创建的虚拟网卡,数字0表示测试用;从图中可以看到,brcm协议的添加是通过添加brcmX虚拟网卡接口实现的。
如果BRCM协议添加正确,那么最终的结果应该是:
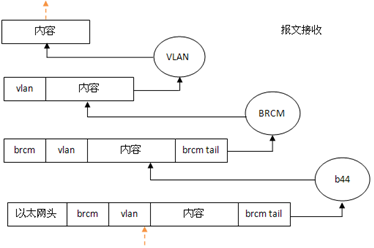
在接收报文时,通过虚拟设备BRCM会脱去brcm的6字节的头部与4字节尾部,当然,协议做的远远不只这些,但这是核心。
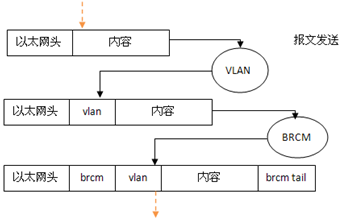
在发送报文时,通过虚拟设备BRCM会添加6字节的头部与4字节的尾部,当然,协议做的远远不只这些,但这是核心。
要做的工作大致是以下几项:
1. 确定brcm_dev的存储数据结构
2. 编写struct ptype_base brcm_packet_type
3. 添加ioctl调用供用户空间调用,至少包括brcm_dev的创建和删除
4. 添加notifier机制、netlink机制、proc机制
5. 添加编译用的Kconfig, Makefile等,并修改Menuconfig
数据结构是核心,每一步也是一个网络协议模块的核心。下一篇开始brcm协议的添加实现。
内核版本:2.6.34
实现思路:
报文在网络协议栈中的流动,对于接收来讲,是对报文的脱壳的过程,由于报文是已知的输入,只要逐个解析协议号;对于发送来讲,是各层发送函数的嵌套调用,由于没有已知的输入,只能按事先设计好的协议进行层层构造。但无论报文怎样的流动,核心是报文所在设备(skb->dev)的变化,相当于各层之间传递的交接棒。
按照上述思路,brcm协议接收的处理作为模块brcm_packet_type加入到ptype_base中就可以了;brcm协议发送的处理则复杂一点,发送的嵌套调用完全是依赖于设备来推动的,因此要有一种新创建的设备X,插入到vlan设备和网卡设备之间。
因此,至少要有brcm_packet_type来加入ptype_base和register_brcm_dev()来向系统注册设备X。进一步考虑,设备X在全局量init_net中有存储,但我们还需要知道设备X与vlan设备以及网卡设备是何种组织关系,所以在这里设计了brcm_group_hash来存储这种关系。为了对设备感兴趣的事件作出响应,添加自己的notifier到netdev_chain中。另外,为了用户空间具有一定控制能力(如创建、删除),还需要添加brcm相关的ioctl调用。为了让它看起来更完整,一种新的设备在proc中也应有对应项,用来调试和查看设备。
从最简单开始
要让网络协议栈能够接收一种新协议是很简单的,由于已经有报文作为输入,我们要做的仅仅是编写好brcm_packet_type,然后在注册模块时只用做一件事:dev_add_pack。
static int __init brcm_proto_init(void)
{
dev_add_pack(&brcm_packet_type);
}
static struct packet_type brcm_packet_type __read_mostly = {
.type = cpu_to_be16(ETH_P_BRCM),
.func = brcm_skb_recv, /* BRCM receive method */
};
int brcm_skb_recv(struct sk_buff *skb, struct net_device *dev,
struct packet_type *ptype, struct net_device *orig_dev)
{
struct brcm_hdr *bhdr;
struct brcm_rx_stats *rx_stats;
skb = skb_share_check(skb, GFP_ATOMIC);
if(!skb)
goto err_free;
bhdr = (struct brcm_hdr *)skb->data;
rcu_read_lock();
skb_pull_rcsum(skb, BRCM_HLEN);
// set protocol
skb->protocol = bhdr->brcm_encapsulated_proto;
// reorder skb
skb = brcm_check_reorder_header(skb);
if (!skb)
goto err_unlock;
netif_rx(skb);
rcu_read_unlock();
return NET_RX_SUCCESS;
err_unlock:
rcu_read_unlock();
err_free:
kfree_skb(skb);
return NET_RX_DROP;
}
注册这个模块后,协议栈就能正常接收带brcm报头的报文的,代码中ETH_P_BRCM是brcm的协议号,BRCM_HLEN是brcm的报头长度。正是由于有报文作为输入,接收变得十分简单。
但这仅仅是能接收而已,发送的报文还是不带brcm报头的,而且接收的这段代码也很粗略,没有变更skb的设备,没有记录流量,没有对brcm报头作有意义的处理,下面逐一进行添加。
设备的相关定义
一种设备就是net_device类型,而每种设备都有自己的私有变量,它存储在net_device末尾,定义如下,其中real_dev指向下层设备,这是最基本属性,其余可以视需要自己设定,brcm_rx_stats则是该设备接收流量统计:
struct brcm_dev_info{
struct net_device *real_dev;
u16 brcm_port;
unsigned char real_dev_addr[ETH_ALEN];
struct proc_dir_entry *dent;
struct brcm_rx_stats __percpu *brcm_rx_stats;
};
struct brcm_rx_stats {
unsigned long rx_packets;
unsigned long rx_bytes;
unsigned long multicast;
unsigned long rx_errors;
};
设备间的关系问题
如果brcm仅仅是只有一个设备,则无需数据结构来存储这种关系,一个全局全变的brcm_dev就可以了。这里的设计考虑的是复杂的情况,可以存在多个下层设备,多个brcm设备,之间没有固定的关系。所以需要一种数据结构来存储这种关系- brcm_group_hash。下面是一个简单的图示:

各个数据结构定义如下:
static struct hlist_head brcm_group_hash[BRCM_GRP_HASH_SIZE];
struct brcm_group {
struct hlist_node hlist;
struct net_device *real_dev;
int nr_ports;
int killall;
struct net_device *brcm_devices_array[BRCM_GROUP_ARRAY_LEN];
struct rcu_head rcu;
};
brcm_group_hash作为全局变量存在,以hash表形式组织,brcm_group被插入到brcm_group_hash中,brcm_group存储了它与下层设备的关系(eth与brcm),real_dev指向e下层设备,而brcm设备则存储在brcm_devices_array数组中。
下面完成由下层设备转换成brcm设备的函数,brcm_port是报头中的值,可以自己设定它的含义,这里设定它表示报文来自于哪个端口。
struct net_device *find_brcm_dev(struct net_device *real_dev, u16 brcm_port)
{
struct brcm_group *grp = brcm_find_group(real_dev);
if (grp)
brcm_dev = grp->brcm_devices_array[brcm_port];
return NULL;
}
因为在接收报文时,报文到达brcm层开始处理时,skb->dev指向的仍是下层设备,这时通过skb->dev查到brcm_group->real_dev相匹配的hash项,然后通过报文brcm报头的信息,确定brcm_group->brcm_devices_array中哪个brcm设备作为skb的新设备;
而在发送报文时,报文到达brcm层开始处理时,skb->dev指向的是brcm设备,为了继续向下传递,需要变更为它的下层设备,在设备数据net_device的私有数据部分,一般会存储一个指针,指向它的下层设备,因此skb->dev只要变更为brcm_dev_info(dev)->real_dev。
流量统计
在数据结构中,brcm设备的私有数据brcm_dev_info中brcm_rx_stats记录接收的流量信息;而dev->_tx[index]则会记录发送的流量信息。
在接收函数brcm_skb_rcv()中对于成功接收的报文会增加流量统计:
rx_stats = per_cpu_ptr(brcm_dev_info(skb->dev)->brcm_rx_stats,
smp_processor_id());
rx_stats->rx_packets++;
rx_stats->rx_bytes += skb->len;
在发送函数brcm_dev_hard_start_xmit()中对于发送的报文会增加相应流量统计:
if (likely(ret == NET_XMIT_SUCCESS)) {
txq->tx_packets++;
txq->tx_bytes += len;
} else
txq->tx_dropped++;
而brcm_netdev_ops->ndo_get_stats()即brcm_dev_get_stats()函数,则会将brcm网卡设备中记录的发送和接收流量信息汇总成通用的格式net_device_stats,像ifconfig等命令使用的就是net_device_stats转换后的结果。
完整收发函数
有了这些后接收函数brcm_skb_recv()就可以完整了,其中关于报头brcm_hdr的处理可以略过,由于是空想的协议,含义是可以自己设定的:
int brcm_skb_recv(struct sk_buff *skb, struct net_device *dev,
struct packet_type *ptype, struct net_device *orig_dev)
{
struct brcm_hdr *bhdr;
struct brcm_rx_stats *rx_stats;
int op, brcm_port;
skb = skb_share_check(skb, GFP_ATOMIC);
if(!skb)
goto err_free;
bhdr = (struct brcm_hdr *)skb->data;
op = bhdr->brcm_tag.brcm_53242_op;
brcm_port = bhdr->brcm_tag.brcm_53242_src_portid- 23;
rcu_read_lock();
// drop wrong brcm tag packet
if (op != BRCM_RCV_OP || brcm_port < 1
|| brcm_port > 27)
goto err_unlock;
skb->dev = find_brcm_dev(dev, brcm_port);
if (!skb->dev) {
goto err_unlock;
}
rx_stats = per_cpu_ptr(brcm_dev_info(skb->dev)->brcm_rx_stats,
smp_processor_id());
rx_stats->rx_packets++;
rx_stats->rx_bytes += skb->len;
skb_pull_rcsum(skb, BRCM_HLEN);
switch (skb->pkt_type) {
case PACKET_BROADCAST: /* Yeah, stats collect these together.. */
/* stats->broadcast ++; // no such counter :-( */
break;
case PACKET_MULTICAST:
rx_stats->multicast++;
break;
case PACKET_OTHERHOST:
/* Our lower layer thinks this is not local, let's make sure.
* This allows the VLAN to have a different MAC than the
* underlying device, and still route correctly.
*/
if (!compare_ether_addr(eth_hdr(skb)->h_dest,
skb->dev->dev_addr))
skb->pkt_type = PACKET_HOST;
break;
default:
break;
}
// set protocol
skb->protocol = bhdr->brcm_encapsulated_proto;
// reorder skb
skb = brcm_check_reorder_header(skb);
if (!skb) {
rx_stats->rx_errors++;
goto err_unlock;
}
netif_rx(skb);
rcu_read_unlock();
return NET_RX_SUCCESS;
err_unlock:
rcu_read_unlock();
err_free:
kfree_skb(skb);
return NET_RX_DROP;
}
同时,发送函数brcm_dev_hard_start_xmit()可以完整了,同样,其中关于brcm_hdr的处理可以略过:
static netdev_tx_t brcm_dev_hard_start_xmit(struct sk_buff *skb,
struct net_device *dev)
{
int i = skb_get_queue_mapping(skb);
struct netdev_queue *txq = netdev_get_tx_queue(dev, i);
struct brcm_ethhdr *beth = (struct brcm_ethhdr *)(skb->data);
unsigned int len;
u16 brcm_port;
int ret;
/* Handle non-VLAN frames if they are sent to us, for example by DHCP.
*
* NOTE: THIS ASSUMES DIX ETHERNET, SPECIFICALLY NOT SUPPORTING
* OTHER THINGS LIKE FDDI/TokenRing/802.3 SNAPs...
*/
if (beth->h_brcm_proto != htons(ETH_P_BRCM)){
//unsigned int orig_headroom = skb_headroom(skb);
brcm_t brcm_tag;
brcm_port = brcm_dev_info(dev)->brcm_port;
if (brcm_port == BRCM_ANY_PORT) {
brcm_tag.brcm_op_53242 = 0;
brcm_tag.brcm_tq_53242 = 0;
brcm_tag.brcm_te_53242 = 0;
brcm_tag.brcm_dst_53242 = 0;
}else {
brcm_tag.brcm_op_53242 = BRCM_SND_OP;
brcm_tag.brcm_tq_53242 = 0;
brcm_tag.brcm_te_53242 = 0;
brcm_tag.brcm_dst_53242 = brcm_port + 23;
}
skb = brcm_put_tag(skb, *(u32 *)(&brcm_tag));
if (!skb) {
txq->tx_dropped++;
return NETDEV_TX_OK;
}
}
skb_set_dev(skb, brcm_dev_info(dev)->real_dev);
len = skb->len;
ret = dev_queue_xmit(skb);
if (likely(ret == NET_XMIT_SUCCESS)) {
txq->tx_packets++;
txq->tx_bytes += len;
} else
txq->tx_dropped++;
return ret;
}
注册设备
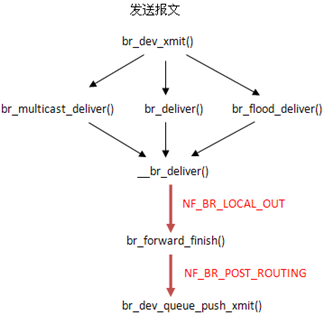
接收通过dev_add_pack(),就可以融入协议栈了,前面几篇的分析已经讲过通过ptype_base对报文进行脱壳。现在要融入的发送,函数已经完成了,既然发送是一种嵌套的调用,并且是由dev来推过的,那么发送函数的融入一定在设备进行注册时,作为设备的一种发送方法。
创建一种设备时,一定会有设备的XXX_setup()初始化,大部分设备都会用ether_setup()来作初始化,再进行适当更改。下面是brcm_setup():
void brcm_setup(struct net_device *dev)
{
ether_setup(dev);
dev->priv_flags |= IFF_BRCM_TAG;
dev->priv_flags &= ~IFF_XMIT_DST_RELEASE;
dev->tx_queue_len = 0;
dev->netdev_ops = &brcm_netdev_ops;
dev->destructor = free_netdev;
dev->ethtool_ops = &brcm_ethtool_ops;
memset(dev->broadcast, 0, ETH_ALEN);
}
其中发送函数就在brcm_netdev_ops中,每层设备都会这样调用:dev->netdev_ops->ndo_start_xmit()。
static const struct net_device_ops brcm_netdev_ops = {
.ndo_change_mtu = brcm_dev_change_mtu,
.ndo_init = brcm_dev_init,
.ndo_uninit = brcm_dev_uninit,
.ndo_open = brcm_dev_open,
.ndo_stop = brcm_dev_stop,
.ndo_start_xmit = brcm_dev_hard_start_xmit,
.ndo_validate_addr = eth_validate_addr,
.ndo_set_mac_address = brcm_dev_set_mac_address,
.ndo_set_rx_mode = brcm_dev_set_rx_mode,
.ndo_set_multicast_list = brcm_dev_set_rx_mode,
.ndo_change_rx_flags = brcm_dev_change_rx_flags,
//.ndo_do_ioctl = brcm_dev_ioctl,
.ndo_neigh_setup = brcm_dev_neigh_setup,
.ndo_get_stats = brcm_dev_get_stats,
};
而设备的初始化应该发生在创建设备时,也就是向网络注册它时,也就是register_brcm_dev(),注册一个新设备,需要知道它的下层设备real_dev以及唯一标识brcm设备的brcm_port。首先确定该设备没有被创建,然后用alloc_netdev_mq创建新设备new_dev,然后设置相关属性,特别是它的私有属性brcm_dev_info(new_dev),然后添加它到brcm_group_hash中,最后发生真正的注册register_netdevice()。
static int register_brcm_dev(struct net_device *real_dev, u16 brcm_port)
{
struct net_device *new_dev;
struct net *net = dev_net(real_dev);
struct brcm_group *grp;
char name[IFNAMSIZ];
int err;
if(brcm_port >= BRCM_PORT_MASK)
return -ERANGE;
// exist yet
if (find_brcm_dev(real_dev, brcm_port) != NULL)
return -EEXIST;
snprintf(name, IFNAMSIZ, "brcm%i", brcm_port);
new_dev = alloc_netdev_mq(sizeof(struct brcm_dev_info), name,
brcm_setup, 1);
if (new_dev == NULL)
return -ENOBUFS;
new_dev->real_num_tx_queues = real_dev->real_num_tx_queues;
dev_net_set(new_dev, net);
new_dev->mtu = real_dev->mtu;
brcm_dev_info(new_dev)->brcm_port = brcm_port;
brcm_dev_info(new_dev)->real_dev = real_dev;
brcm_dev_info(new_dev)->dent = NULL;
//new_dev->rtnl_link_ops = &brcm_link_ops;
grp = brcm_find_group(real_dev);
if (!grp)
grp = brcm_group_alloc(real_dev);
err = register_netdevice(new_dev);
if (err < 0)
goto out_free_newdev;
/* Account for reference in struct vlan_dev_info */
dev_hold(real_dev);
brcm_group_set_device(grp, brcm_port, new_dev);
return 0;
out_free_newdev:
free_netdev(new_dev);
return err;
}
ioctl
由于brcm设备可以存在多个,并且和下层设备不是固定的对应关系,因此它的创建应该可以人为控制,因此通过ioctl由用户进行创建。这里只为brcm提供了两种操作-添加与删除。一种设备添加一定是与下层设备成关系的,因此添加时需要手动指明这种下层设备,然后通过__dev_get_by_name()从网络空间中找到这种设备,就可以调用register_brcm_dev()来完成注册了。而设备的删除则是直接删除,直接删除unregister_brcm_dev()。
static int brcm_ioctl_handler(struct net *net, void __user *arg)
{
int err;
struct brcm_ioctl_args args;
struct net_device *dev = NULL;
if (copy_from_user(&args, arg, sizeof(struct brcm_ioctl_args)))
return -EFAULT;
/* Null terminate this sucker, just in case. */
args.device1[23] = 0;
args.u.device2[23] = 0;
rtnl_lock();
switch (args.cmd) {
case ADD_BRCM_CMD:
case DEL_BRCM_CMD:
err = -ENODEV;
dev = __dev_get_by_name(net, args.device1);
if (!dev)
goto out;
err = -EINVAL;
if (args.cmd != ADD_BRCM_CMD && !is_brcm_dev(dev))
goto out;
}
switch (args.cmd) {
case ADD_BRCM_CMD:
err = -EPERM;
if (!capable(CAP_NET_ADMIN))
break;
err = register_brcm_dev(dev, args.u.port);
break;
case DEL_BRCM_CMD:
err = -EPERM;
if (!capable(CAP_NET_ADMIN))
break;
unregister_brcm_dev(dev, NULL);
err = 0;
break;
default:
err = -EOPNOTSUPP;
break;
}
out:
rtnl_unlock();
return err;
}
这些是brcm协议模块的主体部分了,当然它还不完整,在下篇中继续完成brcm协议的添加,为它完善一些细节:proc文件系统, notifier机制等等,以及内核Makefile的编写,当然还有协议的测试。相关源码在下篇中打包上传。
内核版本:2.6.34
接上篇《添加网络协议》。
为了用户方便查看brcm设备的工作状态,使用proc文件系统是很好的方式。一个网络协议模块可以注册到网络空间中register_pernet_subsys(),这个函数会为子空间分配一个id号,通过id可以在网络空间中找到分配给该子空间的内存:init_net->gen->ptr[id - 1]。而我们正是利用这块内存去存储proc中的相关信息:struct brcm_net,它记录了brcm设备在proc文件系统中的位置。
struct brcm_net {
/* /proc/net/brcm */
struct proc_dir_entry *proc_brcm_dir;
/* /proc/net/brcm/config */
struct proc_dir_entry *proc_brcm_conf;
};
在加载brcm模块时会注册子空间,brcm_init_net创建在proc中的相关项,并记录路径在brcm_net中;brcm_exit_net删除在proc中的相关项;brcm_net_id记录分配给子空间的id,这样通过init_net->gen->ptr[brcm_net_id - 1]就可以操作brcm_net了。
err = register_pernet_subsys(&brcm_net_ops);
static struct pernet_operations brcm_net_ops = {
.init = brcm_init_net,
.exit = brcm_exit_net,
.id = &brcm_net_id,
.size = sizeof(struct brcm_net),
};
注意到在brcm_init_net和brcm_exit_net中添加和删除的仅仅是/proc/net/brcm目录和config文件,而在使用中brcm设备是可以动态创建的,因此这部分代码应该发生在添加和删除brcm设备时,而不是在brcm模块注册和删除时。最简单的是直接添加在register方法或unregister方法中,但内核提供了更好的机制:事件,将对proc的操作分离出来,因为proc的操作实际上属于附加的操作而不是必须的操作。下面就来看event机制。
前面几篇已经有描述过event机制,这里的事件都是关于设备的事件,使用的是register_netdevice_notifier()来,注册notifier到netdev_chain链表上。在加载brcm模块时注册notifier,brcm_notifier_block包含了brcm设备对所关心的事件作出的反应。
err = register_netdevice_notifier(&brcm_notifier_block);
static struct notifier_block brcm_notifier_block __read_mostly = {
.notifier_call = brcm_device_event,
};
设备对哪些事件会感兴趣,首先,brcm设备对注册和注销是感兴趣的,要操作proc文件系统;其次,对于发往brcm下层设备的事件,要考虑这些事件造成的连带影响(比如eth1被down掉,则其上的brcm设备也应该被down掉),一般是下层设备的事件对其上的所有brcm设备都进行相应操作。
所以在brcm_device_event有两类进入的设备dev会进行操作,一类是brcm设备,它仅仅是操作proc文件系统。判断是否为brcm设备,是的话则由__brcm_device_event() 处理。
if (is_brcm_dev(dev))
__brcm_device_event(dev, event);
static void __brcm_device_event(struct net_device *dev, unsigned long event)
{
switch (event) {
case NETDEV_CHANGENAME:
brcm_proc_rem_dev(dev);
if (brcm_proc_add_dev(dev) < 0)
pr_warning("BRCM: failed to change proc name for %s\n",
dev->name);
break;
case NETDEV_REGISTER:
if (brcm_proc_add_dev(dev) < 0)
pr_warning("BRCM: failed to add proc entry for %s\n",
dev->name);
break;
case NETDEV_UNREGISTER:
brcm_proc_rem_dev(dev);
break;
}
}
如何是brcm的下层设备,如根据brcm_group_hash中的映射关系,对下层设备相关的所有brcm设备进行操作:
switch (event) {
case NETDEV_CHANGE:
/* Propagate real device state to vlan devices */
for (i = 0; i < BRCM_GROUP_ARRAY_LEN; i++) {
brcmdev = brcm_group_get_device(grp, i);
if (!brcmdev)
continue;
netif_stacked_transfer_operstate(dev, brcmdev);
}
break;
case NETDEV_CHANGEADDR:
/* Adjust unicast filters on underlying device */
for (i = 0; i < BRCM_GROUP_ARRAY_LEN; i++) {
brcmdev = brcm_group_get_device(grp, i);
if (!brcmdev)
continue;
flgs = brcmdev->flags;
if (!(flgs & IFF_UP))
continue;
brcm_sync_address(dev, brcmdev);
}
break;
case NETDEV_CHANGEMTU:
for (i = 0; i < BRCM_GROUP_ARRAY_LEN; i++) {
brcmdev = brcm_group_get_device(grp, i);
if (!brcmdev)
continue;
if (brcmdev->mtu <= dev->mtu)
continue;
dev_set_mtu(brcmdev, dev->mtu);
}
break;
case NETDEV_DOWN:
/* Put all VLANs for this dev in the down state too. */
for (i = 0; i < BRCM_GROUP_ARRAY_LEN; i++) {
brcmdev = brcm_group_get_device(grp, i);
if (!brcmdev)
continue;
flgs = brcmdev->flags;
if (!(flgs & IFF_UP))
continue;
brcm = brcm_dev_info(brcmdev);
dev_change_flags(brcmdev, flgs & ~IFF_UP);
netif_stacked_transfer_operstate(dev, brcmdev);
}
break;
case NETDEV_UP:
/* Put all VLANs for this dev in the up state too. */
for (i = 0; i < BRCM_GROUP_ARRAY_LEN; i++) {
brcmdev = brcm_group_get_device(grp, i);
if (!brcmdev)
continue;
flgs = brcmdev->flags;
if (flgs & IFF_UP)
continue;
brcm = brcm_dev_info(brcmdev);
dev_change_flags(brcmdev, flgs | IFF_UP);
netif_stacked_transfer_operstate(dev, brcmdev);
}
break;
case NETDEV_UNREGISTER:
/* Delete all BRCMs for this dev. */
grp->killall = 1;
for (i = 0; i < BRCM_GROUP_ARRAY_LEN; i++) {
brcmdev = brcm_group_get_device(grp, i);
if (!brcmdev)
continue;
/* unregistration of last brcm destroys group, abort
* afterwards */
if (grp->nr_ports == 1)
i = BRCM_GROUP_ARRAY_LEN;
unregister_brcm_dev(brcmdev, &list);
}
unregister_netdevice_many(&list);
break;
}
到这里,协议的添加就大致完成了,当然还包括一些头文件的修改,宏变量的添加等就不一一详述,具体可见最后的附件。
为了编译进内核,还需要修改以下文件:
$(linux)/net/Kconfig $(linux)/net/Makefile
最后,在make menuconfig选择添加brcm协议
Networking Support -> Networking options

同时,需要一个简单的用户空间工具来配置我们的brcm设备,就像vconfig用来配置vlan设备一样;编写的简单的bconfig工具,命令格式:
"Usage: add [interface-name] [brcm_port]\n"
" rem [dev-name]";
内核编译完成后就该进行测试了,如果开启了内核调试信息,启动内核就看到以下信息:

然后启用网卡,可以查看到添加了brcm设备后的状态:

可以使用原生套接字自己打上brcm头后发送报文让协议栈接收,或者用wireshark等捕获协议栈发出的报文,下图即是捕获到的报文:

这是主机发出的arp报文,可以看到,在源mac后接的不是vlan报头,而是我们添加的brcm报文,协议号是8744。
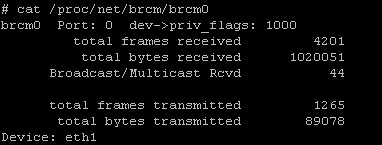
查看proc中信息:
附:patch补丁 && 重要的源文件 && bconfig工具源码
http://download.csdn.net/source/3548117
这篇关于NETDEV 协议 四的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!